
Предлагаем ознакомиться с PUP (Python Upgrade Playbook — практикой обновления Python) в масштабах компании Lyft (1500+ репозиториев в 150+ подразделениях). Речь пойдет о последней итерации инструментов и стратегии, направленной на оптимизацию как общего времени обновления, так и инженерной работы. Надеемся, что техника, которую компания успешно использовала (и развивала) на протяжении нескольких обновлений, от Python 2 до Python 3.10, будет полезна и вам.
Пожаловали в BLT — получите первое задание!
Команда BLT (Backend Language Tooling — языковой инструментарий бэкенда) в Lyft отвечает за опыт работы инженеров компании с Python и Go. Обновление Python — ключевая задача команды BLT (60% репозиториев компании содержат Python-код). Как ни странно, работа над обновлением Python обычно является первым проектом для большинства новых членов команды.
Поддержание Python в актуальном состоянии имеет много преимуществ:
- обеспечивает безопасность и соответствие целям патчинга;
- открывает доступ инженерам к последним версиям инструментов (например, линтеров) и библиотек, которые не поддерживают старые версии Python или работают только на последних версиях (например, библиотек LLM);
- повышает эффективность парка компании, позволяя контролировать расходы (особенно при использовании последних версий Python).
С учетом значительных перемен в Python и его экосистеме команда BLT не видит возможности выполнения всей работы своими силами. Поэтому необходимо сотрудничать с партнерами и вспомогательными подразделениями. При взаимодействии с ними команда BLT придерживается нескольких ключевых принципов.
- Заранее оповещать о предстоящем обновлении, чтобы подразделения могли планировать его, предусмотрев все необходимое на каждом этапе.
- Прежде чем подключить подразделения к процессу обновления, провести комплекс мероприятий по подготовке центральной инфраструктуры и автоматизации.
- Сосредоточиться на критической цепочке: заранее определить репозитории с “длинными” запросами, чтобы избежать задержек в конце, и расставить приоритеты с учетом того, что позволит использовать наибольшее количество репозиториев. Следование этому принципу привело к решению переставить инфраструктуру Airflow с последнего места на одно из первых в очереди на обновление!
Рассмотрим действия команды BLT после отправки письма с текстом “Приготовьтесь к следующему обновлению” всем подразделениям компании.
О, Python! Как тебя использовать?
Все начинается с данных.
При первом обновлении Python возникла неожиданная проблема: подразделения компании сообщили о завершении обновления, но позже стало ясно, что мы что-то упустили и они по-прежнему работали с несколькими версиями Python. Существует множество способов использовать Python в одном репозитории — запуск локально, в сборках, для линтинга, во время тестирования, в качестве зависимости, во время выполнения или даже посредством sidecar-контейнера — и не все они были известны членам команды BLT!
Чтобы решить возникшую проблему, решили инвестировать в данные и создать два дашборда.
- Отчет по каждому репозиторию, показывающий, какие версии Python используются (и где), а также четкие рекомендации: ссылка на открытый PR (pull request — запрос на изменение в коде), требующий исправления и слияния (см. информацию по автоматизации в следующем разделе), а также ссылки на документацию по обновлению, FAQ и Slack-канал поддержки по любым вопросам.
- Сводный отдельный отчет, отражающий использование Python во всей компании, разделенный по компонентам обновления — совместимость зависимостей, использование редактора кода/линтера, прогресс сборки/тестирования по сравнению с развертыванием и т. д. Такой отчет помогает определять приоритеты при планировании, например решать, какую инфраструктуру создавать в первую очередь (в зависимости от того, у какой технологии, Airflow или Streaming, больше пользователей), а также прогнозировать и заранее решать общекорпоративные проблемы, например если определенная широко используемая зависимость нуждается в значительном повышении версии.
Для работы с этими дашбордами были созданы семь конвейеров данных, что позволило расширить возможности службы безопасности по настройке Spark-отчетности (правда, с тех пор эта настройка упростилась).
- Конфигурации линтера, извлеченные из файла .pre-commit-config.yaml в каждом репозитории. Многие “непитоновые” репозитории используют линтеры, написанные на Python, и поэтому подлежат обновлению!
- Граф зависимостей, построенный с помощью Python-инструмента Cartography и используемый службой безопасности.
- Два конвейера для работы с метаданными разрешения зависимостей, поскольку они чувствительны к версии Python. Один считывает стандартное поле метаданных python-requires (для библиотек), другой использует пользовательский комментарий в файле requirements.in, применяемый pip-tools для блокировки зависимостей (для приложений).
- Конфигурация сборки и развертывания, получаемая из специфического для Lyft файла метаданных YAML в каждом репозитории.
- OS-пакеты, присутствующие в каждом Docker-образе. В этом случае используется инфраструктура сканирования образов. Это преподнесло команде BLT большой сюрприз: оказалось, что пакет nodejs (и, соответственно, все фронтенд-сервисы) зависит от Python!
- Вызовы процессов Python в средах Staging/Production с использованием развертывания osquery. Тут возникли сложности, поэтому данный механизм был создан с помощью инженера по данным. Он запускает Trino SQL в Airflow (вместо заданий Spark), чтобы эффективно извлекать данные из osquery.
Все, что может пойти не так, пойдет не так.
Самой большой проблемой, с которой столкнулась команда BLT, было познание истинных глубин закона Мерфи. В числе неожиданных загвоздок оказались:
- полное отсутствие данных;
- дубликаты строк;
- неправильно введенные данные;
- сиротские/фантомные строки;
- усеченные данные;
- нарушения уникальности.
Это сделало членов команды BLT истинными приверженцами проверки качества данных — они взяли на вооружение tinsel и typedload, чтобы, написав свои схемы (как классы данных) один раз, применять их на каждом этапе (извлечении, преобразовании, загрузке) с проверкой типов во время выполнения.
После устранения этих проблем команда BLT предоставляет отчеты в виде веб-страниц (пример из предыдущего обновления):
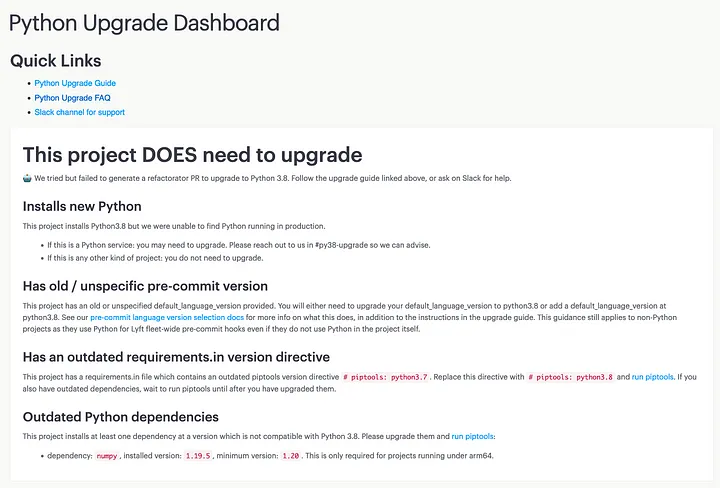
Отчеты выводятся через Voila из Python-скриптов, которые команда BLT обычно итерирует в ноутбуках Jupyter (благодаря jupytext) или запускает непосредственно в оболочке для работы со скриптами (также используются выгружаемые развертывания для обмена и проверки предлагаемых изменений).
Начинается самое интересное!
Имея на руках данные, команда BLT готова создать несколько предварительных PR’ов.
Во-первых, нужно заняться репозиториями, которые не нужно обновлять, поскольку можно отказаться от некоторых из них! Изыскиваются возможности для этого: упомянутые выше наборы данных объединяются с другими внутренними наборами данных:
- сервисы без трафика могут быть отключены;
- воркеры и конвейерные системы с неиспользуемым выводом также можно отключить;
- библиотеки с одним потребителем можно перекомпоновать в потребительские репозитории.
Кроме того, подразделениям с нестандартными настройками репозиториев оказывается помощь в переходе на внутренние стандарты — это позволяет избежать автоматизации, от которой выиграют только один-два репозитория.
Во-вторых, определяются репозитории, требующие обновления. Добавляется поддержка новой версии Python во внутренние инструменты параллельно с существующими версиями Python, а также обновляется документация. Это довольно механический процесс (копирование/вставка).
В-третьих, выявляются репозитории, требующие изменений в PR. Для оптимизации опыта разработки активно применяются стандартные инструменты OSS, многие из которых используют конфигурационные файлы для определения версии Python. Многие неявные версии, например, представленная на приведенном выше скриншоте “unspecific pre-commit version” (“неопределенная версия до коммита”), делаются явными, что способствует их обновлению. Чтобы избежать вышеупомянутой путаницы с несколькими версиями Python, каждый репозиторий настраивается на использование одной версии Python за раз с защитными механизмами, которые запускаются на каждом PR для проверки синхронизации всех конфигурационных файлов.
И наконец, автоматизация фактических шагов обновления для данного репозитория. Учитывая необходимость настройки множества репозиториев, команда BLT обладает внутренним инструментом для реализации столь масштабных изменений. По сути, этот инструмент делает следующее для каждого репозитория:
- создает локальную команду git checkout;
- запускает произвольную Python-функцию, называемую “fixer”, чтобы внести нужные изменения, например обновить зависимость;
- создает и отслеживает PR из этих изменений.
Примечательный факт: с помощью именно этого инструмента команда BLT реализовала вышеупомянутые защитные механизмы! Как только исправления завершены, они помечаются как “enforced” и запускаются в CI для предотвращения регрессий. Это означает, что защитные механизмы не просто выводят сообщение об ошибке, а действительно исправляют все проблемы и печатают diff для инженера, чтобы он мог применить его к своему PR.
У команды BLT есть функция fixer, выполняющая автообновление Python. Познакомимся с ним прямо сейчас!
Автообновление Python
Функция fixer, отвечающая за обновление Python, — самая сложная функция такого типа в Lyft, с более чем пятнадцатью компонентами (sub-fixers), которые разделяют логику на три группы для удобства тестирования:

Dependency Management (управление зависимостями). Как правило, самая сложная часть любого обновления связана не с изменениями в самом Python, а с обновлением зависимостей до последних версий, которые часто вносят собственные существенные изменения. Новые версии зависимостей необходимы, когда:
- библиотека публикует колеса (wheels) — старые версии не будут иметь колес для новых версий Python;
- библиотека требует изменения кода для новых версий Python, например если она взаимодействует с AST.
В итоге приходится обновлять почти все зависимости. Поскольку разрешение зависимостей может быть медленным, команда BLT создала простой сервис-обертку pip-tools. Он позволил сократить время разрешения p50 в ~50 раз (с 5–10 минут до 5–10 секунд) за счет использования общего кэша Redis! Поначалу он не только обеспечивал работу fixer, но и служил заманчивой целью для обновления: только репозитории, основанные на новой версии Python, могли использовать сервис ежедневно (помимо fixer).
Чтобы упростить поиск нужных версий для обновления, внутренний репозиторий пакетов был настроен так, чтобы в нем хранились только колеса для многих пакетов. Таким образом, старые версии, не имеющие колес для нового Python, полностью отсутствуют, поэтому CI может быстро выходить из строя вместо того, чтобы пытаться производить сборку из исходников (что обычно занимает много времени и приводит к неудаче). Помимо обновления зависимостей, набор sub-fixer’ов обновляет файлы конфигурации, чтобы использовать новую версию Python для разрешения зависимостей.
Linters (линтеры). Помимо потребности в обновлении, свойственной любой другой зависимости, линтеры являются мощными компонентами процесса обновления, которые автоматически переписывают код. Команда BLT использует (и вносит вклад в OSS) такие инструменты, как pyupgrade и reorder-python-imports, которые могут удалять устаревший код с обратной совместимостью, добавлять совместимость с форвардами и изменять логику для использования более новых API Python. У каждого линтера есть свой sub-fixer. Наличие умных функций редактирования кода в отдельных линтерах позволяет инженерам запускать их как часть обычного потока, в то время как каждый sub-fixer должен только управлять конфигурацией/версией линтера и запускать линтер для применения автоисправлений. Имеется также sub-fixer, использующий libCST для реализации очень простых изменений, для которых не стоит создавать целый линтер.
Build/Test/Run (сборка/тестирование/запуск). Остальные sub-fixer’ы занимаются обновлением конфигураций сборки, тестирования и запуска/развертывания, а также другими изменениями (например, обновлением версии, если исправляемый репозиторий является библиотекой). Две ключевые библиотеки — ruamel.yaml и ConfigUpdater — позволяют сохранять комментарии и избегать ложных изменений, связанных только с форматированием, при редактировании YAML- и setup.cfg-файлов соответственно, что очень ценят инженеры Lyft.
Фрактальное развертывание
Теоретически все просто: fixer запускается на cron, чтобы генерировать PR для всех репозиториев и поддерживать их в актуальном состоянии. При этом проводится работа с подразделением компании по слиянию кода. Однако есть несколько нюансов, заставляющих углубиться на несколько уровней!
Первый уровень. Команда BLT не выполняет все обновление в рамках одного PR! Обычно, прежде чем запустить основную функцию обновления fixer, запускаются по отдельности fixer’ы обновления зависимостей и линтера. Это сокращает диффы, увеличивая вероятность прохождения тестов и автослияния, а также упрощая отладку в случае неудачи (для полноты картины они также включены в основную функцию fixer).
Второй уровень. Невозможно объединить все PR сразу! В то время как обновления зависимостей и линтера обычно безопасно проходят автослияние в масштабах всего парка, фактическое обновление Python может привести к сбою. После тестирования с помощью ранних пользователей команда BLT совместно с подразделением “Инфраструктурные операции” работает над автослиянием сгенерированных PR по батчам, упорядоченным по уровню критичности для бизнеса (после чего они автоматически развертываются). Если PR касаются незначительных проблем, то проверяется, можно ли добавить исправление в автоматизацию. Если нет, исправляются PR подразделений, в которых затраты на информирование о необходимости исправления перевесят время, потраченное на самостоятельные исправления.
Третий уровень. Невозможно создать PR для всех репозиториев сразу! По сути, этот процесс осуществляется в три фазы:
- частичное обновление библиотек, обеспечивающее совместимость с новой версией, с новыми тестовыми наборами CI в качестве подтверждения;
- обновление сервисов, использующих эти библиотеки;
- обновление исходных библиотек для снятия совместимости с прежними версиями Python.
Эти три фазы накладываются друг на друга, поскольку команда BLT обладает детализированными данными из упомянутого выше набора данных графа зависимостей. По сути дела, cron будет отмечать сервисы и библиотеки, подходящие для обновления (и генерировать PR), как только конкретные зависимости/потребители будут обновлены.
Хотя большинство репозиториев можно полностью обновить автоматически, некоторые из них всегда требуют человеческого вмешательства. После того как автоматика сделает все, что в ее силах, команда BLT отправляет задания JIRA отдельным подразделениям, чтобы отследить оставшуюся работу. В большинстве случаев им нужно внести всего несколько исправлений в автоматически сгенерированный PR.
На протяжении процесса обновления команда BLT отправляет ежемесячные письма с обновлениями, чтобы поделиться информацией о прогрессе, и через Slack-каналы осуществляет поддержку подразделений, испытывающих сложности в обновлении. Кроме того, добавляются новые функции, которые будут работать только с новыми версиями Python. В качестве дополнительного стимула обновлений, например, добавляется возможность окрашивания вывода тестирования/линтинга в CI и более быстрое локальное обновление venv.
Заключение
Специалисты BLT, постоянно обновляющие 1500+ репозиториев, никогда не сталкивались с серьезными проблемами благодаря безупречному состоянию CI и среды Staging (единственный минус — меньше забавных историй об инцидентах). Обновление Python становится быстрее с каждым разом — от нескольких лет до сегодняшних нескольких месяцев. И это на фоне других крупных инициатив, таких как переход на k8s и ARM; перестройка процессов разработки до полной локализации, изменение общих бизнес-направлений, рефакторинг сборок и т. д.
Следует подчеркнуть, что команда BLT всегда достигает своих основных целей: разработчики получают доступ к новейшим библиотекам и функциональности, а Lyft остается востребованным и безопасным сервисом, постоянно повышающим экономическую эффективность хостинга.
Проделанная специалистами BLT работа принесла и другие преимущества: стандартизация ускорила общий процесс разработки, а созданные наборы данных широко используются для отслеживания проектов и специальных исследований. В будущем намечается работа по созданию многоразового инструментария для всей инфраструктуры, который позволит отслеживать каждое обновление и внедрение лучших практик.
Технология обновления Python — одна из успешных практик команды Lyft BLT. Надеемся, она подойдет и вам!
Читайте также:
- Эти декораторы Python позволят сократить код вдвое
- 8 причин использовать Pydantic для улучшения парсинга и валидации данных
- Сравниваем целочисленное и линейное программирование в Python
Читайте нас в Telegram, VK и Дзен
Перевод статьи Aneesh Agrawal: Python Upgrade Playbook




