
Продвинутые стратегии RAG позволяют повысить производительность процесса извлечения данных в RAG-конвейере.
Стандартный RAG-конвейер использует один и тот же чанк (фрагмент) текста для эмбеддинга и синтеза. Проблема этого подхода заключается в том, что извлечение данных на основе эмбеддинга эффективно при работе с небольшими чанками, в то время как LLM требуется больше контекста и более объемных чанков для получения удовлетворительного ответа.
В этом руководстве рассмотрим два продвинутых метода извлечения информации.
Извлечение данных в окне предложений
Метод извлечения данных в окне предложений (Sentence Window Retrieval) предполагает первоначальное извлечение данных из небольших предложений (что обеспечивает большее соответствие релевантному контексту) с последующим расширением контекстного окна предложения.
Сначала обрабатываются небольшие чанки или предложения с сохранением в векторной базе данных. Затем добавляется контекст предложений, которые встречаются до и после каждого чанка.
В процессе извлечения информации с помощью поиска по сходству отбираются предложения, которые в большей степени соответствуют вопросу, после чего заменяются всем окружающим контекстом. Это позволяет расширить контекст, передаваемый LLM.
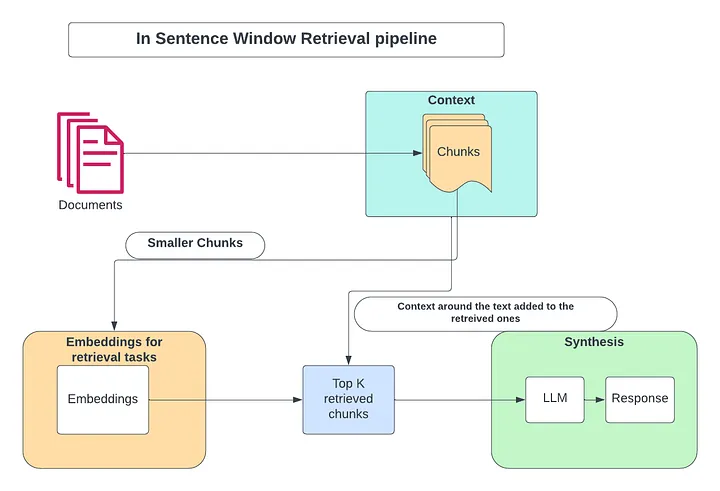
Посмотрим, как настроить извлечение данных в окне предложений в ноутбуке Colab.
Использование этого ноутбука предполагает, что вы выполнили все предварительные требования, упомянутые в первой части и необходимые для этой настройки.
Шаг 1. Импортируем модель Gemini Pro:
from llama_index.llms import Gemini
llm = Gemini(model="models/gemini-pro", temperature=0.1)
Шаг 2. Настроим документ, который уже был использован в первой части. Кроме того, подадим PDF-файл, разобьем его на чанки, создадим эмбеддинги с помощью модели и индексируем с использованием индекса извлечения данных в окне предложений (Sentence Window Retrieval Index).
from llama_index import SimpleDirectoryReader
documents = SimpleDirectoryReader(
input_files=["./eBook-How-to-Build-a-Career-in-AI.pdf"]
).load_data()
print(type(documents), "\n")
print(len(documents), "\n")
print(type(documents[0]))
print(documents[0])
Объединим 41 PDF-страницу в единый документ для обеспечения точности разделения текста при использовании продвинутых методов извлечения данных.
from llama_index import Document
document = Document(text="\n\n".join([doc.text for doc in documents]))
Шаг 3. Создадим индекс, используя индекс окна предложений для данного документа. Нам необходимо определить LLM и эмбеддинг-модель.
Примечание: будем использовать эмбеддинг-модель HuggingFace.
Для создания индекса окна предложений применим вспомогательные функции из файла utils, находящегося в репозитории.
from utils import build_sentence_window_index
sentence_index = build_sentence_window_index(
document,
llm,
embed_model="local:BAAI/bge-small-en-v1.5",
save_dir="sentence_index"
)
Шаг 4. Получим механизм выполнения запросов из индекса окна предложений.
from utils import get_sentence_window_query_engine
sentence_window_engine = get_sentence_window_query_engine(sentence_index)
Шаг 5. Теперь выполним базовый запрос к модели, чтобы проверить, выполняется ли индексация должным образом.
window_response = sentence_window_engine.query(
"how do I get started on a personal project in AI?"
)
print(str(window_response))
Шаг 6. Сравним полученные результаты с TruLens, как делали это с базовым RAG-пайплайном. Импортируем предварительно созданный регистратор TruLens для извлечения данных в окне предложений.
from utils import get_prebuilt_trulens_recorder
tru_recorder_sentence_window = get_prebuilt_trulens_recorder(
sentence_window_engine,
app_id = "Sentence Window Query Engine"
)
Шаг 7. Теперь проведем бенчмаркинг набора оценочных вопросов, как в части 1. Запустим извлечение данных в окне предложений на основе этих оценочных вопросов и сравним эффективность триады метрик RAG.
with tru_recorder_sentence_window as recording:
for question in eval_questions:
response = sentence_window_engine.query(question)
Шаг 8. Запустим запрос для tru-таблицы лидеров с идентификаторами приложений и увидим результаты по обоим приложениям. Механизм обработки прямых запросов (Direct Query Engine, базовый RAG) и механизм обработки запросов к окну предложений (Sentence Window Query Engine, продвинутый RAG, вариант 1).
tru.get_leaderboard(app_ids=[])

Извлечение с автослиянием чанков
Еще одна проблема, связанная с базовым подходом, заключается в следующем. Вы извлекаете немного фрагментированных контекстов из чанков, чтобы разместить их в контекстном окне LLM, но при уменьшении размера чанков фрагментация усиливается. Например, вы можете получить два или более контекста из чанков, расположенных в одном разделе, однако нет никаких гарантий в отношении порядка следования этих чанков.
Это может повлиять на способность LLM синтезировать информацию по извлеченному контексту в пределах контекстного окна.
Вот как решает эту проблему извлечение с автослиянием чанков (auto-merging retrieval):
- Сначала определяется иерархия меньших чанков, связанных с родительскими чанками.
- Если набор меньших чанков, связанных с родительским чанком, превышает некий порог, тогда происходит “вливание” меньших чанков в больший родительский чанк. Таким образом, извлекается более крупный родительский чанк для предоставления LLM более целостного контекста.
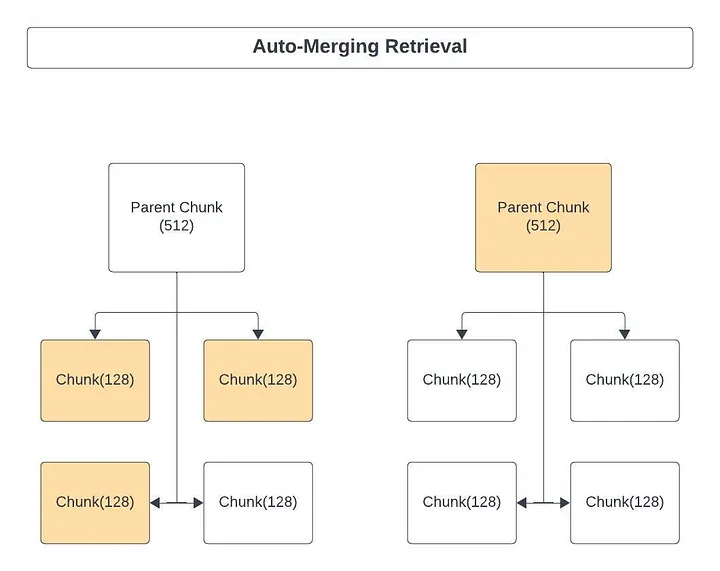
Посмотрим, как настроить извлечение с автослиянием чанков в ноутбуке Colab.
Для этой настройки вы должны выполнить все предварительные требования, упомянутые в части 1.
Настроим ноутбук для извлечения с автослиянием чанков, а затем с помощью TruLens сравним показатели производительности.
Шаг 1. Как и в случае других ноутбуков, импортируем модель Gemini.
import warnings
warnings.filterwarnings('ignore')
from llama_index.llms import Gemini
llm = Gemini(model="models/gemini-pro", temperature=0.1)
Шаг 2. Теперь создаем документ, который использовали в части 1. Загружаем PDF-файл, разбиваем его на чанки, создаем эмбеддинги, используя модель, и индексируем с помощью Automerging Retrieval Index (индекса извлечения с автослиянием чанков).
Примечание: как упоминалось в части 1, вы можете протестировать этот подход, загрузив свой PDF-файл на следующем шаге.
from llama_index import SimpleDirectoryReader
documents = SimpleDirectoryReader(
input_files=["./eBook-How-to-Build-a-Career-in-AI.pdf"]
).load_data()
print(type(documents), "\n")
print(len(documents), "\n")
print(type(documents[0]))
print(documents[0])
Шаг 3. Объединяем 41 PDF-страницу в единый документ для обеспечения точности разделения текста при использовании продвинутых методов извлечения данных.
from llama_index import Document
document = Document(text="\n\n".join([doc.text for doc in documents]))
Следующие шаги будут направлены на определение ретривера автослияния (части системы, которая отвечает за поиск и извлечение информации).
Шаг 4. Определяем парсер иерархических узлов.
Чтобы использовать ретривер автослияния, нужно иерархически спарсить узлы (родительские и дочерние). Узлы парсятся по убыванию размера и содержат связи с родительскими узлами.
В результате был создан node_parser (парсер иерархических узлов) с тремя размерами чанков. Вы можете изменить размер чанков в зависимости от своих потребностей. Здесь использовано уменьшение размера чанка в 4 раза.
from llama_index.node_parser import HierarchicalNodeParser
# создание парсера иерархических услов с настройками по умолчанию
node_parser = HierarchicalNodeParser.from_defaults(
chunk_sizes=[2048, 512, 128]
)
Шаг 5. Этот код возвращает все конечные (листовые), промежуточные и родительские узлы документа. Информация между конечными, родительскими и промежуточными узлами будет пересекаться.
nodes = node_parser.get_nodes_from_documents([document])
Шаг 6. Если нас интересуют только конечные узлы, можем получить их с помощью функции “get_leaf_nodes”.
from llama_index.node_parser import get_leaf_nodes
leaf_nodes = get_leaf_nodes(nodes)
print(leaf_nodes[30].text)
Шаг 7. Исследуем отношения между родительским и конечным узлами путем вывода родительского узла. Один родительский узел содержит 512 токенов [4 конечных узла]; один конечный узел содержит 128 токенов.
nodes_by_id = {node.node_id: node for node in nodes}
parent_node = nodes_by_id[leaf_nodes[30].parent_node.node_id]
print(parent_node.text)
Шаг 8. Определив иерархию узлов, перейдем к созданию индекса для ретривера автослияния.
Будем использовать Gemini Pro в качестве LLM и HuggingFace bag-small в качестве эмбеддинг-модели. Упаковываем всю эту информацию в объект контекста сервиса, который содержит LLM, эмбеддинг-модель и парсер иерархических узлов.
from llama_index import ServiceContext
from llama_index.llms import Gemini
llm = Gemini(model="gemini-pro", temperature=0.1)
auto_merging_context = ServiceContext.from_defaults(
llm=llm,
embed_model="local:BAAI/bge-small-en-v1.5",
node_parser=node_parser,
)
Шаг 9. Создание индекса для ретривера автослияния.
Создадим VectorIndex специально для конечных узлов используемых документов. Все остальные узлы будут храниться как объект контекста хранения в хранилище документов (in-memory) и извлекаться динамически по мере необходимости при последующих запросах к индексу.
Изначально выбираем Top-K (конечные узлы, которые встраиваем с помощью модели эмбеддинга).
В индекс VectorStore передаем storage_context и service_context.
Storage_context содержит информацию об узлах (родительских и промежуточных), а service_context знает, какие LLM, эмбеддинг-модель и парсер использовать для создания индекса на конечных узлах. Сохраняем этот индекс на диске.
from llama_index import VectorStoreIndex, StorageContext
from llama_index import set_global_service_context
set_global_service_context(auto_merging_context)
storage_context = StorageContext.from_defaults()
storage_context.docstore.add_documents(nodes)
automerging_index = VectorStoreIndex(
leaf_nodes, storage_context=storage_context, service_context=auto_merging_context
)
automerging_index.storage_context.persist(persist_dir="./merging_index")
Шаг 10. Настраиваем ретривер и запускаем механизм выполнения запросов.
Примечание: если для запроса будет извлечено большинство дочерних узлов, они будут заменены родительским узлом.
Для эффективной работы ретривера автослияния задаем большое значение Top-K для конечных узлов [128 токенов]. Применяем модель повторного ранжирования после слияния, чтобы уменьшить использование токенов.
Например, можно получить топ-12 результатов, объединить их и получить топ-10, а затем с помощью повторного ранжирования довести это количество до топ-6.
Топ-N для извлечения кажется больше, но, как видите, базовый размер конечного узла составляет всего 128 токенов, а родителя — 512 токенов.
Шаг 11. Объединяем ретривер автослияния и модуль повторного ранжирования и создаем механизм автослияния для работы с запросами.
from llama_index.indices.postprocessor import SentenceTransformerRerank
from llama_index.retrievers import AutoMergingRetriever
from llama_index.query_engine import RetrieverQueryEngine
from llama_index.llms import Gemini
automerging_retriever = automerging_index.as_retriever(
similarity_top_k=12
)
retriever = AutoMergingRetriever(
automerging_index.service_context,
automerging_retriever,
automerging_index.storage_context,
verbose=True
)
rerank = SentenceTransformerRerank(top_n=6, model="BAAI/bge-reranker-base")
auto_merging_engine = RetrieverQueryEngine.from_args(
automerging_retriever, node_postprocessors=[rerank], verbose=True
)
Шаг 12. Протестируем оценочные вопросы с помощью созданного механизма обработки запросов.
auto_merging_response = auto_merging_engine.query(
"How to I build a portfolio of AI projects??"
)
print(str(auto_merging_response))
Шаг 13. Импортируем регистратор TruLens из модуля utils, как показано в части 1.
from utils import get_prebuilt_trulens_recorder
tru_recorder_automerging = get_prebuilt_trulens_recorder(auto_merging_engine,
app_id="Automerging Query Engine")
Шаг 14. Проведем бенчмаркинг набора оценочных вопросов, как и в части 1. Теперь запустим ретривер автослияния в отношении этих оценочных вопросов и сравним производительность по триаде метрик RAG.
for question in eval_questions:
with tru_recorder_automerging as recording:
response = auto_merging_engine.query(question)
Шаг 15. При запросе идентификаторов приложений таблицы лидеров tru можно увидеть результаты для всех трех приложений. Direct Query Engine (базовый RAG), Sentence Window Query Engine (1-й вариант продвинутого RAG) и Automerging Query Engine (2-й вариант продвинутого RAG).
tru.get_leaderboard(app_ids=[])

Читайте также:
- Паттерны проектирования генеративного ИИ: полное руководство
- Продвинутая генерация ответа, дополненная результатами поиска (RAG): от теории до реализации на LlamaIndex
- Как создать Android-приложение чат-бота с генеративным ИИ Google
Читайте нас в Telegram, VK и Дзен
Перевод статьи Ishmeet Mehta: Building and Evaluating Basic and Advanced RAG Applications with LlamaIndex and Gemini-pro in Google Cloud — Part 2


 сэкономить 1000 строк кода")


