
Любой проект по науке о данных нуждается в данных. Чтобы извлечь их с сайта и создать необходимый набор, используются инструменты веб-скрейпинга.
Однако на одном сайте не всегда находятся все нужные данные либо там могут быть несоответствия, из-за которых можно извлечь только часть данных.
Так случилось со мной, когда я искал данные о футбольных матчах, проведенных на Чемпионатах мира с 1930 по 2022 год. Некоторые данные были извлечены, но не все. С помощью этого руководства мы извлечем остальные данные с нуля с помощью Selenium, чтобы в дальнейшем использовать их в проекте.
Шаг 1. Установка Selenium
Чтобы установить Selenium, откроем терминал и выполним следующую команду:
pip install selenium
Теперь загрузите версию Chromedriver, подходящую для вашего компьютера.
- Проверьте версию вашего Google Chrome (нажмите на три точки, кликните на “help”, а затем выберите “about Google Chrome”).
- Скачайте нужную версию Chromedriver здесь (после обновления Chrome скачайте файл снова).
- Распакуйте скачанный файл и скопируйте путь к файлу Chromedriver.
Шаг 2. Веб-скрейпинг одной страницы
Чтобы извлечь данные с сайта, сначала нужно импортировать все необходимые для этого библиотеки.
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
import time
import pandas as pd
- Selenium — для сбора данных.
- Time — для добавления времени ожидания при автоматизации сайта.
- Pandas — для организации извлеченных данных в датафреймы.
Каждый раз, проводя скрейпинг сайта с помощью Selenium, необходимо определять следующие переменные.
path— местонахождения файла Chromedriver.web— сайт, который вы собираетесь скрейпить (мы будем скрейпить эту страницу).driver— объект, который поможет проводить скрейпинг сайта.
path = # Здесь прописываем путь
service = Service(executable_path=path)
driver = webdriver.Chrome(service=service)
web = 'https://en.wikipedia.org/wiki/1982_FIFA_World_Cup'
Теперь, чтобы открыть Chromedriver и перейти на целевой сайт, выполним следующую строку кода:
driver.get(web)
Появится новое окно с сообщением “Chrome is controlled by automated test software” (“Chrome управляется автоматизированным тестовым программным обеспечением”).
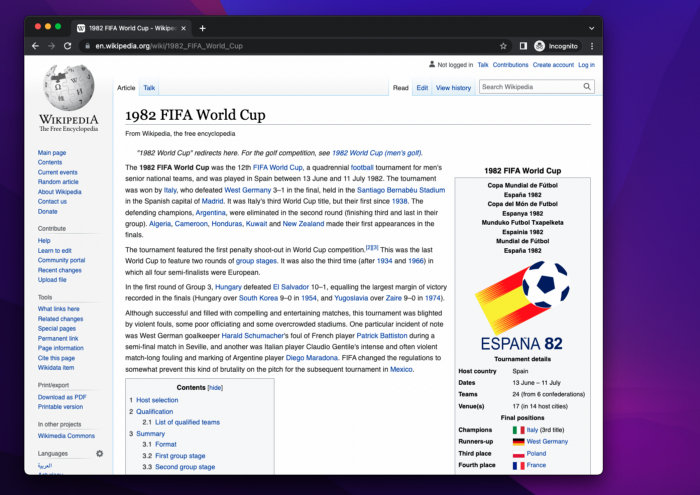
Теперь нужно посмотреть HTML-код, стоящий за элементами, которые нужно извлечь. Для этого прокрутим страницу вниз, пока не найдем данные о футбольных матчах, затем щелкнем правой кнопкой мыши и выберем “Inspect”.
Откроются инструменты разработчика. Нужно нажать на кнопку выбора (значок курсора слева) и найти строку, содержащую информацию о футбольном матче.
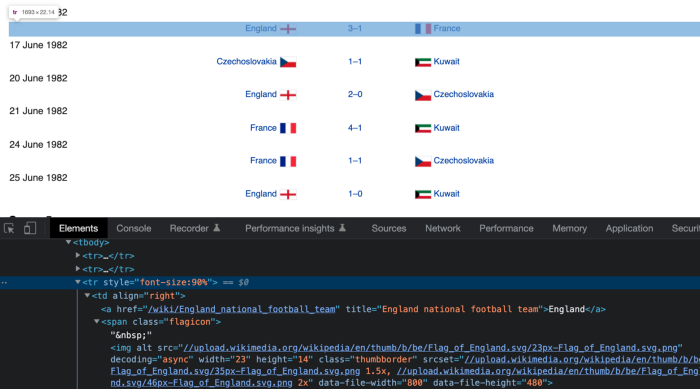
После выделения строки получим HTML-элемент, который стоит за ней.
<tr style="font-size:90%">
Теперь, чтобы найти этот элемент с помощью Selenium, нужно создать его XPath. Вот синтаксис XPath:

Если заменить каждый элемент, получим следующее:
//tr[@style="font-size:90%"]
Создав XPath, мы можем использовать .find_elements для поиска такого элемента с помощью Selenium.
matches = driver.find_elements(by='xpath', value='//tr[@style="font-size:90%"]')
Переменная matches — это список, содержащий 48 строк/матчей, перечисленных на сайте. Пройдясь по этому списку, получим все элементы td, поскольку они являются дочерними узлами элемента tr, XPath которого мы создали ранее.
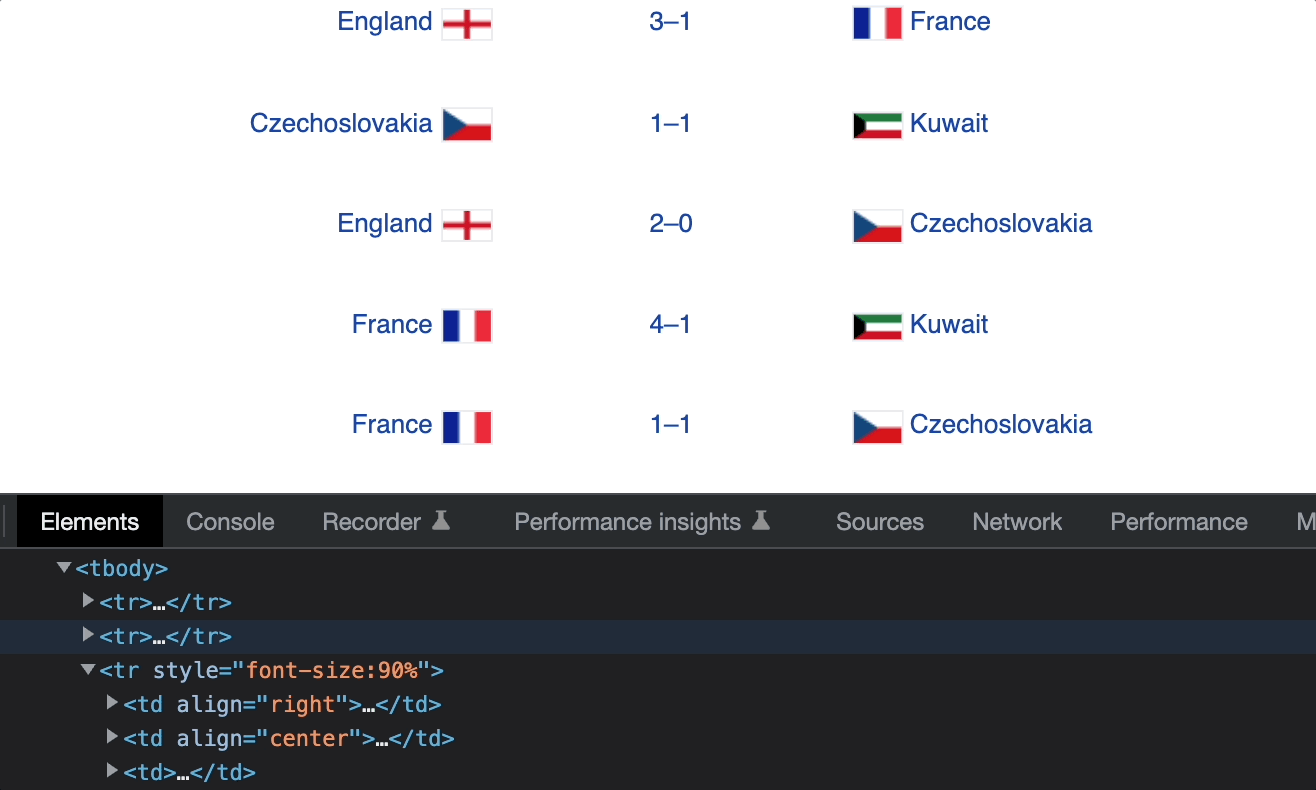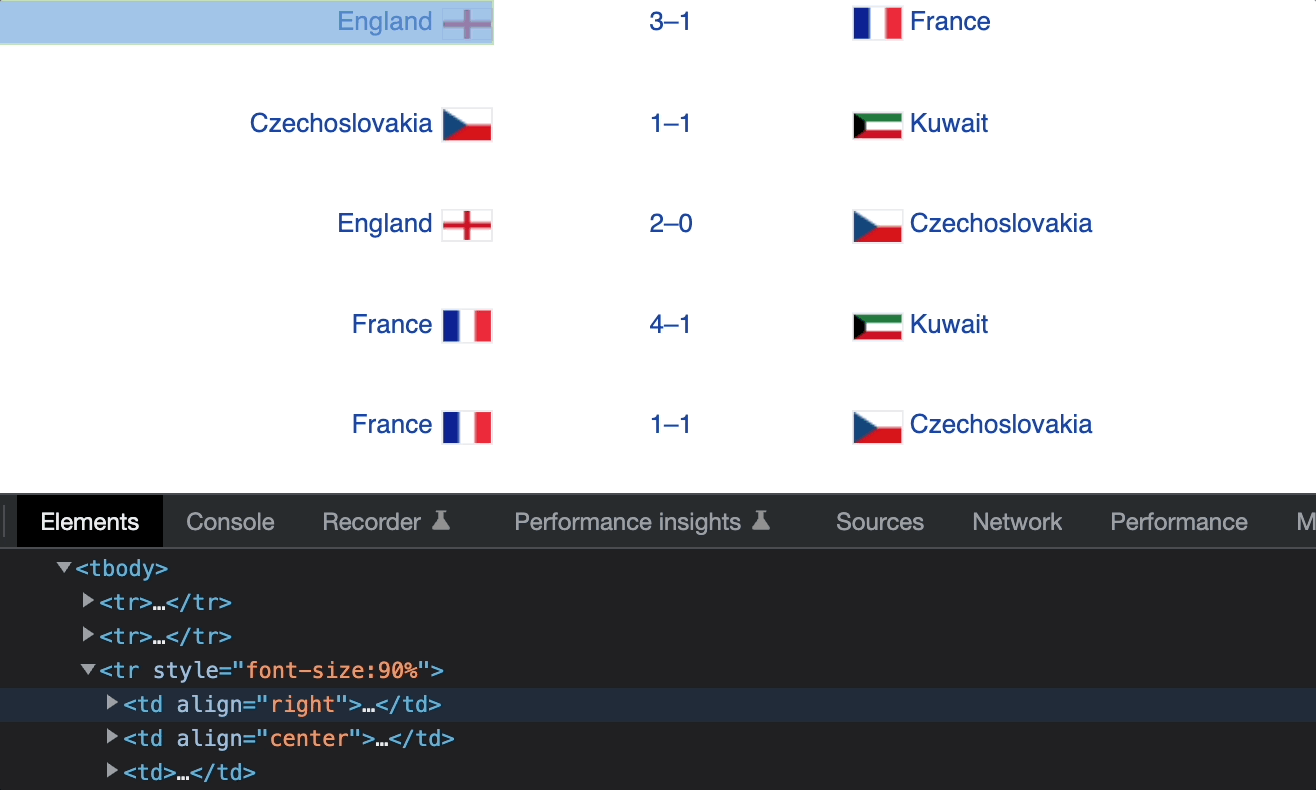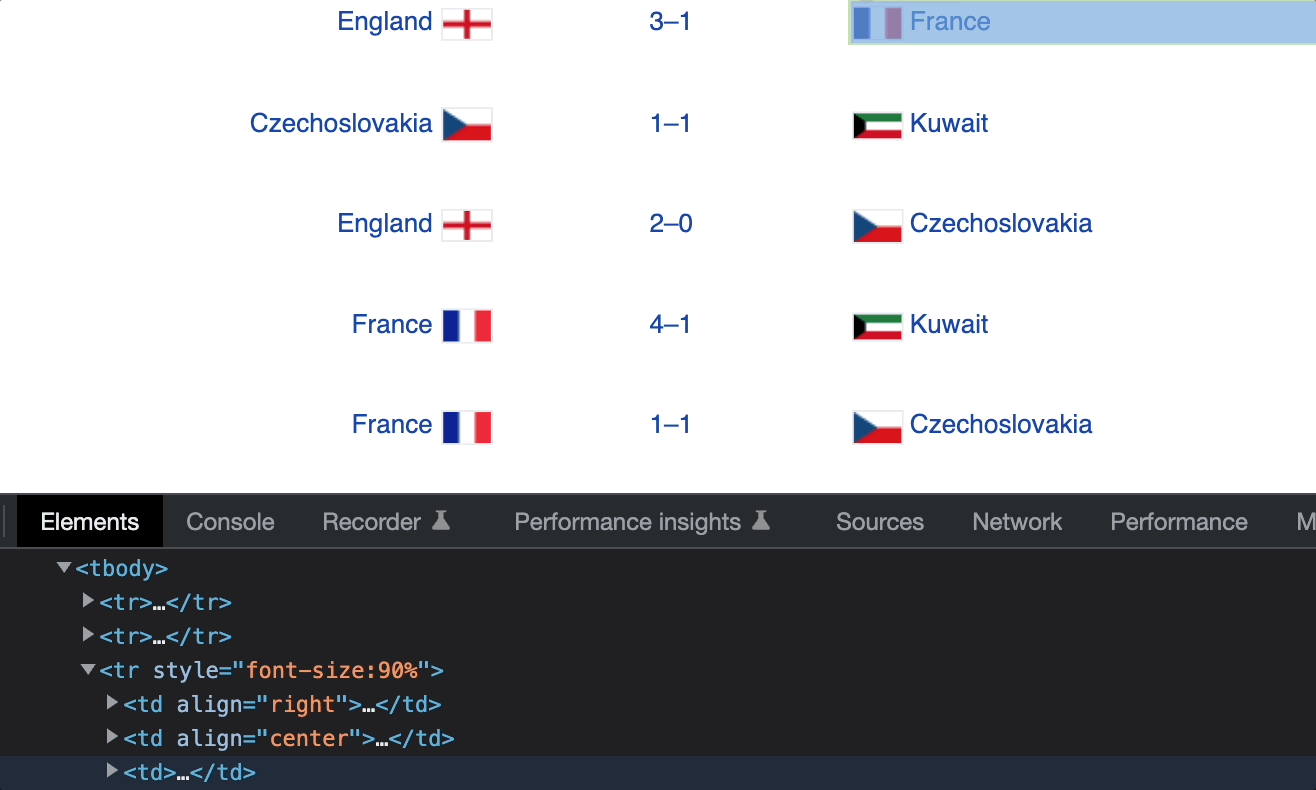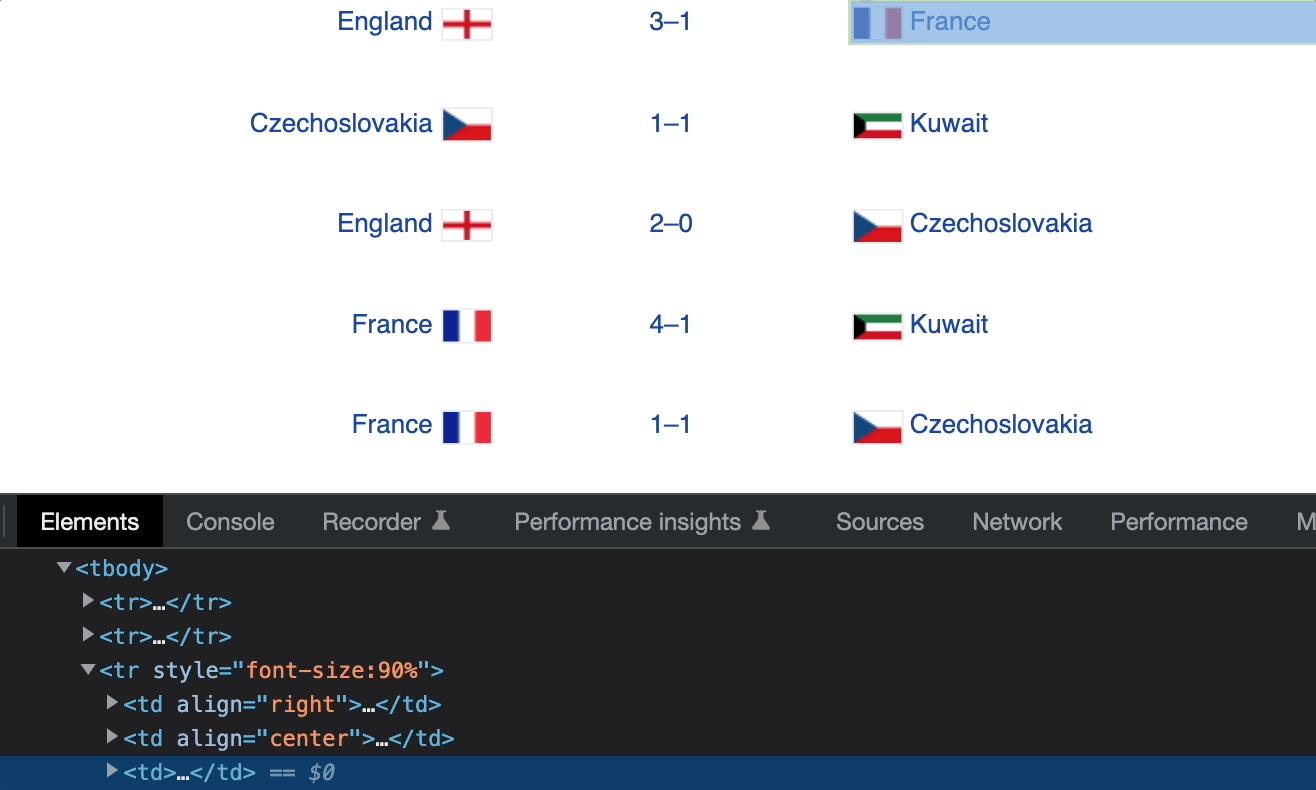
Элементы td содержат данные о команде хозяев поля, счете и команде-гостье. Мы можем получить эти данные с помощью следующих XPath.
/td[1]— команда хозяев поля./td[2]— счет./td[3]— команда-гостья.
Пройдемся по matches и сохраним данные в пустых списках, которые назовем home (хозяева), score (счет) и away (гости).
home = []
score = []
away = []
for match in matches:
home.append(match.find_element(by='xpath', value='./td[1]').text)
score.append(match.find_element(by='xpath', value='./td[2]').text)
away.append(match.find_element(by='xpath', value='./td[3]').text)
Обратите внимание на добавление . перед исходным /td XPath. Это связано с тем, что теперь используется не driver.find_element, а match.find_element (символ . указывает на то, что поиск начинается с узла match).
Кроме того, добавляется атрибут text, чтобы получить текст, содержащийся в узле (например, Англия, 3–1, Франция).
Наконец, создаем датафрейм из списков home, score и away. Добавляем новый столбец year (год), время ожидания — 2 секунды (это необязательно) и выходим из driver’а.
dict_football = {'home': home, 'score': score, 'away': away}
df_football = pd.DataFrame(dict_football)
df_football['year'] = 1982
time.sleep(2)
driver.quit()
Для экспорта датафрейма используем .to_csv.
df_football.to_csv("fifa_worldcup_missing_data.csv", index=False)
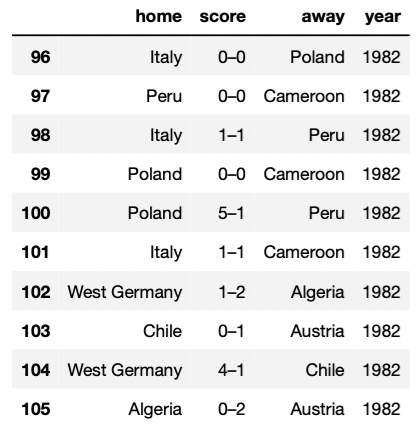
Экспортированные данные должны выглядеть так, как показано на изображении ниже, и содержать 48 строк.
Код, написанный до этих пор, можно найти на GitHub. Теперь, немного подправив код, проведем скрейпинг уже не одной, а нескольких страниц.
Шаг 3. Создание функции для скрейпинга нескольких страниц
Самое интересное в веб-скрейпинге — возможность провести его на нескольких страницах после выполнения на одной (при условии, что все страницы имеют одинаковую структуру).
Вот функция, которая позволяет это сделать:
def get_misssing_data(year):
web = f'https://en.wikipedia.org/wiki/{year}_FIFA_World_Cup'
driver.get(web)
matches = driver.find_elements(by='xpath', value='//tr[@style="font-size:90%"]')
home = []
score = []
away = []
for match in matches:
home.append(match.find_element(by='xpath', value='./td[1]').text)
score.append(match.find_element(by='xpath', value='./td[2]').text)
away.append(match.find_element(by='xpath', value='./td[3]').text)
dict_football = {'home': home, 'score': score, 'away': away}
df_football = pd.DataFrame(dict_football)
df_football['year'] = year
time.sleep(2)
return df_football
Обратите внимание, что данная функция использует year в качестве входных данных. Переменная year помещена в ссылку web и столбец df_football[‘year’]. Остальное остается неизменным.
Запустив get_misssing_data(1982), получим тот же результат, что и в шаге 2.
Чтобы извлечь данные с нескольких страниц, создадим список years, содержащий все годы, в которые проводился Чемпионат мира.
years = [1930, 1934, 1938, 1950, 1954, 1958, 1962, 1966, 1970, 1974,
1978, 1982, 1986, 1990, 1994, 1998, 2002, 2006, 2010, 2014,
2018]
Теперь с помощью генератора списков проскрейпим страницу, соответствующую каждому году, и сохраним данные в списке с именем fifa. Соберем все списки вместе с помощью .concat и, наконец, экспортируем эти данные в CSV.
fifa = [get_misssing_data(year) for year in years]
driver.quit()
df_fifa = pd.concat(fifa, ignore_index=True)
df_fifa.to_csv("fifa_worldcup_missing_data.csv", index=False)
Теперь в CSV-файле должны быть сотни строк, содержащих все извлеченные данные.
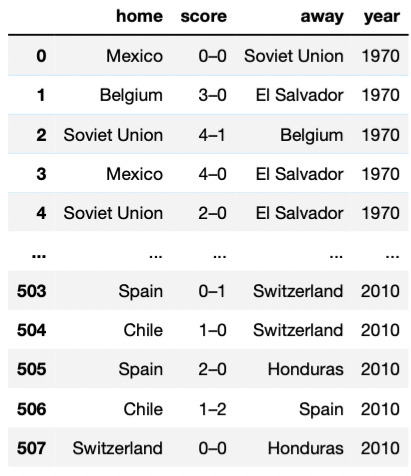
Поздравляем! Вы научились создавать датасеты с помощью Selenium.
Читайте также:
- Python + Selenium: как получить координаты по адресам
- Как я устроил пожизненный запас чесночных пицца-палочек с помощью Python и Selenium
- Настройте свой Jupyter Notebook правильно
Читайте нас в Telegram, VK и Дзен
Перевод статьи Frank Andrade: How to Collect Data for a Data Science Project with Python (in 3 Steps)

")



