
Введение
В век больших языковых моделей (LLM) и их широкого применения — от простого обобщения и перевода текстов до прогнозирования курса акций на основе настроений и финансовых отчетов — важность текстовых данных как никогда велика.
Существует множество типов документов, содержащих подобную неструктурированную информацию, от веб-статей и постов в блогах до рукописных писем и стихов. Однако значительная часть этих текстовых данных хранится и передается в формате PDF. В частности, установлено, что ежегодно в Outlook открывается более 2 млрд PDF-файлов, а в Google Drive и электронной почте ежедневно сохраняется 73 млн новых PDF-файлов.
Таким образом, разработка более систематизированного способа обработки PDF-документов и извлечения из них информации позволила бы организовать автоматизированный поток, лучше освоить и использовать этот огромный объем текстовых данных. И для решения этой задачи лучшим другом, конечно же, может стать не кто иной, как Python.
Однако прежде чем приступить к работе, необходимо определить различные типы PDF-документов, которые существуют в настоящее время, а точнее, три наиболее часто встречающиеся.
- Программно созданные PDF-файлы. Эти PDF-файлы создаются на компьютере с помощью технологий W3C, таких как HTML, CSS и JavaScript, или с помощью другого программного обеспечения, например Adobe Acrobat. Этот тип файлов может содержать различные компоненты, такие как изображения, текст и ссылки, допускающие возможность поиска и легкого редактирования.
- Традиционные отсканированные документы. Эти PDF-файлы создаются на неэлектронных носителях с помощью сканера или мобильного приложения. Такие файлы представляют собой набор изображений, сохраненных в PDF-файле. При этом элементы, содержащиеся в таких изображениях, например текст и ссылки, нельзя выбрать или найти. По сути, PDF-файл служит контейнером для этих изображений.
- Отсканированные документы с OCR-распознаванием. В этом случае после сканирования документа используется программа оптического распознавания символов (OCR), которая определяет текст на каждом изображении в файле и преобразует его в текст, доступный для поиска и редактирования. Затем программа добавляет к изображению слой с текстом, и таким образом при просмотре файла его можно выделить как отдельный компонент.
Несмотря на то что в настоящее время все большее количество машин оснащено системами OCR, позволяющими распознавать текст в отсканированных документах, все еще встречаются документы, содержащие полные страницы в формате изображения. Вы наверняка замечали, как при чтении большой статьи, если попытаться выделить одно предложение, выделяется вся страница. Это может быть следствием ограничения конкретного OCR-устройства или его полного отсутствия. Описанный в данной статье процесс учитывает и такие случаи, что позволит извлечь максимум пользы из PDF-файлов.
Теоретический подход
Учитывая все эти разновидности PDF-файлов и различные элементы, входящие в их состав, важно провести первичный анализ структуры PDF-файла, чтобы определить инструмент, необходимый для работы с каждым компонентом. Точнее, на основе результатов этого анализа мы будем применять соответствующий метод для извлечения текста из PDF-файла — будь то текст, представленный в блоке корпуса с метаданными, текст в изображениях или структурированный текст в таблицах.
В отсканированном документе без OCR за всю тяжелую работу будет отвечать метод, который идентифицирует и извлекает текст из изображений. Результатом этого процесса станет Python-словарь, содержащий информацию, извлеченную из каждой страницы PDF-файла. Каждый ключ в этом словаре будет представлять собой номер страницы документа, а соответствующее ему значение — список, содержащий следующие 5 вложенных списков:
- текст, извлеченный из каждого текстового блока корпуса;
- формат текста в каждом текстовом блоке с точки зрения семейства и размера шрифта;
- текст, извлеченный из изображений на странице;
- текст, извлеченный из таблиц в структурированном виде;
- полное текстовое содержание страницы.

Таким образом, мы сможем добиться более логичного разделения извлеченного текста по компонентам источника и более легкого извлечения информации, которая обычно появляется в конкретном компоненте (например, название компании на изображении логотипа). Кроме того, метаданные, извлеченные из текста, такие как семейство и размер шрифта, могут быть использованы для идентификации заголовков текста или выделенного текста, имеющего большую важность. Это поможет в дальнейшем разделить текст на несколько различных фрагментов и обработать их. Наконец, сохранение информации в структурированных таблицах в понятном для LLM виде значительно повысит качество выводов о взаимосвязях внутри извлеченных данных. Затем эти результаты можно оформить в виде вывода всей текстовой информации, появившейся на каждой странице.
Блок-схема такого подхода приведена на рисунках ниже.
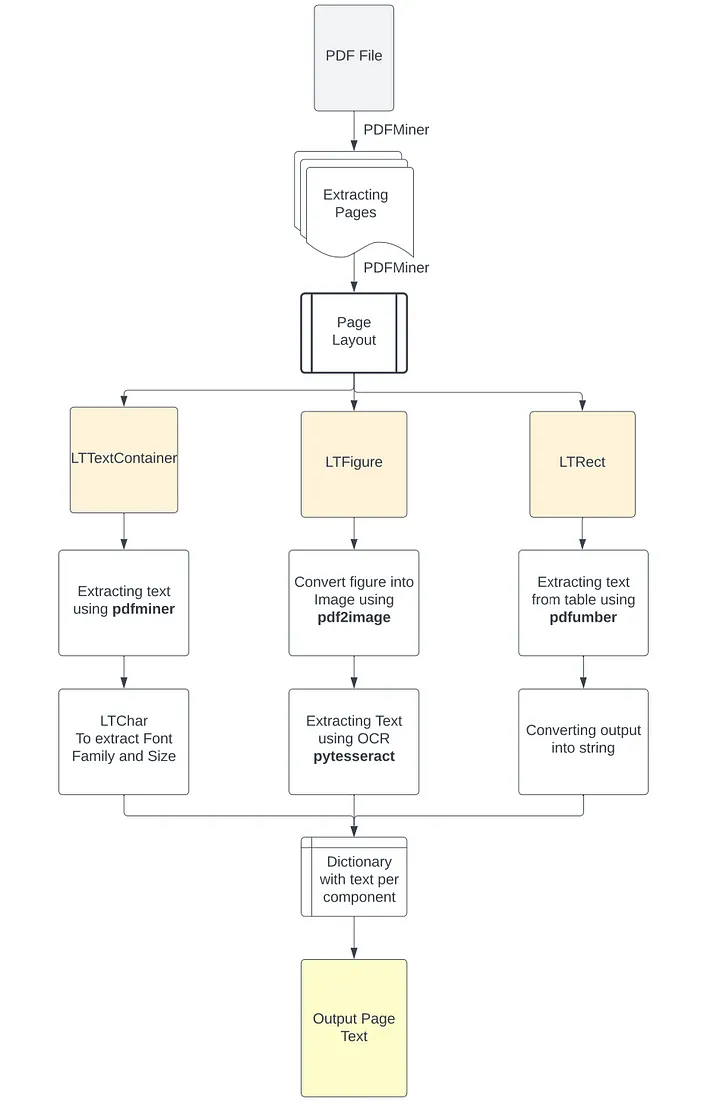
Установка всех необходимых библиотек
Прежде чем приступить к реализации проекта, необходимо установить библиотеки. Предполагаем, что на вашей машине установлен Python 3.10 или выше. В противном случае можете взять его отсюда. Затем установим следующие библиотеки.
PyPDF2: для чтения PDF-файла из пути к хранилищу.
pip install PyPDF2
Pdfminer: для анализа макета и извлечения текста и формата из PDF (версия pdfminer.six поддерживает Python 3).
pip install pdfminer.six
Pdfplumber: для идентификации таблиц на PDF-странице и извлечения из них информации.
pip install pdfplumber
Pdf2image: для преобразования обрезанного PDF-изображения в PNG-изображение.
pip install pdf2image
PIL: для чтения изображения в формате PNG.
pip install Pillow
Pytesseract: Для извлечения текста из изображений с помощью технологии OCR.
Это немного сложнее, поскольку сначала необходимо установить Google Tesseract OCR, который представляет собой OCR-машину, основанную на LSTM-модели. Он предназначен для распознавания строк и шаблонов символов.
Пользователи Mac могут установить его на устройство через Brew из терминала.
brew install tesseract
Пользователи Windows для установки должны выполнить следующие действия. Затем при загрузке и установке программ необходимо добавить пути к исполняемым файлам в переменные среды на компьютере. В качестве альтернативы можно выполнить следующие команды для непосредственного включения их путей в скрипт Python, используя приведенный ниже код:
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
Затем устанавливаем библиотеку Python.
pip install pytesseract
Импортируем все библиотеки в начало скрипта.
# Для чтения PDF
import PyPDF2
# Для анализа PDF-макета и извлечения текста
from pdfminer.high_level import extract_pages, extract_text
from pdfminer.layout import LTTextContainer, LTChar, LTRect, LTFigure
# Для извлечения текста из таблиц в PDF
import pdfplumber
# Для извлечения изображений из PDF
from PIL import Image
from pdf2image import convert_from_path
# Для выполнения OCR с целью извлечения текста из изображений
import pytesseract
# Для удаления дополнительно созданных файлов
import os
Теперь все готово. Переходим к самому интересному.
Анализ макета документа с помощью Python

Для предварительного анализа мы использовали библиотеку PDFMiner Python, которая позволяет разделить текст объекта документа на несколько страничных объектов, а затем разбить и изучить макет каждой страницы.
PDF-файлы по своей природе не содержат структурированной информации, такой как абзацы, предложения и слова, воспринимаемые человеческим глазом. Вместо этого они понимают только отдельные символы текста и их расположение на странице. Таким образом, библиотека PDFMiner пытается реконструировать содержимое страницы в отдельные символы и их положение в файле. Затем, сравнивая расстояния этих символов от других, она составляет соответствующие слова, предложения, строки и абзацы текста.
Для этого библиотека выделяет отдельные страницы из PDF-файла с помощью высокоуровневой функции extract_pages() и преобразует их в объекты LTPage.
Затем для каждого объекта LTPage выполняется итерация по каждому элементу сверху вниз и попытка идентифицировать соответствующий компонент как:
- LTFigure — область PDF-файла, где могут быть представлены рисунки или изображения, встроенные в страницу в виде другого PDF-документа.
- LTTextContainer — группу текстовых строк в прямоугольной области, позже разбиваемую на списки объектов LTTextLine. Каждый из них представляет собой список объектов LTChar, в котором хранятся отдельные символы текста вместе с их метаданными.
- LTRect — двумерный прямоугольник, который может быть использован для обрамления изображений и рисунков или создания таблиц в объекте LTPage.
Таким образом, на основе этой реконструкции страницы и классификации ее элементов на LTFigure (изображения или рисунки), LTTextContainer, (текстовую информацию) и LTRect (обрамления/таблицы) можно применить соответствующую функцию для более эффективного извлечения информации.
for pagenum, page in enumerate(extract_pages(pdf_path)):
# Итерация элементов, из которых состоит страница
for element in page:
# Проверка того, является ли элемент текстовым
if isinstance(element, LTTextContainer):
# Функция извлечения текста из текстового блока
pass
# Функция извлечения текстового формата
pass
# Проверка элементов на наличие изображений
if isinstance(element, LTFigure):
# Функция преобразования PDF в изображение
pass
# Функция извлечения текста с помощью OCR
pass
# Проверка элементов на наличие таблиц
if isinstance(element, LTRect):
# Функция для извлечения таблицы
pass
# Функция преобразования содержимого таблицы в строку
pass
Теперь, разобравшись с аналитической частью процесса, создадим функции, необходимые для извлечения текста из каждого компонента.
Определение функции для извлечения текста из PDF
С этого момента извлечение текста из текстового контейнера становится предельно простым.
# Создание функции для извлечения текста
def text_extraction(element):
# Извлечение текста из строчного текстового элемента
line_text = element.get_text()
# Поиск форматов текста
# Инициализация списка всеми форматами, которые появились в строке текста
line_formats = []
for text_line in element:
if isinstance(text_line, LTTextContainer):
# Итерация по каждому символу в строке текста
for character in text_line:
if isinstance(character, LTChar):
# Добавление имени шрифта символа
line_formats.append(character.fontname)
# Добавление размера шрифта символа
line_formats.append(character.size)
# Нахождение в строке уникальных размеров и названий шрифтов
format_per_line = list(set(line_formats))
# Возвращает кортеж с текстом в каждой строке и его форматом
return (line_text, format_per_line)
Для извлечения текста из текстового контейнера достаточно воспользоваться методом get_text() элемента LTTextContainer. Этот метод извлекает все символы, из которых состоят слова в конкретном блоке корпуса, и сохраняет результат в виде списка текстовых данных. Каждый элемент этого списка представляет собой исходную текстовую информацию, содержащуюся в контейнере.
Для определения формата этого текста проводим итерацию по объекту LTTextContainer, чтобы получить доступ к каждой текстовой строке этого корпуса в отдельности. На каждой итерации создается новый объект LTTextLine, представляющий строку текста в данном фрагменте корпуса. Затем проверяем, содержит ли вложенный элемент строки текст. Если содержит, обращаемся к каждому отдельному элементу символа как к LTChar, который включает все метаданные для этого символа. Из этих метаданных извлекаем два типа форматов и сохраняем их в отдельном списке, придерживаясь расположения соответственно исследуемому тексту:
- семейство шрифтов символов (включая данные о том, является ли символ жирным или курсивным);
- размер шрифта символа.
Как правило, символы в определенном фрагменте текста имеют одинаковое форматирование, если только некоторые из них не выделены жирным шрифтом. Для облегчения дальнейшего анализа фиксируем уникальные значения форматирования текста для всех символов в тексте и сохраняем их в соответствующем списке.
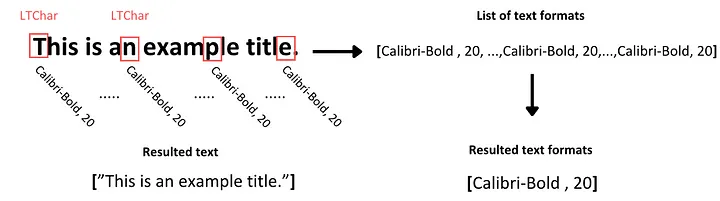
Определение функции для извлечения текста из изображений
Здесь, на мой взгляд, более сложная часть. Как работать с текстом на изображениях в PDF-файле?
Прежде всего, необходимо установить, что элементы изображения, хранящиеся в PDF, не имеют формата, отличного от формата файла, например JPEG или PNG. Таким образом, чтобы применить к ним программу OCR, необходимо сначала выделить их из файла, а затем преобразовать в формат изображения.
# Создание функции для обрезки элементов изображения из PDF-файлов
def crop_image(element, pageObj):
# Получение координат для обрезки изображения из PDF-файла
[image_left, image_top, image_right, image_bottom] = [element.x0,element.y0,element.x1,element.y1]
# Обрезка страницы по координатам (слева, снизу, справа, сверху)
pageObj.mediabox.lower_left = (image_left, image_bottom)
pageObj.mediabox.upper_right = (image_right, image_top)
# Сохранение обрезанной страницы в новом PDF-файле
cropped_pdf_writer = PyPDF2.PdfWriter()
cropped_pdf_writer.add_page(pageObj)
# Сохранение обрезанного PDF-файла в новом файле
with open('cropped_image.pdf', 'wb') as cropped_pdf_file:
cropped_pdf_writer.write(cropped_pdf_file)
# Создание функции для преобразования PDF в изображения
def convert_to_images(input_file,):
images = convert_from_path(input_file)
image = images[0]
output_file = "PDF_image.png"
image.save(output_file, "PNG")
# Создание функции для чтения текста с изображений
def image_to_text(image_path):
# Чтение изображения
img = Image.open(image_path)
# Извлечение текста из изображения
text = pytesseract.image_to_string(img)
return text
Для этого выполняем следующую процедуру.
- Используя метаданные объекта LTFigure, найденного PDFMiner, обрезаем рамку изображения, используя ее координаты на макете страницы. Затем сохраняем его в каталоге как новый PDF-файл с помощью библиотеки PyPDF2.
- Затем используем функцию convert_from_file() из библиотеки pdf2image для преобразования всех PDF-файлов в каталоге в список изображений, сохраняя их в формате PNG.
- Теперь, когда у нас есть файлы изображений, читаем их в скрипте с помощью пакета Image модуля PIL и применяем функцию image_to_string() библиотеки pytesseract для извлечения текста из изображений с помощью OCR-движка tesseract.
В результате этой процедуры из изображений извлекается текст, который нужно сохранить в третьем списке словаря на выходе. Этот список содержит текстовую информацию, извлеченную из изображений на исследуемой странице.
Определение функции для извлечения текста из таблиц
Теперь будем извлекать более логически структурированный текст из таблиц на PDF-странице. Эта задача посложнее, чем извлечение текста из корпуса, поскольку необходимо учитывать степень детализации информации и связи между точками данных, представленных в таблице.
Несмотря на то что существует несколько библиотек для извлечения табличных данных из PDF-файлов, одной из наиболее известных является Tabula-py. Мы выявили некоторые ограничения в их функциональности.
Наиболее примечательным, на наш взгляд, является то, что библиотека идентифицирует различные строки таблицы, используя специальный символ разрыва строки \n в тексте таблицы. В большинстве случаев эта особенность работает достаточно хорошо, но в случае, когда текст в ячейке обернут в 2 и более строк, приводит к добавлению ненужных пустых строк и потере контекста выделенной ячейки.
Ниже показан пример извлечения данных из таблицы с помощью tabula-py:
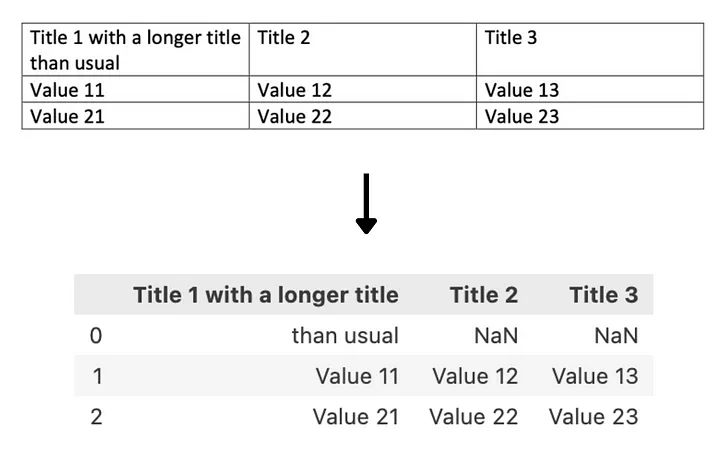
Затем извлеченная информация выводится не в виде строки, а в виде DataFrame Pandas. В большинстве случаев такой формат может оказаться подходящим, но в случае трансформеров, учитывающих текст, полученные результаты необходимо преобразовать перед подачей в модель.
Для решения этой задачи мы использовали библиотеку pdfplumber по ряду причин:
- Она создана на базе версии pdfminer.six, использованной нами для предварительного анализа, а значит, содержит схожие объекты.
- Ее подход к обнаружению таблиц основан на использовании элементов линий и их пересечений, которые строят ячейку, содержащую текст, а затем и саму таблицу. Таким образом, определив ячейку таблицы, мы можем извлечь только ее содержимое, не задумываясь о том, сколько строк необходимо вывести. Затем, когда мы получим содержимое таблицы, мы отформатируем его в таблично-подобную строку и сохраним в соответствующем списке.
# Извлечение таблиц из страницы
def extract_table(pdf_path, page_num, table_num):
# Открытие pdf-файла
pdf = pdfplumber.open(pdf_path)
# Найти исследуемую страницу
table_page = pdf.pages[page_num]
# Извлечение соответствующей таблицы
table = table_page.extract_tables()[table_num]
return table
# Преобразование таблицы в соответствующий формат
def table_converter(table):
table_string = ''
# Итерация по каждой строке таблицы
for row_num in range(len(table)):
row = table[row_num]
# Удаление разрыва строк из обернутых текстов
cleaned_row = [item.replace('\n', ' ') if item is not None and '\n' in item else 'None' if item is None else item for item in row]
# Преобразование таблицы в строку
table_string+=('|'+'|'.join(cleaned_row)+'|'+'\n')
# Удаление последнего разрыва строк
table_string = table_string[:-1]
return table_string
Для этого мы создали две функции: extract_table() для извлечения содержимого таблицы в список списков и table_converter() для объединения содержимого этих списков в строку, подобную таблице.
В функции extract_table():
- Открываем PDF-файл.
- Переходим на исследуемую страницу PDF-файла.
- Из списка таблиц, найденных на странице программой pdfplumber, выбираем нужную.
- Извлекаем содержимое таблицы и выводим его в виде списка вложенных списков, представляющих каждую строку таблицы.
В функции table_converter():
- Выполняем итерации в каждом вложенном списке и очищаем его контекст от нежелательных разрывов строк, возникающих в результате обертывания текста.
- Соединяем все элементы строки, разделяя их с помощью символа |, чтобы создать структуру ячейки таблицы.
- Добавляем в конце разрыв строки для перехода к следующей строке.
В результате получаем строку текста, которая будет представлять содержимое таблицы без потери детализации представленных в ней данных.
Соединим все вместе
Теперь, когда у нас готовы все компоненты кода, объединим их в полнофункциональный код. Можете скопировать код отсюда или найти его вместе с PDF-примером в Github-репозитории.
# Нахождение пути к PDF-файлу
pdf_path = 'OFFER 3.pdf'
# создание объекта PDF-файла
pdfFileObj = open(pdf_path, 'rb')
# создание объекта для чтения PDF-файлов
pdfReaded = PyPDF2.PdfReader(pdfFileObj)
# Создание словаря для извлечения текста из каждого изображения
text_per_page = {}
# Мы извлекаем страницы из PDF-файла
for pagenum, page in enumerate(extract_pages(pdf_path)):
# Инициализация переменных, необходимых для извлечения текста со страницы
pageObj = pdfReaded.pages[pagenum]
page_text = []
line_format = []
text_from_images = []
text_from_tables = []
page_content = []
# Инициализация количества исследуемых таблиц
table_num = 0
first_element= True
table_extraction_flag= False
# Открытие pdf-файла
pdf = pdfplumber.open(pdf_path)
# Нахождение исследуемой страницы
page_tables = pdf.pages[pagenum]
# Нахождение количества таблиц на странице
tables = page_tables.find_tables()
# Нахождение всех элементов
page_elements = [(element.y1, element) for element in page._objs]
# Сортировка всех элементов по мере их появления на странице
page_elements.sort(key=lambda a: a[0], reverse=True)
# Поиск элементов, из которых состоит страница
for i,component in enumerate(page_elements):
# Извлечение положения верхней стороны элемента в PDF
pos= component[0]
# Извлечение элемента макета страницы
element = component[1]
# Проверка того, является ли элемент текстовым
if isinstance(element, LTTextContainer):
# Проверка наличия текста в таблице
if table_extraction_flag == False:
# Использование функции для извлечения текста и формата для каждого элемента текста
(line_text, format_per_line) = text_extraction(element)
# Добавление текста каждой строки к тексту страницы
page_text.append(line_text)
# Добавление формата для каждой строки, содержащей текст
line_format.append(format_per_line)
page_content.append(line_text)
else:
# Исключение текста, появившегося в таблице
pass
# Проверка элементов на наличие изображений
if isinstance(element, LTFigure):
# Обрезка изображения из PDF-файла
crop_image(element, pageObj)
# Преобразование обрезанного pdf в изображение
convert_to_images('cropped_image.pdf')
# Извлечение текста из изображения
image_text = image_to_text('PDF_image.png')
text_from_images.append(image_text)
page_content.append(image_text)
# Добавление заполнителя в списки текстов и форматов
page_text.append('image')
line_format.append('image')
# Проверка элементов на наличие таблиц
if isinstance(element, LTRect):
# Если первый прямоугольный элемент
if first_element == True and (table_num+1) <= len(tables):
# Поиск ограничительной рамки таблицы
lower_side = page.bbox[3] - tables[table_num].bbox[3]
upper_side = element.y1
# Извлечение информации из таблицы
table = extract_table(pdf_path, pagenum, table_num)
# Преобразование табличной информации в формат структурированной строки
table_string = table_converter(table)
# Добавление строки таблицы в список
text_from_tables.append(table_string)
page_content.append(table_string)
# Установка флага в True для избежания повторного появления содержимого
table_extraction_flag = True
# Сделать еще одним элементом
first_element = False
# Добавление заполнителя в списки текстов и форматов
page_text.append('table')
line_format.append('table')
# Проверьте, извлекли ли вы уже таблицы со страницы
if element.y0 >= lower_side and element.y1 <= upper_side:
pass
elif not isinstance(page_elements[i+1][1], LTRect):
table_extraction_flag = False
first_element = True
table_num+=1
# Создание ключа словаря
dctkey = 'Page_'+str(pagenum)
# Добавить список списков в качестве значения ключа страницы
text_per_page[dctkey]= [page_text, line_format, text_from_images,text_from_tables, page_content]
# Закрытие объекта pdf-файла
pdfFileObj.close()
# Удаление дополнительно созданных файлов
os.remove('cropped_image.pdf')
os.remove('PDF_image.png')
# Отображение содержимого страницы
result = ''.join(text_per_page['Page_0'][4])
print(result)
Приведенный выше скрипт позволяет:
- Импортировать необходимые библиотеки.
- Открыть PDF-файл с помощью библиотеки pyPDF2.
- Извлечь каждую страницу PDF-файла и выполнить следующие шаги.
- Проверить, есть ли на странице таблицы, и создать их список с помощью pdfplumner.
- Найти все элементы, вложенные в страницу, и отсортировать их в том виде, в котором они были представлены в ее макете.
Затем для каждого элемента:
- Проверяем, является ли он текстовым контейнером и не находится ли в элементе таблицы. Затем с помощью функции text_extraction() извлекаем текст вместе с его форматом, в иных случаях пропускаем этот текст.
- Проверяем, является ли он изображением, и с помощью функции crop_image() обрезаем компонент изображения из PDF-файла, преобразуем его в файл изображения с помощью функции convert_to_images() и извлекаем из него текст с помощью OCR и функции image_to_text().
- Проверяем, является ли элемент прямоугольным. В данном случае смотрим, является ли первый прямоугольник частью таблицы страницы, и если да, то переходим к следующим шагам:
- Находим ограничительную рамку таблицы, чтобы не извлекать ее текст повторно с помощью функции text_extraction().
- Извлекаем содержимое таблицы и преобразовываем его в строку.
- Добавляем параметр boolean для уточнения того, что текст извлекается из таблицы.
Завершаем этот процесс после того, как последний LTRect, попадающий в ограничительную рамку таблицы, и следующий элемент макета не будут являться прямоугольными объектами. Все остальные объекты, составляющие таблицу, будут пропущены.
Результаты процесса будут храниться в 5 списках на 1 итерацию с именами:
- page_text: содержит текст, полученный из текстовых контейнеров в PDF (будет размещен заполнитель, если текст был извлечен из другого элемента).
- line_format: содержит форматы текстов, извлеченных выше (будет размещен заполнитель, если текст извлечен из другого элемента).
- text_from_images: содержит тексты, извлеченные из изображений на странице.
- text_from_tables: содержит строку, подобную таблице, с содержимым таблиц.
- page_content: содержит весь текст, отображаемый на странице, в виде списка элементов.
Все списки будут храниться под ключом в словаре, который каждый раз будет представлять собой номер просмотренной страницы.
После этого закроем PDF-файл.
Затем удалим все дополнительные файлы, созданные в процессе работы.
Наконец, можно вывести содержимое страницы, соединив элементы списка page_content.
Заключение
Этот подход, на мой взгляд, использует лучшие характеристики многих библиотек и применим к различным типам PDF-файлов и элементов. При этом PDFMiner выполняет большую часть работы. Кроме того, информация о формате текста позволяет определить потенциальные заголовки, разделяющие текст на логические части, а также выделить наиболее важные фрагменты текста.
Читайте также:
- Рисуем Дораэмона с помощью Python
- Как повысить эффективность кода Python с помощью кэширования
- 9 странностей Python и их объяснение
Читайте нас в Telegram, VK и Дзен
Перевод статьи George Stavrakis: Extracting Text from PDF Files with Python: A Comprehensive Guide





