
Представьте, что вам нужно изучить данные и преобразовать их, но времени не хватает. Вы владеете методами Pandas, которые нужно использовать для построения столбца, его сортировки, изменения имени и создания визуализации, но написание кода для получения всего этого займет больше времени, чем вы можете себе позволить.
Что же делать? Можно быстро написать код и довести дело до конца (что может привести к глупым ошибкам) или же использовать библиотеку Mito, чтобы исследовать и преобразовать данные за несколько минут. Mito — это библиотека Python, которая позволяет проводить анализ данных так же быстро, как если бы вы работали с электронными таблицами в Microsoft Excel.
Чтобы разобраться в том, как она работает, для начала скачайте набор данных и установите библиотеку. В этом руководстве будет использоваться набор данных игроков FIFA 22. Его можно загрузить здесь. Мы будем исследовать этот набор данных с помощью библиотеки Mito. Чтобы ее установить, скачайте либо Jupyter Notebook, либо Jupyter Lab. Затем выполните приведенную ниже команду в терминале или командной строке.
python -m pip install mitoinstaller
python -m mitoinstaller install
Чтобы узнать больше о Mito и ее установке, ознакомьтесь с официальной документацией.
После установки Mito понадобится создать mitosheet, чтобы приступить к работе. Затем строить столбцы и визуализации можно будет в пару кликов.
Импорт датафрейма
Перед импортом датафрейма убедитесь, что загруженный набор данных находится в рабочем каталоге. Если это так, нажмите на кнопку Import, затем найдите название набора данных, выберите его и кликните на Import.
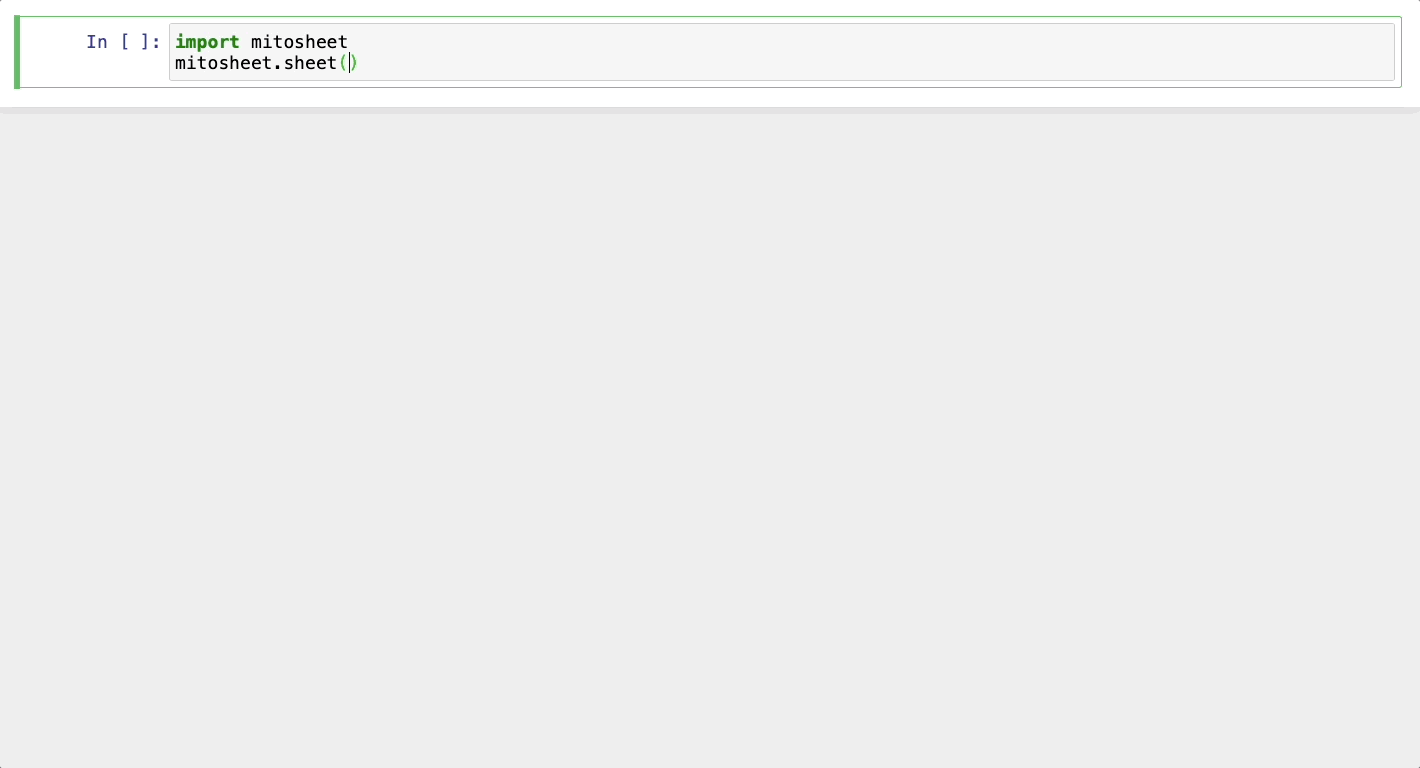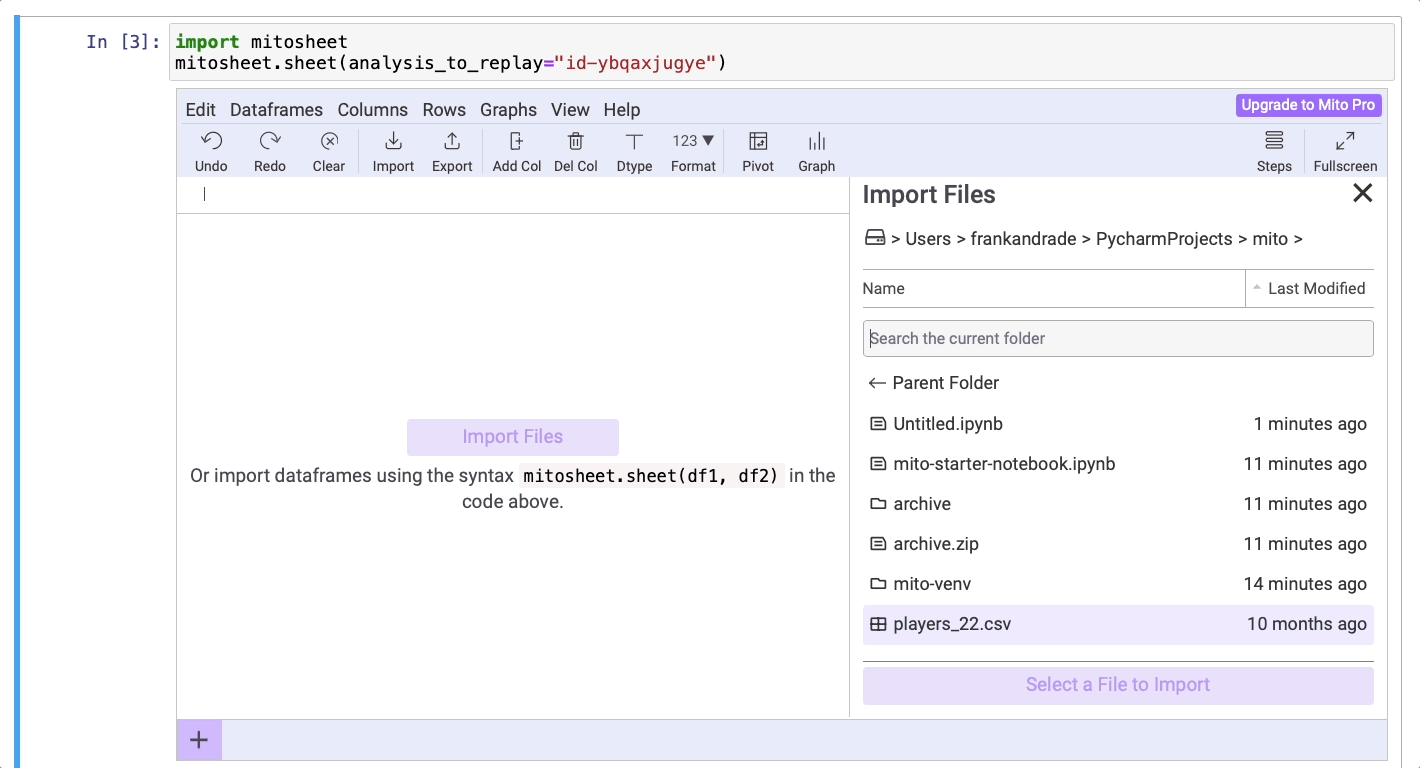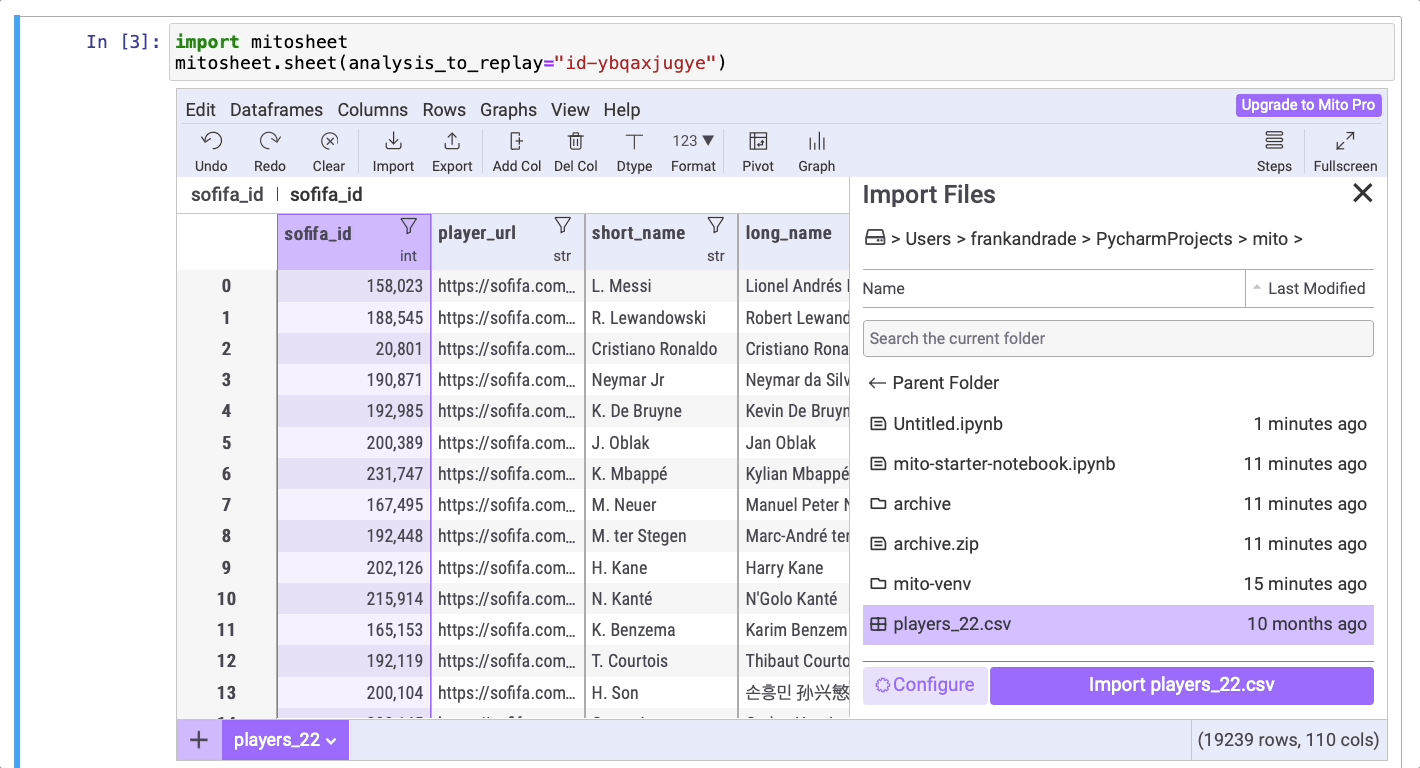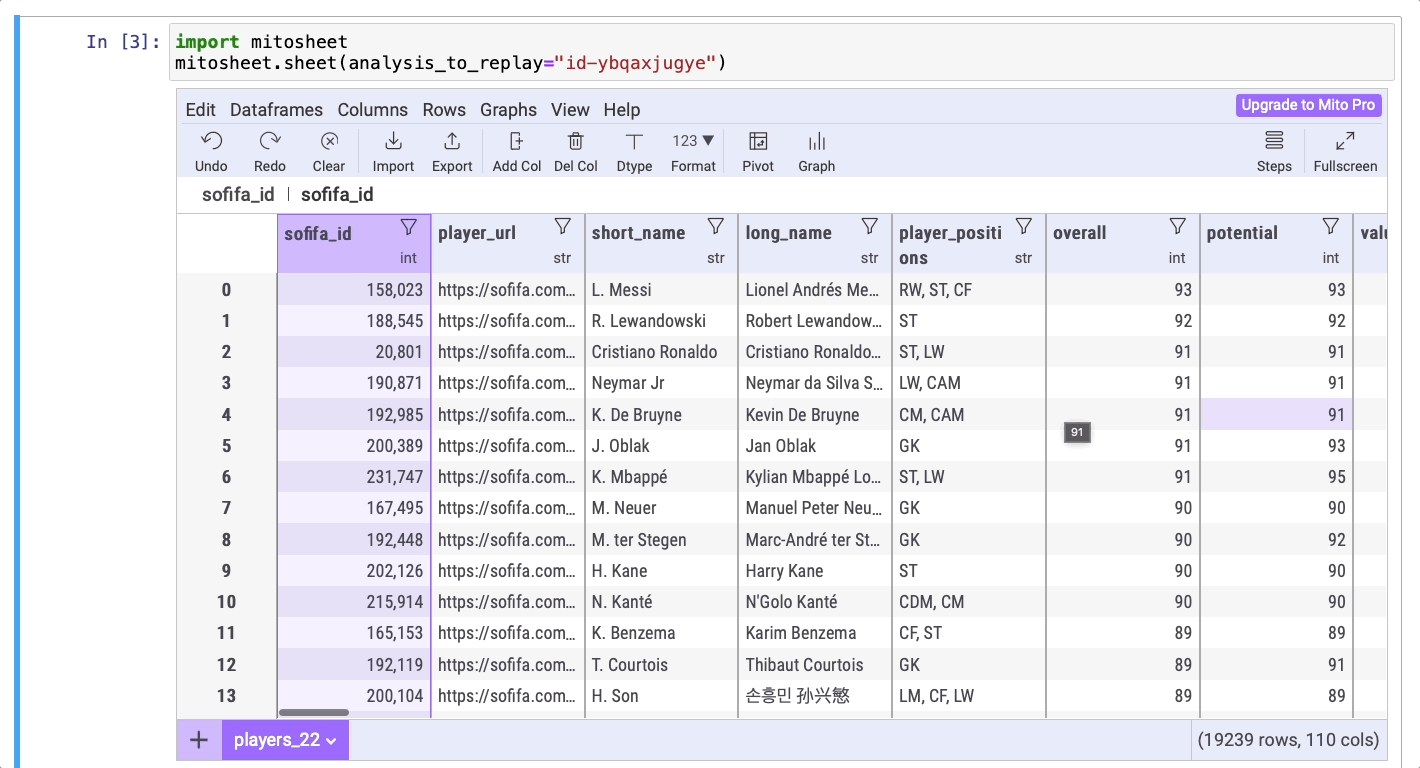
Главное преимущество библиотеки Mito в том, что она генерирует код Python после всех действий, произведенных в mitosheet.
Вот сгенерированный код, который выполнил операцию импорта:
# Импорт players_22.csv
import pandas as pd
players_22 = pd.read_csv(r'players_22.csv')
Сортировка значений в столбце
Сортировать значения с помощью библиотеки Mito просто — достаточно нажать на кнопку “Сортировать” (Filter) и выбрать “Возрастание” (Ascending) или “Убывание” (Descending).
Отсортируем общий результат футболистов по убыванию, а затем по возрастанию, чтобы установить лучшего и худшего игроков.
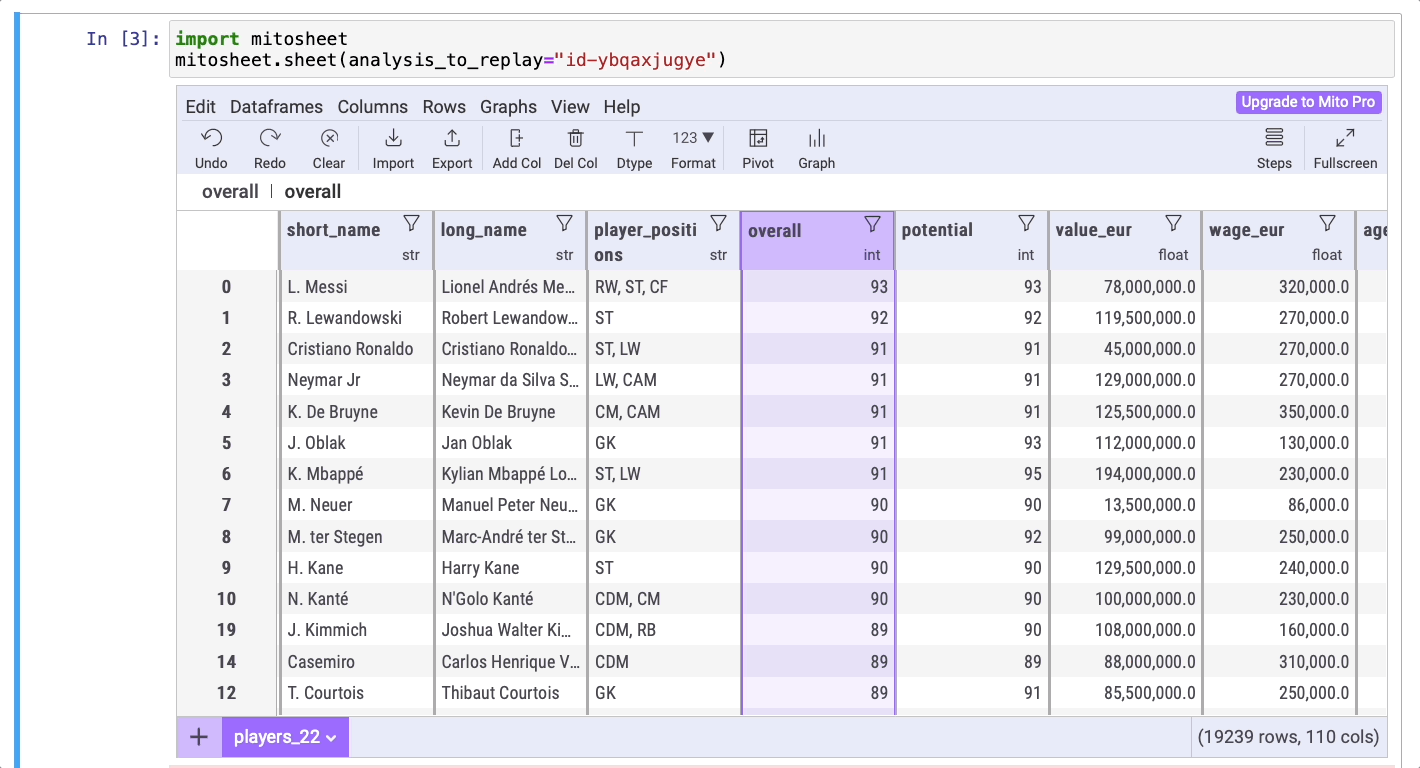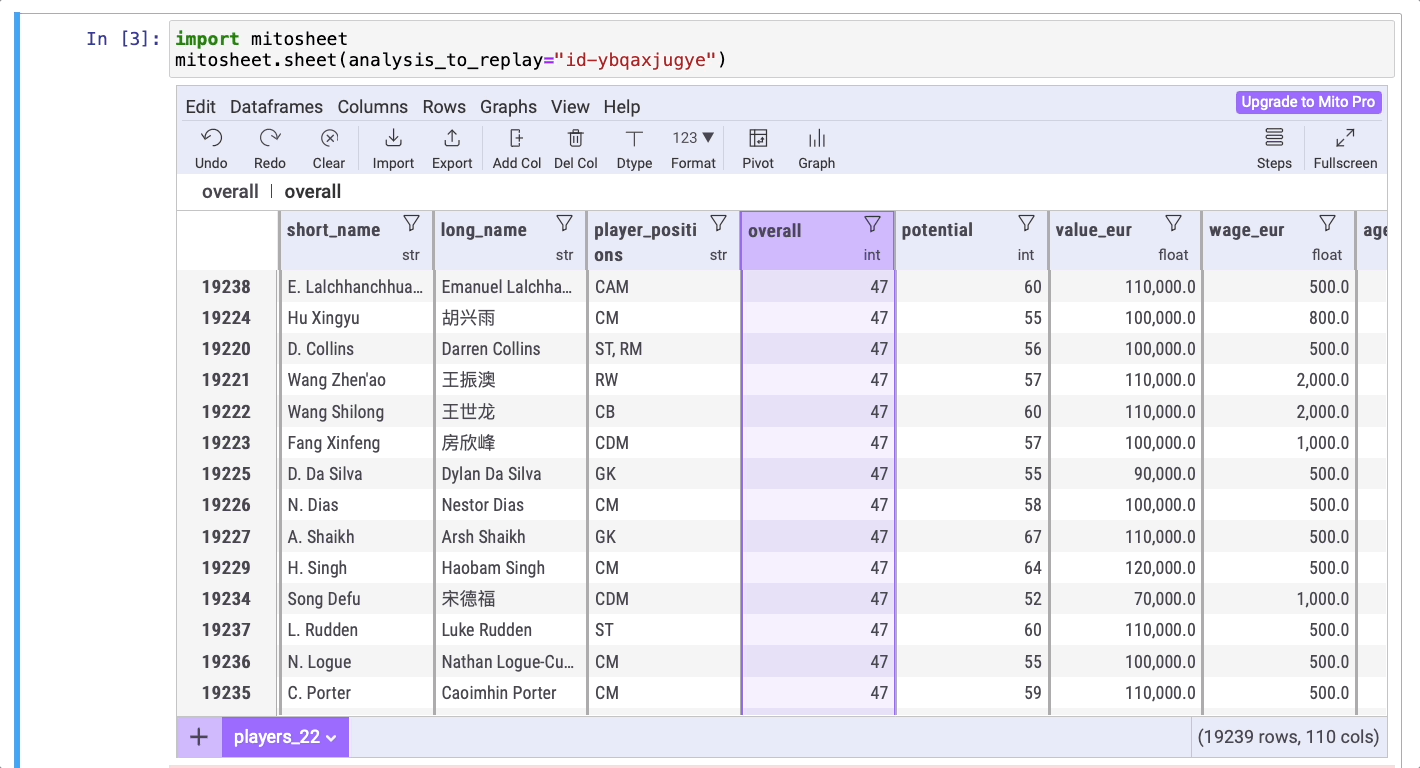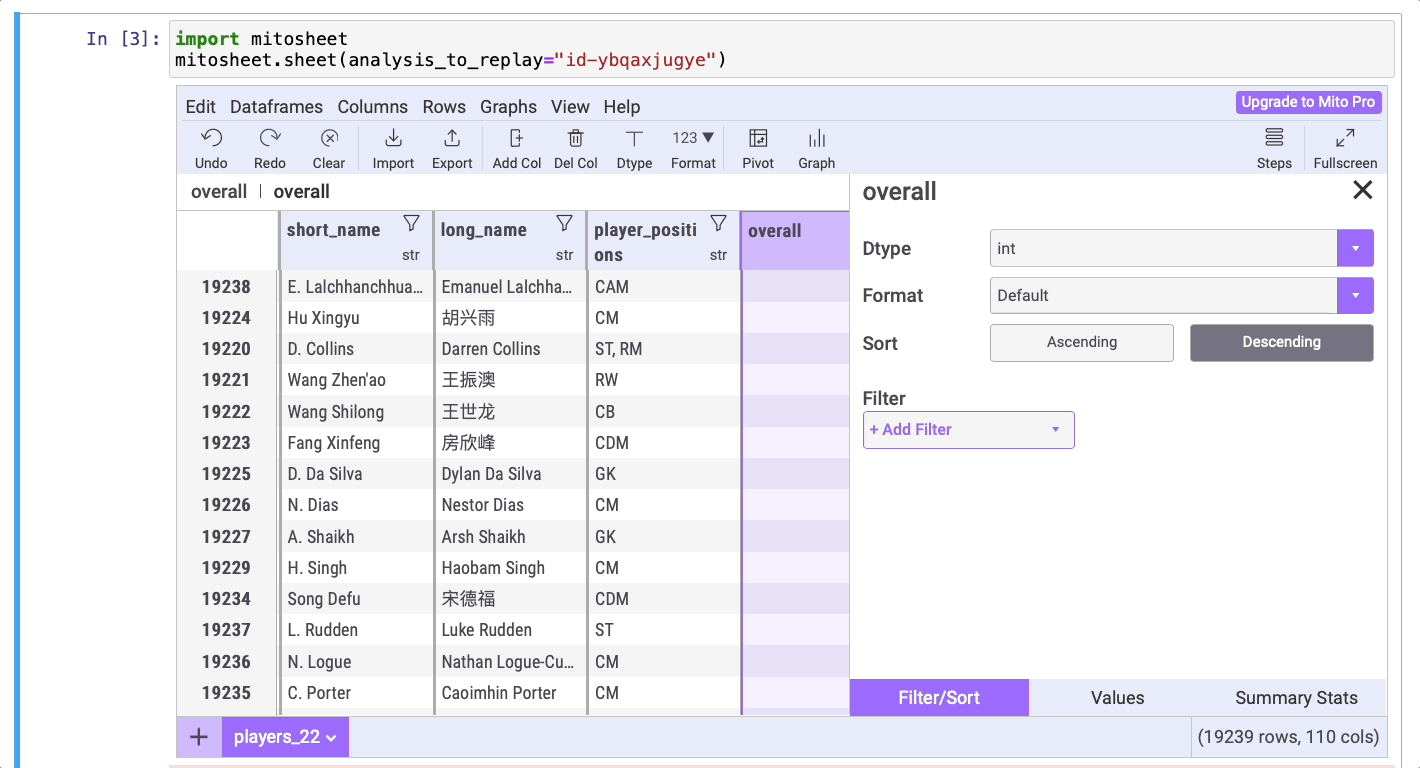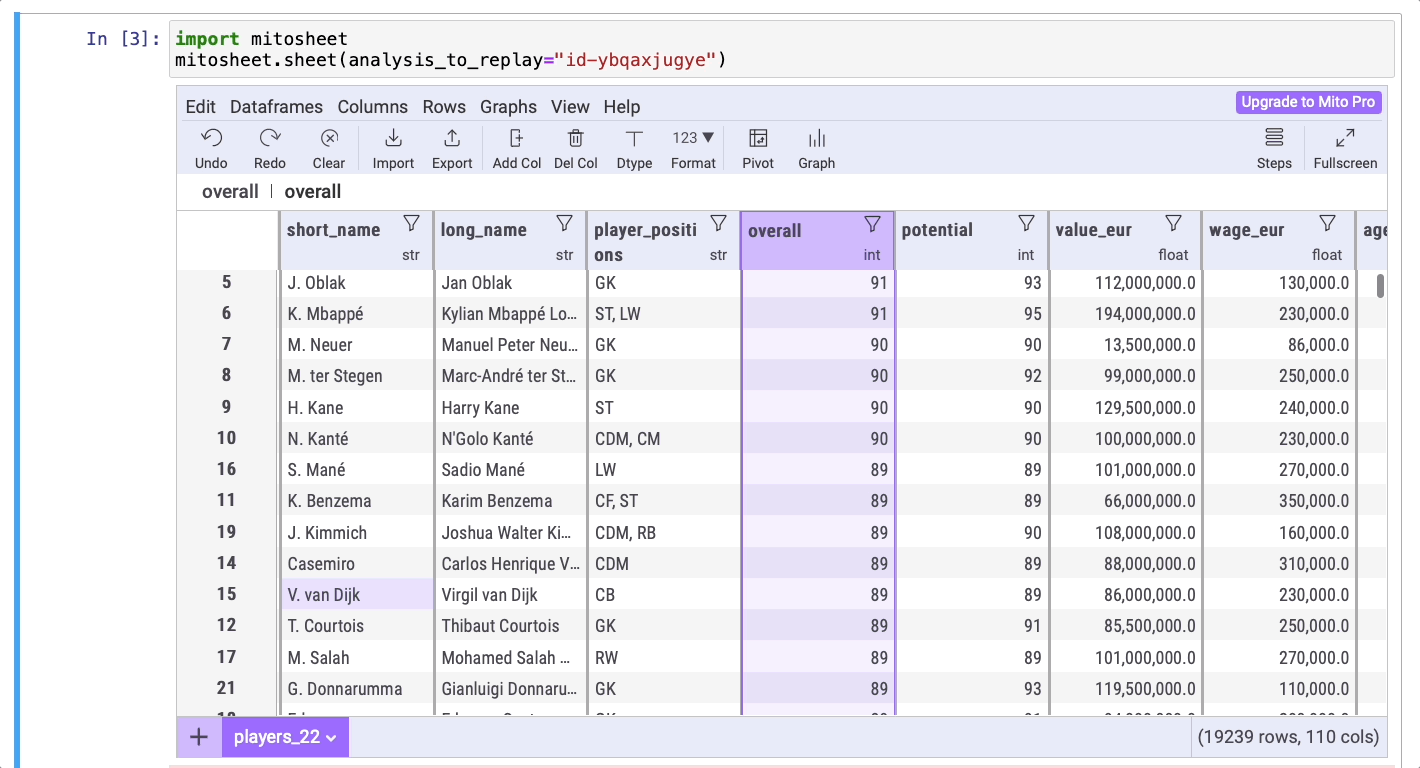
Через пару секунд вы выясните, что игроком с самым высоким баллом является Лионель Месси, а игроком с самым низким баллом — Эмануэль Лалчханчхуаха.
Вот код Python, который без Mito пришлось бы писать самостоятельно:
# Сортировка в порядке убывания players_22 = players_22.sort_values(by='overall', ascending=False, na_position='last') # Сортировка по возрастанию players_22 = players_22.sort_values(by='overall', ascending=True, na_position='first')
Создание нового столбца, его переименование и применение формул
Синтаксис для создания новых столбцов и изменения их имен в Pandas иногда трудно запомнить. Хорошая новость заключается в том, что в Mito нужно нажать всего пару кнопок, чтобы выполнить все эти действия за считанные секунды!
Создадим новый столбец, который будет содержать данные о росте игроков, выраженном в метрах. Для этого нажмите на кнопку Add Col (“Добавить столбец”), затем дважды кликните на названии столбца, чтобы изменить его на height_m. В этом новом столбце нужно преобразовать рост из сантиметров в метры, введя формулу =height_cm/100.
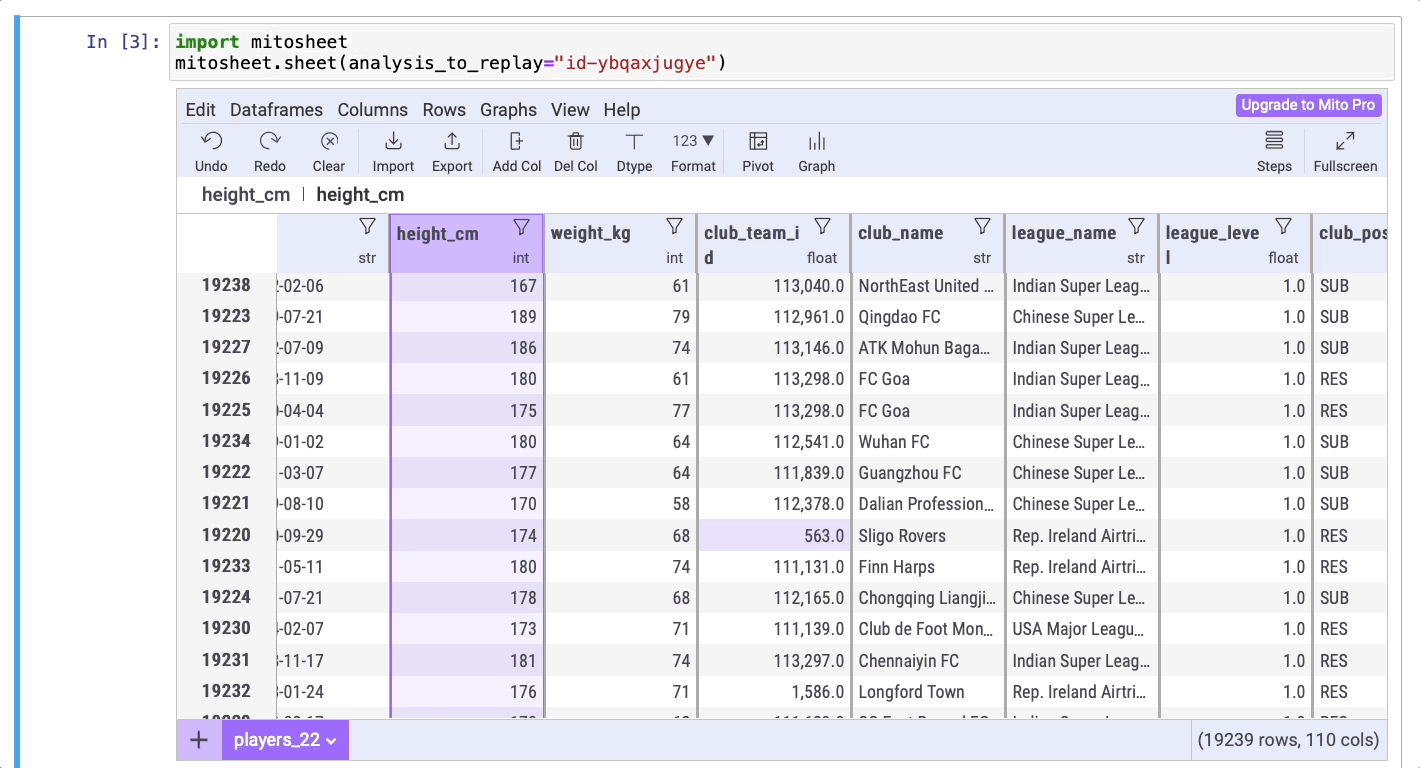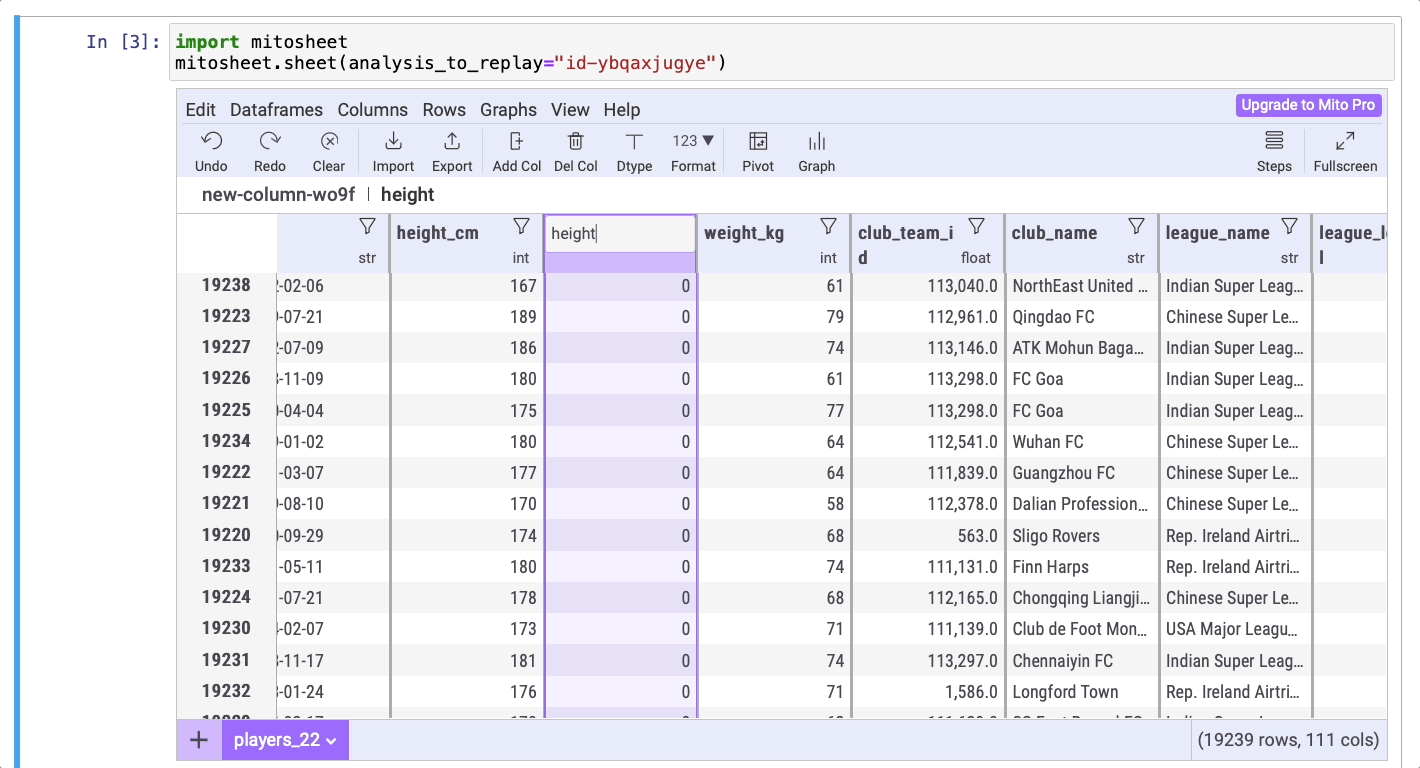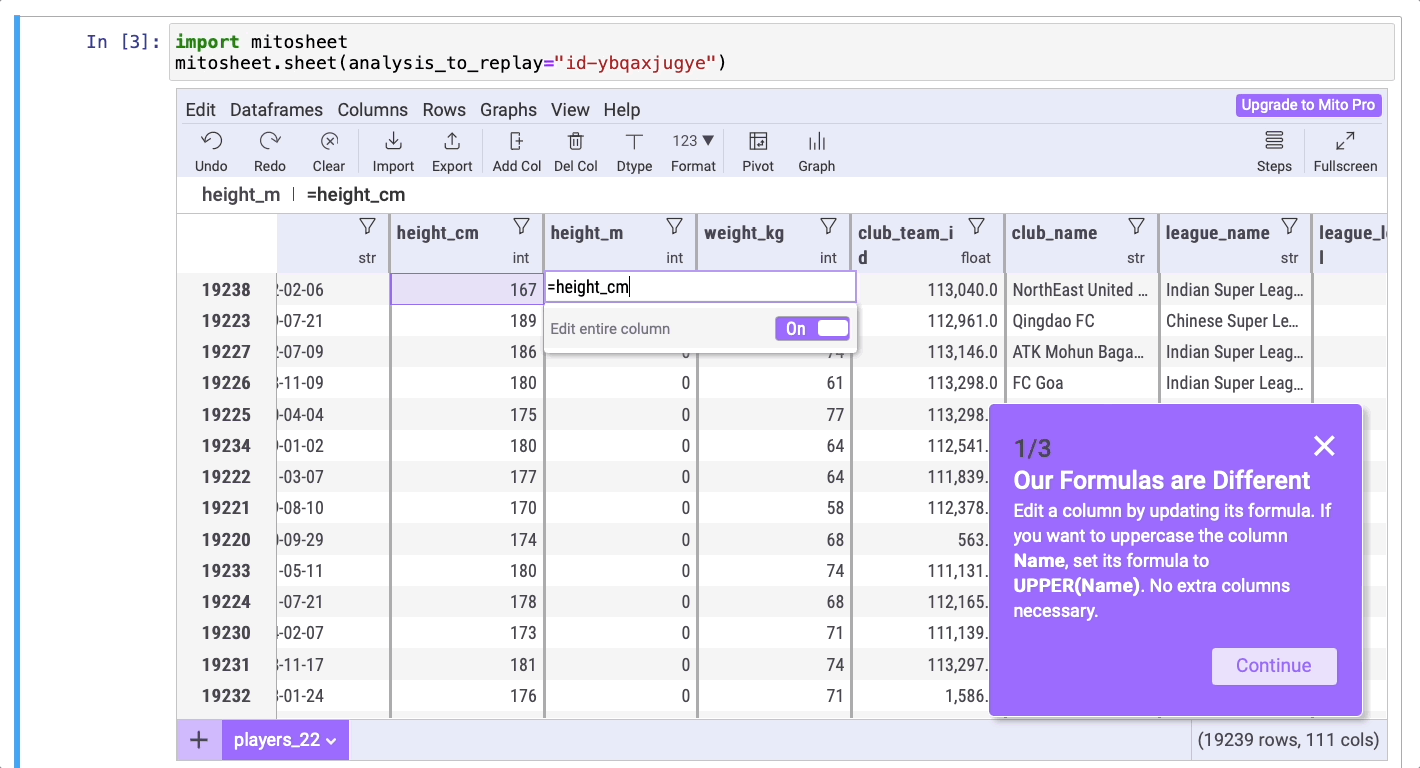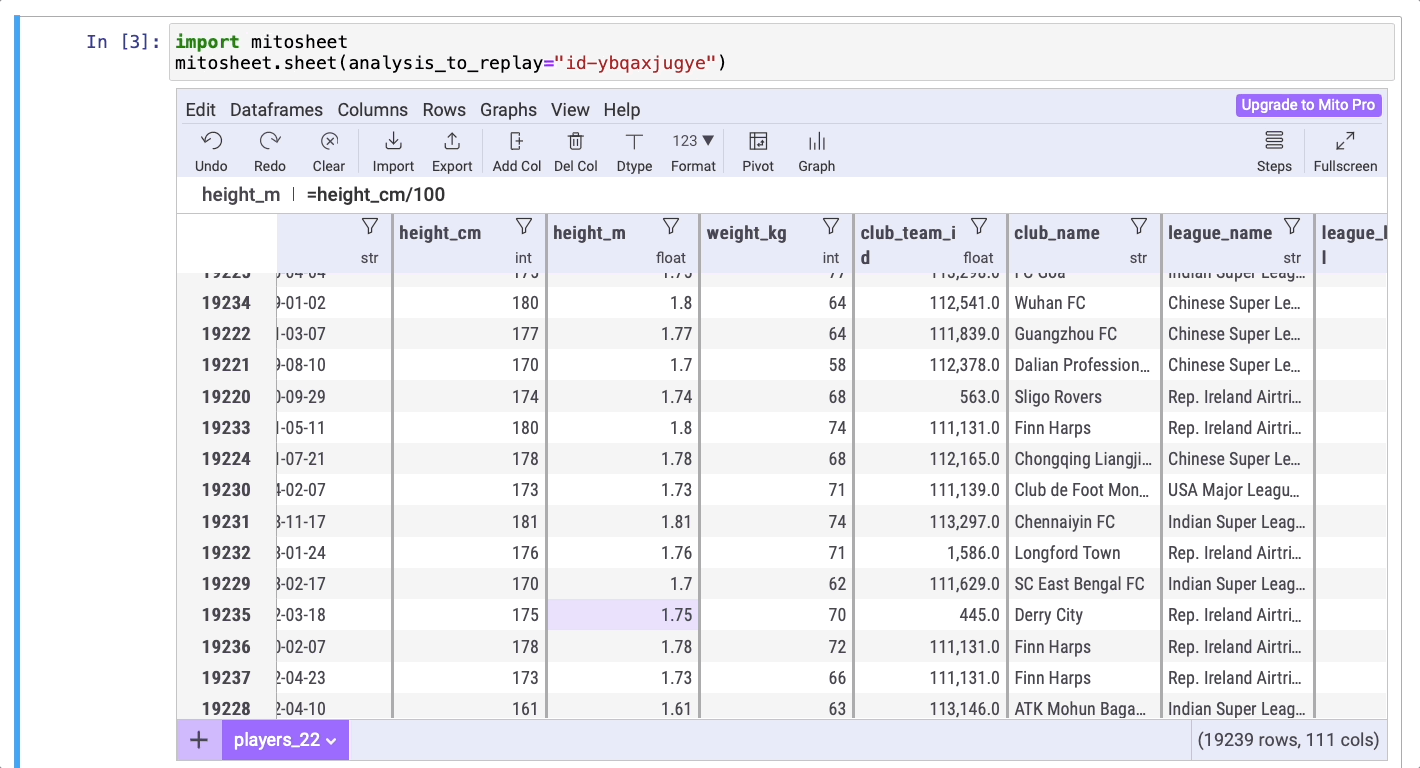
Отлично! Теперь можно отсортировать данные столбца, чтобы найти самого высокого и самого низкого игроков. Ниже приведен код, сгенерированный Mito:
# Добавление столбца new-column-wo9f
players_22.insert(12, 'new-column-wo9f', 0)
# Переименование столбцов в height_m
players_22.rename(columns={'new-column-wo9f': 'height_m'}, inplace=True)
# Установка формулы height_m
players_22['height_m'] = players_22['height_cm']/100
Теперь, в качестве упражнения, создайте новый столбец BMI (ИМТ, индекс массы тела). Формула для его расчета: BMI = kg/m2. Выполните следующие шаги, чтобы создать этот новый столбец.
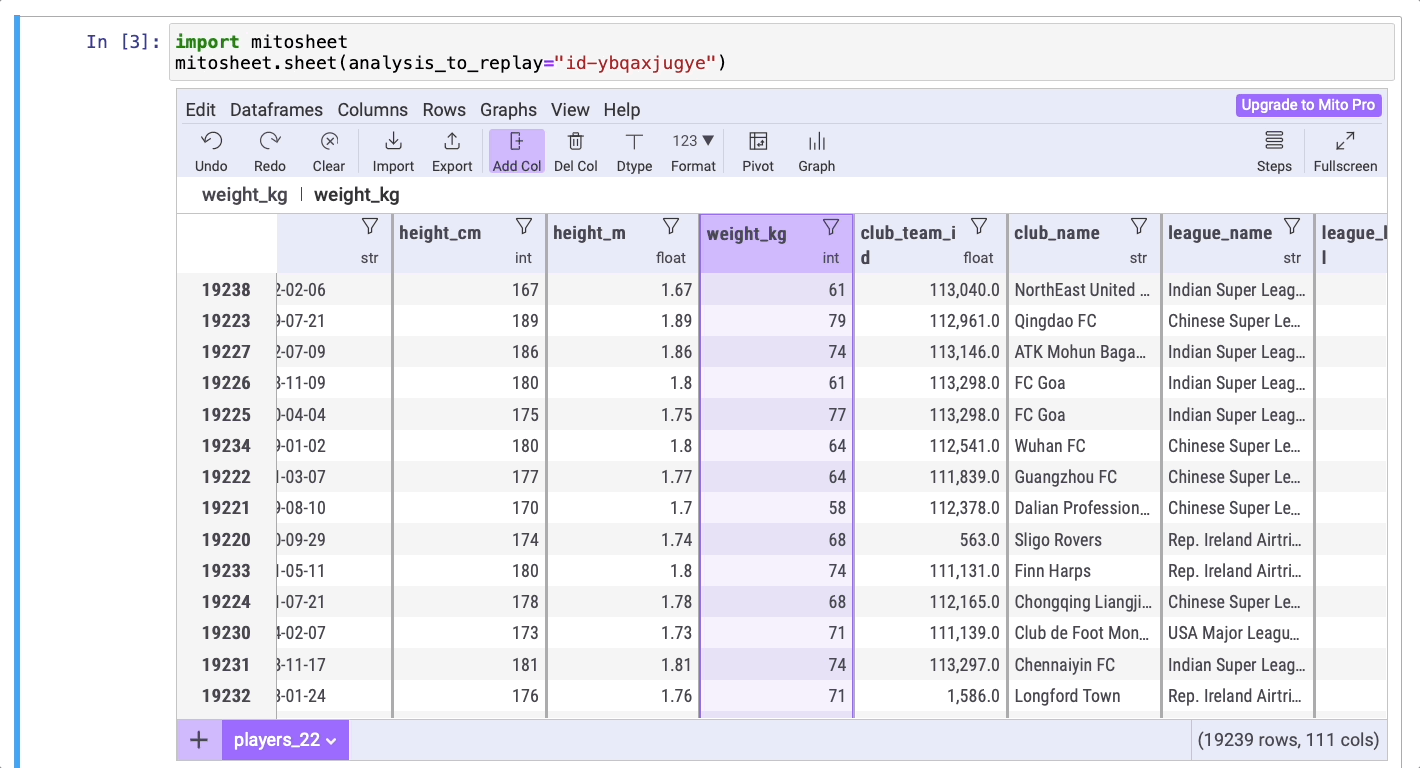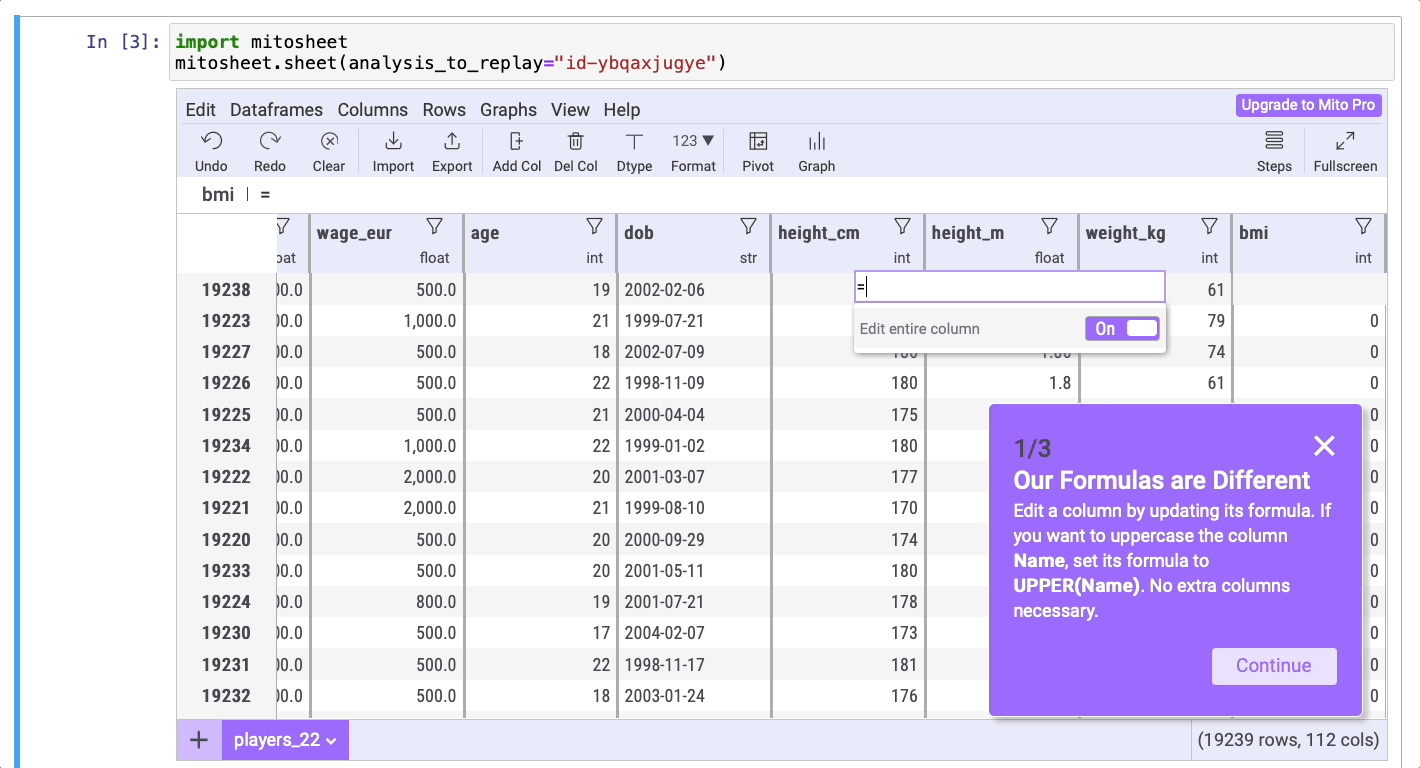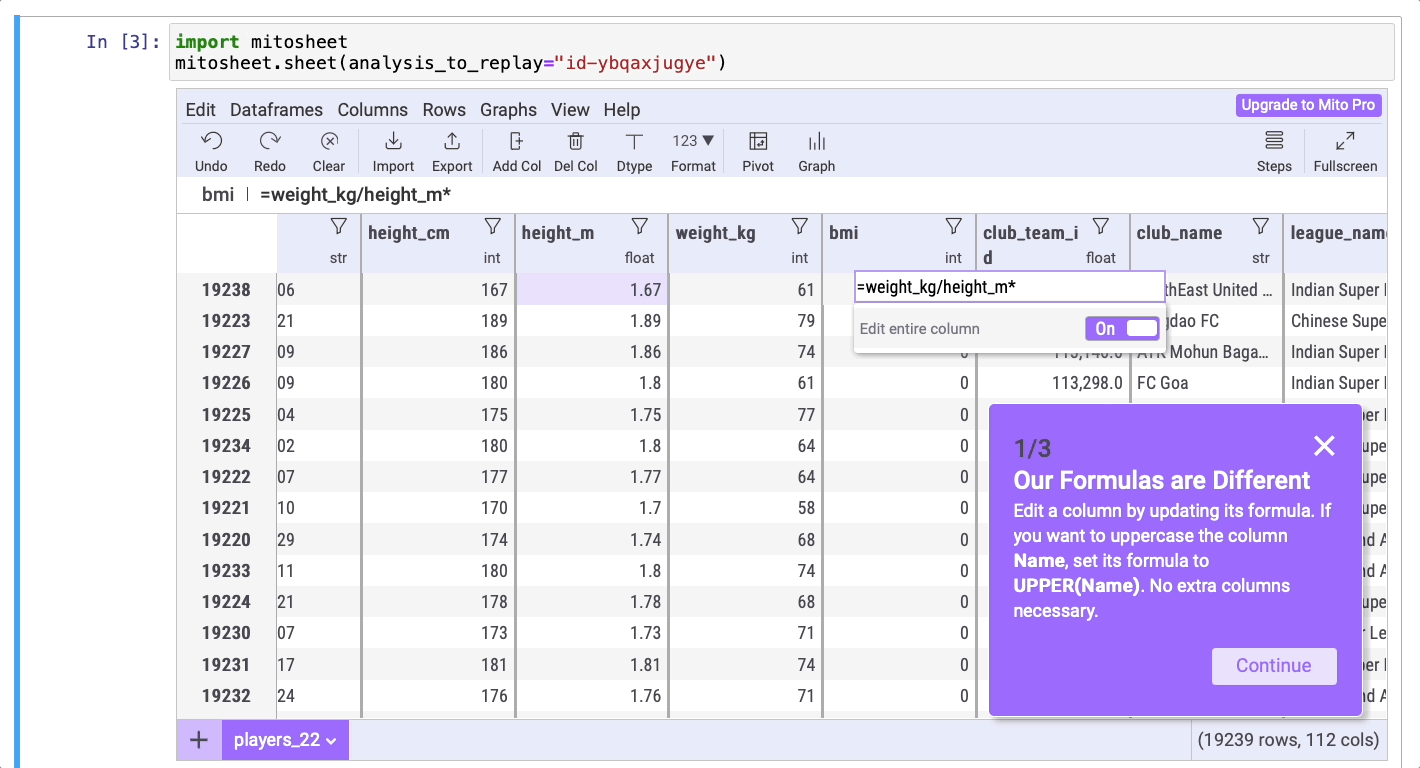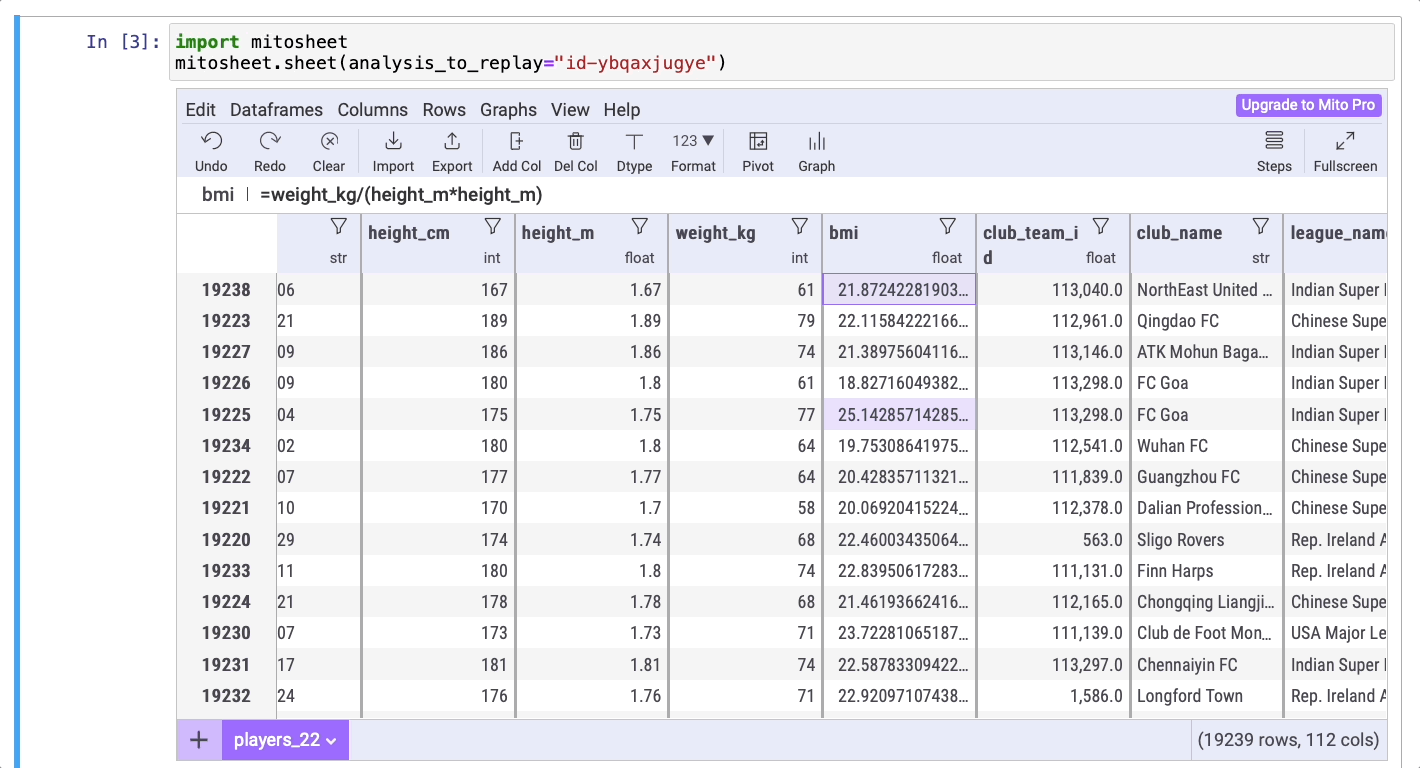
Вот код, сгенерированный Mito:
# Добавление столбца new-column-o0fb
players_22.insert(14, 'new-column-o0fb', 0)
# Переименование столбцов в bmi
players_22.rename(columns={'new-column-o0fb': 'bmi'}, inplace=True)
# Установка формулы bmi
players_22['bmi'] = players_22['weight_kg']/(players_22['height_m']*players_22['height_m'])
Создание визуализации
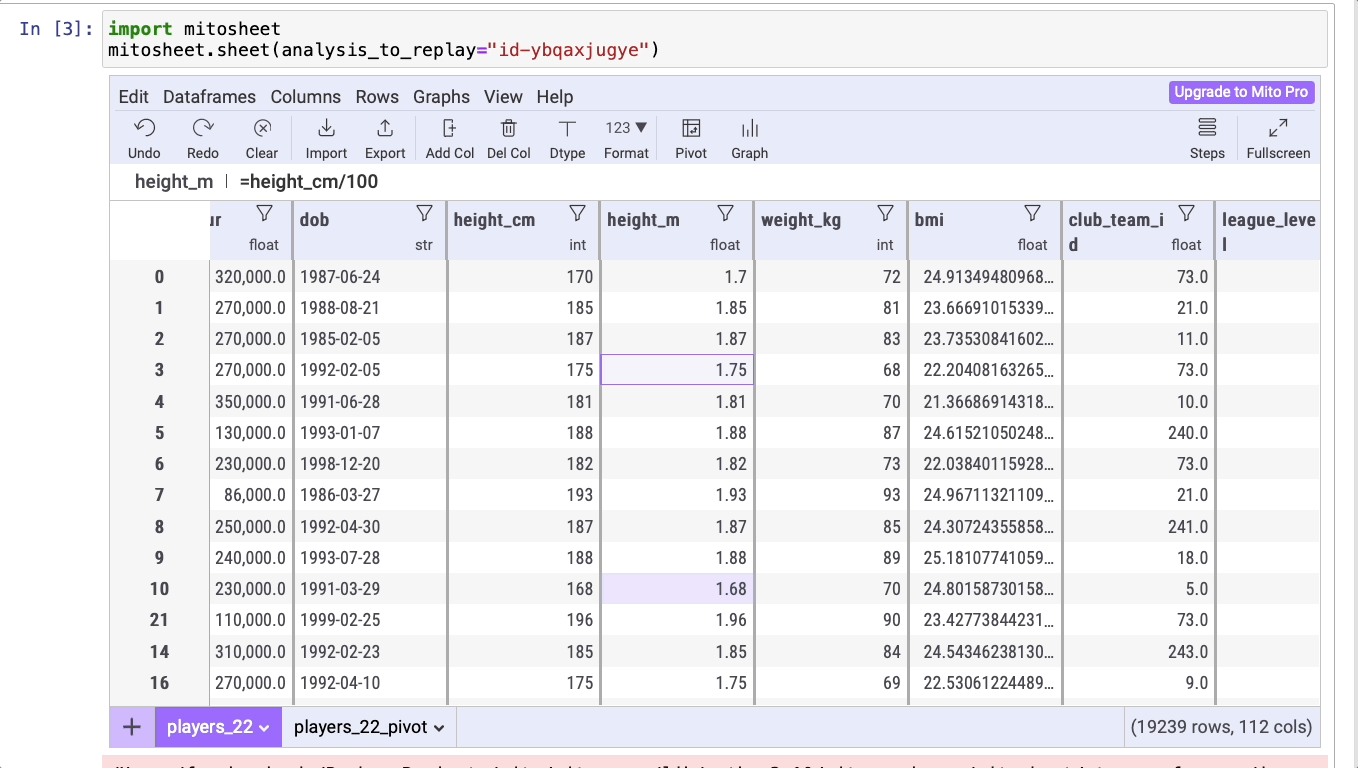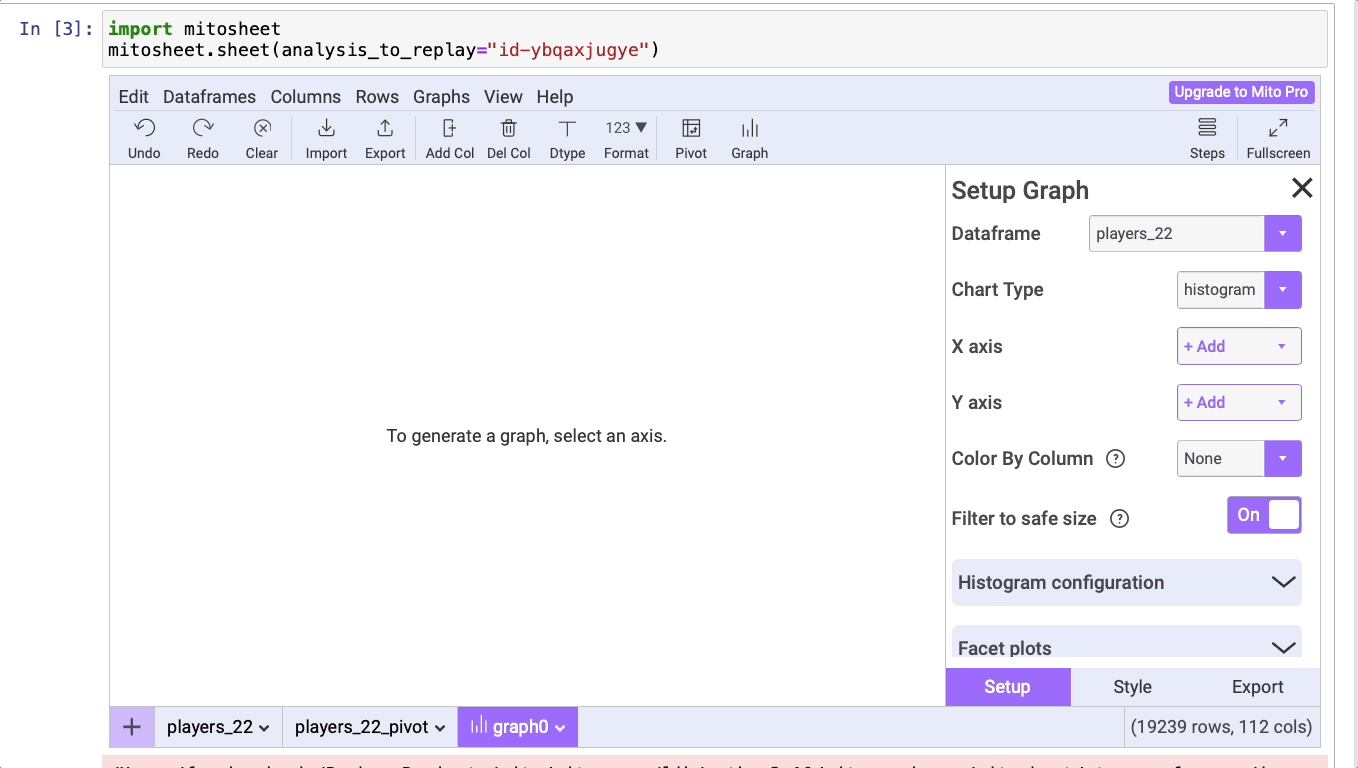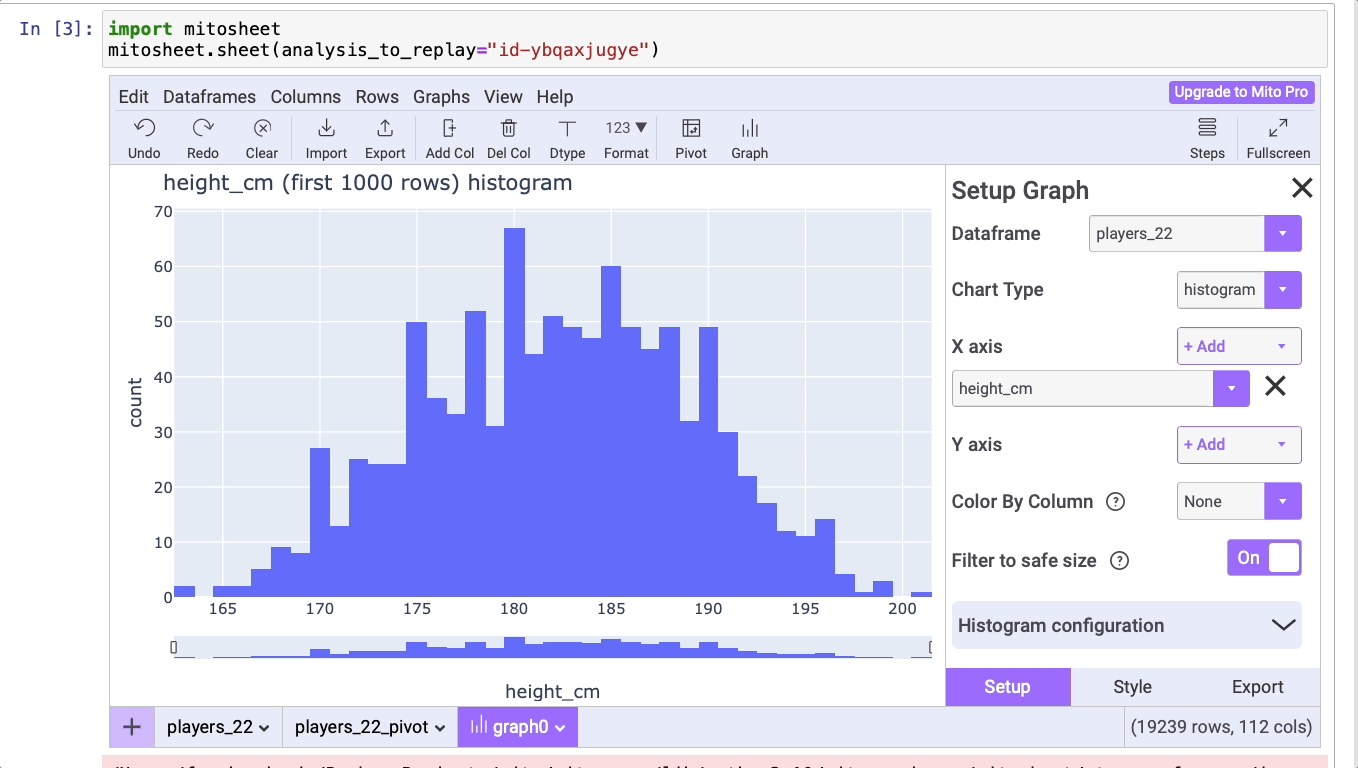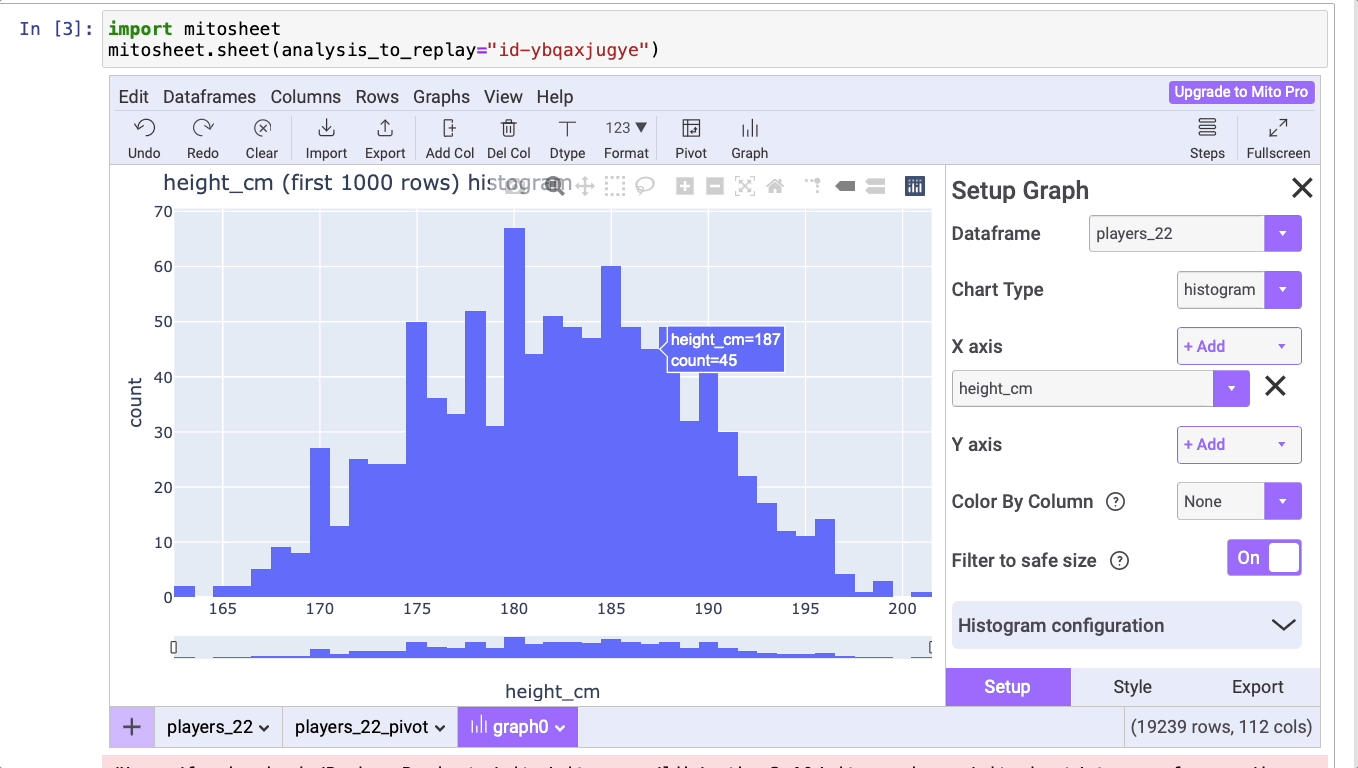
Обычным этапом в процессе изучения числовых данных является создание гистограммы. С помощью Mito можно создать это и многие другие графические представления данных всего за пару кликов.
Подготовим гистограмму роста игроков. Для этого достаточно нажать на кнопку Graph (“Граф”) и выбрать нужный тип графического представления. Затем на оси X добавим данные, которые необходимо отобразить.
Сортировка датафрейма на основе нескольких условий
Сортировать данные в Mito можно точно так же, как это делается в Excel! Нужно только нажать на значок сортировки, перейти в раздел Filter, нажать на Add a Filter и затем выбрать Add a filter (“Добавить сортировку”), если нужно задать одно условие, или Add a group of filters (“Добавить группу сортировок”), если нужно задать несколько условий.
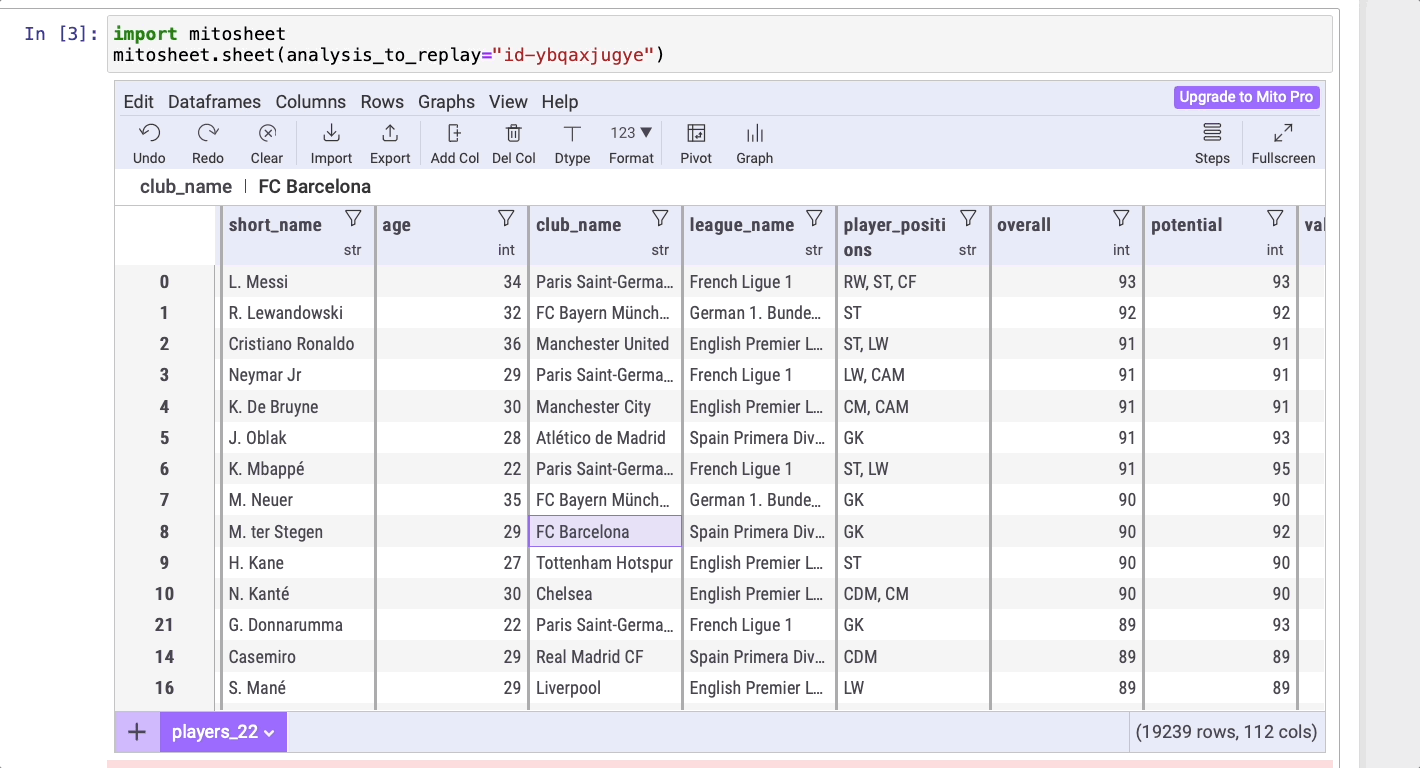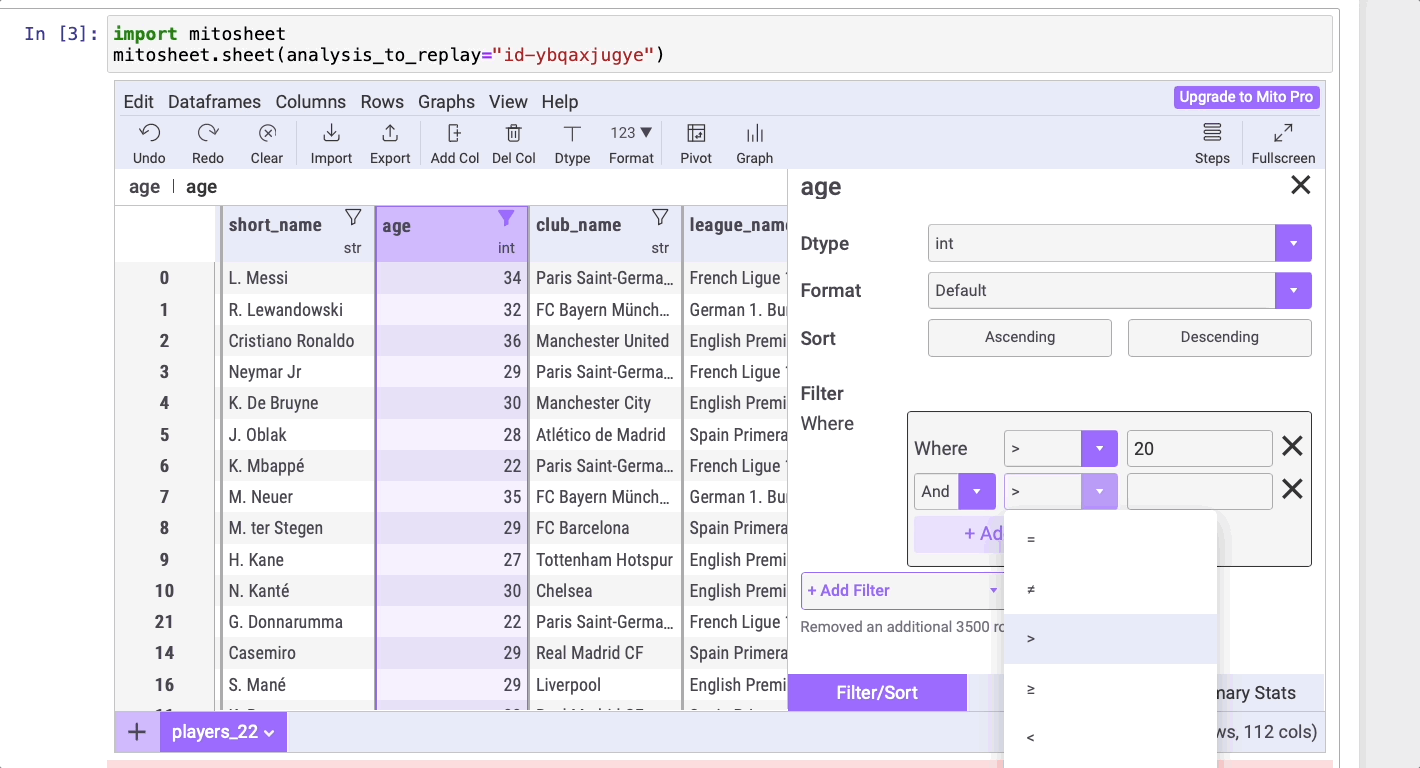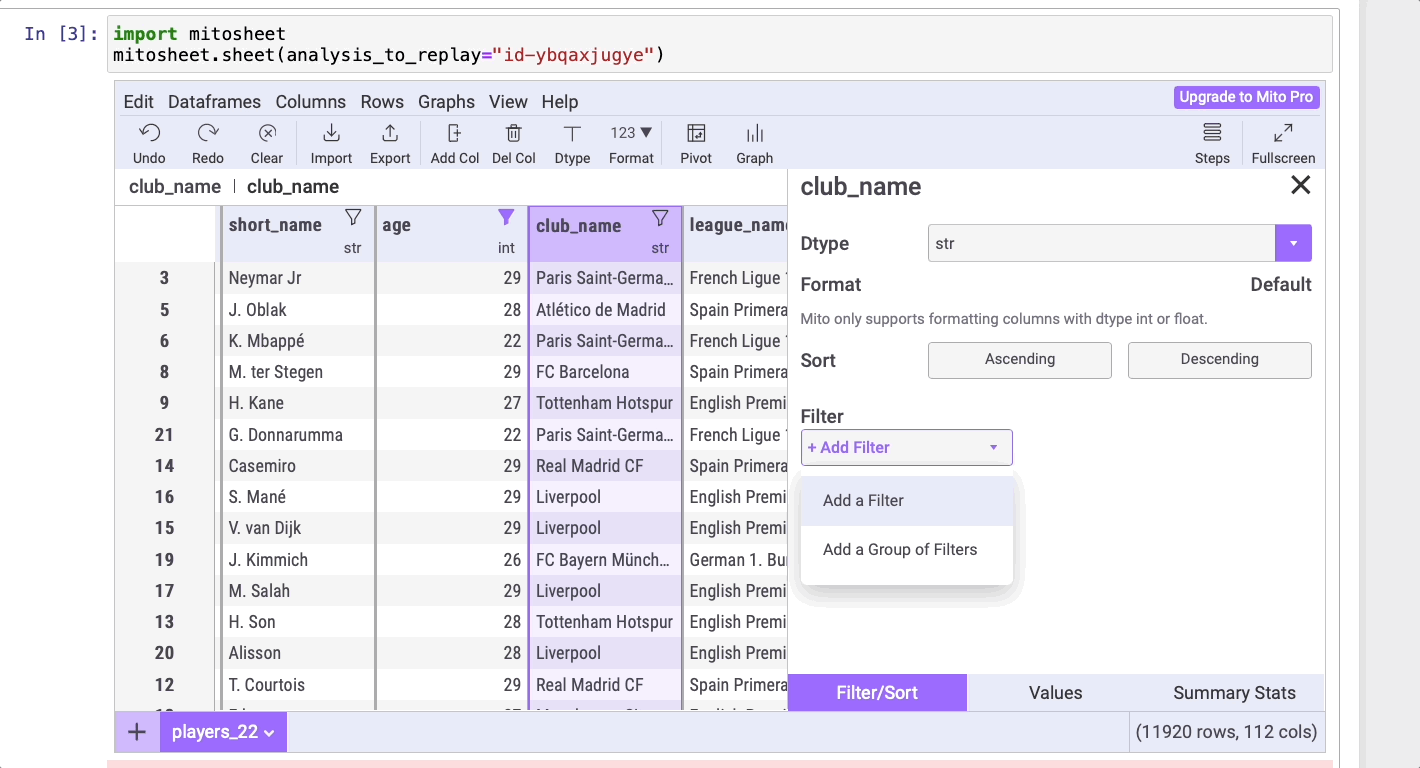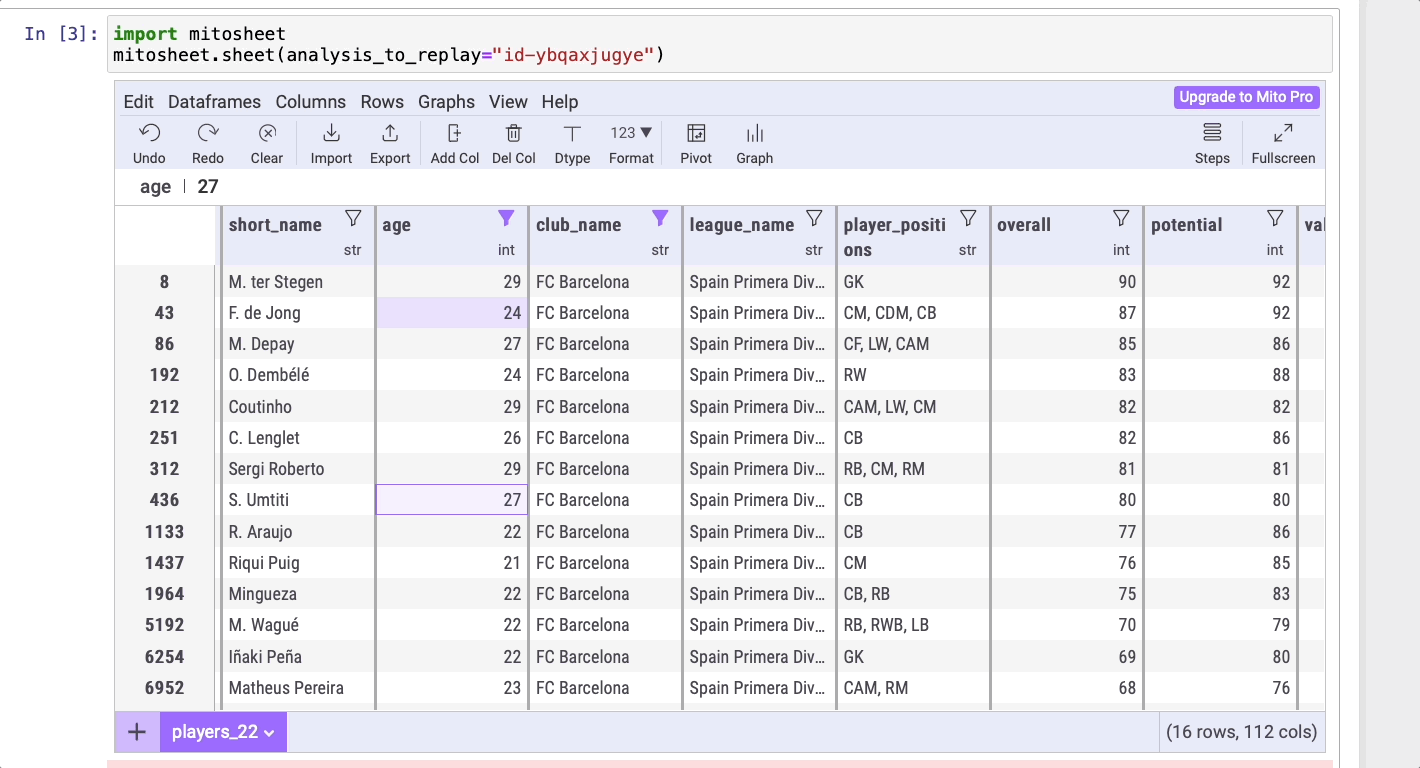
В данном примере в столбце age (“возраст”) отсортируем игроков в возрасте от 20 до 30 лет, поэтому выберем Add a group of filters. А вот в столбце club_name (“название клуба”) отсортируем игроков ФК “Барселона”, поэтому выберем Add a Filter.
Вот код, сгенерированный Mito:
# Сортировка по возрасту players_22 = players_22[((players_22[‘age’] > 20) & (players_22[‘age’] < 30))] # Сортировка по названию клуба players_22 = players_22[players_22[‘club_name’] == ‘FC Barcelona’]
Создание сводной таблицы
Чтобы создать сводную таблицу в Pandas, необходимо помнить синтаксис метода .pivot_table (что иногда является проблемой). К счастью, шаги по созданию сводной таблицы в Mito аналогичны Excel.
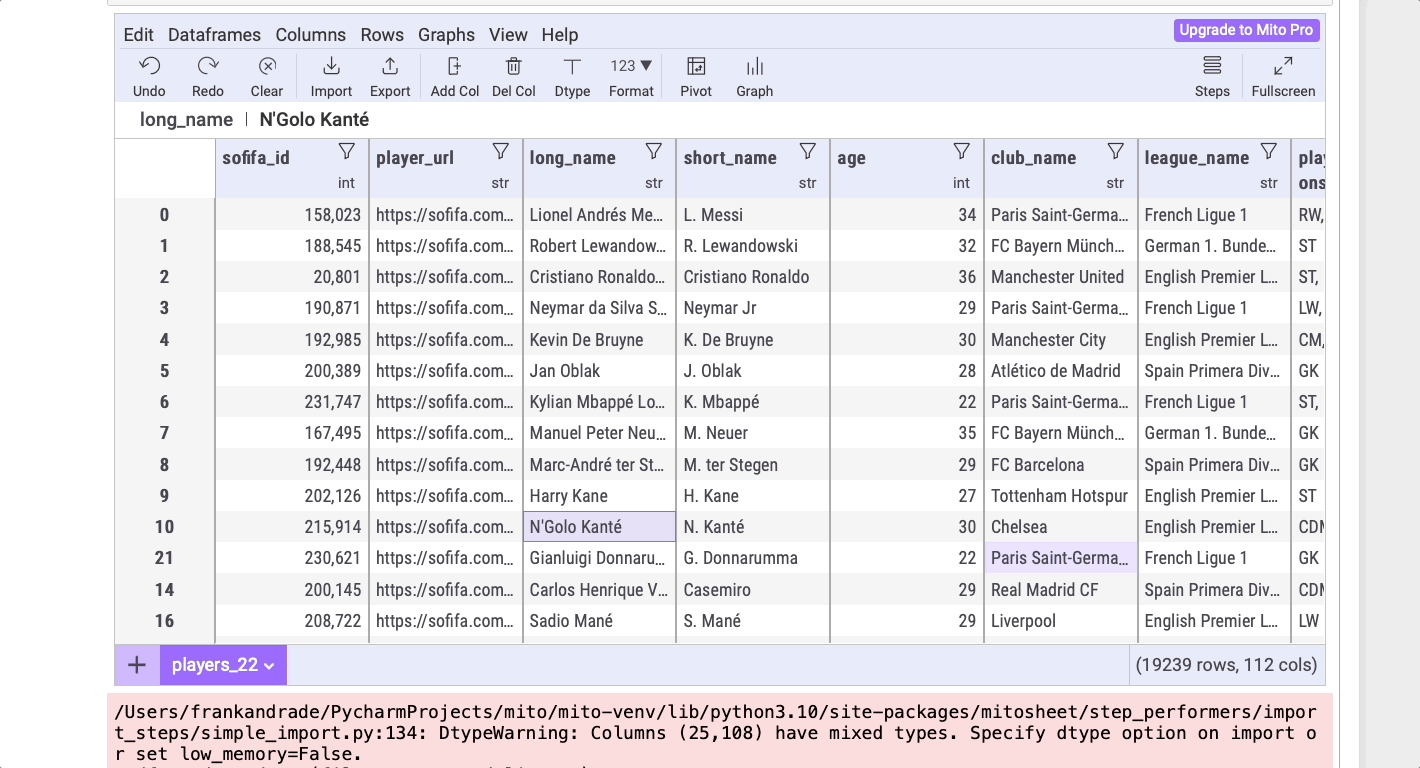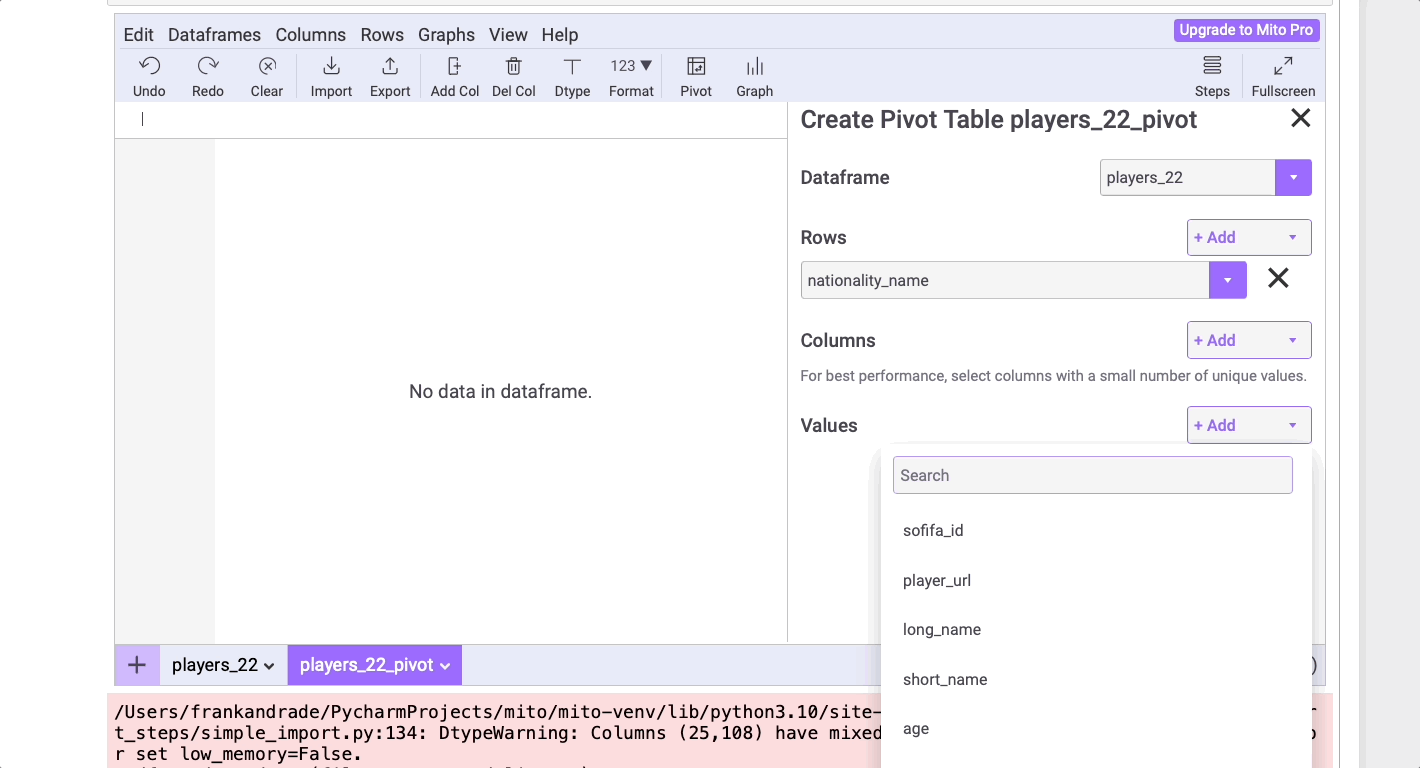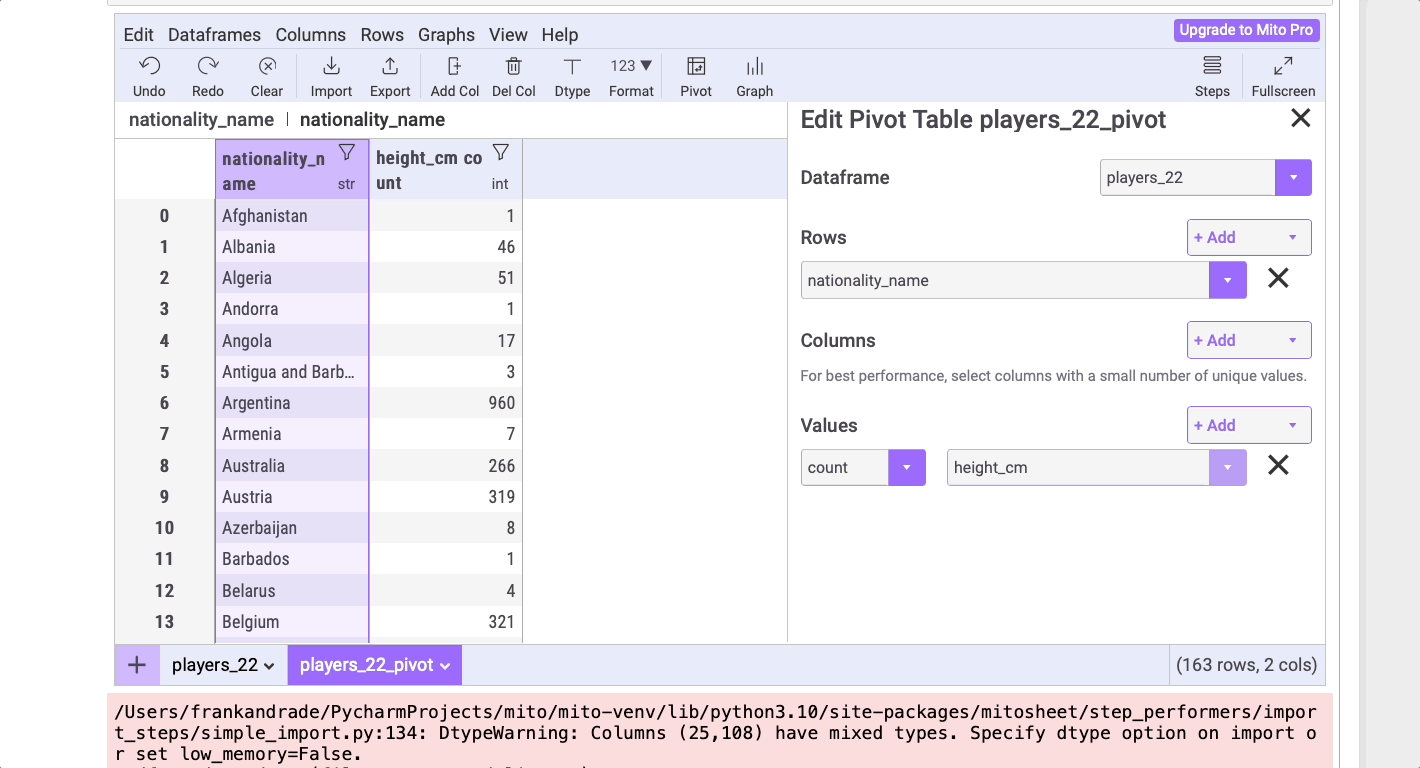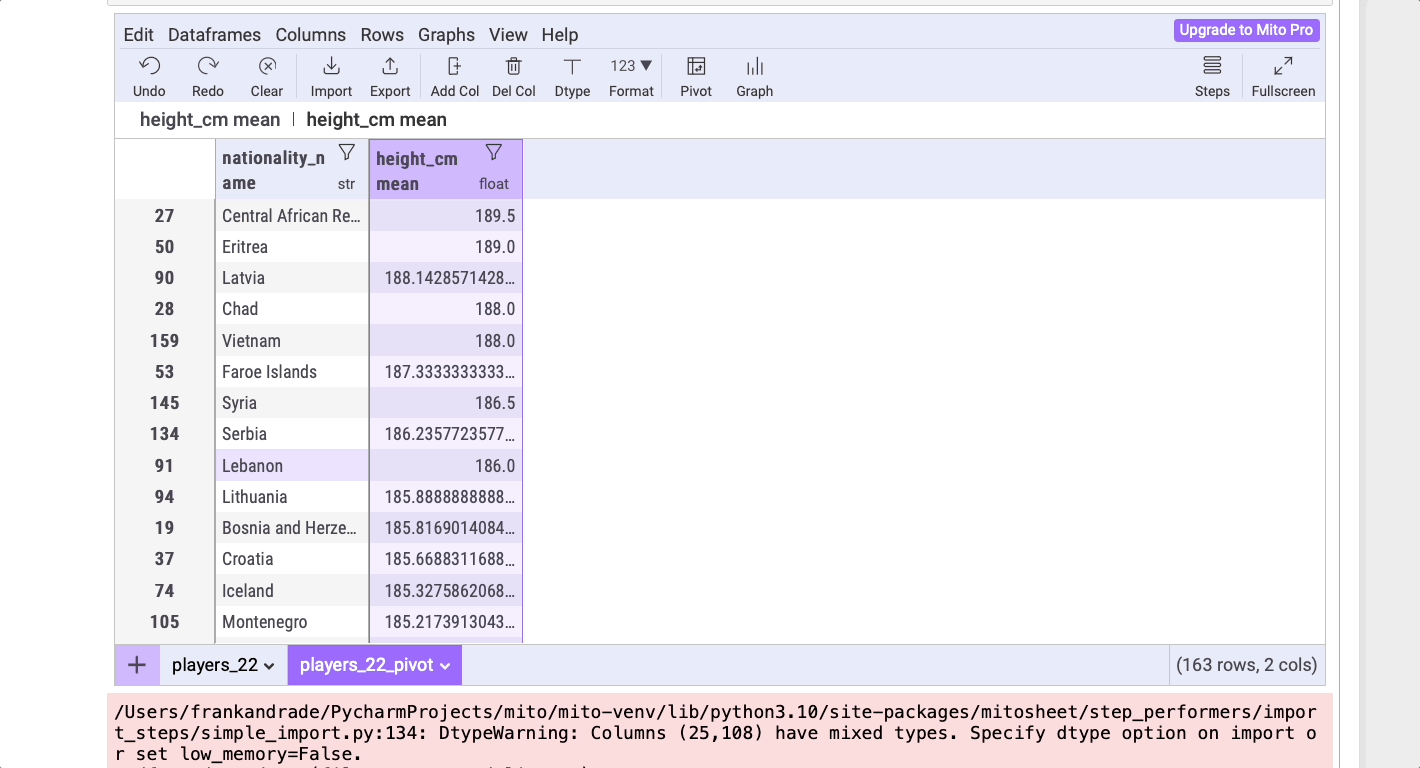
Выясним на основе набора данных, в каких странах самые высокие игроки. Для этого щелкните по таблице Pivot и выберите nationality_names в Rows (форме “Строки”) и height_cm в Values (в форме “Значения”), как показано ниже. Не забудьте выбрать mean (“среднее значение”) в выпадающем списке.
Вот код, сгенерированный Mito (как видите, синтаксис не так-то легко запомнить, особенно новичку):
# Сведение в таблицу players_22
tmp_df = players_22[[‘nationality_name’, ‘height_cm’]]
pivot_table = tmp_df.pivot_table(
index=[‘nationality_name’],
values=[‘height_cm’],
aggfunc={‘height_cm’: [‘mean’]}
)
pivot_table.set_axis([flatten_column_header(col) for col in pivot_table.keys()], axis=1, inplace=True)
players_22_pivot = pivot_table.reset_index()
# Сортировка средних значений height_cm в порядке убывания
players_22_pivot = players_22_pivot.sort_values(by=’height_cm mean’, ascending=False, na_position=’last’)
Читайте также:
- Топ-10 вопросов о Pandas на StackOverflow
- Почему вы должны начать использовать .npy файл чаще…
- Как оптимизировать код на Python
Читайте нас в Telegram, VK и Дзен
Перевод статьи Frank Andrade: Super Fast Data Analysis in Python





