
Человеческий слух легко приспосабливается к любому разговору с другими людьми, распознавая разные по тональности и акцентам манеры речи. Но машинное распознавание особенностей человеческого голоса реализовать не так просто.
Точное описание речевого сигнала считается довольно сложной задачей для машин. Такая проблема существовала и до появления систем искусственного интеллекта, которые теперь выполняют функции распознавания речи и обработки естественного языка. Рассмотрим, как разработать с помощью Python и платформы AssemblyAI высокопроизводительную систему, распознающую речь в режиме реального времени.
Произносимая пользователем в микрофон информация будет одновременно отображаться для него в виде текста. Помимо транскрибирования, ИИ также попытается разбить речь на предложения, разобраться в особенностях лингвистики и расставить знаки препинания.
В данной статье не рассматриваются особенности написания с помощью Python веб-приложения для преобразования речи (аналогового сигнала) в текст (цифровые данные). Создание такой программы — это отдельная тема.
Система распознавания речи в режиме реального времени
Целью проекта является транскрибирование звука в режиме реального времени с максимально высоким качеством. Каждую секунду микрофон будет передавать результаты пословно, распознавая речь с помощью платформы AssemblyAI. Для оптимизации распознавания ИИ попытается по завершении предложения понять его смысл, добавив знаки препинания и заглавные буквы.
Приступим к добавлению всех необходимых пакетов и библиотек.
Установка необходимых компонентов
Для чтения информации через микрофон в этом проекте используется библиотека pyAudio. Также нужно установить библиотеку веб-сокетов для создания с помощью Python надежных и высокопроизводительных веб-сокетов серверов и клиентов.
pip install pyaudio
pip install websocketsУстановка на MAC относительно проще, поскольку с помощью команды «brew install portaudio» можно получить все необходимые зависимости, настроенные соответствующим образом. Для Windows нужно посетить неофициальный сайт библиотек Python и загрузить нужную версию pyAudio. Загруженный файл уже содержит важные детали для непосредственной установки библиотеки. Загрузите его в нужную папку и запустите установку в этом каталоге следующим образом.
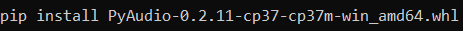
В завершение импортируем все необходимые компоненты, как показано в приведенном ниже блоке кода. Asyncio — это стандартная среда асинхронного ввода-вывода Python, которая включает элегантный API на основе сопрограмм. Также мы будем использовать библиотеку base64 для декодирования запросов, библиотеку JSON для подготовки файлов и импорт конфигурации, в которой будет храниться ключ API.
import websockets
import asyncio
import base64
import json
from configure import auth_key
import pyaudioПосле импорта всех необходимых библиотек переходим к следующему этапу — к настройке файла конфигурации для установки соединения с платформой AssemblyAI.
Настройка конфигурации
Файл конфигурации должен называться configure.py и содержать ключ API, который можно получить на сайте Assembly. Обратите внимание, что для транскрибирования в реальном времени потребуется приобрести относительно недорогой профессиональный план. Введите ключ авторизации, указанный в правой части экрана, скопировав его и вставив в показанный ниже фрагмент кода.
auth_key = 'Введите здесь ключ API'После установки файла конфигурации с ключом аутентификации продолжим работу с основным файлом Python, где завершим оставшуюся часть скриптов для декодирования произносимой в микрофон речи.
Настройка параметров
Сначала импортируем все основные параметры, чтобы получать с микрофона входные сигналы наилучшего качества. Для pyAudio могут быть установлены: кадры, формат, каналы и скорость, как показано в приведенном ниже фрагменте кода. После установки параметров в соответствии с требованиями можно также задать URL-адрес конечной точки, ссылающийся на сайт assemblyAI.
FRAMES_PER_BUFFER = 3200
FORMAT = pyaudio.paInt16
CHANNELS = 1
RATE = 16000
p = pyaudio.PyAudio()
# начало записи
stream = p.open(
format=FORMAT,
channels=CHANNELS,
rate=RATE,
input=True,
frames_per_buffer=FRAMES_PER_BUFFER
)
# адрес конечной точки AssemblyAI
URL = "wss://api.assemblyai.com/v2/realtime/ws?sample_rate=16000"Следует заметить, что частота дискретизации, указанная в конечной точке Assembly AI, также равна 16000, что синхронизируется с частотой в библиотеке pyAudio. Определив эти основные параметры, можно создать функцию, которая позволит отправлять входные аудиоданные и получать по ним транскрибированные текстовые данные.
Создаем функцию отправки и приема
Разработаем полный код для отправки информации от микрофона в конечную точку AssemblyAI (там аудио данные преобразуются в текст) и получения обратно в режиме реального времени. Для транскрибирования аудио данных в таком режиме понадобится несколько асинхронных функций.
В следующем фрагменте реализуем основную функцию, позволяющую создать асинхронное соединение из локальной системы с конечной точкой AssemblyAI. Используя ранее импортированную библиотеку WebSockets можно установить соединение с сайтом AssemblyAI, где информация от микрофона будет каждую секунду транскрибироваться и сразу отправляться обратно.
async def send_receive():
print(f'Connecting websocket to url ${URL}')
async with websockets.connect(
URL,
extra_headers=(("Authorization", auth_key),),
ping_interval=5,
ping_timeout=20
) as _ws:
await asyncio.sleep(0.1)
print("Receiving SessionBegins ...")
session_begins = await _ws.recv()
print(session_begins)
print("Sending messages ...")После написания основной функции можно приступить к созданию пары асинхронных функций для отправки и получения данных. Первая функция send() позволит получать поток звука от микрофона. Затем преобразовываем его в формат base64 с некоторым декодированием и отправляем через установленное соединение в конечную точку. Отметим также некоторые встречающиеся исключения.
async def receive():
while True:
try:
result_str = await _ws.recv()
print(json.loads(result_str)['text'])
except websockets.exceptions.ConnectionClosedError as e:
print(e)
assert e.code == 4008
break
except Exception as e:
assert False, "Not a websocket 4008 error"
send_result, receive_result = await asyncio.gather(send(), receive())
while True:
asyncio.run(send_receive())В завершение определим функцию receive(), которая позволит получить транскрибированные тестовые результаты для отправленных аудиоданных. Можно получать либо частичные предварительные результаты, которые содержат оперативную посекундную выборку, либо окончательные результаты, содержащие полное уточненное и грамматически правильное предложение. Полная информация о различных параметрах транскрибирования в реальном времени есть в документации к Assembly AI .
async def receive():
while True:
try:
result_str = await _ws.recv()
print(json.loads(result_str)['text'])
except websockets.exceptions.ConnectionClosedError as e:
print(e)
assert e.code == 4008
break
except Exception as e:
assert False, "Not a websocket 4008 error"
send_result, receive_result = await asyncio.gather(send(), receive())
while True:
asyncio.run(send_receive())По завершении этих этапов переходим к последнему, где рассмотрим результаты и полный код для распознавания речи в режиме реального времени.
Окончательный код
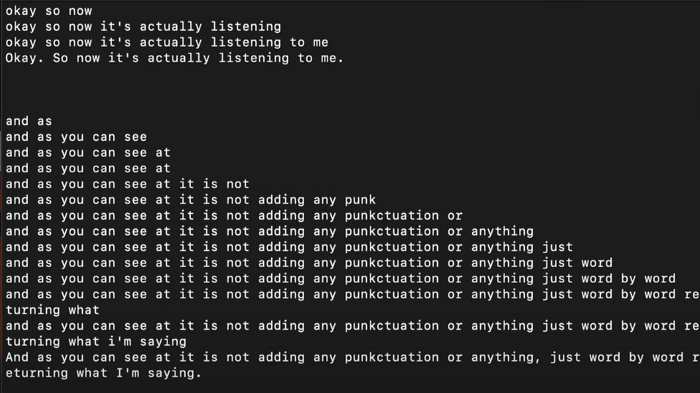
Каждое произносимое слово ежесекундно транскрибируется конечной точкой Assembly AI с выдачей соответствующего результата. Но по завершении предложения ИИ автоматически начнет его с заглавной буквы, сформулирует грамматически правильно, расставит знаки препинания и добавит необходимые изменения, как в последнем предложении на скриншоте выше. Ниже приведен финальный вариант кода программы. Ее можно запустить с командного терминала с помощью команды python speech_recognition.py.
import websockets
import asyncio
import base64
import json
from configure import auth_key
import pyaudio
FRAMES_PER_BUFFER = 3200
FORMAT = pyaudio.paInt16
CHANNELS = 1
RATE = 16000
p = pyaudio.PyAudio()
# начало записи
stream = p.open(
format=FORMAT,
channels=CHANNELS,
rate=RATE,
input=True,
frames_per_buffer=FRAMES_PER_BUFFER
)
# адрес конечной точки AssemblyAI
URL = "wss://api.assemblyai.com/v2/realtime/ws?sample_rate=16000"
async def send_receive():
print(f'Connecting websocket to url ${URL}')
async with websockets.connect(
URL,
extra_headers=(("Authorization", auth_key),),
ping_interval=5,
ping_timeout=20
) as _ws:
await asyncio.sleep(0.1)
print("Receiving SessionBegins ...")
session_begins = await _ws.recv()
print(session_begins)
print("Sending messages ...")
async def send():
while True:
try:
data = stream.read(FRAMES_PER_BUFFER)
data = base64.b64encode(data).decode("utf-8")
json_data = json.dumps({"audio_data":str(data)})
await _ws.send(json_data)
except websockets.exceptions.ConnectionClosedError as e:
print(e)
assert e.code == 4008
break
except Exception as e:
assert False, "Not a websocket 4008 error"
await asyncio.sleep(0.01)
return True
async def receive():
while True:
try:
result_str = await _ws.recv()
print(json.loads(result_str)['text'])
except websockets.exceptions.ConnectionClosedError as e:
print(e)
assert e.code == 4008
break
except Exception as e:
assert False, "Not a websocket 4008 error"
send_result, receive_result = await asyncio.gather(send(), receive())
while True:
asyncio.run(send_receive())Заключение
С развитием технологии ИИ значительно упростилось создание качественных и производительных систем распознавания речи на основе компьютеров. В этой статье мы разобрали особенности программирования такой системы на языке Python с использованием сетевой платформы AssemblyAI для транскрибирования речевого сигнала в режиме реального времени.
Читайте также:
- Распознавание речи с помощью Python
- 10 инструментов Python для работы с изображениями
- 6 концептов книги Эндрю Ына «Жажда машинного обучения»
Читайте нас в Telegram, VK и Дзен
Перевод статьи Bharath K: How To Use AI for Real-Time Speech Recognition with Python





