
Шаблон «Репозиторий» используется в проектах Laravel немного неоднозначно. У разработчиков разные потребности и мотивация: одни придерживаются классических определений, другие применяют этот шаблон для дампа запросов.
Рассмотрим преимущества и недостатки шаблона «Репозиторий» и три альтернативы для построения кодовой базы на основе запросов.
Прочитав эту статью, вы научитесь применять:
- заготовки Eloquent;
- пользовательские запросы;
- классы action.
Что такой шаблон «Репозиторий»?
Это слой абстракции между хранилищем данных и бизнес-логикой, хорошее применение принципа инверсии зависимостей для работы с абстрактными интерфейсами, а не конкретными реализациями:

Основные преимущества:
- разделение обязанностей;
- многократное применение;
- кеширование данных, к которым осуществляется доступ;
- заменяемость;
- тестируемость.
Реализация
В шаблоне «Репозиторий» нужны интерфейсы и конкретная реализация каждого уровня хранилища. В примере ниже показано отдельное хранилище для доступа к данным через кеш BookCacheRepository:
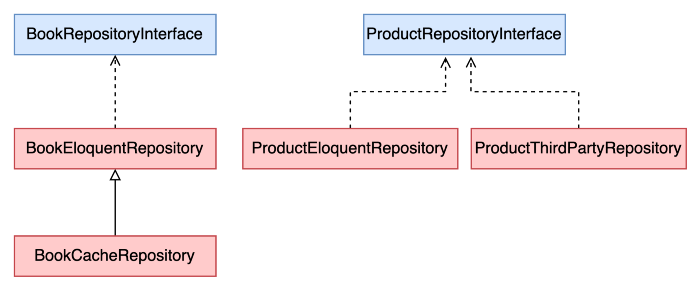
Другой вариант — кешировать результаты прямо в главном репозитории. Подробнее об этом позже.
Пример на Laravel:
// Сначала привязываем интерфейсы к реализации.
class AppServiceProvider extends ServiceProvider
// ...
public function register(): void
{
$this->app->bind(BookRepositoryInterface::class, BookEloquentRepostiory::class);
$this->app->bind(ProductRepositoryInterface::class, ProductThirdPartyRepostiory::class);
}
}
// Затем с помощью внедрения зависимостей применяем это в бизнес-логике.
class FooController extends Controller
{
public function __invoke(BookRepositoryInterface $repostiory)
{
// ...
$data = $repostiory->get();
}
}
В этом примере привязка жестко задана. Бывает еще динамическая привязка, например, к определенному репозиторию в зависимости от того, является ли запрос веб-запросом или API-вызовом.
Основные преимущества
Рассмотрим две отличительные особенности шаблона: заменяемость и тестируемость. С остальными все понятно.
Заменяемость
Благодаря принципу инверсии зависимостей бизнес-логика не зависит от реализации. То есть детали реализации легко поменять, не затрагивая бизнес-логики.
Допустим, вы поручили учет запасов своего магазина стороннему сервису, у которого для обмена данными с ним имеется API. Бизнес-логика привязана к ProductRepositoryInterface. Вместо базы данных создаете новую реализацию для взаимодействия с API и привязываете ее к указанному интерфейсу в контейнере. Все будет как надо.
Нет ли здесь подвоха?
Почти все примеры шаблона «Репозиторий» на Laravel связаны с Eloquent и ее коллекциями, поэтому Eloquent нельзя заменить на другое хранилище данных или ORM.
Не следует связывать с ней интерфейсы, тогда замена возможна. При использовании другого слоя данных, скорее всего, Eloquent вами больше не задействуется.
Правда, в примере API выше можно еще гидратировать результаты в модели Eloquent. Но это рискованно, потому что Eloquent — реализация шаблона Active Record, а это запись реляционной БД с возможностью ее обновления и сохранения.
Краткий вывод
Замена реализации — перспективная концепция. Но, чтобы правильно выполнить замену, не следует связывать ее с Eloquent. Исключение — использование шаблона «Репозиторий» только для разделения слоев данных и кеширования, как показано на схеме 2 выше, или для моков/фейков (см. ниже).
Уверены, что замените реализацию? Тогда вперед! В противном случае придерживайтесь YAGNI: редко в проекте Laravel вам понадобится что-то, кроме Eloquent.
Тестируемость
Благодаря заменяемости возможны разные реализации тестов без взаимодействия с реальной БД — тестовые mock/fake-объекты.
Основное их преимущество — быстрые тесты, менее подверженные случайным сбоям.
Кто-то предпочитает базу данных в памяти, такую как SQLite. Хотелось упомянуть о ней здесь, поскольку преимущества и концепции те же, а значит, и недостатки.
Проблема в том, что это рискованно: у тестов неопределенные результаты, они выполняются не на той же БД, где запускается рабочий сервер.
Нельзя утверждать, что в работе базы данных в разных ситуациях исключены неожиданности: остановка рабочего сервера после развертывания несовместимого с БД изменения или системная ошибка из-за различий в поведении по умолчанию каждой СУБД.
Как сделать тесты быстрыми и отказоустойчивыми без имитирования?
В Laravel имеется типаж RefreshDatabase для упрощения тестирования с реальными БД. Каждый раз у вас будет небольшой набор данных и чистое состояние.
Краткий вывод
Запускать тесты на реальном зеркале рабочей БД безопаснее, но медленнее. Избегайте замен, mock-объектов и использования разных баз данных во время тестов. Тестируйте то, что используется на рабочем сервере.
Почему шаблону «Репозиторий» не угнаться за растущими проектами?
Для простых проектов шаблона «Репозиторий» достаточно. Но с добавлением бизнес-логики эти репозитории усложняются.
Возьмем репозиторий с методом all для получения всех книг. Добавим платные книги и подписку на них. Теперь этим all вернем для подписавшихся пользователей все книги, а для неподписавшихся — только бесплатные.
Для этого добавляем:
- к
allпараметр, например объект пользователя или флаг, для отфильтровывания книг; - метод
allWithoutPremiumдля неподписавшихся пользователей; - отдельный репозиторий для подписавшихся.
Дальше вводим новый функционал: анонимные книги и роли. Авторов видят только пользователи с ролью администратора. Нужно условно загрузить это соотношение.
Какие изменения внесете в репозиторий?
Заметили здесь проблему с растущим проектом? Репозитории обычно плохо масштабируются. Когда логика усложняется, в них легко накапливается код с запашком. В итоге они получаются огромными по размеру и когнитивной нагрузке.
Чтобы решить эту проблему и сделать кодовую базу удобнее для восприятия и сопровождения, изучим три альтернативы.
Альтернативы шаблону «Репозиторий»
Рассмотрим альтернативные методы абстрагирования запросов от бизнес-логики с получением пригодного для тестирования, удобного для восприятия и сопровождения кода. Альтернативы не заменяют шаблон «Репозиторий» 1 в 1. Это способы инкапсуляции доступа к данным и манипулирования ими.
Заготовки Eloquent
С Eloquent как ORM при работе в коде с заготовками придерживаемся принципа DRY.
Заготовки — это самая примитивная и низкоуровневая альтернатива. С ее помощью для моделей накладываются общие ограничения.
Продолжим пример с книгами, нужно условно загрузить только бесплатные книги или все, в том числе платные. И исходя из того, авторизован пользователь или нет.
Использование заготовок для состояний книг в этом случае — отличная идея:
<?php
namespace App\Models;
use Illuminate\Database\Eloquent\Model;
class Book extends Model
{
public function scopeWhereFree(Builder $query): void
{
$query->where('is_premium', false);
}
public function scopeWherePublished(Builder $query): void
{
$query->whereNotNull('published_at');
}
}
Эта заготовка используется в коде так:
<?php
use App\Models\Book;
// ...
Book::query()
->wherePublished()
->when(!Auth::user()?->isPremium(), fn(Builder $query) => $query->whereFree())
->latest()
->limit(10)
->get();
Таким запросом загрузятся все книги по умолчанию. Если же пользователь не авторизован или не подписался, в результатах будут только бесплатные книги.
Используя заготовки, вы создаете одно место, в котором содержатся критерии. Захотите поменять то, что считать бесплатной или опубликованной книгой? Измените заготовку.
Заготовки — отличный строительный блок для следующих вариантов, применяются и в репозиториях.
Чтобы расширить конструктор запросов модели и уменьшить сами модели, используйте конструкторы пользовательских запросов Laravel.
Пользовательские запросы
Пользовательский запрос — это способ определить сложные ограничения для извлечения данных в бизнес-контексте. В репозитории это не сложный метод, а автономные классы.
Можно провести связь между пользовательским запросом и заготовкой: если вы задумались об ограничении данных, упорядочивании, кешировании, объединениях или любой другой пользовательской логике, то стоит применить пользовательский запрос.
Пример
Чтобы получить набор платных книг конкретной категории, нужно извлечь предопределенное количество книг и упорядочить их по дате.
Когда категория архивируется, извлекаются только книги без пользователей. Большого смысла здесь нет, это просто ради примера.
Получается такой пользовательский запрос:
<?php
namespace App\Queries\Books;
class LatestPremiumBooksOfCategoryQuery
{
public function __constructor(
private readonly Category $category,
private readonly ?int $limit = null,
): void
{
$this->limit ??= config('categories.limit');
}
/**
* @return Collection<Book>
*/
public function get(): Collection
{
return $this
->category
->books()
->wherePublished()
->wherePremium()
->when($this->category->isArchived(), fn(Builder $builder) => $builder->whereNull('books.user_id'))
->latest()
->take($this->limit)
->get();
}
// применение
(new LatestPremiumBooksOfCategoryQuery($category))->get();
В этом примере только один открытый метод для получения всех результатов. Но добавляется сколько угодно открытых точек доступа, например paginate() для получения данных с разбивкой по страницам. Из общей части выносится отдельный закрытый метод, например query().
Стратегия кеширования
В запросе выше нет кеширования. Результаты кешируются двояко: все данные или только идентификаторы*.
* В следующий раз после кеширования идентификаторов данные извлекаются выполнением where in, это быстрее исходных фильтров — в первую очередь при поиске идентификаторов. Аналогично SerializesModels на Laravel для задач.
Преимущества и недостатки

У этих стратегий практически противоположные преимущества и недостатки. Комбинируйте стратегии в зависимости от того, что кешируется и как это применяется.
Правила
Согласованность обеспечивается набором правил их применения в организации.
В Studocu правила такие.
Допустимо:
- Отношения безотложной загрузки.
- Определение Select/Where/Joins/OrderBy/Limit в запросах.
- Работа с кешем.
- Раскрытие всех методов — но только не конструктора — точек доступа сценария использования, таких как get и first.
Не допустимо:
- Работа со слоем представления данных, например возвращение JsonResource.
- Выполнение запросов, кроме SELECT.
Тестирование
Цель пользовательского запроса — точное извлечение нужных данных. Важно подтвердить корректность извлечения.
Нужно убедиться, что у теста максимально определенные результаты. Например, чтобы протестировать приведенный выше запрос, необходимо обеспечить:
- отбор книг целевой и других категорий с критериями и без критериев;
- предсказуемое упорядочение книг.
Так обеспечивается селективность запроса относительно получаемых им данных.
При тестировании запросов нужно проверять их на:
- фильтрацию по внешним ключам, состояниям и пороговым значениям;
- упорядочение;
- ограничение.
Вот пример тестирования нашего пользовательского запроса:
<?php
class LatestPremiumBooksOfCategoryQueryTest extends TestCase
{
use RefreshDatabase;
use WithFaker;
private const LIMIT = 5;
/** @test */
public function it_works_for_non_archived_categories(): void
{
// Упорядочение
$categories = Category::factory()->count(4)->create()->shuffle();
$targetCategory = $categories->pop();
$expectedBooks = $this->seedBooks($targetCategory);
$categories
->each(function (Category $category) {
// Отсев книг, которые не должны быть включены.
$this->seedBooks($category);
});
// Действие
$result = (new LatestPremiumBooksOfCategoryQuery($targetCategory, self::LIMIT))->get();
// Подтверждение
$this->assertCount(self::LIMIT, $result);
$this->assertEquals(
$expectedBooks->toArray(),
$result->toArray(),
);
}
}
Весь тест здесь.
Дальше запросы инкапсулируются с помощью пакета ViewModels из Spatie: реализация будет беспроблемной.
Выводы
За классами пользовательских запросов скрыта вся цепочка конструктора с возможностью адаптации ко многим сценариям применения, например кешированию результатов с необязательной сериализацией, повторному использованию результатов других запросов, включая пользовательские, ранним завершениям, динамическим пустым состояниям, пользовательской безотложной загрузке, принятию параметров запроса и действиям в соответствии с ними и т. д.
Классы action
Action — это класс для выполнения специфичных для предметной области задач: от простых операций создания, обновления или удаления данных до выполнения сложной логики, например объединения двух моделей и переноса всех соответствующих данных из одной в другую.
Это такая CUD-часть репозитория, то есть CRUD, плюс бизнес-логика сервиса.
Классы action активно используются повторно в различных приложениях и компонуются друг с другом.
Реализация
Для классов action стандартизированной практики на Laravel нет: здесь встречаются различные реализации. Но все они крутятся вокруг одной концепции. Отрегулировать детали реализации для своей организации — хорошая идея.
В Studocu правила такие:
- Классы action не должны быть расширены или расширяться. Будем полагаться на компоновку. Возможно применение ключевого слова final, но тогда во время тестирования нельзя использовать mock-объекты для классов action. Если только не проводить тестирование «черного ящика», когда action не тестируются изолированно.
- Чтобы разрешать зависимости, с классами action в конструкторе должно использоваться внедрение зависимостей. Поэтому их тоже нужно внедрять.
- У классов action должен быть только один открытый метод —
execute. Параметры и возвращаемое в методе у каждого класса разные. Все остальные методы и свойства следует объявлять как закрытые. - В методе
executeпринимается максимум один параметр. Нужно больше? Используйте объект переноса данных DTO, с ним action становится многоразовым. DTO создаются с помощью фабрик на основе контекста, в котором применяются.
Классы action в действии
Создадим action для публикации книг. С его помощью будем:
- Сохранять того, кто делал операцию.
- Делать книгу платной, если нужно.
- Отправлять событие book published («Книга опубликована») для запуска прослушивателей событий. Например, отправлять электронные письма пользователям о том, что доступна новая книга.
С учетом этого создаем такой action:
<?php
class PublishBookAction
{
public function execute(PublishBookData $data): void
{
$data->book->markAsPublishedBy($data->user);
if ($data->shouldBePremium) {
$data->book->markAsPremium();
}
$data->book->save();
event(new BookPublishedEvent($data->book));
}
}
<?php
final class PublishBookData
{
public function __construct(
public readonly Book $book,
public readonly User $user,
public readonly bool $shouldBePremium,
) {
}
public static function fromBookPublishRequest(PublishBookStoreRequest $request): self
{
$data = $request->validated();
$book = Book::findOrFail($request->route('book_id'));
return new self(
book: $book,
user: $request->user(),
shouldBePremium: $data['should_be_premium'] ?? false,
);
}
}
Выводы
В этом примере мы применили action для публикации книги с соблюдением бизнес-правил и перенесли данные, использовав специальные DTO для классов action.
Этими DTO ведется работа с запросами и инициализацией всех необходимых для action входных данных. Чтобы упростить инстанцирование классов из разных контекстов, мы использовали статические фабричные методы.
Подробнее о классах action, различных вариантах использования и их компоновке читайте здесь.
Тестирование
Классы action тестируются изолированно или в рамках стратегии «черного ящика». Можно выбрать оба подхода вместе — все зависит от вас и вашей организации.
К тестированию «черного ящика» прибегают при разработке через тестирование, значительно упрощая этим рефакторинг. Тесты будут служить основой для документации и проверки функционала.
Вот пример тестирования «черным ящиком» конечной точки публикации книги:
class PublishBookTest extends TestCase
{
use RefreshDatabase;
/**
* @dataProvider publishBookDataProvider
* @test
*/
public function it_publishes_books(array $requestParams, bool $expectedToBePremium): void
{
// Упорядочение
Event::fake();
$book = Book::factory()->free()->unpublished()->create();
$user = User::factory()->create();
Carbon::setTestNow(today());
// Действие
$response = $this
->actingAs($user)
->postJson(route('books.publish', ['book_id' => $book->id, ...$requestParams]));
// Подтверждение
$response->assertOk();
$book->refresh();
$this->assertEquals($expectedToBePremium, $book->isPremium());
$this->assertEquals($user->id, $book->published_by);
$this->assertEquals(today(), $book->published_at);
Event::assertDispatched(
BookPublishedEvent::class,
fn (BookPublishedEvent $event) => $event->book->is($book),
);
}
public function publishBookDataProvider(): array
{
return [
'it publish book as free book [explicit]' => [
'params' => [
'should_be_premium' => false,
],
'expectedToBePremium' => false,
],
'it publish book as free book [implicit]' => [
'params' => [],
'expectedToBePremium' => false,
],
'it publish book as premium book' => [
'params' => [
'should_be_premium' => true,
],
'expectedToBePremium' => true,
],
];
}
}
Чтобы не перегружать статью, в этом примере показан только один тест. Все тесты здесь.
Заключение
Мы рассмотрели преимущества и недостатки шаблона «Репозиторий». В основном заменяемость, благодаря которой части приложения выводятся вовне, разделяются слои данных и кеширования или ускоряются тесты.
Затем мы изучили три альтернативы абстрагирования управления данными:
- заготовки Laravel для загрузки Eloquent связанными с бизнесом запросами;
- пользовательские запросы для извлечения и кеширования сложных данных;
- классы action для манипулирования данными.
В завершение подчеркнем, что эти альтернативы вы не должны, но, скорее, можете использовать.
Загляните в репозиторий GitHub, там есть все примеры.
Читайте также:
- Laravel: неизвестный, но эффективный способ реализации фильтров в Eloquent
- Топ-10 бэкенд-фреймворков для веб-разработки в 2022 году
- PHP: создание и публикация пакета composer
Читайте нас в Telegram, VK и Дзен
Перевод статьи Mazen Touati: You might not need a repository in Laravel: 3 alternatives





