
Kafka позволяет передавать очень большие объемы данных с минимальной задержкой (100 Мбайт/с при 100 тыс. сообщений в секунду с задержкой в 2 мс). Здесь можно провести аналогию с жидкостью, протекающей через широкую трубу. Чем больше диаметр трубы, тем больше объем протекающей через нее жидкости.
В основе производительности Kafka лежит несколько решений. Рассмотрим два наиболее важных.
Отличную производительность Kafka обеспечивают два фундаментальных принципа — последовательный ввод-вывод и принцип нулевого копирования.
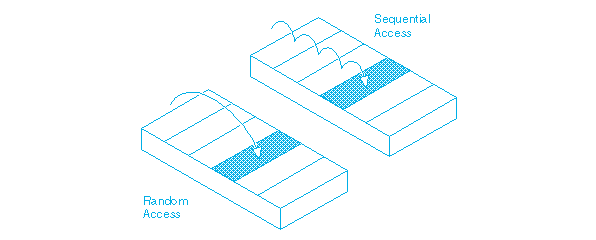
1. Последовательный ввод-вывод
Согласно распространенному заблуждению, доступ к диску медленнее, чем к памяти. Однако многое зависит от используемой схемы доступа. Произвольный доступ к диску более медленный, поскольку требуется время для физического перемещения данных из одной точки в другую. Но при последовательном доступе головке чтения/записи с диска не нужно прыгать с места на место. Поэтому чтение и запись блоков данных (одного за другим) происходит намного быстрее.
Такой же принцип действует и в Kafka. Сообщения хранятся в разделах в порядке создания. При записи новых данных они добавляются в конец раздела. Такая схема работает гораздо быстрее, чем произвольный доступ, и позволяет в полной мере реализовать возможности базового оборудования последовательного чтения и записи данных.
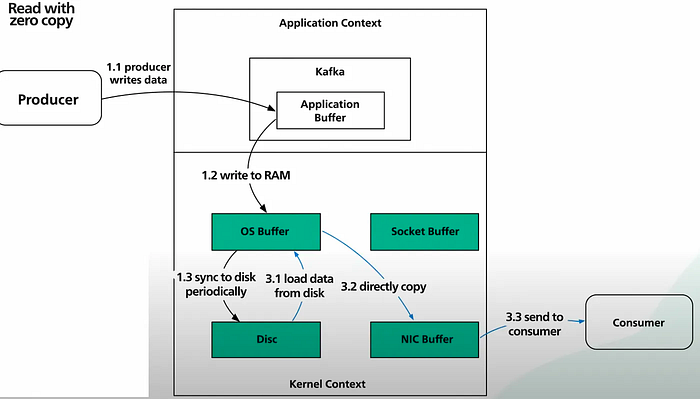
2. Принцип нулевого копирования
В обычных системах процесс перемещения передаваемых данных (например, из памяти в сетевые сокеты) часто включает несколько этапов копирования. Они занимают циклы процессора и ресурсы памяти, поэтому замедляется весь процесс передачи данных.
В Kafka используется метод “sendfile” или “scatter-gather”, не требующий промежуточного копирования (Zero Copy). Появляющееся сообщение сразу сохраняется в кэш-памяти страниц. Вместо создания избыточных копий такой рациональный подход предусматривает передачу данных оттуда непосредственно в сетевой сокет или потребителям. Отсутствие ненужного копирования данных снижает загрузку процессора и значительно повышает производительность.
Заключение
Быстродействие Kafka можно объяснить разумным использованием последовательного ввода-вывода, обеспечивающего упорядоченные чтение и запись данных, и нулевым копированием. При этом минимизируются накладные расходы, возникающие при копировании данных.
Читайте также:
- Как интегрировать Kafka со Spring Boot
- Не заблудитесь при работе с кластерами Kafka — возьмите компас
- Потоки Kafka: как обрабатывать CSV-файлы для выполнения вычислений
Читайте нас в Telegram, VK и Дзен
Перевод статьи Nishant Sharma: Unlocking the Need for Speed: The Secrets Behind Kafka’s Blazing Performance





