
Парсеры (в контексте компьютерных технологий) — это программы или алгоритмы, способные преобразовать определенный массив данных в некую структурированную информацию. При обмене данными между устройствами (к примеру, при отправке этой статьи на ваше устройство) парсеры используются для преобразования полученных данных в то, что устройство может обработать.
Учитывая это, легко понять важность подобных алгоритмов, а также значение их эффективности для общей производительности системы. Одним из способов оптимизации таких программ является использование технологии, называемой zero-copy (нулевое копирование).
Парсер с нулевым копированием представляет собой участок кода, который может преобразовывать полученные данные в структурированную форму, не копируя при этом содержимое в новые буферы. Это отличает данный вид парсеров от прочих, используемых для преобразования части данных в набор значений (например, строки и массивы): программы без нулевого копирования выделяют новую область в куче и копируют в нее соответствующую часть полученных данных.
В качестве примера простейшего парсера с нулевым копированием я создал программу на языке C, которая выполняет парсинг массива байтов в заранее определенный struct. Программа предполагает, что полученные данные будут содержать заголовочный байт, за которым следует строка.
struct ParsedData {
uint8_t header;
char *payload;
};
void parse_buffer(uint8_t *buffer, struct ParsedData *parsed_data) {
parsed_data->header = buffer[0];
parsed_data->payload = (char *)&buffer[1];
};
Код достаточно прост: в struct перемещается значение примитива (header — заголовок) и указатель на массив символов (payload — полезная нагрузка). Заметим, что хотя некоторые могут назвать эту процедуру копированием, она не выделяет новую память, а лишь выполняет простые инструкции перемещения значений и указателей:
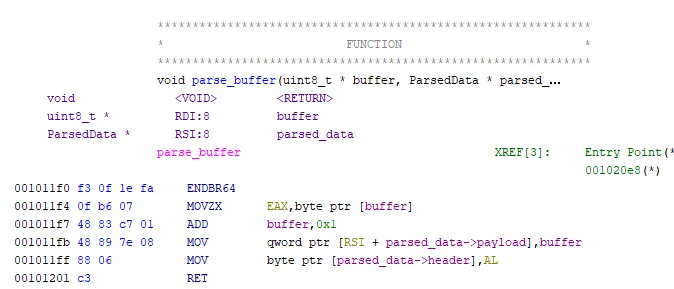
А теперь применим парсер. В следующей программе выделим буфер и сымитируем получение определенных данных. После этого выполним парсинг с помощью вышеупомянутой функции и выведем полезную нагрузку.
#include <stdint.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
struct ParsedData {
uint8_t header;
char *payload;
};
void parse_buffer(uint8_t *buffer, struct ParsedData *parsed_data) {
parsed_data->header = buffer[0];
parsed_data->payload = (char *)&buffer[1];
};
void get_data(uint8_t *buffer) {
const uint8_t data[] = {255, 't', 'e', 's', 't'};
memcpy(buffer, data, sizeof(data));
}
int main(void) {
// Выделение буфера для полученных данных
uint8_t *buffer = malloc(1024); // Игнорируем, если указатель - NULL
// Имитация получения данных из другого места (например, из сокета)
get_data(buffer);
// Парсинг буфера в struct ParsedData
struct ParsedData parsed_data;
parse_buffer(buffer, &parsed_data);
// Вывод содержимого полезной нагрузки
printf("%s\n", parsed_data.payload);
free(buffer);
return 0;
}
Выполнив этот код, увидим, что парсер работает и полезная нагрузка выводится корректно. Но причем тут Rust?
Дело в том, что здесь возникает одна из самых больших проблем, связанных с языком C/C++: безопасность памяти, точнее ее отсутствие. Несмотря на то что в данном сценарии все работает, код чреват несколькими глубинными сбоями.
- Применение указателя к динамически выделяемому буферу может привести к неопределенному поведению при попытке прочитать полезную нагрузку после того, как буфер будет освобожден.
- Переменные в языке C по умолчанию мутабельны, а это означает, что данные в исходном буфере могут быть изменены, в результате чего из структуры впоследствии будет считана не та полезная нагрузка.
Для убедительности я изменил код таким образом, чтобы он выводил полезную нагрузку как после манипуляций с буфером, так и после его освобождения:
// Вывод содержимого полезной нагрузки
printf("Original: %s\n", parsed_data.payload);
// Манипуляция с исходным буфером
buffer[1] = 'j';
// Вывод содержимого полезной нагрузки
printf("Tampered: %s\n", parsed_data.payload);
free(buffer);
// Вывод содержимого полезной нагрузки
printf("Freed: %s\n", parsed_data.payload);
Вот результат этого изменения:
Original: test
Tampered: jest
Freed:
Существуют способы предотвращения такого рода проблем, и их устранение на 100% зависит от разработчика. Причем в условиях многопоточности подобные решения принимать гораздо сложнее. Это одна из причин, по которой некоторые разработчики избегают парсеров с нулевым копированием, используя постоянное копирование данных.
Rust решает две упомянутые ранее проблемы с помощью системы borrow checker. Она работает путем верификации на соответствие набору правил во время компиляции, ограничивая применение небезопасных практик.
Вот правила и задачи, которые они решают.
- Владение (Ownership). Только одна переменная может одновременно владеть значением, причем значение освобождается после того, как переменная выходит из области видимости.
Решаемая задача: компилятор может детерминированно определять момент освобождения значения, что позволяет безопасно освобождать значение в неявном виде без сборщика мусора. - Заимствование (Borrowing). На значение можно ссылаться (заимствовать) много раз, если оно неизменяемое, но только один раз, если на него идет ссылка как на изменяемое.
Решаемая задача: если на значение ссылаются как на неизменяемое, то оно гарантированно не будет изменено другой сущностью, пока остается заимствованным. - Время жизни (Lifetimes). На значение можно ссылаться (заимствовать) только в том случае, если оно живет по крайней мере столько же, сколько и переменная, которая на него ссылается.
Решаемая задача: ссылки гарантированно всегда действительны (нет висячих указателей).
Разобравшись с принципами работы системы borrow checker, создадим в Rust парсер с ненулевым копированием, а затем преобразуем его в парсер с нулевым копированием. Так вы сможете понять не только разницу между ними (включая бенчмарки), но и связанные с этим трудности.
После определения struct создадим функцию, которая выполняет парсинг массива байтов, перемещая значение заголовка, создавая новый вектор с байтами полезной нагрузки и преобразуя вектор в строку. Функция to_vec отвечает за выделение кучи и копирование данных из фрагмента массива, а строковый метод from_utf8 перемещает владение от вновь созданного Vec и использует его данные на месте:
pub struct ParsedData {
pub header: u8,
pub payload: String,
}
impl ParsedData {
pub fn parse(data: &[u8]) -> ParsedData {
let header = data[0];
let payload_bytes = data[1..data.len()].to_vec();
let payload = String::from_utf8(payload_bytes).unwrap();
ParsedData {
header,
payload,
}
}
}
Чтобы применить нулевое копирование, необходимо удалить функцию to_vec, а также использовать ссылку на str вместо String. Если выполнить это, то получим следующий код:
pub struct ParsedData {
pub header: u8,
pub payload: &str,
}
impl ParsedData {
pub fn parse(data: &[u8]) -> ParsedData {
let header = data[0];
let payload = std::str::from_utf8(&data[1..data.len()]).unwrap();
ParsedData {
header,
payload,
}
}
}
Но не все так просто. Необходимо помнить, что мы получим ссылки только в том случае, если компилятор сможет определить, что значение, на которое идет ссылка, будет жить достаточно долго. Решим эту проблему, добавив в код явное время жизни, чтобы исходные данные пережили свою ссылку внутри struct.
pub struct ParsedData<'a> {
pub header: u8,
pub payload: &'a str,
}
impl<'a> ParsedData<'a> {
pub fn parse(data: &'a [u8]) -> ParsedData<'a> {
let header = data[0];
let payload = std::str::from_utf8(&data[1..data.len()]).unwrap();
ParsedData {
header,
payload,
}
}
}
Благодаря пропуску времени жизни, приведенный выше код можно упростить, удалив некоторые явные аннотации, которые не нужны для того, чтобы время жизни было детерминированным (это не всегда так).
pub struct ParsedData<'a> {
pub header: u8,
pub payload: &'a str,
}
impl ParsedData<'_> {
pub fn parse(data: &[u8]) -> ParsedData {
let header = data[0];
let payload = std::str::from_utf8(&data[1..data.len()]).unwrap();
ParsedData {
header,
payload,
}
}
}
Теперь создадим программу, использующую парсер, аналогично тому, как это было сделано для версии на языке С:
pub struct ParsedData<'a> {
pub header: u8,
pub payload: &'a str,
}
impl ParsedData<'_> {
pub fn parse(data: &[u8]) -> ParsedData {
let header = data[0];
let payload = std::str::from_utf8(&data[1..data.len()]).unwrap();
ParsedData {
header,
payload,
}
}
}
fn get_data() -> Vec<u8> {
const DATA: [u8; 5] = [255, 't' as u8, 'e' as u8, 's' as u8, 't' as u8];
DATA.to_vec() // Возвращение динамически размещенного массива (вектора)
}
fn main() {
// Имитация получения данных из другого места (например, из сокета). (Rust позволяет возвращать объект)
let buffer = get_data();
// Парсинг буфера в struct ParsedData
let parsed_data = ParsedData::parse(&buffer);
// Вывод содержимого полезной нагрузки
println!("{}", parsed_data.payload);
}
Теперь, имея готовую программу, смоделируем проблемы, обнаруженные ранее в коде на языке C. Для начала попробуем изменить исходный буфер. Вот новая функция main:
fn main() {
// Имитация получения данных из другого места (например, из сокета). (Rust позволяет возвращать объект)
let mut buffer = get_data(); // Сделайте их мутабельными для тестирования
// Парсинг буфера в struct ParsedData
let parsed_data = ParsedData::parse(&buffer);
// Вывод содержимого полезной нагрузки
println!("Original: {}", parsed_data.payload);
// Манипуляция с исходным буфером
buffer[1] = 'j' as u8;
// Вывод содержимого полезной нагрузки
println!("Tempered: {}", parsed_data.payload);
}
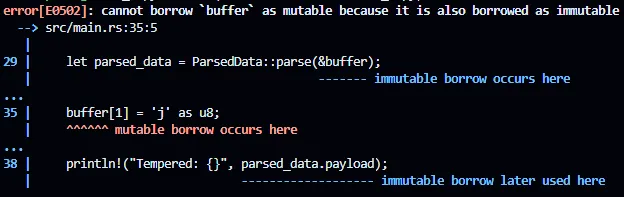
Если попытаться скомпилировать этот код, получим ошибку: cannot borrow `buffer` as mutable because it is also borrowed as immutable. Это происходит потому, что никакое другое заимствование не может произойти, если значение заимствовано как mutable (изменяемое).
Теперь попробуем решить вторую проблему, обнаруженную в коде на языке C: обращение к полезной нагрузке после освобождения исходного буфера. Вот новая функция main:
fn main() {
let parsed_data = { // Создайте область видимости для имитации освобождения буфера (RAII)
// Имитация получения данных из другого места (например, из сокета). (Rust позволяет возвращать объект)
let buffer = get_data();
// Парсинг буфера в struct ParsedData
let parsed_data = ParsedData::parse(&buffer);
// Вывод содержимого полезной нагрузки
println!("{}", parsed_data.payload);
parsed_data
};
println!("Freed: {}", parsed_data.payload);
}
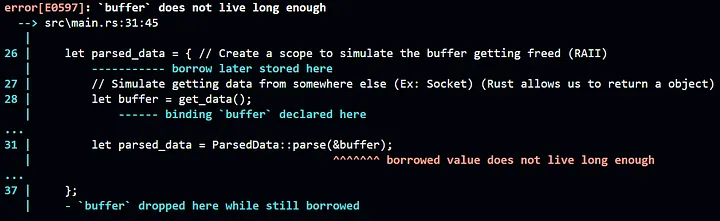
Если попытаться скомпилировать этот код, получим новую ошибку: `buffer` does not live long enough (`buffer` живет недостаточно долго). Это происходит потому, что в то время как буфер выходит за пределы области видимости, происходит перемещение владения parsed_data в переменную, находящуюся за ее пределами. Таким образом, правила Rust RAII освободят любую переменную, вышедшую за пределы области действия, и тогда время жизни, явно определенное между исходными данными и struct, будет нарушено.
Таким образом, хотя концепции времени жизни и заимствования довольно сложные, они позволяют использовать парсер с нулевым копированием без изъянов, связанных с безопасностью памяти и возникающих при использовании других языков.
С помощью библиотеки Criterion я создал простой бенчмарк, в котором сравниваются парсеры с копированием и нулевым копированием. Тесты проводились с полезной нагрузкой в 1, 10, 100, 500 и 1000 символов:
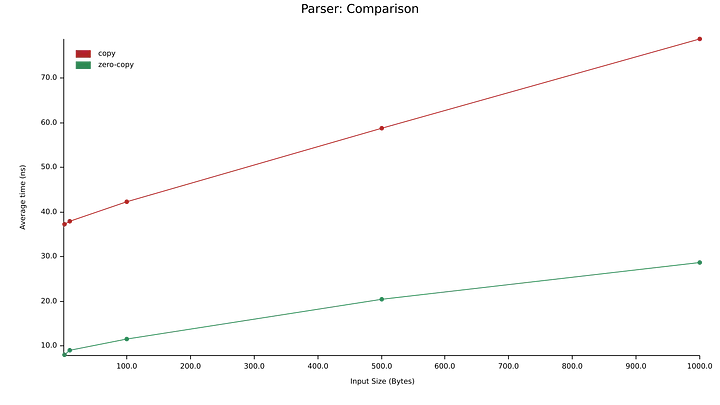
Результаты в приведенном графе удивляют. Нулевое копирование не только оказывается быстрее при любом объеме полезной нагрузки, но и может выполнить парсинг 1000 символов всего за 70% времени, которое требуется алгоритму копирования для парсинга одного символа.
Читайте также:
Читайте нас в Telegram, VK и Дзен
Перевод статьи Daniel Stuart: Rust: The joy of safe zero-copy parsers





