
Если вы когда-либо работали в корпоративном SOC (security operations center — центр обеспечения безопасности), то наверняка слышали вопрос:
Сколько правил детекции развернуто в настоящее время? [Метрик].
Это вполне резонный вопрос, особенно если он исходит от руководителей служб кибербезопасности или спонсоров проектов.
Он не только служит отправной точкой для обсуждения количества и качества детекции, но и позволяет понять, насколько далеко продвинулась команда в плане пропускной способности (производительности).
Однако эта метрика может стать самым быстрым путем к усталости от сигналов тревоги, поскольку предполагает больше обнаружений сигналов тревоги вместо повышения их качества.
Многие аспекты, затронутые в этой статье, связаны с запросами или обсуждениями, с которыми я сталкиваюсь как независимый консультант по безопасности.
Но прежде чем перейти к ним, рассмотрим несколько проблем, связанных с практикой разработки средств детекции и аналитики безопасности. Надеюсь, это поможет вам немного иначе отнестись к вопросам обеспечения безопасности.
“Ползучесть” кейсов детекции
При управлении проектами бывает сложно справиться со спросом на новые функции или изменения. Помимо всего прочего, он возрастает до такой степени, что качество выполнения начинает заметно и значительно снижаться.
Это явление известно как неконтролируемое расширение рамок проекта, или “ползучесть” кейса.
Определенный уровень “ползучести” испытывает большинство команд корпоративных SOC после внедрения сотен правил детекции и до интеграции SOAR (технологии получения данных из различных SIEM — систем управления информационной безопасностью) либо найма армии аналитиков (или ботов).
Как думаете, можно гарантировать непрерывную доставку данных без надлежащего управления кейсами детекции и процессов обеспечения качества?
Разработка средств детекции вращается вокруг непрерывной доставки данных. По мере доступности новых данных, готовых к использованию, бэклог разработки (список задач и требований) пересматривается.
Мусор на входе — мусор на выходе (это не так)
Если вы достаточно давно занимаетесь SIEM, то наверняка сталкивались с этим утверждением.
Идея заключается в том, что при получении некачественных данных оповещения тоже будут некачественными. Однако это не совсем так.
Источники данных и журналы будут постоянно расширяться. Предполагается, что данные, независимо от того, много ли в них обнаружений и проходят ли они какую-либо обработку, в конечном итоге попадут в SIEM. Это факт.
Обратите внимание: хотя сбор, извлечение и преобразование данных — часто называемые дата-инжинирингом — очень важны, кто-то должен осмыслить эти данные и, возможно, сгенерировать из них сигналы тревоги.
Реальность такова, что разработчики средств детекции должны полностью владеть последним процессом независимо от объема и качества данных! И вот тут-то фраза “мусор на входе/мусор на выходе” начинает терять смысл.
Мусорные данные будут существовать всегда.
Хотя желательно отфильтровать шум как можно раньше, невозможно исключить его на этапе детекции. Данные не виноваты в некачественных оповещениях.
Логика детекции и аналитика (правило, модель) в конечном итоге будут отвечать за генерацию сигналов тревоги, которые попадут к SOC-аналитику. Он — главный привратник (контролер входящей информации).
Если данные не готовы к использованию, это должно быть помечено и задокументировано. Нельзя генерировать оповещения ради оповещений — слишком высоки затраты на них.
Усталость от сигналов тревоги как симптом
Если вы занимаетесь отслеживанием инженерно-технических метрик, то должны знать, что количество активных правил — еще одна из них.
Хочу обратить ваше внимание на следующий факт: поскольку большинство метрик сосредоточено на отслеживании объема и рабочей нагрузки, может показаться очевидным, что необходимо сосредоточить усилия на снижении объемов сигналов тревоги.
Это порождает всевозможные задачи — начиная от разработки сложных плейбуков (сценариев реагирования) SOAR, которые в определенный момент просто автоматически закрывают сигналы тревоги, и заканчивая тонкой настройкой логики, которая практически глушит подавляющее большинство сигналов тревоги в соответствии с правилами.
Коренная причина
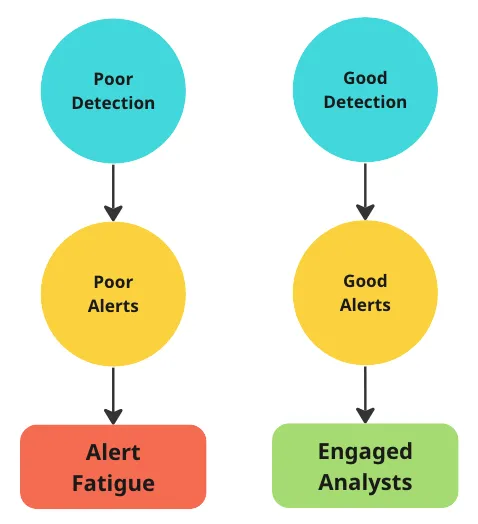
Некачественные сигналы возникают из-за некачественной детекции.
Если вам ежедневно приходится добавлять в правила исключения, скорее всего, вы имеете дело с непродуманной системой детекции!
Аналогичным образом, если вам постоянно приходится корректировать плейбук SOAR из-за модели детекции, которая за годы работы не дала ни одного положительного результата, это, скорее всего, еще один пример плохо разработанного кейса.
Все ли дело в правильном выборе идеи и разработке эффективного кода детекции?
Тщательно продуманный процесс управления системами детекции, включающий курирование бэклога и тестирование/рецензирование готовых продуктов, — ключ к тому, чтобы не запустить в производство еще одно малозначимое и трудно обслуживаемое средство детекции.
Попробуйте измерить количество изменений или работ по тонкой настройке, примененных к правилу, отследить его до автора источника/продукта и понять, как вы к этому пришли.
Возникает вопрос: правильно ли мы делаем, пытаясь устранить усталость от сигналов тревоги?
Пока организации не поймут основных причин усталости от сигналов тревоги, они будут продолжать инвестировать в неподходящие решения, основанные на текущем понимании проблемы.
Это касается как SOAR, так и продуктов для автоматизации и постдетекторной обработки.
Целевая задача
В чем назначение детекции угроз и мониторинга для обеспечения безопасности?
Их целевая задача заключается в непрерывном выявлении и анализе подозрительных действий, потенциально указывающих на угрозу безопасности или нарушение.
Кто-то может возразить, утверждая, что если уменьшить объем оповещений, то освободится больше времени для надлежащей сортировки и анализа.
На самом деле после нескольких дней сортировки повторяющихся сигналов тревоги SOC-аналитик уже знает, на какие из них ему следует обратить внимание, включая, скорее всего, все редко обнаруживаемые сигналы.
Чтобы не пропустить сильный сигнал в океане оповещений, необходимо разрабатывать эффективные средства детекции, а не исправлять неэффективные в постдетекторном конвейере.
Эффективные средства детекции должны генерировать управляемый объем оповещений. К сожалению, реальность для большинства команд далека от этого.
Тонкая настройка выполняется в основном для того, чтобы не нарушить соглашения об уровне обслуживания (MSSP/MDR) или не исказить отчеты по поведению клиентов и мониторингу безопасности.
Выдвижение гипотезы
Предположим, что объем сигналов тревоги всегда имеет тенденцию к увеличению, как это происходит с источниками данных и журналами. Тогда следует подчеркнуть важность качества, на время отбросив количественные характеристики.
Слишком много хороших сигналов тревоги — это “проблема”, которую хочет иметь каждая команда SOC, хотя сомневаюсь, что данный кейс для большинства. Будет ли это по-прежнему вызывать усталость от сигналов тревоги?
А как насчет качества данных? Насколько оно важно? Оно определенно поможет! Однако при некачественной детекции и основанной на ней аналитики безопасности результаты в конечном итоге не сильно изменятся. Согласны?
Может ли ИИ покончить с усталостью от сигналов тревоги?
Возможно, это не самая удачная формулировка вопроса.
Спрошу иначе: как использовать искусственный интеллект (ИИ) и машинное обучение (МО) для создания насыщенных контекстом, высокоточных сигналов тревоги с интуитивно понятными интерфейсами сортировки и анализа, с которыми работает SOC?
Хотя о ценности детекции можно судить только после надлежащей сортировки и анализа, легко заметить следующее: каким бы качественным и автоматизированным ни был исследовательский процесс, низкий уровень аналитики неизбежно снизит его ценность.
Проблема не в пропуске сигнала тревоги из-за усталости. Проблема в плохой детекции, которая приводит к появлению множества неинтересных, неинформативных сигналов!
Целью является генерация достаточно сильных сигналов, чтобы сортировать и анализировать их с поддержкой масштабирования при использовании помощников ИИ (co-pilots).
Читайте также:
- Механизм самовнимания в моделях интерпретации языка
- Технология составления промптов для модели ИИ на примере одного чат-бота
- Клятва Гиппократа для дизайнеров в эпоху искусственного интеллекта
Читайте нас в Telegram, VK и Дзен
Перевод статьи Alex Teixeira: AI-Powered SOC: it’s the end of the Alert Fatigue as we know it?





