
Для начала позволю себе заметить, что в интернете есть много качественного технического контента, посвященного оцениванию моделей. Такие метрики, как F1-score (гармоническое среднее), MSE (средняя квадратическая ошибка), MAE (среднее абсолютное отклонение), Huber Loss (функция потерь Хьюбера), precision (точность), recall (полнота), cross-entropy loss (потери перекрестной энтропии) и многие другие, детально описаны на различных платформах. Однако эти метрики обычно фокусируются на подгонке модели к данным, а не на оптимизации ее для конкретного бизнеса.
Чего зачастую не хватает, так это инструментов экономического анализа для оптимизации полезности модели. Полезность определяется просто как удовольствие или ценность, которые клиент может получить от услуги — в данном случае от модели МО.
Хотя эта концепция не преподается будущим специалистам МО, я уверен: экономический анализ и оценка полезности имеют большое значение для создания практичных и долговечных моделей в реальном мире. Пока все заинтересованные стороны (технические и нетехнические работники) совместно не создадут экономический слой МО-модели, бизнес-ценность и предельную полезность машинного обучения можно считать неопределенными.
Примечание. Эта публикация предназначена для технических МО-специалистов, а также для менеджеров по продуктам и менее технически подготовленных заинтересованных лиц, работающих с ИИ-продуктами. Здесь будет немного математики, но в заключительный раздел включены высокоэффективные концептуальные шаги.
Пример МО с бинарным классификатором
Представьте, что у вас есть во всем сомневающийся товарищ, который никогда не знает, стоит ли смотреть новый фильм. Вы, как настоящий друг и продвинутый специалист в области МО, решаете создать простую модель — бинарный классификатор, — чтобы предсказывать, понравится или не понравится ему очередной фильм.
Вы проделываете кропотливую работу, присваивая обозначения предпочтений множеству различных фильмов, которые смотрел ваш друг. С помощью конструирования признаков извлекаете из этих фильмов главных актеров, режиссеров, жанры и другие признаки, добавляя их к обучающим данным. Добавляете также метку, обозначающую, понравился ли фильм вашему другу (1) или нет (0). В итоге получаете набор данных, как показано ниже.
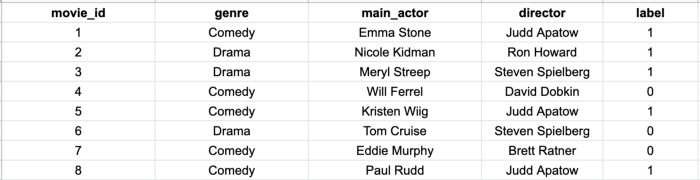
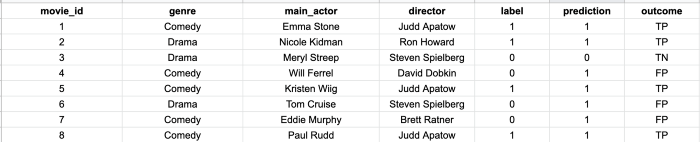
Следуя стандартным МО-протоколам, обучаете модель с помощью любимого классификатора и тестируете ее на тестовом наборе из 300 фильмов.
Как выясняется, модель обладает довольно высокой точностью — 90% меток были предсказаны правильно. Поэтому вы создаете приложение на основе обученной модели и передаете его своему товарищу, чтобы он стал более уверенным в своих решениях!
Через несколько недель вы встречаете товарища и спрашиваете, пользуется ли он вашим приложением. Немного поколебавшись, тот сообщает, что, хотя многие рекомендации были точны, все же некоторые из них не попали в цель. В конце концов он перестал пользоваться приложением.
Когда одной точности мало
Итоги классификации
Так что же произошло? Почему ваш товарищ перестал пользоваться приложением? Чтобы ответить на этот вопрос, углубимся в проблему.
Бинарный классификатор предоставил 2 способа быть правым и 2 способа ошибаться.
На изображении ниже показаны возможные результаты прогнозирования: ложноположительные (False Positives), ложноотрицательные (False Negatives), истинно положительные (True Positives) и истинно отрицательные (True Negatives).

Вот определения TP, FP, FN и TN в ситуации с вашим товарищем.
- TP = вы правильно предсказали хороший фильм для товарища (метка = 1, предсказание = 1).
- TN = вы правильно предсказали плохой фильм для товарища (метка = 0, предсказание = 0).
- FP = вы неверно предсказали плохой фильм для товарища (метка = 0, предсказание = 1).
- FN = вы пропустили предсказание хорошего фильма для товарища (метка = 1, предсказание = 0).
Экономический анализ
На этой стадии начинаем разрабатывать экономический слой модели. Первый этап состоит из 2 шагов.
- Перечислите все выгоды и затраты, связанные с моделью.
- Определите стоимость (в долларах) каждой выгоды и затрат.
Допустим, что в решении для просмотра фильмов, которое вы разработали для своего товарища, затраты FP составили $20 за билет в кино и 2 часа потраченного впустую времени. Ему также пришлось пережить несколько отрицательных моментов из-за нанесенного эмоционального ущерба, которые можно конвертировать в конкретную сумму — в данном случае $12. Выгода от получения правильного прогноза стоила вашему товарищу около $50. Кроме того, он не чувствовал себя плохо, когда пропускал фильм, который ваше приложение не рекомендовало, что можно выразить в $5.
Некоторые из этих затрат уже выражены в долларах, поэтому их легче рассчитать. Другие затраты сложнее, так как они относятся к временным и эмоциональным. Чтобы оценить их количественно, вы должны очень хорошо знать своего товарища (или клиента). Проделав достаточно напряженную работу, вы объединяете все вышеперечисленное в следующие определения выгод и затрат вашего товарища.
- A = потраченное время = $10.
- B = эмоциональный ущерб от просмотра плохого фильма = $50.
- C = эмоциональный ущерб от пропуска хорошего фильма = $12.
- D = эмоциональное удовлетворение от просмотра хорошего фильма = $50.
- E = эмоциональное удовлетворение от пропущенного плохого фильма = $5.
- F = цена билета в кино = $20.
Поиск и измерение различных затрат и выгод, а затем перевод их в единую интерпретируемую валюту — важный шаг для создания слоя оптимизации полезности модели.
Объединение экономики и МО
Теперь нужно построить функцию, чтобы связать количественные затраты и выгоды вашего товарища с результатами классификации. Для упрощения уравнений добавляем метки переменных (A, B, C и т.д.), определенных в вышеприведенных уравнениях. На этом этапе суммируем различные выгоды и затраты, чтобы создать долларовые значения для каждого результата классификации.
Например, ложноположительный результат составляет $80, потому что вы складываете стоимость билета в кино, 2 часа времени, потраченного на просмотр фильма, и эмоциональный ущерб от просмотра плохого фильма. Истинно положительный результат составляет $10, потому что для вашего товарища просмотр этого фильма стоил $50, но он потратил $40 времени и денег. Для простоты предположим, что каждый фильм длится 2 часа.
- Ложноположительный = F + 2(A) + B = $20 + ($10 * 2) + $50 = $80.
- Ложноотрицательный = C = $12.
- Истинно положительный = D — F — 2(A) = $50 — $20 — ($10*2) = $10.
- Истинно отрицательный = E = $5.
Соотношение выгод и затрат
Теперь, когда все затраты и выгоды связаны с результатами классификации, можно ввести функцию полезности. Этот процесс отличается от настройки максимально точной модели.
Одним из примеров экономической функции полезности является соотношение выгод и затрат (Benefit Cost Ratio). Это популярный расчет, выполняемый в рамках общего финансово-экономического анализа. Интерпретация этого соотношения заключается в том, что значение больше 1 означает, что выгоды перевешивают затраты, а меньше 1 — наоборот.
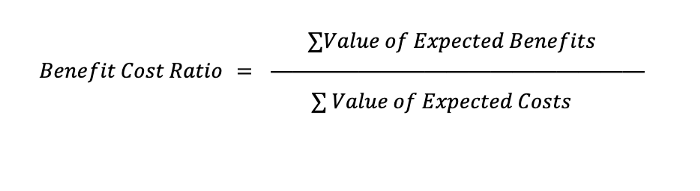
Теперь можно выполнить следующие действия.
- Подсчитать количество TP, TN, FP и FN.
- Использовать затраты, рассчитанные для каждого результата, в качестве весов для расчета соотношения выгод и затрат.
Возвращаясь к примеру с фильмами, вспомним, что у нас был тестовый набор из 300 фильмов, и 90% из них были предсказаны правильно. После выполнения описанных выше инструкций получаем следующее количество точек данных для каждого типа результатов классификатора.
- TP-предсказания = 80.
- TN-предсказания = 190.
- FP-предсказания = 30.
- FN-предсказания = 0.
Как и ожидалось, 270 из 300 предсказаний были правильными (TP + TN). 30 результатов оказались ложноположительными (FP), а их стоимость составила $80.
Соотношение затрат и выгод — это общая сумма ожидаемых выгод, деленная на общую сумму ожидаемых затрат.
[(Веса * TP) + (Веса * TN)] / [(Веса * FP) + (Веса * FN)].
Ожидаемые выгоды — это TP и TN, а ожидаемые затраты — FP + FN. Применив веса, рассчитанные для TP, TN, FP и FN, можем составить следующее уравнение:
[($10*TP)] + [($5*TN)] / [($80*FP) + ($12*FN)].
Применим все вычисленные числа к соотношению затрат и выгод:
[10(80) + 5(190)] / [80(30) + 12(0)] = 1750 / 2400 = .729
Значение 1 (выше) означает, что модель приносит пользу. В нашем случае значение равно .729. Это говорит о том, что модель вредит вашему товарищу, несмотря на то, что 270 из 300 прогнозов оказались верными. Неудивительно, что товарищ перестал пользоваться приложением.
Экономические функции за пределами бинарной классификации
Рассмотренное выше решение можно применить и к другим типам проблем. Например, в многоклассовом классификаторе можно измерить правильные, неправильные, пропущенные и выходящие за рамки высказывания, а затем применить соответствующие веса к этим измерениям для определения выгод и затрат.
В качестве альтернативы можно использовать классификатор “один против всех” для построения глубоких метрик на уровне каждого класса. Некоторые метки классов могут быть более важными для более высокой точности, чем другие метки, поэтому экономическую метрику стоит настроить на оптимизацию для этих подмножеств классов.
Независимо от того, какую модель вы используете, никогда не помешает применить этот экономический анализ, чтобы выбрать правильные настройки для используемой в производстве модели.
Действенные шаги и более глубокие метрики МО
Теперь, после определения количественных параметров предпочтений вашего товарища, вам потребуется модель, дающая меньше рекомендаций. Один из способов добиться этого — установить порог и измерить, как этот порог работает с вашей функцией полезности.
По опыту работы в больших и малых компаниях я знаю, что пороговые значения обычно устанавливаются произвольно. Между тем экономический слой помог бы объяснить то, почему так происходит. Есть и другие способы назначения пороговых значений для модели, которые здесь не будут рассмотрены.
Более глубокие метрики, такие как F1, учитывают precision и recall (и, следовательно, результаты классификации), что дает лучшее представление о работе модели по сравнению с точностью. Такие понятия, как чувствительность и специфичность, являются хорошо известными, часто обсуждаемыми понятиями и перекликаются с данной статьей.
Но даже в этих случаях экономические функции по-прежнему ценны и могут быть использованы для присвоения денежной стоимости различным результатам и непосредственной привязки моделей к потребностям клиента.
Экономические функции в реальном мире
Конечно, реальный мир намного сложнее, чем пример с фильмами. Процесс соотношения выгод и затрат может занять несколько итераций и значительное время. Кроме того, очень сложно измерить такие аспекты, как “эмоциональный ущерб”. Чтобы получить достойную оценку этого показателя, необходимо очень хорошо знать своих клиентов, и даже тогда она может быть не на 100% точной. Применяемые веса, скорее всего, будут неверными и рискуют оказаться субъективными, а не ориентированными на клиента.
Чтобы смягчить предвзятость, процесс создания этого экономического слоя возлагается на специалистов по машинному обучению, менеджеров по продуктам и всех заинтересованных лиц, работающих с клиентами.
Заключение
В этом разделе перечислим предпринятые нами высокоэффективные концептуальные шаги (причем шаги, касающиеся экономического слоя, выделим жирным шрифтом).
- Получение и подготовка данных.
- Построение и обучение модели.
- Генерирование прогнозов с использованием тестового набора.
- Использование прогнозов, обозначение метками результатов классификации (TP, FP, TN и FN в случае бинарного классификатора).
- Определение затрат и выгод результатов классификации и переведение их в доллары (это требует от МО-специалистов работы с заинтересованными сторонами, которые очень хорошо понимают, чего хотят клиенты).
- Взвешивание результатов классификации с учетом выгод и затрат, рассчитанных в шаге 5.
- Вычисление экономической функции полезности, когда соотношение выгод и затрат более 1.
- Оптимизация модели в соответствии с функцией полезности. Это может привести к снижению точности. В случае с соотношением выгод и затрат необходимо, чтобы оно было больше 1 (для нашей исходной модели этот параметр был менее 1).
В заключение хочу сказать, что, хотя все согласны с тем, что машинное обучение и искусственный интеллект повышают ценность бизнеса, клиентов и конечного результата, важно начать измерять и оптимизировать эту ценность.
Читайте также:
- Простой способ решить алгоритм Apriori с нуля
- Обзор шаблонов SnapML и их возможностей в Lens Studio
- Как освоить машинное обучение
Читайте нас в Telegram, VK и Дзен
Перевод статьи Siddarth Ramesh: Why Accurate Models Aren’t Always Useful





