
Книги Кайла Симпсона о JavaScript и руководство Лусиано Рамальо “Fluent Python” (“Свободный Python”) посвящены разным языкам, но затрагивают одну и ту же проблему. Ее можно выразить так:
Поскольку язык слишком прост в изучении, многие практикующие программисты лишь поверхностно осваивают его потенциал, не обращая внимания на более продвинутые и мощные аспекты, которые делают его по-настоящему уникальным и сильным.
Поэтому предлагаю вкратце обсудить важнейшие функциональные возможности Python. О некоторых их них вы, возможно, еще не слышали. Но поверьте: без овладения всем потенциалом языка вам не стать профессионалом.
Оценка аргументов по умолчанию
Аргументы Python оцениваются при обнаружении определения функции. Каждый раз при вызове функции fib_memo (которая упоминается ниже) без явного указания значения аргумента memo будет использоваться тот же объект словаря, который был создан при определении функции.
def fib_memo(n, memo={0:0, 1:1}):
"""
n is the number nth number
you would like to return in the sequence
"""
if n not in memo:
memo[n] = fib_memo(n-1) + fib_memo(n-2)
return memo[n]
# 6-е число Фибоначчи (включая 0 в качестве первого числа)
fib_memo(6) # должен вернуть 8
Вот так этот код работает в Python. Это также означает, что функцию fib_memo можно выполнять в одном скрипте несколько раз, например в цикле for, с каждым выполнением увеличивая вычисляемое число Фибоначчи, не достигая ограничения “maximum recursion depth exceeded” (“превышена максимальная глубина рекурсии”), пока memo будет продолжать расширяться.
Важное замечание: изменяемые аргументы по умолчанию (как уже говорилось выше) могут привести к уменьшению объема кода. Не все знают о таком поведении, хотя оно чревато трудноразрешимыми ошибками. Некоторые даже считают его скорее багом, чем фичей. Поэтому, если есть возможность, придерживайтесь одного из принципа Python-дзена: явное лучше неявного.
Кроме того, упомянутый выше вариант if n not in memo, как справедливо заметили на Hacker News, более прост для чтения, чем if n not in memo, хотя оба решения дают одинаковый результат. Более подробную информацию можно найти здесь.
Моржовый оператор
Моржовый оператор (:=), который был представлен в Python 3.8, позволяет присваивать переменной значение внутри выражения. Таким образом, в одном выражении можно присвоить значение переменной и проверить ее значение:
import random
some_value = 9 # возвращает число от 0 до 100 (включительно)
if below_ten := some_value < 10:
print(f"{below_ten}, some_value is smaller than 10")
Очевидно, что также легко присвоить и проверить, содержит ли возвращаемое значение истинное значение:
if result := some_method(): # если результат не ложный
print(result)
*args и **kwargs
В Python можно распаковать аргументы с помощью одной звездочки (*) или именованные аргументы с помощью двух звездочек (**) перед передачей их в функцию. Для примера рассмотрим следующий код:
my_numbers = [1,2]
def sum_numbers(first_number, second_number):
return first_number + second_number
# Это вернет TypeError.
# TypeError: sum() missing 1 required positional argument: 'second_number'
sum_numbers(my_numbers)
# Это вернет ожидаемый результат - 3
sum_numbers(*my_numbers)
При вызове функции sum_numbers без распаковки my_numbers возникает ошибка типа TypeError, поскольку функция ожидает два отдельных аргумента. Однако, используя звездочку (*), можно распаковать значения из my_numbers и передать их как отдельные аргументы, что приведет к правильному результату.
Техника распаковки работает не только с кортежами и списками, но и со словарями (правда, в этом случае в качестве аргументов будут передаваться ключи). Но как быть с именованными аргументами? Для этого можно использовать двойную звездочку (**). В качестве примера приведем следующий код:
def greet_person(last_name, first_name):
print(f"Hello {first_name} {last_name}")
data = {"first_name": "John", "last_name": "Doe"}
greet_person(**data)
Кроме случаев распаковки последовательности для передачи в качестве аргументов в функцию, оператор * может использоваться, например, для создания новой последовательности:
numbers = [1, 2, 3, 4, 5]
new_list_numbers = [*numbers]
Исходный список чисел остается незатронутым, а переменная new_list_numbers содержит копию того же списка. Однако будьте осторожны со ссылками, содержащими объекты:
numbers = [[1, 2], [3, 4], [5, 6]]
packed_numbers = [*numbers]
numbers[0].append(10) # Измените вложенный список внутри исходного списка
print(numbers) # Вывод: [[1, 2, 10], [3, 4], [5, 6]]
print(packed_numbers) # Вывод: [[1, 2, 10], [3, 4], [5, 6]]
any и all
any и all — это встроенные функции, которые работают с итерируемыми объектами (такими как списки, кортежи и множества) и возвращают булево значение, основанное на элементах итерируемого объекта. Пример:
some_booleans = [True, False, False, False]
any(some_booleans) # возвращает True
all(some_booleans) # возвращает
Функции all и any можно использовать в сочетании со списковыми включениями, которые возвращают итерируемый объект и передают его в качестве аргумента функции all:
numbers = [5, 10, 3, 8, -2]
all_positive = all(num > 0 for num in numbers)
А также функции any:
fruits = ['apple', 'banana', 'cherry', 'durian']
# Проверить, все ли фрукты начинаются с буквы "а"
result = all(fruit.startswith('a') for fruit in fruits)
print(result) # Вывод: False
Ниже приведена таблица, в которой показаны различия выходов в зависимости от значений в итерируемом объекте.
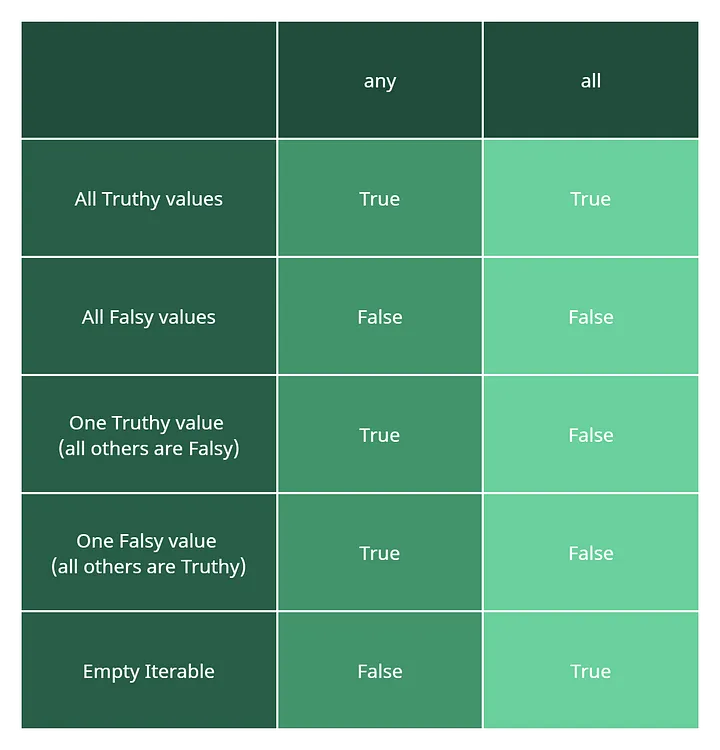
Обмен значений переменных
В Python можно комбинировать упаковку кортежей (то, что справа от знака равенства =) и распаковку (то, что слева от знака равенства =) и использовать эту функциональность для обмена переменных:
a = 10
b = 5
# Обмен значений b и a посредством их упаковки и распаковки
a, b = b, a
print(a) # 5
print(b) # 10
str и repr
Обычно, чтобы преобразовывать какую-то переменную или значение в строку для выведения и отладки, используется str(some_value). Хочу познакомить вас с функцией repr(some_value). Основное отличие между этими функциями заключается в том, что repr пытается вернуть выводное представление объекта, а str — только строковое. Для наглядности приведем пример:
import datetime
today = datetime.datetime.now()
print(str(today)) # Вывод: 2023-07-20 15:30:00.123456
print(repr(today)) # Вывод: datetime.datetime(2023, 7, 20, 15, 30, 0, 123456)
Как видно, str() просто возвращает значение datetime в виде строкового представления. Эта функция не позволит определить, содержит ли переменная today строку или объект datetime. Между тем, repr() предоставляет информацию о реальном объекте, который содержит переменная. Эта информация имеет значительно большую ценность при отладке.
Расширенная распаковка итерабельной последовательности
Если надо получить первое и последнее значение последовательности одной командой, можно сделать это просто:
first, *middle, last = [1, 2, 3, 4, 5]
print(first) # 1
print(middle) # [2, 3, 4]
print(last) # 5
Но это тоже работает:
*the_first_three, second_last, last = [1, 2, 3, 4, 5]
print(the_first_three) # [1, 2, 3]
print(second_last) # 4
print(last) # 5
Также можно попробовать другие комбинации.
Контекстные менеджеры
Обычно используется один контекстный менеджер за раз, например для открытия файла:
with open('file.txt', 'r') as file:
# Код, использующий файл
# Файл будет автоматически закрыт в конце блока
# даже при возникновении исключения
# Пример: считывание строк из файла
for line in file:
print(line.strip())
with open('file_2.txt', 'r') as other_file:
# Второй контекстный менеджер
for line in other_file:
print(line.strip())
Но можно было бы легко открыть несколько файлов в одном операторе. Это просто, если нужно, например, записать строки в другой файл:
with open('file1.txt') as file1, open('file2.txt', 'w') as file2:
# Код, использующий как файл1, так и файл2
# Файлы будут автоматически закрыты в конце блока
# даже при возникновении исключения
# Пример: чтение строк из файла1 и запись их в файл2
for line in file1:
file2.write(line)
Отладчик Python
Для отладки можно просто вывести множество переменных в файл, а можно воспользоваться отладчиком Python (pdb), который позволяет устанавливать точки останова, что значительно упрощает задачу:
import pdb
# Установите эту точку останова где-либо в коде
pdb.set_trace()
Еще более ценным является то, что программа остановится в точке останова, и при этом можно вывести любую переменную, чтобы проверить ее значение или существование в этой конкретной точке останова.
Вот несколько команд, которые можно использовать, когда программа попадает в точку останова.
nилиnext: выполнить следующую строку.sилиstep: переход к вызову функции.cилиcontinue: продолжить выполнение до следующей точки останова.lилиlist: показать текущий контекст кода.p <expression>илиpp <expression>: вывести значение выражения.b <line>илиbreak <line>: установка новой точки останова в указанной строке.hилиhelp: получить справку по использованиюpdb.qилиquit: выход из отладчика и завершение работы программы.
collections.Counter
Класс Counter из модуля collections предоставляет удобный способ подсчета элементов в итерируемом объекте:
from collections import Counter
my_list = [1, 2, 3, 1, 2, 1, 3, 4, 5]
counts = Counter(my_list)
print(counts) # Вывод: Counter({1: 3, 2: 2, 3: 2, 4: 1, 5: 1})
Комбинации с помощью Itertools
Можно комбинировать различные циклы for для создания перестановок, комбинаций и декартова произведения, а можно просто использовать встроенные инструменты itertools.
Перестановки:
import itertools
# Создание перестановок
perms = itertools.permutations([1, 2, 3], 2)
print(list(perms)) # Output: [(1, 2), (1, 3), (2, 1), (2, 3), (3, 1), (3, 2)]
Комбинации:
import itertools
# Создание комбинаций
combs = itertools.combinations('ABC', 2)
print(list(combs)) # Output: [('A', 'B'), ('A', 'C'), ('B', 'C')]
Декартово произведение:
import itertools
# Создание декартова произведения
cartesian = itertools.product('AB', [1, 2])
print(list(cartesian)) # Output: [('A', 1), ('A', 2), ('B', 1), ('B', 2)]
Два способа использования символа подчеркивания
Вот два способа использования символа подчеркивания в Python: в качестве разделителя больших чисел и в качестве переменной throwaway.
Переменная throwaway
Подчеркивание _ можно использовать в качестве одноразовой переменной throwaway для отбрасывания ненужных значений:
# Игнорирование первого возвращаемого значения функции
_, result = some_function()
# Циклирование без использования переменной loop
for _ in range(5):
do_something()
# Нужны только первое и последное значение
first, *_, last = [1, 2, 3, 4, 5]
Разделитель больших чисел
Для повышения удобочитаемости при работе с большими числовыми значениями можно использовать символы подчеркивания (_) в качестве визуальных разделителей. Эта возможность появилась в Python 3.6 и известна как “underscore literals” (“литералы с подчеркиванием”).
population = 7_900_000_000
revenue = 3_249_576_382.50
print(population) # Вывод: 7900000000
print(revenue) # Вывод: 3249576382.5
Читайте также:
- Как профессионально писать логи Python
- Расширяем возможности собственного мозга на базе ИИ, Python и ChatGPT
- Обнаружение и извлечение текста из изображения с помощью Python
Читайте нас в Telegram, VK и Дзен
Перевод статьи Erik van de Ven: Python: Uncovering the Overlooked Core Functionalities





