
1. Почему AutoML?
Когда-то давно модели машинного обучения с автоматическим обучением были мечтой исследователей данных. Типичная работа специалиста по изучению данных проходит по следующему алгоритму:
- Определение
- Понимание
- Получение
- Анализ
- Подготовка
- Обучение
- Оценка
- Передача
Но большую часть времени специалист потратит только на фазы подготовки, обучения и оценки. Иногда цикл может быть бесконечным!
Поскольку все больше компаний обращаются к МО для решения своих ключевых проблем, от специалистов по обработке данных ожидают результатов за более короткий промежуток времени. Следовательно, возникла потребность в автоматизации ключевых этапов проекта, чтобы исследователи данных могли сосредоточиться на решении реальной проблемы, а не на написании сотен строк кода в поисках лучшей модели. Тогда-то и заговорили об автоматическом МО, которое сразу же вызвало широкий общественный резонанс.
2. Как это реализовать?
В последние годы появилось множество пакетов автоматического МО. Некоторые из них были разработаны так называемыми “компаниями MAGNA” (Meta — Apple — Google — Netflix — Amazon) и предоставляются как часть их облачных сервисов, как, например, Cloud AutoML от Google.
Среди таких проектов-альтернатив с открытым исходным кодом можно назвать следующие:
- AutoWEKA;
- Auto-sklearn;
- Auto-PyTorch;
- PyCaret;
- H2O AutoML и др.
В этой статье мы рассмотрим применение PyCaret.
PyCaret — это малокодовая библиотека машинного обучения с открытым исходным кодом, которая помогает специалистам по изучению данных автоматизировать рабочие процессы МО. Она упрощает этап экспериментирования с моделями и позволяет достичь желаемых результатов с помощью минимального количества кода.
Примечание: Я предполагаю, что PyCaret уже установлена на вашем компьютере. Вы можете инсталлировать ее с помощью команды pip install pycaret
Я проведу вас через весь процесс, используя пример набора данных, предоставленный PyCaret. Мы попытаемся решить задачу по классификации и определим, является ли клиент надежным налогоплательщиком или нет.
Вы можете импортировать данные с помощью функции get_data()
from pycaret.datasets import get_data
# Импорт данных
df = get_data("credit")
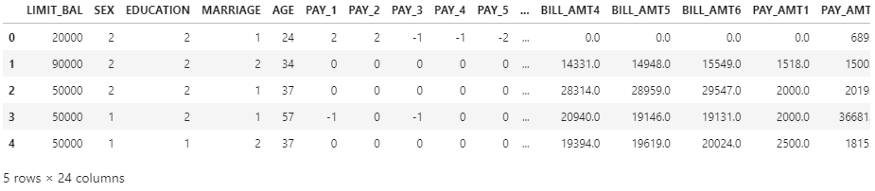
Мы можем проверить форму датасета и разделить данные на наборы знаний (из них мы получим тренировочный, валидационный и тестовый наборы) и наборы полезных данных.
# Выводим форму датафрейма df.shape # Подготовка набора знаний knowledge = df.sample(frac=.8, random_state=seed) knowledge.reset_index(inplace=True, drop=True) knowledge.shape # Подготовка набора полезных данных payload = df.drop(knowledge.index) payload.reset_index(inplace=True, drop=True) payload.shape
PyCaret включает в себя несколько алгоритмов для решения задач классификации. Мы можем использовать их путем импорта.
from pycaret.classification import *
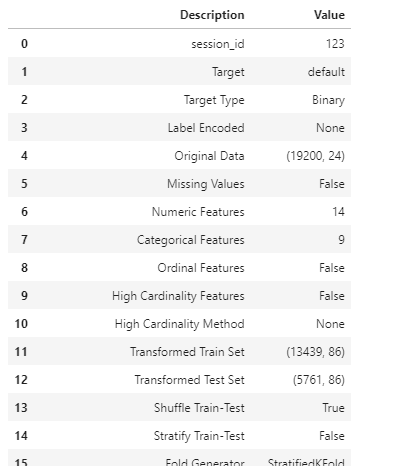
Далее нам необходимо инициализировать среду и конвейер преобразования. Это можно сделать с помощью функции setup(). Эта функция выполняет все шаги по предварительной обработке данных, чтобы подготовить их к работе. Мы также можем вручную переопределить параметры по умолчанию, указав их при вызове. Нам просто нужно передать набор данных и целевой столбец, а все остальные параметры являются необязательными.
clf = setup(data=knowledge, target="default", session_id=123)
После выполнения этого действия в ноутбуке будет предложено указать, являются ли обнаруженные типы данных столбцов корректными или нет. Нажмите Enter для подтверждения, и PyCaret отобразит следующий набор информации.
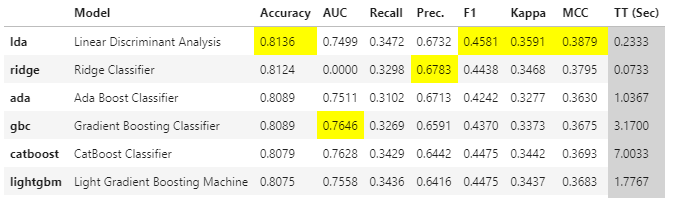
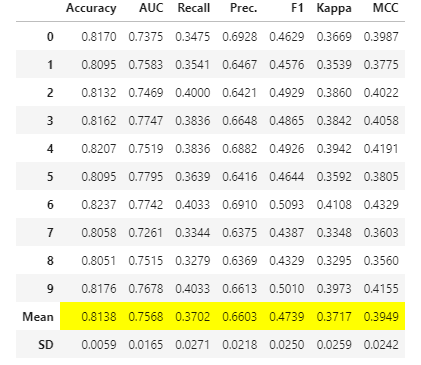
Теперь мы можем сравнить, как различные модели работают на нашем обучающем датасете. Используем для этого функцию compare_models()
best_model = compare_models(fold=3)
В таблице ниже показано, как различные модели показали себя относительно нашего набора данных. Результаты по умолчанию отсортированы по уровню точности.
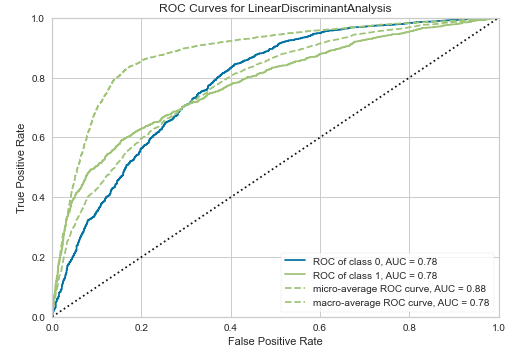
Мы можем визуализировать производительность моделей с помощью функции plot_model()
plot_model(best_model, plot="auc")
Мы можем легко выполнить настройку гиперпараметров с помощью функции tune_model()
tuned = tune_model(best_model)
Как только мы определились с моделью, можем использовать ее для прогнозирования на наборе полезных данных. Это поможет нам понять, как модель работает с невидимыми данными. Используем функцию predict_model().
predictions = predict_model(final_model, data=payload)
PyCaret также позволяет сохранить модель в виде файла .pkl, чтобы ее можно было потом развернуть для использования в производственных конвейерах.
save_model(final_model,'Tuned Model 13 Nov 2021')
Как видим, с помощью минимального количества кода мы провели предварительную обработку данных, поэкспериментировали с более чем 15 алгоритмами и создали образец нашей модели, который может быть развернут для предоставления прогнозов в реальном времени. Так что использовать PyCaret для проектов в сфере дата-сайенс очень просто. PyCaret также позволяет нам задействовать такие продвинутые технологии, как бэггинг, бустинг и стекинг с помощью соответствующих функций.
Полный код
from pycaret.datasets import get_data
# Набор данных о неплательщиках по кредиту
df = get_data("credit")
# Проверка формы набора данных
df.shape
# Инициализация начального числа для генераторов случайных чисел
seed = 10
# Создание обучающего набора с помощью выборки pandas — видимый набор данных
knowledge = df.sample(frac=.8, random_state=seed)
knowledge.reset_index(inplace=True, drop=True)
knowledge.shape
# Использование образцов, недоступных в обучающем наборе, в качестве будущего или невидимого набора данных
payload = df.drop(knowledge.index)
payload.reset_index(inplace=True, drop=True)
payload.shape
# Задействуем волшебную функцию!
from pycaret.classification import *
# Функция setup инициализирует среду и создает конвейер преобразования
clf = setup(data=knowledge, target="default", session_id=123)
# Сравниваем различные модели в зависимости от их метрик производительности. По умолчанию модели сортируются по точности
best_model = compare_models(fold=5)
# Построение кривой AUC
plot_model(best_model, plot="auc")
# Функция Tune model выполняет сеточный поиск для определения оптимальных параметров
tuned = tune_model(best_model)
plot_model(tuned, plot="confusion_matrix")
# Прогнозирование на тестовом наборе
predict_model(tuned)
# Доработка модели путем переобучения на всем видимом наборе данных
final_model = finalize_model(tuned)
# Прогнозирование на невидимых данных
predictions = predict_model(final_model, data=payload)
predictions.head()
# Модель будет сохранена в формате .pkl и может быть использована в дальнейшем
save_model(tuned,'Tuned Model 13 Nov 2021')
3. Что нам дает автоматическое МО?
AutoML упрощает задачу специалиста по анализу данных, автоматически обучая и настраивая модели для достижения оптимальной точности в зависимости от предоставленных данных. Поначалу это может показаться нереальным, но AutoML действительно обучает модели с помощью различных алгоритмов и настраивает параметры с помощью сеточного поиска. Это, безусловно, воплощенная мечта всех ленивых специалистов по данным!
В AutoML еще многое предстоит улучшить. Но это уже определенно шаг вперед в области машинного обучения. Благодаря AutoML, специалисты по обработке данных могут сосредоточиться на предоставлении компьютеру высококачественных данных для решения той или иной задачи. В конце концов, чем больше времени вы потратите на получение качественных данных, тем меньше усилий вам понадобится на создание из них наилучшей модели!
Читайте также:
- Новый модуль временных рядов PyCaret
- 8 показателей эффективности классификации
- Как использовать ИИ и Python для распознавания речи
Читайте нас в Telegram, VK и Дзен
Перевод статьи Venkatesh Prabhu, Introduction to AutoML using PyCaret





