
На днях LLM (Large Language Model — большая языковая модель) помогла объяснить моему 4-летнему ребенку, что такое векторы. За считанные секунды она выдала историю, наполненную мифическими существами, магией и векторами. У меня был готов набросок для новой детской книги. И он был впечатляющим, потому что единорог назывался “LuminaVec” (можно перевести как “СветоВектор” или “Сияющий Вектор”).

Как же модель помогла сотворить это чудо? Секрет креативности LLM заключается в использовании векторов (в реальной жизни) и, скорее всего, векторных баз данных. Как именно? Сейчас объясню.
Векторы и эмбеддинг
Начнем с того, что модель не понимает, какие именно слова я ввожу. Понять слова ей помогают их числовые представления в виде векторов. С помощью этих векторов модель находит сходство между различными словами, фокусируясь на значимой информации о каждом из них. Для этого используются эмбеддинги — низкоразмерные векторы, передающие семантику и контекст информации.
Другими словами, векторы в эмбеддинге — это списки чисел, которые определяют положение объекта в модельном пространстве. Такими объектами могут быть признаки, определяющие переменную в наборе данных. С помощью числовых значений векторов можно определить, насколько близко или далеко один признак находится от другого — похожи они (близки) или не похожи (далеки)?
Векторы чрезвычайно полезны, но, когда речь заходит о большой языковой модели, нужно быть особенно осторожными с ними — из-за слова “большой”. Как часто случается с этими “большими” моделями, векторы могут быстро стать длинными и сложными, охватывая сотни или даже тысячи измерений. Если не принять меры, скорость обработки и затраты на конструирование могут очень быстро стать обременительными!
Векторные базы данных
Решить эту проблему помогают “могучие воины” — векторные базы данных.
Векторные базы данных — это специальные базы данных, которые содержат векторные эмбеддинги. В векторной базе данных похожие объекты имеют векторы, расположенные ближе друг к другу, а непохожие — векторы, расположенные дальше друг от друга. Таким образом, вместо парсинга данных при каждом запросе и генерации векторных эмбеддингов, что требует огромных ресурсов, можно гораздо быстрее один раз прогнать данные через модель, сохранить их в векторной базе данных и извлекать по мере необходимости. Это делает векторные базы данных одним из самых эффективных решений проблемы масштабирования и скорости обработки данных в LLM.
Теперь вернемся к истории о радужном единороге, сверкающей магии и мощных векторах. Получив мой запрос, модель проделала примерно следующее:
- преобразовала вопрос в векторный эмбеддинг;
- сравнила векторный эмбеддинг с эмбеддингами в базе (базах) данных векторов, связанной (связанными) с веселыми историями для 4–5-летних детей и векторами;
- на основе этого поиска и сравнения возвратила векторы, которые были наиболее похожи;
- результат состоял из списка векторов, расположенных в порядке их сходства с вектором запроса.
Как это на самом деле работает?
Предлагаю отправиться в исследовательское путешествие и разобраться в нюансах. Настало время обратиться к основам! В этом нам поможет публикация профессора Тома Йеха, которая объясняет закулисную работу векторов и векторных баз данных. Все изображения ниже, если не указано иное, принадлежат профессору Тому Йеху из вышеупомянутого поста на LinkedIn, отредактированного мной с его разрешения.
Для примера возьмем набор данных из 3 предложений, в каждом из которых по 3 слова (или токена):
- How are you? (Как ты?);
- Who are you? (Кто ты?);
- Who am I? (Кто я?).
Наш запрос — предложение “Am I you?” (“Я — это ты?”).

В реальной жизни база данных может содержать миллиарды предложений (вспомните Википедию, архивы новостей, журнальные статьи или любое собрание документов) с десятками тысяч токенов. Теперь, когда сцена подготовлена, приступим к процессу.
1. Эмбеддинг (Embedding). На первом этапе будем создавать векторные эмбеддинги для всего используемого текста. Для этого ищем соответствующие слова в таблице из 22 векторов, где 22 — объем словаря для взятого примера.
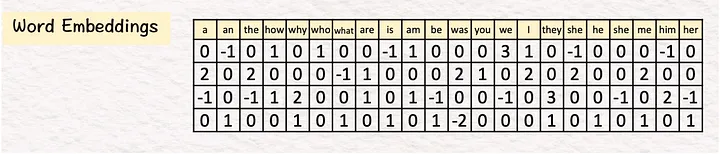
В реальной жизни объем словаря может составлять десятки тысяч. Размеры эмбеддингов слов исчисляются тысячами (например, 1024, 4096).
Эмбеддинги для слов how are you при поиске в словаре выглядят следующим образом:
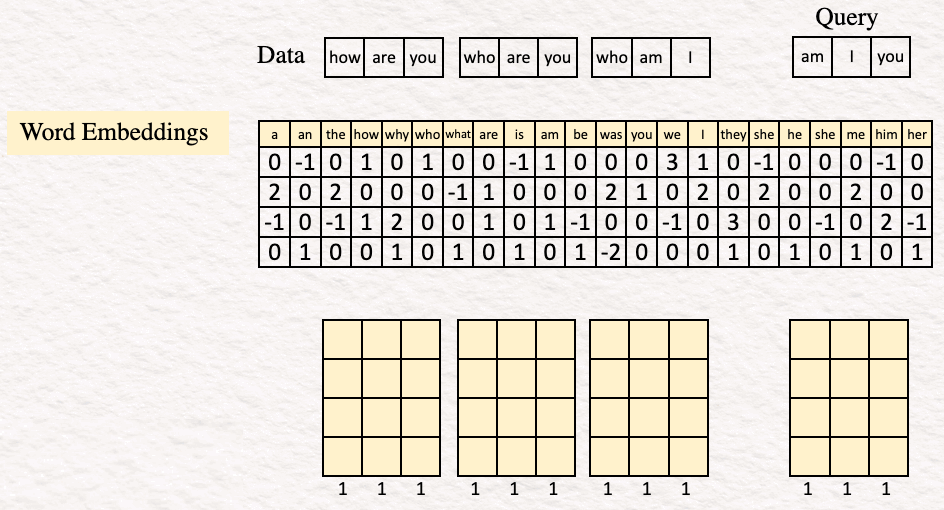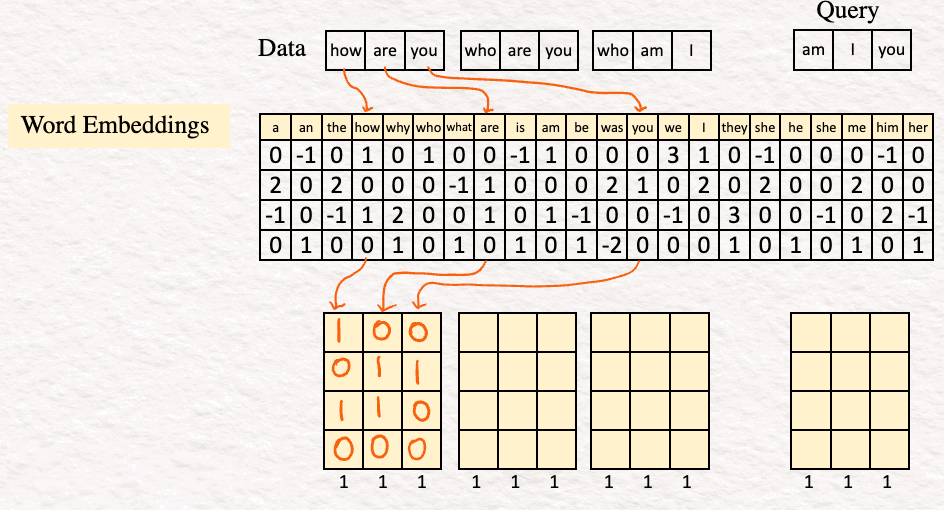
2. Кодирование (Encoding). Следующим шагом будет кодирование эмбеддингов слов для получения последовательности признаковых описаний, по одному на слово. В нашем примере кодировщик представляет собой простой перцептрон, состоящий из линейного слоя с функцией активации ReLU.
Краткое описание:
- Линейное преобразование: входной эмбеддинговый вектор умножается на весовую матрицу W, а затем складывается с вектором смещения b;
- z = Wx+b, где W — весовая матрица, x — эмбеддинг слова, а b — вектор смещения;
- функция активации ReLU: применяем ReLU к этому промежуточному z;
- ReLU возвращает поэлементный максимум входных данных и нуля. Математически, h = max{0,z}.
В нашем случае эмбеддинг текста будет выглядеть следующим образом:
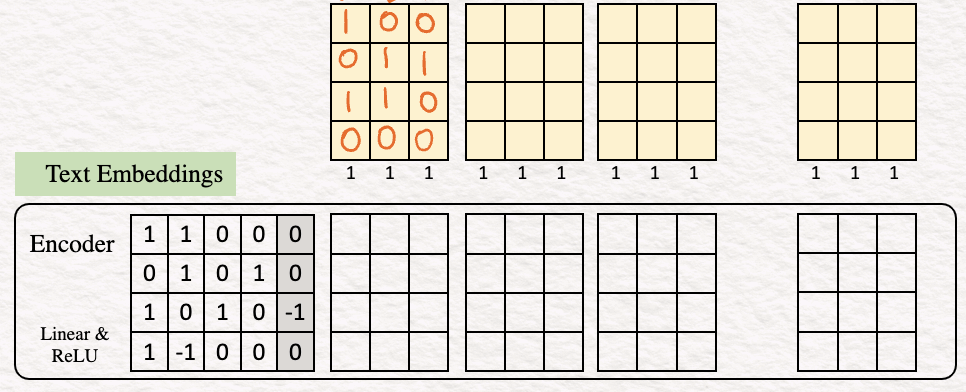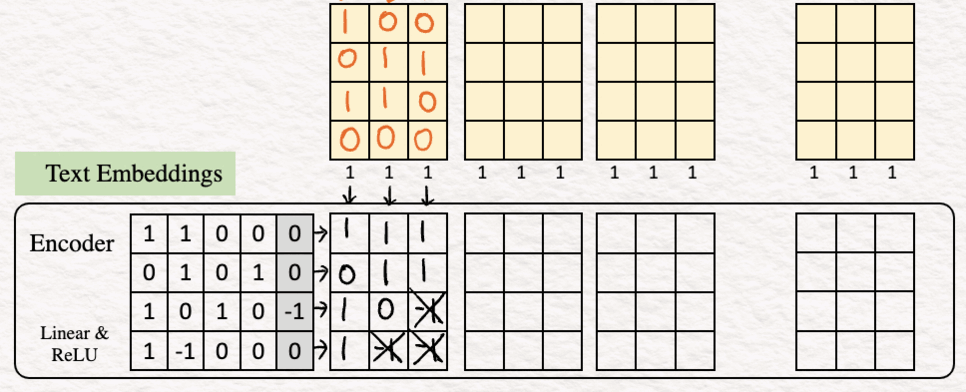
Чтобы представить, как это работает, в качестве примера вычислим значения для последнего столбца.
Линейное преобразование:
[1.0 + 1.1 + 0.0 +0.0] + 0 = 1
[0.0 + 1.1 + 0.0 + 1.0] + 0 = 1
[1.0 + (0).1+ 1.0 + 0.0] + (-1) = -1
[1.0 + (-1).1+ 0.0 + 0.0] + 0 = -1
ReLU
max {0,1} =1
max {0,1} = 1
max {0,-1} = 0
max {0,-1} = 0
Таким образом, получаем последний столбец признакового описания. Можете повторить те же шаги для других столбцов.
3. Объединение средних значений (Mean Pooling). На этом этапе объединяем признаковые описания путем усреднения по столбцам, чтобы получить единый вектор. Это часто называют эмбеддингом текста или эмбеддингом предложений.
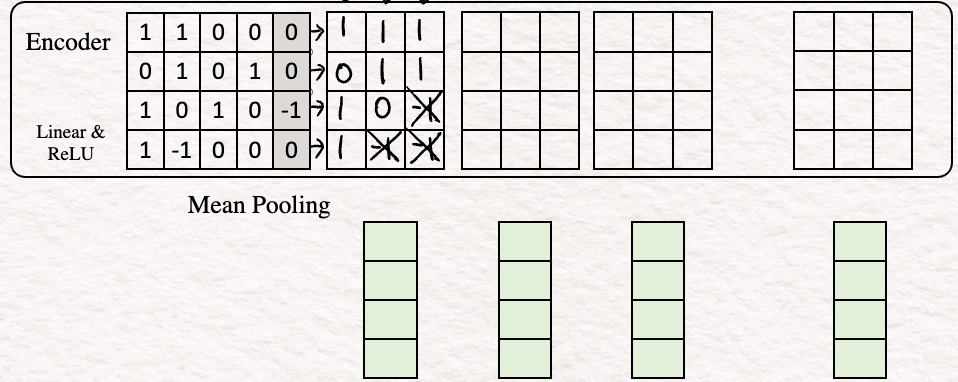
Могут использоваться и другие методы объединения, такие как CLS, SEP, но наиболее широко применяется метод объединения средних значений.
4. Индексирование (Indexing). На этом этапе необходимо уменьшить размерность вектора эмбеддинга текста, что делается с помощью матрицы проекций. Эта матрица проекций может быть случайной. Идея состоит в том, чтобы получить краткое представление, которое позволит быстрее сравнивать и извлекать информацию.
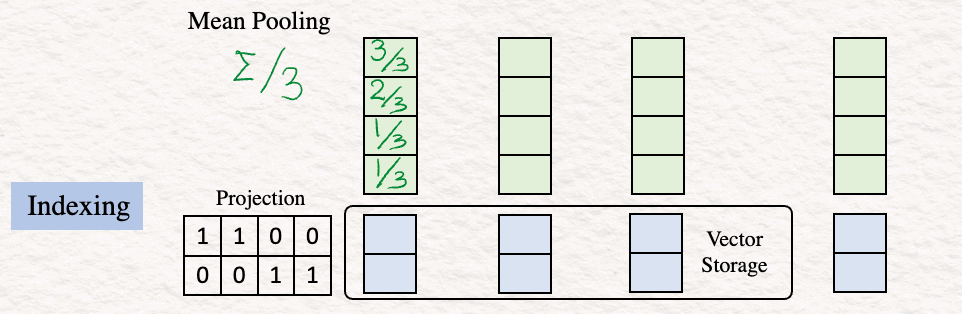
Этот результат сохраняется в векторном хранилище (Vector Storage).
5. Повтор (Repeat). Описанные выше шаги [1]-[4] повторяются для двух других предложений из набора данных: “Who are you?” (“Кто ты?”) и “Who am I?” (“Кто я?”).
Теперь, проиндексировав набор данных в векторной базе данных, переходим к реальному запросу и смотрим, как эти индексы работают для выдачи решения.
Запрос : “Am I you?” (“Я — это ты?”).
6. Для начала повторяем те же шаги, что и выше (эмбеддинг, кодирование и индексирование), чтобы получить 2d-векторное представление запроса.
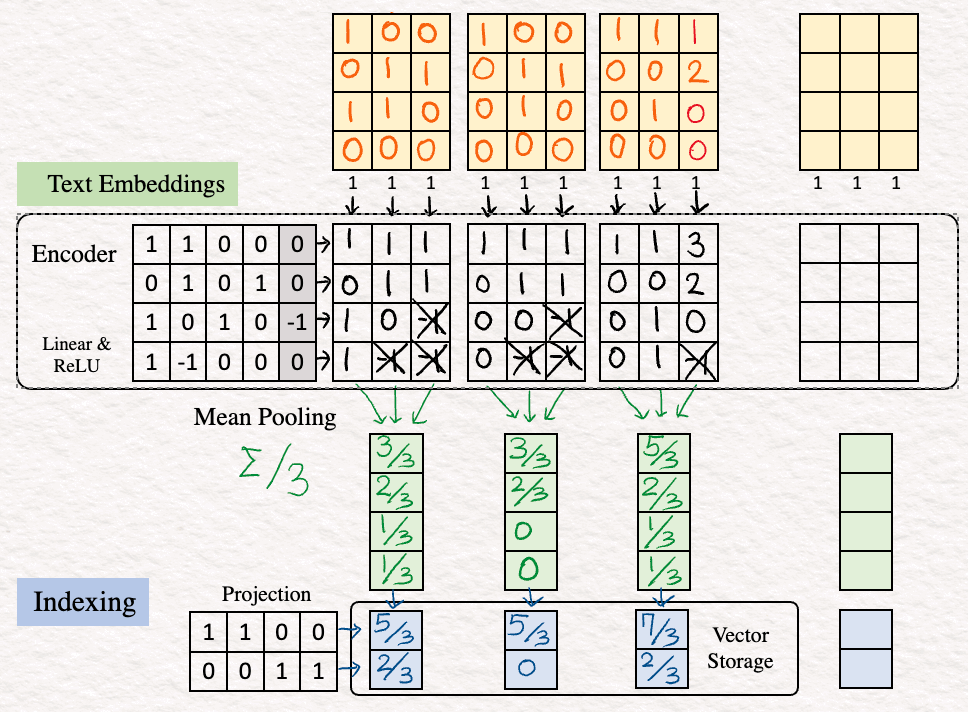
7. Скалярное произведение (Dot Product) — поиск сходства. После выполнения предыдущих шагов выполняем скалярное произведение. Это очень важно, так как скалярное произведение позволяет сравнить вектор запроса с векторами базы данных. Чтобы выполнить этот шаг, транспонируем вектор запроса и перемножаем его с векторами базы данных.
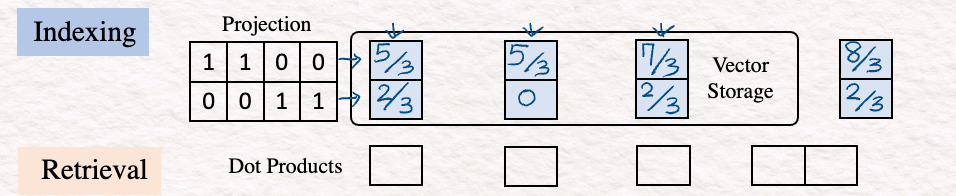
8. Ближайший сосед (Nearest Neighbor). Последний шаг — линейное сканирование для поиска наибольшего скалярного произведения, которое для нашего примера равно 60/9. Это и есть векторное представление для “Who am I?” (“Кто я?”). В реальной жизни линейное сканирование может быть невероятно медленным, так как подчас включает миллиарды значений. Поэтому альтернативой является использование алгоритмов ANN (Approximate Nearest Neighbor — приблизительный поиск ближайшего соседа), например HNSW (Hierarchical Navigable Small Worlds — иерархический маленький/тесный мир).

На этом наша самостоятельная работа с векторами, не лишенная элегантности, завершается.
Таким образом, используя векторные эмбеддинги наборов данных в векторной базе данных и выполнив описанные выше этапы, мы нашли предложение, наиболее близкое к данному запросу. Эмбеддинг, кодирование, объединение средних значений, индексирование, а затем вычисление скалярного произведения составляют основу этого процесса.
Расширим картину
Стоит еще раз обратить внимание на ситуацию в ее истинном масштабе:
- Набор данных может содержать миллионы или миллиарды предложений.
- Количество токенов в каждом из них может доходить до десятков тысяч.
- Размеры эмбеддингов слов могут исчисляться тысячами.
Если свести все эти данные и процессы вместе, то придется выполнять операции с величинами, подобными по размеру мамонту. Справиться с этими грандиозными масштабами помогают векторные базы данных. Раз уж мы начали эту статью с разговора о LLM, уместно будет сказать: благодаря своей способности справляться с масштабной работой, векторные базы данных стали играть важную роль в RAG (Retrieval Augmented Generation — генерация ответа, дополненная результатами поиска). Масштабируемость и скорость, предлагаемые векторными базами данных, обеспечивают эффективный поиск для RAG-моделей, тем самым прокладывая путь высокопроизводительным генеративным моделям.
В общем, можно с полным правом сказать, что векторные базы данных — это мощный инструмент. Неудивительно, что они уже давно находят применение: начав свой путь с помощи рекомендательным системам, сегодня они служат основой для LLM и продолжают удерживать свое господство. А учитывая темпы развития векторных эмбеддингов в различных модальностях ИИ (текстах, изображениях, аудио, видео), похоже, что лидирующее положение векторных баз данных продлится еще долгое время!
P.S. Если хотите сами поэкспериментировать, вот ссылка на пустой шаблон для самостоятельных упражнений.
Читайте также:
- Использование LLM в реальном мире
- ExLlamaV2: самая быстрая библиотека для работы с LLM
- Промпт-инжиниринг: как использовать LLM для создания приложений
Читайте нас в Telegram, VK и Дзен
Перевод статьи Srijanie Dey, PhD: Deep Dive into Vector Databases by Hand ✍︎





