
Эта статья основана на материалах из книги Артура Эйсмонта Web Scalability for Startup Engineers и призвана помочь в первую очередь начинающим программистам. Это очень краткое изложение основных концепций и положений. Желающим основательнее разобраться в архитектуре современного ПО стоит ознакомиться с этой книгой или аналогичными источниками в сети.
Архитектура сетевого взаимодействия
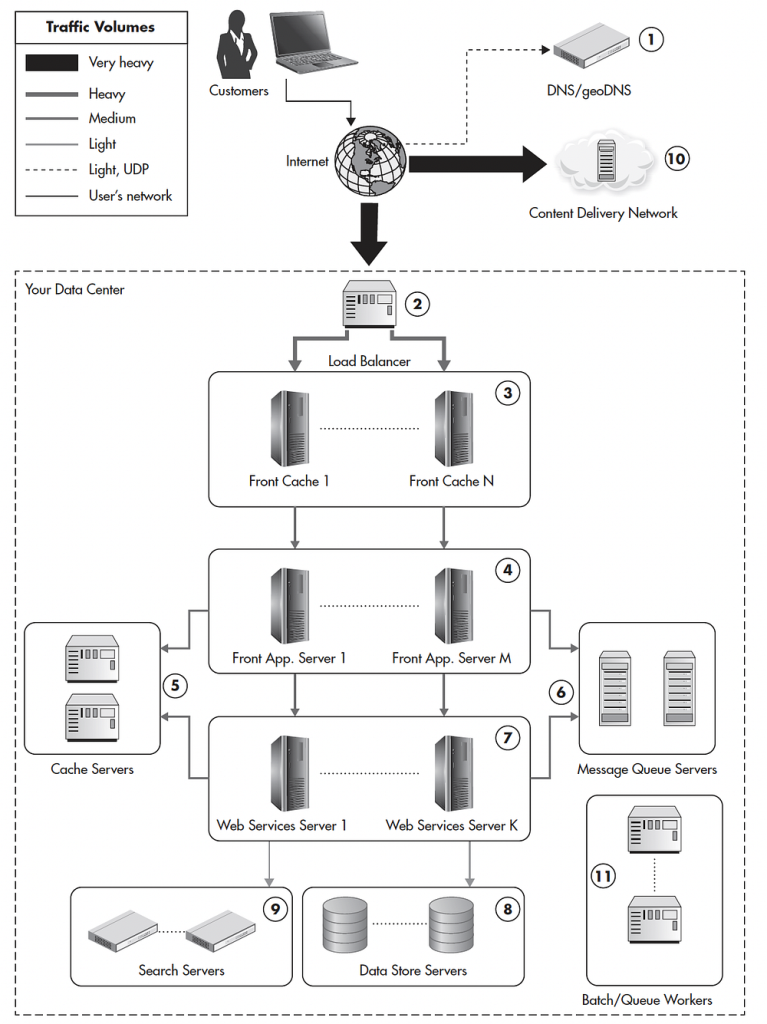
(0) Customers (клиенты) — конечные пользователи веб-приложения.
(1) Domain Name System (DNS, система доменных имен) определяет IP-адрес (адрес сервера, который будет обрабатывать запрос пользователя) на основе доменного имени, например medium.com.
(2) Load Balancer (балансировщик нагрузки) распределяет трафик и нагрузку между несколькими серверами.
(3;5) Cache (кэш) сохраняет данные для ускорения процесса обслуживания запросов пользователей.
(4) Интерфейсное приложение (Frontend) — это пользовательский интерфейс, оболочка приложения, уровень представления данных.
(6) Очередь сообщений хранит запросы пользователей для дальнейшей обработки веб-сервисами.
(7) Веб-сервисы (Backend) отвечают за бизнес-логику (функциональность приложения).
(8) Хранилища данных — место, в которое веб-сервисы записывают данные и из которого считывают их.
(9) Поисковая система отвечает за сложные поисковые запросы, которые хранилище данных не может обрабатывать эффективно.
(10) Сеть доставки контента (CDN) хранит статические файлы для ускоренного обслуживания запросов пользователей, такие как изображения, файлы CSS и JavaScript.
(11) Queue Workers — дополнительные серверы для обработки запросов (сообщений) из очереди сообщений.
Фронтенд-уровень
Фронтенд состоит из следующих компонентов.
- DNS.
- CDN.
- Балансировщик нагрузки/обратный прокси-сервер. Может быть трех типов:
а) размещенный на сервере сервис (например, Elastic Load Balancer от Amazon);
b) самоуправляемый программный балансировщик нагрузки (например, Nginx);
c) аппаратный балансировщик нагрузки. - Интерфейсные веб-серверы (уровень представления и агрегирования результатов, при создании которого используются такие технологии, как PHP, Python, Groovy, Ruby и JavaScript, а именно Node.js).
Фронтенд-уровень хранит информацию о HTTP-сессии (данные о пользователе) через:
а) файлы cookie;
b) внешнее хранилище данных;
c) балансировщика нагрузки.
В случае закрепленного сеанса балансировщик должен убедиться, что запросы с одними и теми же сеансовыми cookies всегда отправляются на тот сервер, который изначально выдал файл cookie.
Бэкенд-уровень/веб-сервисы
Реализовать приложение можно следующими способами.
- Создать монолитное приложение, а затем добавить веб-сервисы в соответствии с потребностями бизнеса.
- Придерживаться ориентированного на API подхода: все клиенты (мобильное приложение, настольная и мобильная версии сайта и т. д.) используют один и тот же интерфейс API.
- Комбинация двух вышеперечисленных подходов.
Веб-сервисы могут быть следующих типов.
- Функционально ориентированные.
> Могут вызывать методы функций на удаленных компьютерах без необходимости знать, как эти функции реализованы.
> Пример. SOAP (использует протокол XML и HTTP). SOAP — более сложный и безопасный вариант, чем REST. - Ориентированные на ресурсы (REST + JSON).
> Ресурсы рассматриваются как объекты, над которыми можно выполнять 4 операции: чтение, создание, обновление и удаление (GET,POST,PUT,DELETE).
>RESTтребует аутентификации для доступа к ресурсам (OAuth 2).
> Зависит от безопасности транспортного уровня (HTTPS).
Масштабировать веб-сервисы REST можно тремя способами.
- Разделение на функциональные части/функциональное разделение.
> Способ разделения сервиса на более мелкие независимые веб-сервисы, когда каждый из них фокусируется на определенной функциональности.
> Между веб-сервисами может быть несколько зависимостей, например между пользователемUserProfileServiceи каталогом продуктовProductCatalogService, когда пользователь сохраняет продукты из каталога.
> Каждый веб-сервис может масштабироваться независимо.
> Интеграция сервисов может оказаться сложной задачей.
> Автор рекомендует использовать сервис-ориентированную архитектуру и веб-сервисы, только когда в технической команде работает более 10-20 инженеров. - Добавление клонов.
- Кэширование протокола HTTP.
> Когда ответыGETкэшируются (ответ чаще возвращается не из веб-сервиса, а из кэша).
Решения для масштабируемости
- Добавление дополнительных клонов/серверов. Это самый простой и дешевый вариант.
- Разделение по функциональности — специализация серверов. Представляет собой сервис-ориентированную архитектуру (SOA), требует больше усилий, а функциональные возможности ограничены.
- Разделение по данным. Подробнее — в следующем разделе.
Уровень данных
Традиционно применяется вертикальное масштабирование (покупка более мощных серверов, добавление оперативной памяти, дополнительных жестких дисков и т. д.).
Ниже перечислены методы масштабирования реляционного хранилища данных (например, MySQL).
1. Репликация.
> Несколько копий одних и тех же данных хранятся на разных компьютерах.
> Необходимо синхронизировать состояние двух серверов: исходного и реплики.
> Модификация данных — только через исходный сервер, но запросы на чтение могут быть распределены между репликами.
> Проблемы репликации: a) масштабирование только для чтения (отлично подходит для приложений с большим объемом чтения); b) нет способа решить проблему активно растущего набора данных; c) реплики могут возвращать устаревшие данные.
2. Разделение/сегментирование данных.
> Разделение набора данных на более мелкие части (нет необходимости обрабатывать весь набор данных).
> Ключ сегментирования является критерием для разделения (например, идентификатор пользователя в интернет-магазине может представлять сегмент, поэтому любая информация о нем, такая как заказы, хранится в этом сегменте).
> Недостатки: а) добавляет значительный объем работы и сложности; b) невозможно выполнять запросы по нескольким сегментам; c) в зависимости от того, как вы сопоставляете ключ сегментирования с номером сервера, может быть сложность с добавлением серверов в инфраструктуру.
> Azure SQL Database Elastic Scale — это готовое к использованию решение для сегментирования.
Ниже — информация о масштабировании с помощью NoSQL (например, Cassandra, Redis, MongoDB, Riak, CouchDB).
Представленная Эриком Брюером теорема CAP гласит: невозможно построить распределенную систему, которая бы одновременно гарантировала согласованность, доступность и устойчивость к разделению.
- Согласованность (Consistency): одни и те же данные одновременно становятся видимыми для всех узлов.
- Доступность (Availability): все доступные узлы должны обрабатывать все входящие запросы, возвращая адекватный ответ.
- Разделение (Partition): кластер должен продолжать работу, несмотря на любое количество сбоев связи между узлами в системе.
Это означает, что одновременно могут быть выполнены только 2 из 3 атрибутов. Например, MongoDB отдает предпочтение высокой доступности, а не согласованности — это хранилище данных CP. Cassandra — хранилище данных AP — обеспечивает доступность и устойчивость к разделению, но не может постоянно гарантировать согласованность.
Текущий тренд: использование функционального разбиения уровня веб-сервисов и различных хранилищ данных в зависимости от потребностей бизнеса.
Кэширование
- Используется для повышения производительности и масштабируемости, поскольку возвращает готовые к использованию результаты.
- Постарайтесь добиться наиболее высокого коэффициента попаданий в кэш (количество повторных использований одного и того же кэшированного ответа).
- Кэширование полезно для приложений со множеством операций чтения и может быть бесполезным для приложений со множественной записью.
- Любое кэширование при необходимости можно добавить на более поздней стадии.
Кэш на основе HTTP — кэш сквозного чтения (клиент сначала обращается к кэшу и только при отсутствии ответа — к веб-сервису).
Кэш на основе HTTP разделяется на следующие типы.
1. Кэш браузера.
> Позволяет хранить данные в браузере.
2. Кэширование прокси-серверов.
> Сервер обычно устанавливается в локальной корпоративной сети или у интернет-провайдера (ISP).
3. Обратные прокси (например, Nginx).
> Размещаются в корпоративном центре обработки данных, чтобы снизить нагрузку на собственные веб-серверы.
> Отличный способ масштабирования.
4. CDN.
> Используется для кэширования статических файлов, таких как изображения, CSS, JavaScript, видео и PDF, но также может обслуживать и динамический контент, если это необходимо.
Кэши пользовательских объектов могут быть следующих видов.
1. Кэш объектов на стороне клиента.
> Хранится на устройстве клиента.
2. Кэши, расположенные с кодом.
> Расположены на веб-серверах (FE или BE).
> Объекты могут кэшироваться непосредственно в: a) памяти/ОЗУ приложения; b) разделяемой памяти (к ней могут обращаться несколько процессов, запущенных на одной машине); c) сервер кэширования может быть развернут на каждом веб-сервере как отдельное приложение (для небольших веб-приложений).
3. Распределенные объектные кэши.
> Redis, Memcached.
Асинхронная обработка
При синхронной обработке вызывающая сторона отправляет запрос и ждет ответа, прежде чем продолжить работу. Используя синхронную обработку, невозможно создавать современные адаптивные приложения.
Асинхронная обработка — клиент может завершить работу, не зная результата обработки запроса, принцип “выстрелил и забыл”.
Очереди сообщений — это технология асинхронной обработки.
- Производители сообщений — часть клиентского кода, создающая сообщение и отправляющая его в очередь сообщений.
- Очереди сообщений — в них сообщения буферизуются и отправляются потребителям.
- Потребители сообщений получают и обрабатывают сообщения из очереди сообщений. Типы потребителей сообщений: а) cron-подобные (вытягивают сообщения из очереди); 2) демоноподобные (push-модель).
Ниже — примеры платформ обмена сообщениями.
- Amazon Simple Queue Service (SQS) — хорошее, простое и практичное решение для стартапов на ранней стадии.
- RabbitMQ предоставляет много возможностей, в том числе сложную маршрутизацию. Это довольно простая и гибкая платформа.
- ActiveMQ написана на основе Java, предлагает очень малую задержку и менее гибкую маршрутизацию, а также может быть чувствительна к пиковым нагрузкам публикуемых сообщений.
Управляемая событиями архитектура
- Не является моделью запроса/ответа. Компоненты объявляют уже произошедшие события вместо того, чтобы запрашивать работу, которая должна быть выполнена.
- Событие — это объект или сообщение, представляющие произошедшее.
- Есть издатели и потребители, которые ничего не знают друг о друге. Они знают только формат и значение сообщения о событии.
Поиск данных
- Полное сканирование таблицы — обычный поиск (нужно просмотреть весь набор данных, чтобы найти искомую строку).
- Для ускорения поиска используются индексы:
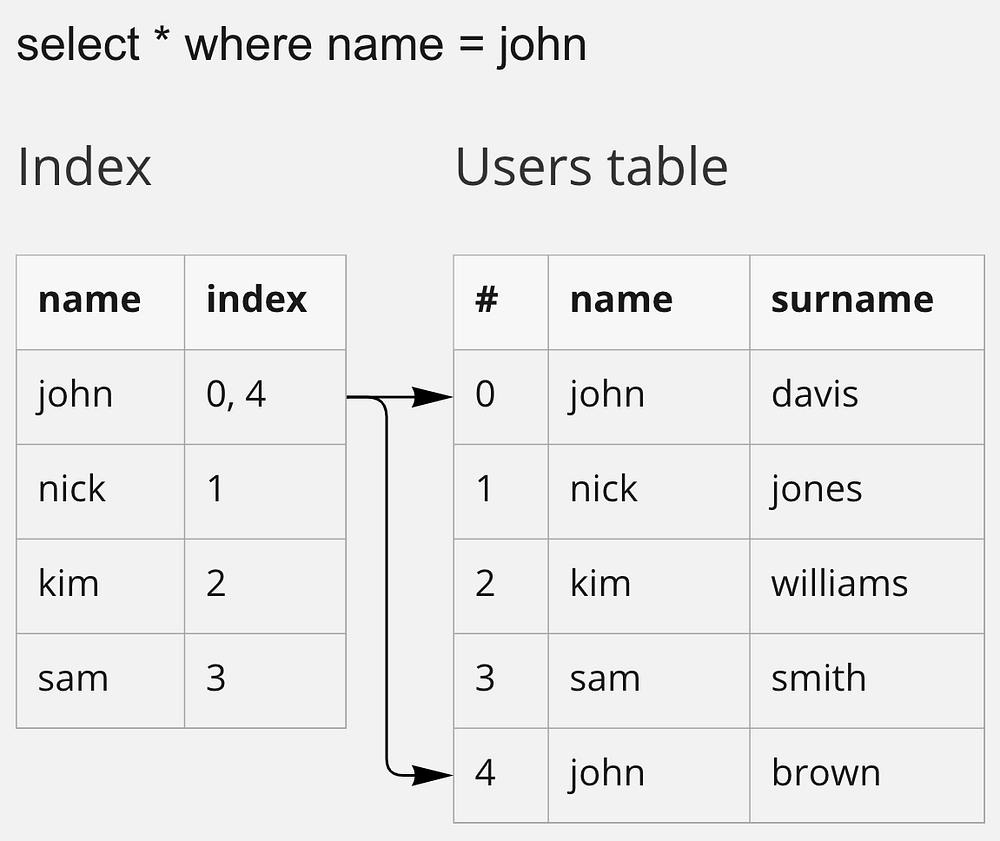
- Что касается моделей данных, реляционная модель — это представление имеющих взаимозависимости таблиц. В нереляционной модели данных вы фокусируетесь на сценариях использования и разрабатываете соответствующие запросы, например, запрос о возвращении набора продуктов (обычно в виде JSON со списком продуктов).
- Для сложных поисковых запросов рекомендуется выбирать поисковые системы. Обычно они используют инвертированный индекс, который позволяет искать фразы и отдельные слова. Готовыми к использованию поисковыми системами являются Amazon CloudSearch, Azure Search, Elasticsearch, Solr и Sphinx.
Заключение
Масштабируемость — это не только архитектура, но и автоматизация различных процессов (тестирование, сборка и развертывание, мониторинг и оповещение, агрегация журналов).
Вот как масштабировать собственный рабочий процесс.
- Работайте умнее, а не усерднее.
- Избегайте сверхурочной работы, поскольку это приводит к психическим проблемам и выгоранию.
- Управляйте задачами, расставляя приоритеты и понимая их реальную ценность.
- Создавайте простой и минималистичный функционал.
- Делегируйте обязанности.
- Делитесь знаниями, сотрудничайте.
- Пользуйтесь сторонними сервисами и не изобретайте велосипед.
- Согласовывайте сроки.
- Выпускайте небольшие версии, следите за отзывами и не развивайтесь в вакууме.
- Создавайте небольшие кросс-функциональные автономные команды от 4 до 9 человек для конкретных областей продукта (например, команда для кассового блока).
- Соблюдайте гибкость для всех процедур и стандартов проекта, поскольку они ограничивают творчество и инновации.
- Совмещайте команды, ставьте общие цели и создавайте хорошую инженерную культуру.
Читайте также:
- Построение системы распределенного кэширования
- Основы аутентификации для начинающих
- Как развернуть веб-приложение Streamlit в сети: три простых способа
Читайте нас в Telegram, VK и Дзен
Перевод статьи Olga Mitroshyna: Software Architecture & System Design: I wish I had known about this earlier…





