
В первой части мы начали с нуля разработку ML-фреймворка на Rust. Основная цель — оценить рост скорости обучения модели на Rust и PyTorch по сравнению с Python. Для сетей прямой связи результаты очень позитивные.
Продолжим со сверточными нейросетями CNN, их определением и обучением. Чтобы иметь доступ к тензорной линейной алгебре и функционалу Autograd, снова задействуем крейт Tch-rs как обертку LibTorch, библиотеки PyTorch на C++. Остальное разрабатывается с нуля.
Код для обеих частей доступен на Github. Конечный результат — определение сверточных нейросетей CNN на Rust.
Листинг 1. Определение модели CNN
struct MyModel {
l1: Conv2d,
l2: Conv2d,
l3: Linear,
l4: Linear,
}
impl MyModel {
fn new (mem: &mut Memory) -> MyModel {
let l1 = Conv2d::new(mem, 5, 1, 10, 1);
let l2 = Conv2d::new(mem, 5, 10, 20, 1);
let l3 = Linear::new(mem, 320, 64);
let l4 = Linear::new(mem, 64, 10);
Self {
l1: l1,
l2: l2,
l3: l3,
l4: l4,
}
}
}
impl Compute for MyModel {
fn forward (&self, mem: &Memory, input: &Tensor) -> Tensor {
let mut o = self.l1.forward(mem, &input);
o = o.max_pool2d_default(2);
o = self.l2.forward(mem, &o);
o = o.max_pool2d_default(2);
o = o.flat_view();
o = self.l3.forward(mem, &o);
o = o.relu();
o = self.l4.forward(mem, &o);
o
}
}
… затем инстанцирование и обучение:
Листинг 2. Обучение модели CNN
fn main() {
let (mut x, y) = load_mnist();
x = x / 250.0;
x = x.view([-1, 1, 28, 28]);
let mut m = Memory::new();
let mymodel = MyModel::new(&mut m);
train(&mut m, &x, &y, &mymodel, 20, 512, cross_entropy, 0.0001);
let out = mymodel.forward(&m, &x);
println!("Accuracy: {}", accuracy(&y, &out));
}
Чтобы листинг 1 был интуитивно понятен пользователям Python и PyTorch, определение модели максимально приближено к соответственному эквиваленту.
В структуре MyModel теперь добавляются слои Conv2D, которые затем инициируются в ассоциированной функции new.
В реализации типажа Compute определяется функция forward, которой принимаются входные данные через все слои, включая промежуточную функцию MaxPooling.
В функции main листинга 2, аналоге main из первой части, модель обучается и применяется к набору данных Mnist.
Рассмотрим подробнее такое определение и обучение CNN, это новые добавления к начатому в первой части фреймворку.
Поэкспериментируем с ядрами
Уникальная характеристика сверточных сетей — как минимум в одном слое вместо общего перемножения матриц применяется свертка. Цель операции свертки — с помощью ядра извлечь из входного изображения нужные признаки. Ядро — это матрица, перемещаемая по подразделам входного изображения и перемножаемая с ними так, что входные данные преобразуются в выходные определенным образом:

В двумерном случае в качестве входных данных используются двумерное изображение I и, как правило, двумерное ядро K, в итоге получаются такие вычисления свертки:
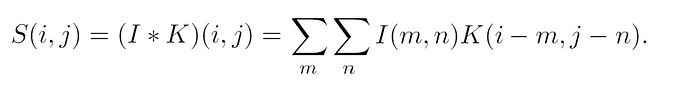
По уравнению 1 ясно, что наивный алгоритм применения свертки довольно затратен вычислительно из-за большого числа контуров и матричных умножений. К тому же эти вычисления многократно повторяются для каждого сверточного слоя сети и каждого примера/пакета обучения. Поэтому, прежде чем расширить для работы с CNN библиотеку из части 1, находим эффективный способ вычисления сверток.
Это задача очень хорошо изучена. Из различных вариантов, в том числе версий исключительно на Rust с промежуточными преобразованиями данных из тензоров PyTorch, решено использовать функцию свертки из LibTorch на C++. Для нее создается небольшая программа, в которой принимаемое цветное изображение преобразуется в полутоновое, а затем для выделения границ применяются известные ядра.
Сначала в чате Bing от Microsoft генерируем изображение. Применяем функцию свертки с гауссовым и лапласовым ядрами:
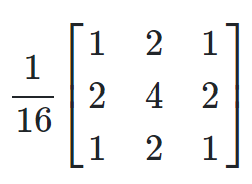
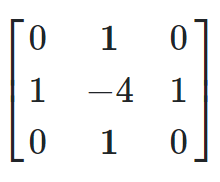
Ядра применены с методом conv2d, который берется из LibTorch на C++ через Tch-rs в таком виде:
Листинг 3. Метод «conv2d», берется из LibTorch через «Tch-rs»
pub fn conv2d<T: Borrow<Tensor>>(
&self,
weight: &Tensor,
bias: Option<T>,
stride: impl IntList,
padding: impl IntList,
dilation: impl IntList,
groups: i64
) -> Tensor
Вот финальная программа:
Листинг 4. Прием изображения и применение операций свертки для выделения границ
use tch::{Tensor, vision::image, Kind, Device};
fn rgb_to_grayscale(tensor: &Tensor) -> Tensor {
let red_channel = tensor.get(0);
let green_channel = tensor.get(1);
let blue_channel = tensor.get(2);
// По формуле светового излучения вычисляется тензор оттенков серого
let grayscale = (red_channel * 0.2989) + (green_channel * 0.5870) + (blue_channel * 0.1140);
grayscale.unsqueeze(0)
}
fn main() {
let mut img = image::load("mypic.jpg").expect("Failed to open image");
img = rgb_to_grayscale(&img).reshape(&[1,1,1024,1024]);
let bias: Tensor = Tensor::full(&[1], 0.0, (Kind::Float, Device::Cpu));
// Определяется и применяется гауссово ядро
let mut k1 = [-1.0, 0.0, 1.0, -2.0, 0.0, 2.0, -1.0, 0.0, 1.0];
for element in k1.iter_mut() {
*element /= 16.0;
}
let kernel1 = Tensor::from_slice(&k1)
.reshape(&[1,1,3,3])
.to_kind(Kind::Float);
img = img.conv2d(&kernel1, Some(&bias), &[1], &[0], &[1], 1);
// Определяется и применяется лапласово ядро
let k2 = [0.0, 1.0, 0.0, 1.0, -4.0, 1.0, 0.0, 1.0, 0.0];
let kernel2 = Tensor::from_slice(&k2)
.reshape(&[1,1,3,3])
.to_kind(Kind::Float);
img = img.conv2d(&kernel2, Some(&bias), &[1], &[0], &[1], 1);
image::save(&img, "filtered.jpg");
}
Вот результат операции:

В этой программе указанные ядра применены для свертки: исходное изображение преобразовано в нужные признаки, то есть границы. Далее рассмотрим реализацию этой идеи в CNN. Основное ее отличие — значение матрицы с ядрами выбирается сетью при обучении, то есть выбираемые из изображения признаки определяются в самой сети настройкой ядра.
Сверточный слой
Типичная структура CNN — это сверточные слои, за каждым из которых имеется слой подвыборки, подводимый затем обычно к полносвязным слоям. Во многом из-за слоя подвыборки, где выборка входных данных уменьшается, количество параметров сокращается.
Вот LeNet-5, одна из первых CNN:
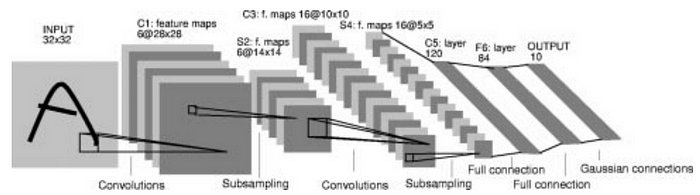
Простая структура с полносвязным слоем уже определена в первой части. Добавим в нее определение сверточного слоя, оно пригодится при определении новых сетевых архитектур, как в листинге 1.
Учитываем, что в программе листинга 4 матрица с ядрами и смещение задаются фиксированными, но теперь определяются как сетевые параметры, обучаемые алгоритмом обучения. Поэтому отслеживаем их градиенты и соответственным образом обновляем.
Новый сверточный слой Conv2d определяется так:
Листинг 5. Новый слой «Conv2d»
pub struct Conv2d {
params: HashMap<String, usize>,
}
impl Conv2d {
pub fn new (mem: &mut Memory, kernel_size: i64, in_channel: i64, out_channel: i64, stride: i64) -> Self {
let mut p = HashMap::new();
p.insert("kernel".to_string(), mem.new_push(&[out_channel, in_channel, kernel_size, kernel_size], true));
p.insert("bias".to_string(), mem.push(Tensor::full(&[out_channel], 0.0, (Kind::Float, Device::Cpu)).requires_grad_(true)));
p.insert("stride".to_string(), mem.push(Tensor::from(stride as i64)));
Self {
params: p,
}
}
}
impl Compute for Conv2d {
fn forward (&self, mem: &Memory, input: &Tensor) -> Tensor {
let kernel = mem.get(self.params.get(&"kernel".to_string()).unwrap());
let stride: i64 = mem.get(self.params.get(&"stride".to_string()).unwrap()).int64_value(&[]);
let bias = mem.get(self.params.get(&"bias".to_string()).unwrap());
input.conv2d(&kernel, Some(bias), &[stride], 0, &[1], 1)
}
}
Напомню: в структуре имеется поле params. Это коллекция типа HashMap, в типе ключа которого String хранится имя параметра, а в типе значения usize содержится местоположение конкретного параметра, то есть тензора PyTorch, в Memory, где, в свою очередь, хранятся все параметры модели.
В случае сверточного слоя в ассоциированной функции new в HashMap вставляется два параметра: Kernel и bias. При этом флагу required_gradient задается значение True. Добавляем и параметр Stride, хотя не задаем его обучаемым.
Затем реализуем в сверточном слое типаж Compute. Для этого определяется функция forward, вызываемая во время прямого прохода процесса обучения. В ней сначала с помощью метода get получаем ссылку на тензоры kernel, bias и stride из хранилища тензоров, затем вызываем функцию Conv2d — как в программе, только в этом случае в сети указывается используемое ядро. Жестко задан нулевой отступ, хотя этот параметр добавить не сложнее, чем Stride.
Вот и все. Это единственное добавление к начатому в первой части фреймворку для определения и обучения CNN согласно листингам 1 и 2.
Оптимизация Adam
В прошлой статье запрограммировано два алгоритма обучения: стохастического градиентного спуска и стохастического градиентного спуска с импульсом. Не менее популярен алгоритм Adam — закодируем на Rust и его.
В алгоритме Adam, впервые опубликованном в 2015 году, сочетаются идеи алгоритмов обучения Momentum и RMSProp:

В первой части мы реализовали тензор в Memory, а также позаботились о методах apply_grads_sgd и apply_grads_sgd_momentum — эквиваленте имеющейся на PyTorch функции step для градиентов. Добавляем метод new в реализацию структуры Memory, где с помощью Adam выполняется обновление градиентов:
Листинг 6. Реализация «Adam»
fn apply_grads_adam(&mut self, learning_rate: f32) {
let mut g = Tensor::new();
const BETA:f32 = 0.9;
let mut velocity = Tensor::zeros(&[self.size as i64], (Kind::Float, Device::Cpu)).split(1, 0);
let mut mom = Tensor::zeros(&[self.size as i64], (Kind::Float, Device::Cpu)).split(1, 0);
let mut vel_corr = Tensor::zeros(&[self.size as i64], (Kind::Float, Device::Cpu)).split(1, 0);
let mut mom_corr = Tensor::zeros(&[self.size as i64], (Kind::Float, Device::Cpu)).split(1, 0);
let mut counter = 0;
self.values
.iter_mut()
.for_each(|t| {
if t.requires_grad() {
g = t.grad();
mom[counter] = BETA * &mom[counter] + (1.0 - BETA) * &g;
velocity[counter] = BETA * &velocity[counter] + (1.0 - BETA) * (&g.pow(&Tensor::from(2)));
mom_corr[counter] = &mom[counter] / (Tensor::from(1.0 - BETA).pow(&Tensor::from(2)));
vel_corr[counter] = &velocity[counter] / (Tensor::from(1.0 - BETA).pow(&Tensor::from(2)));
t.set_data(&(t.data() - learning_rate * (&mom_corr[counter] / (&velocity[counter].sqrt() + 0.0000001))));
t.zero_grad();
}
counter += 1;
});
}
Результаты и мнения
Как и в первой части, объективность сравнения рассмотренного кода с его эквивалентом на Python и PyTorch обеспечивается главным образом применением одинаковых гиперпараметров нейросети, алгоритмов и параметров обучения. Для тестов, запускаемых на том же ноутбуке Surface Pro 8, i7 с 16 Гб оперативной памяти и без графического процессора, применялся тот же набор данных Mnist.
В ходе многократных прогонов на Rust отмечался в среднем 60%-ный рост скорости обучения по сравнению с эквивалентом на Python. Это немало, но все же скромнее достигнутого в полносвязных сетях первой части. Меньший прирост объясняется тем, что самое затратное вычисление в CNN — это свертка и использовалась функция conv2d из LibTorch на C++, в целом та же, что вызывается эквивалентом на Python. Тем не менее сокращение времени на обучение модели более чем наполовину не следует игнорировать — это экономия многих часов, а то и дней.
Использованные материалы
Ян Гудфеллоу, Йошуа Бенджио и Аарон Курвилль, «Глубокое обучение», MIT Press, 2016 г.
Павел Карас и Давид Свобода, «Алгоритмы для эффективного вычисления свертки», в разделе «Дизайн и архитектуры цифровой обработки сигналов», Нью-Йорк, штат Нью-Йорк, США: IntechOpen, янв. 2013 г.
Янн Лекун, Леон Ботту, Йошуа Бенджио и Патрик Хаффнер, «Обучение на основе градиента, применяемое для распознавания документов», материалы Конференции IEEE 86, 2278–2324, 1998 г.
Дьедерик П. Кингма и Джимми Ба, «Adam: метод стохастической оптимизации», в материалах 3-й Международной конференции по обучению представлениям (ICLR), 2015 г.
Читайте также:
- Фича-флаги времени компиляции в Rust: зачем, как и когда используются
- Как создать API-шлюз в Rust посредством библиотеки Hyper
- Разработка макроса Rust для автоматического написания шаблонного кода SQL
Читайте нас в Telegram, VK и Дзен
Перевод статьи Vince Vella: Boosting Machine Learning Performance With Rust (Part 2)





