
Ludwig — это декларативный фреймворк машинного обучения с открытым исходным кодом. Он позволяет легко определять конвейеры глубокого обучения с помощью простой и гибкой системы конфигурации, основанной на данных. Этот фреймворк подходит для решения широкого спектра задач ИИ и размещен на Linux Foundation AI & Data.
Ludwig позволяет определить конвейер глубокого обучения лишь с помощью конфигурационного файла, в котором перечислены входы и выходы, а также соответствующие им типы данных. Затем Ludwig собирает и обучает модель глубокого обучения и, основываясь на конфигурационном файле, определяет, как входные и выходные данные будут предварительно обработаны, закодированы, декодированы, а также какие метрики и критерий потерь использовать.
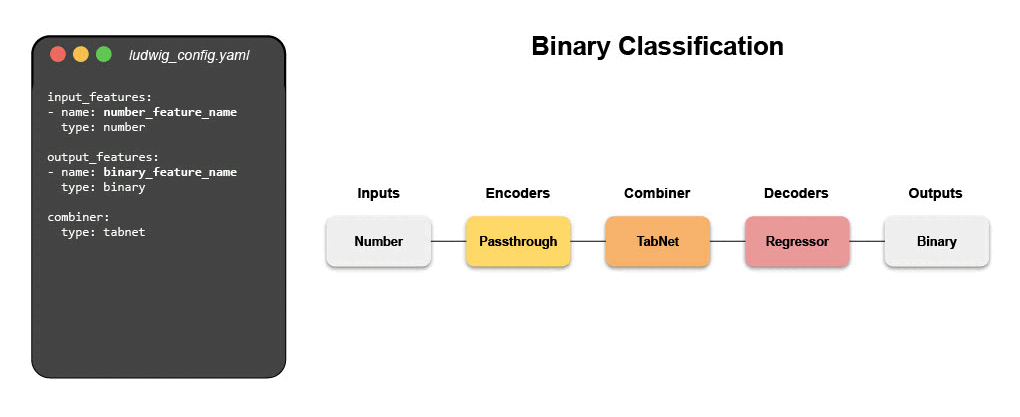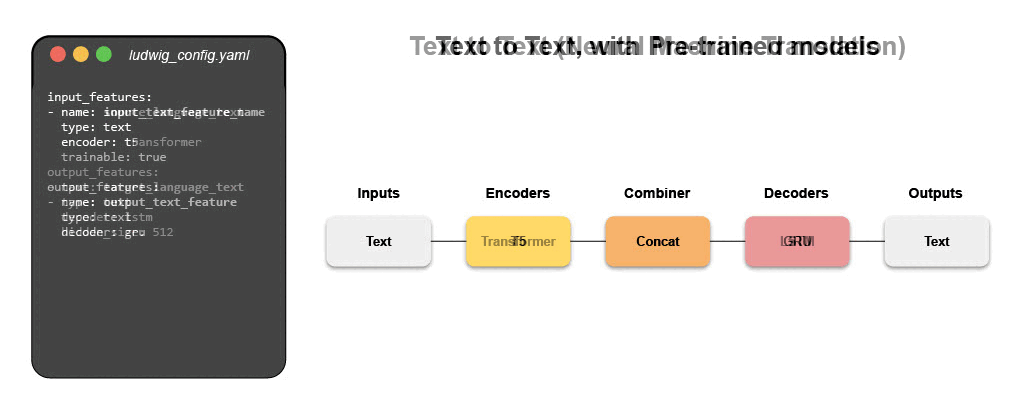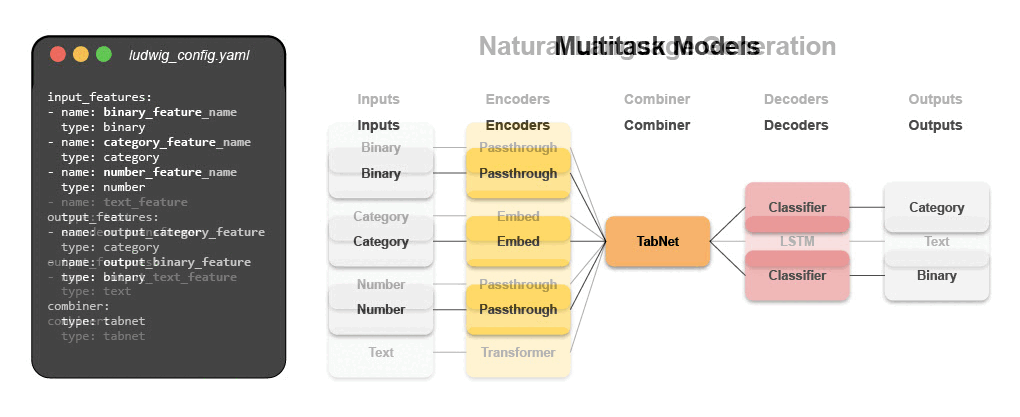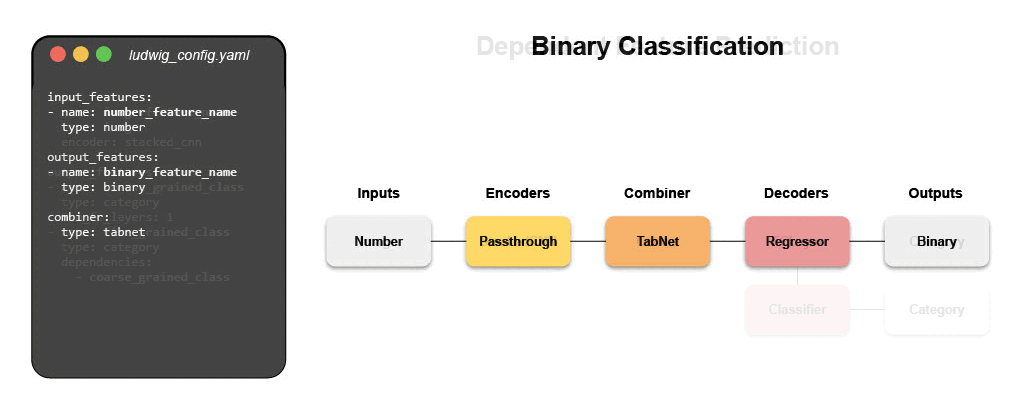
Написать конфигурационный файл для Ludwig очень просто. Гибкость конфигурационного файла позволяет полностью контролировать каждый аспект сквозного конвейера. Этот контроль включает:
- изучение самых современных архитектур моделей;
- запуск поиска по гиперпараметрам;
- масштабирование до наборов данных, превышающих объем доступной памяти, и многоузловых кластеров;
- предоставление в производство наилучшей модели.
Все это достигается путем простого изменения конфигурационного файла.
Мы с радостью объявляем о выпуске Ludwig v0.5 — переработанной с нуля версии Ludwig. Помимо новых функций и нескольких важных технических оптимизаций, Ludwig v0.5 переводит весь бэкенд на PyTorch. Этот переход стал результатом 6-месячной работы, включающей свыше 230 коммитов, изменения в более чем 70 тысячах строк кода и вклада более 40 человек.
Дизайн PyTorch и акцент на опыте разработчиков идеально сочетаются с принципами Ludwig — простотой, модульностью и расширяемостью. С переносом Ludwig на PyTorch разработчики, исследователи и специалисты по обработке данных в растущем сообществе PyTorch смогут привнести в Ludwig много полезных функций.
Мы расскажем о том, как пользователи PyTorch могут применять Ludwig, а также поделимся результатами сравнительного анализа Ludwig v0.4 и Ludwig v0.5 на PyTorch. Помимо этого, расскажем о том, что ждет Ludwig в будущем.
Декларативное глубокое обучение теперь в PyTorch
Ludwig v0.5 привносит в экосистему PyTorch декларативный подход к структурированию конвейеров машинного обучения, а также свои модели, инструменты, инфраструктуру и опыт участников.
Полезные ссылки:
Ludwig пригодится ученым-исследователям, специалистам по обработке данных и инженерам по машинному обучению, работающим в PyTorch.
Для ученых-исследователей
PyTorch — самая популярная библиотека для ученых-исследователей глубокого обучения, которые разрабатывают новые алгоритмы обучения, проектируют и создают новые архитектуры моделей и проводят эксперименты с ними.
Однако эксперименты с новой архитектурой часто требуют огромного объема кода для масштабируемой загрузки и предварительной обработки данных, а также настройки конвейеров для (распределенного) обучения, оценки и оптимизации гиперпараметров.
Минимальные шаблоны машинного обучения
Ludwig берет на себя заботу об инженерной сложности глубокого обучения, позволяя ученым-исследователям сосредоточиться на построении моделей на самом высоком уровне абстракции.
Допустим, у вас есть отличная идея для новой архитектуры классификации изображений, которая меняет способ их кодирования. Эту новую модель вы бы реализовали в виде модуля PyTorch.
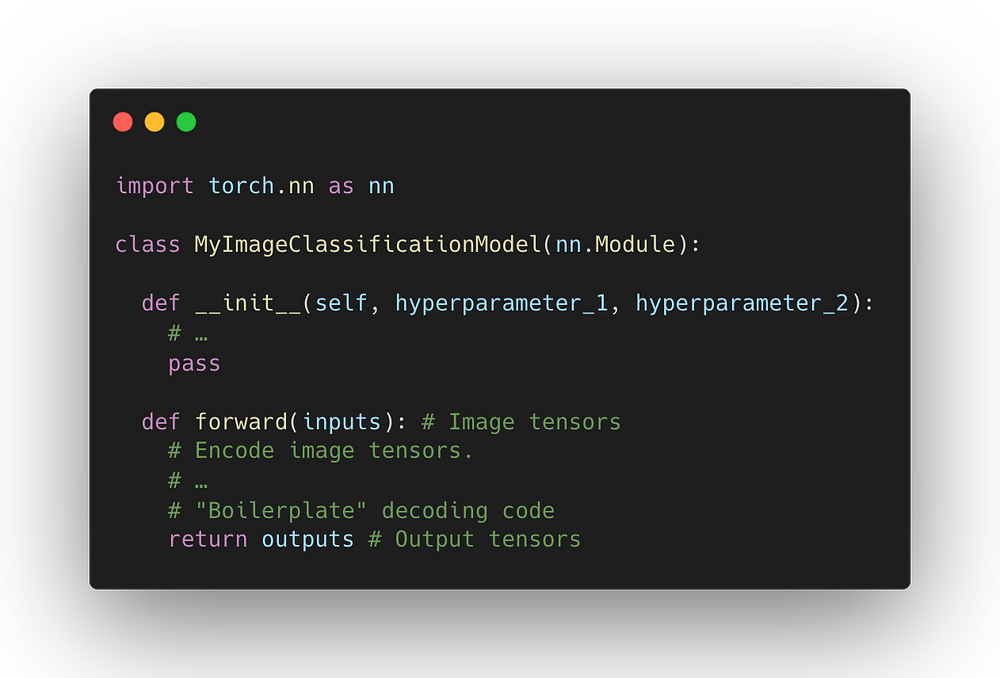
Однако этого недостаточно — также потребуется выяснить, как считывать изображения с диска с помощью пакета Torchvision, написать цикл “обучение → контрольная точка → оценка”, выполнить постпроцессинг логит-тензоров в предсказания и вычислить метрики на основе предсказаний. Все эти шаги увеличивают время разработки модели и создают потенциальные источники ошибок.
Вместо того чтобы реализовывать все это с нуля, ученые-исследователи могут внедрять новые модели в виде модулей PyTorch непосредственно в Ludwig. Поскольку в нашем случае идея моделирования применима конкретно к кодированию изображений, то необходимо реализовать только кодер.
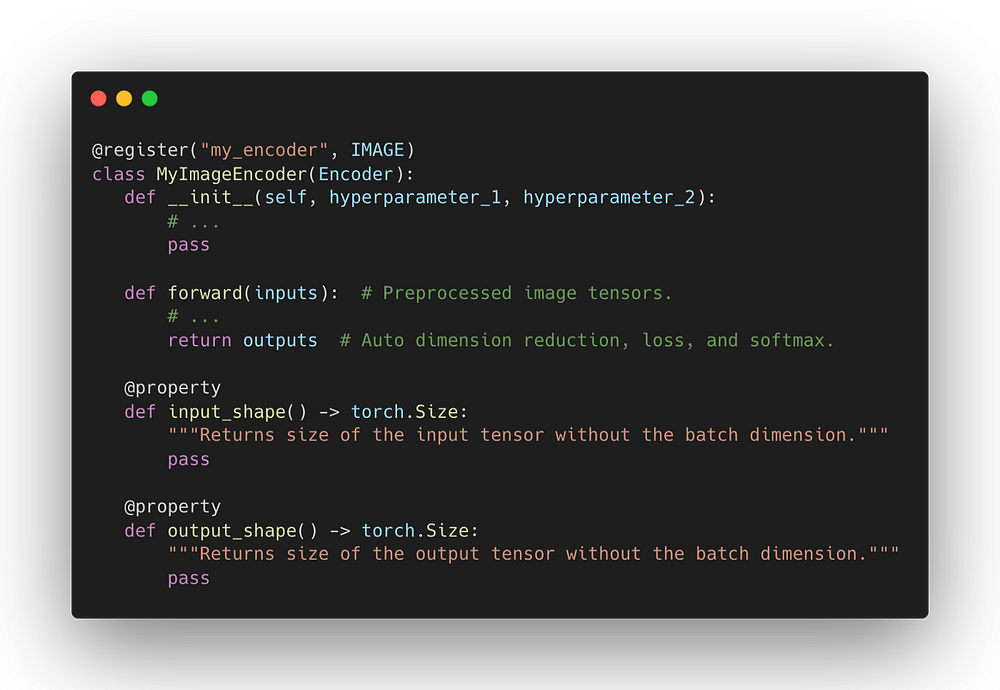
Кодер my_encoder можно сразу использовать в новой конфигурации Ludwig, просто запустив его с помощью encoder: my_encoder. А Ludwig позаботится об остальной части конвейера.
Сравнение с исходными моделями
При создании новой модели всегда хочется сравнить ее с исходной. Ludwig позволяет создать две почти идентичные конфигурации — для исходной модели и для новой. Они будут отличаться только в части кодирования. Например, вы можете обучить исходную модель ResNet с помощью следующей конфигурации и команды.

ludwig experiment --config baseline.yaml --dataset my_dataset.csv
Замена одного только кодера на my_encoder с его параметрами позволяет обучить модель с использованием пользовательского кодера.

ludwig experiment --config my_encoder.yaml --dataset my_dataset.csv
Это гарантирует проведение одинаковой предварительной обработки, обучения и оценки в обоих случаях, что позволит легко и объективно определить производительность нового кодера.
Оптимизация гиперпараметров с помощью Ray Tune
Конфигурации Ludwig могут также включать раздел оптимизации гиперпараметров. Он позволяет объявить оптимизацию гиперпараметров, их диапазонов и метрик, используя RayTune — библиотеку Python для проведения экспериментов и настройки гиперпараметров.
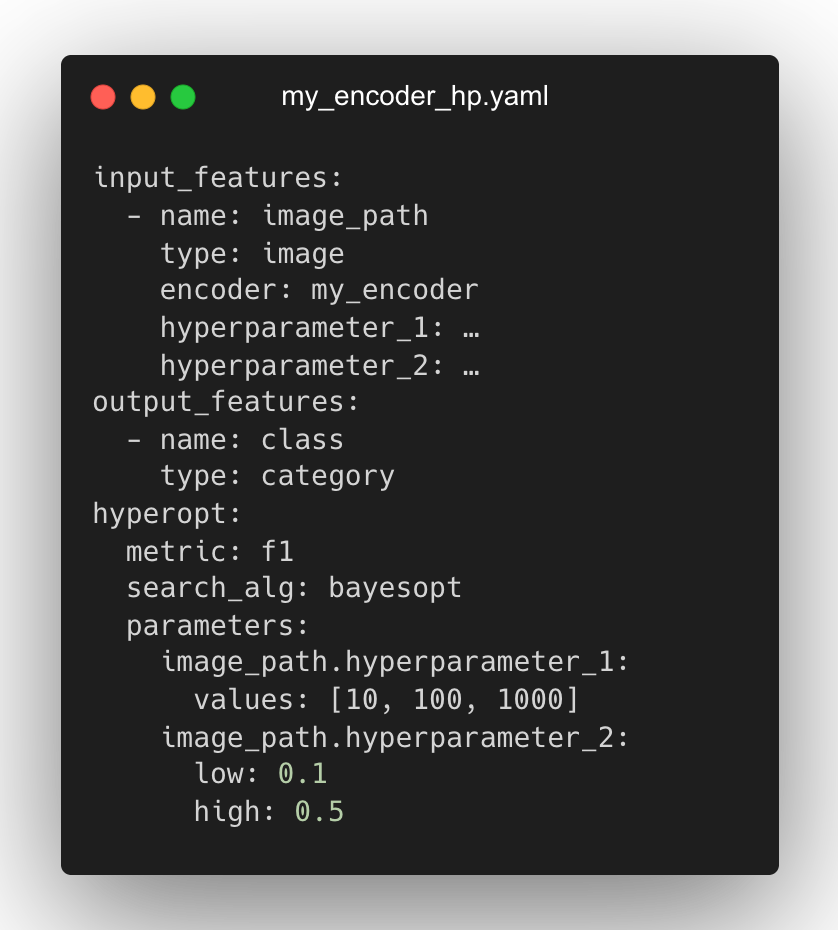
Процесс оптимизации гиперпараметров может быть запущен локально или на кластере Ray. При этом может быть выбран любой из алгоритмов поиска, поддерживаемых RayTune, включая байесовскую оптимизацию, Hyperband, Nevergrad и другие.
Простое тестирование на нескольких задачах и наборах данных
Зарегистрированные модели могут быть впоследствии применены на обширном спектре задач и наборов данных, которые поддерживает Ludwig, а также на новых. Ludwig включает в себя полный набор инструментов для бенчмаркинга. Он позволяет проводить эксперименты с несколькими моделями на нескольких наборах данных с помощью простой конфигурации.
Чтобы узнать, как добавить набор данных и модель в Ludwig, ознакомьтесь с документацией Ludwig и набором данных Ludwig Dataset Zoo.
Для специалистов по анализу данных
Low-code интерфейс для самых современных моделей, включая предварительно обученные модели Huggingface Transformers
Ludwig обеспечивает современный уровень производительности для многих задач МО без необходимости написания сотен строк кода.
Ludwig предоставляет надежные реализации распространенных архитектур, включая CNN, RNN, Transformers, TabNet и MLP-Mixer. Кроме того, благодаря кодовой базе на PyTorch, Ludwig может более тесно интегрироваться с такими проектами сообщества, как torchtext, torchvision и torchaudio, для поддержки дополнительных архитектур и модальностей.
Модели могут быть обучены с нуля, но Ludwig также интегрируется с предварительно обученными моделями, такими как модели Huggingface Transformers. Вы можете выбрать из обширной коллекции PyTorch любую современную предварительно обученную модель, чтобы использовать ее без написания какого-либо кода. Например, с помощью Ludwig можно легко обучить модель анализа настроений на основе BERT:
ludwig train --dataset sst5 --config_str "{input_features: [{name: sentence, type: text, encoder: bert}], output_features: [{name: label, type: category}]}"
Low-code интерфейс для AutoML
Ludwig AutoML позволяет получать обученные модели, предоставляя только набор данных, целевой столбец и бюджет времени выполнения.
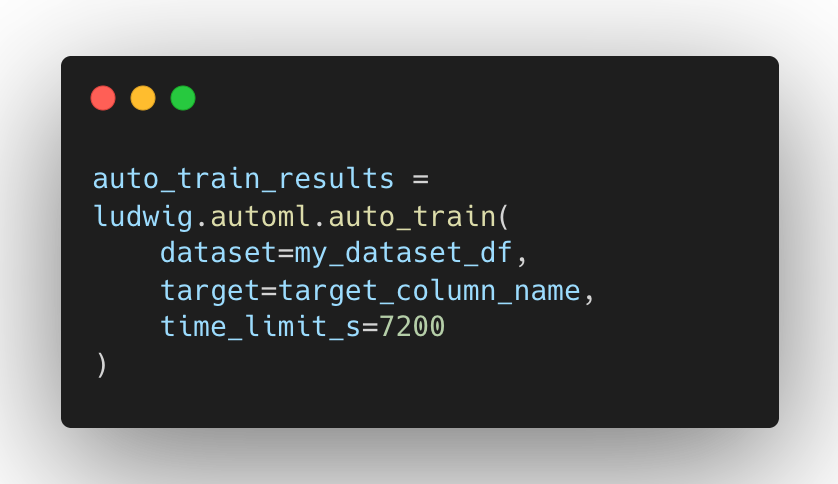
Ludwig AutoML является функцией предварительного просмотра, но она уже полностью перенесена в PyTorch в версии 0.5.
Высококонфигурируемая предварительная обработка данных, моделирование и метрики
Любые аспекты архитектуры модели, цикла обучения, поиска по гиперпараметрам и инфраструктуры бэкенда могут быть изменены в виде дополнительных полей в декларативной конфигурации для настройки конвейера в соответствии с вашими требованиями. Вот пример конфигурации со множеством дополнительных параметров настройки.
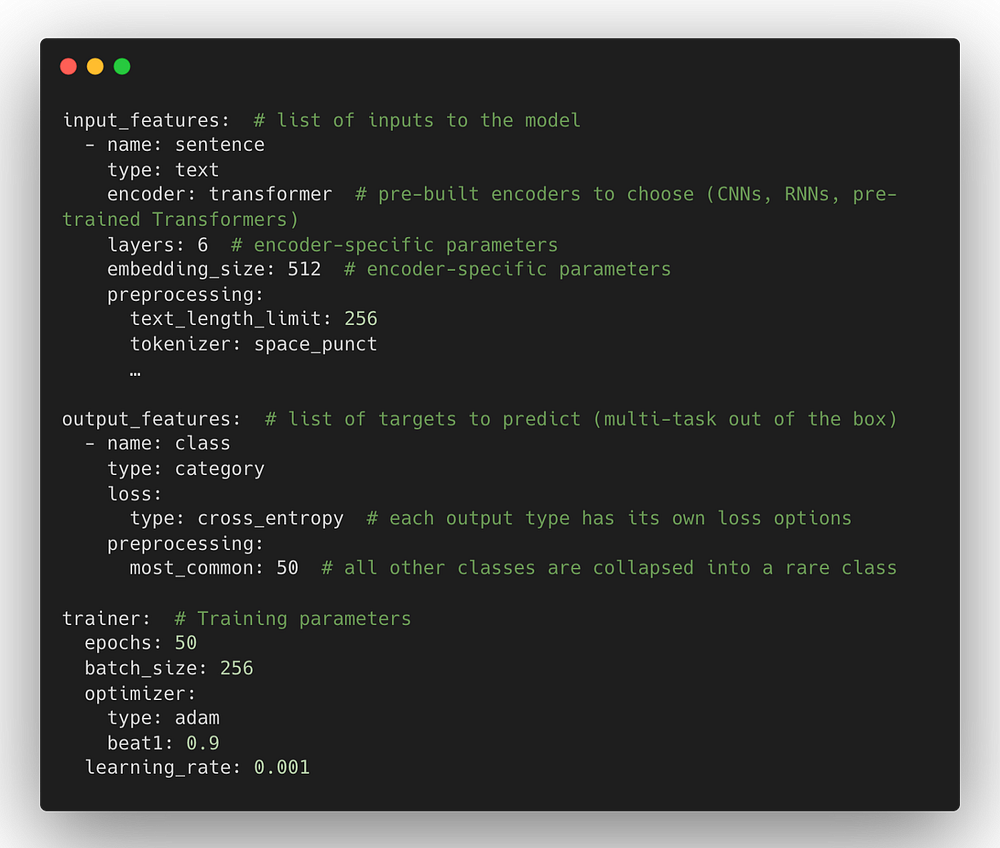
Подробную информацию о настройках можно найти в документации по конфигурации Ludwig. Если модель, потери, метрика оценки, функция предварительной обработки и другие части конвейера еще не доступны, модульность базовой архитектуры позволяет пользователям легко расширить возможности Ludwig путем реализации простых абстрактных интерфейсов, как описано в руководстве для разработчиков.
Для инженеров по машинному обучению
Эффективное сквозное масштабирование до нескольких узлов, Multi-GPU
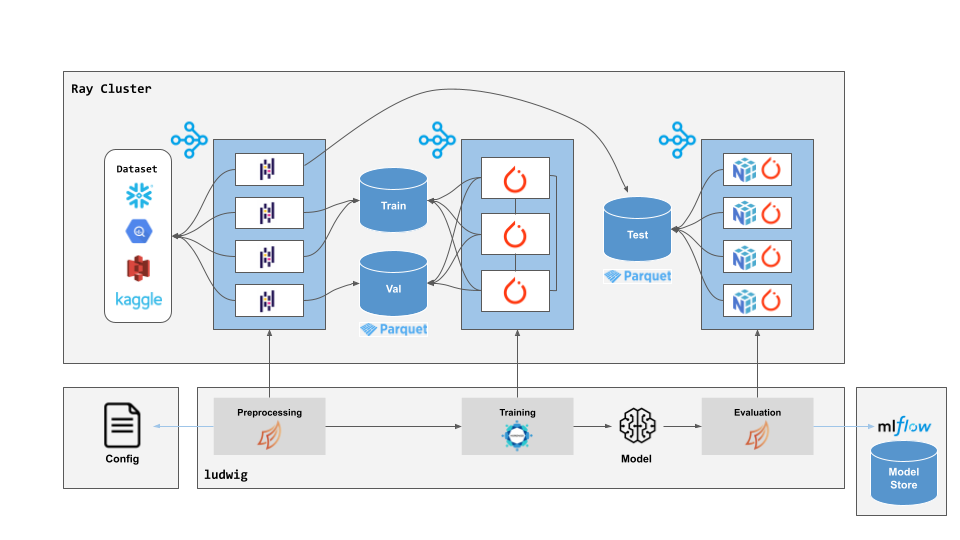
PyTorch обеспечивает высокую производительность при обучении на одном или нескольких GPU. Однако при построении сквозной системы для распределенного обучения остается много операционных сложностей.
- Необработанные входные данные должны быть предварительно обработаны и преобразованы в формат, пригодный для обучения. Если имеется большой набор данных, потребуется создать кластер пакетной обработки, такой как Spark и Dask, для выполнения этого этапа.
- Обработанные данные необходимо эффективно перемешивать в каждый период для обеспечения устойчивости модели. Часто эта работа перекладывается на тренинг-воркеры для GPU, что приводит к несовершенному локальному перемешиванию, которое затягивает процесс обучения.
- Тренинг-воркеры для GPU должны быть предоставлены и настроены для координации друг с другом с помощью библиотеки коллективного взаимодействия, например MPI и NCCL. Это означает, что конвейеры поглощения данных, вычисление метрик, инициализация весов модели и шаги обратного распространения должны быть переписаны для поддержки параллелизма данных.
- Вся эта распределенная инфраструктура обучения должна быть предоставлена и настроена для запуска в виде рабочего процесса, обычно с использованием дополнительной системы, такой как Airflow и Kubeflow, для работы в качестве уровня оркестровки.
В Ludwig v0.5 все это упрощено и представляет собой всего лишь деталь реализации. Благодаря запуску Ludwig на базе Ray, та же командная строка Ludwig и вызовы Python API, которые выполняются на ноутбуке, могут масштабироваться на кластер машин в облаке без изменений кода. Достаточно лишь запустить Ray-кластер и отправить имеющуюся в Ludwig команду или скрипт для выполнения с помощью Ray CLI:
ray up cluster.yaml
ray submit cluster.yaml ludwig train --config model.yaml --dataset s3://bucket/dataset.parqut
При работе на Ray Ludwig автоматически обрабатывает всю сквозную оркестровку и распределенное выполнение. Dask на Ray будет использоваться для масштабирования предварительной обработки на произвольно большие наборы данных. Предварительно обработанные данные можно кэшировать в удаленной системе хранения объектов, например Amazon S3 и Google GCS, в виде разбитого на разделы набора данных Parquet. Этот кэшированный набор данных может быть повторно использован в ходе нескольких этапов обучения при помощи одних и тех же входных и выходных признаков, но разных конфигураций обучения.
Во время обучения всегда будет использоваться GPU, если он доступен по умолчанию. Если кластер Ray содержит несколько узлов, Ludwig автоматически масштабирует обучение на то количество GPU, которое доступно в кластере, используя Horovod на Ray. Ludwig на Ray также использует недавно выпущенный API Ray Datasets для эффективного параллелизма конвейера поглощения данных (включая полное перемешивание по периодам) и обучения, распределяя перемешивание и пакетирование данных по узлам кластера, не использующим GPU.
Наконец, если вы применяете кластер с автоматическим масштабированием или многопользовательский кластер, то можете запросить точное количество воркеров и GPU для использования во время распределенного обучения. Ludwig + Ray будет автоматически масштабироваться до запрашиваемого количества ресурсов:
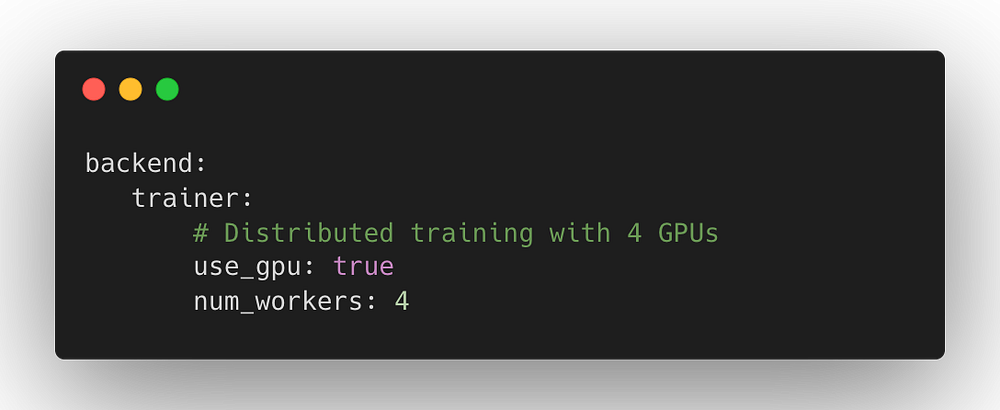
Хотя все в Ludwig на Ray можно запускать без дополнительной настройки, используя разумные значения по умолчанию, декларативная структура обеспечивает полный контроль для пользователей, которые хотят дополнительно оптимизировать инфраструктуру МО для обучения. Более подробную информацию можно найти в документации по конфигурации бэкенда Ludwig.
Простота внедрения в производство
Внедрение моделей машинного обучения в производство обычно представляет собой длительный и сложный процесс. Ludwig предоставляет несколько опций для упрощения процесса развертывания.
Благодаря Ludwig Serving, Ludwig обеспечивает простоту работы с моделями глубокого обучения, в том числе на GPU.
Используйте ludwig serve, чтобы запустить REST API для обученной модели Ludwig.
ludwig serve --model_path /path/to/model
curl http://0.0.0.0:8000/predict -X POST -F 'review=the movie was awesome'
Для высокоэффективных развертываний часто важно минимизировать потребление ресурсов, вызванное временем выполнения Python. Ludwig поддерживает экспорт моделей в эффективные пакеты Torschscript.
ludwig export_torchscript --model_path /path/to/model
Сравнение производительности Ludwig v0.4 и v0.5
Переход на использование PyTorch в качестве бэкенда Ludwig был продиктован повышением продуктивности разработки, отладки и итераций, предоставляемым API PyTorch и отличной экосистемой выстроенной сообществом PyTorch.
В то же время мы хотели убедиться в том, что пользователи Ludwig будут получать только лучший опыт. Мы провели большую аналитическую работу по сравнению Ludwig v0.5 (на базе PyTorch) и Ludwig v0.4 на текстовых, графических и табличных наборах данных. Нас интересовали оценки скорости обучения, скорости вывода и эффективности модели — мы хотели убедиться, что они не ухудшились.
Результаты показали примерно такой же высокий уровень использования GPU (~90%), но вместе с тем значительное улучшение в скорости распределенного обучения и использовании памяти без влияния на точность модели и время конвергенции. Для краткости мы приводим здесь только результаты, полученные на наборе данных DBpedia, но те же тенденции характерны для всех тестов.
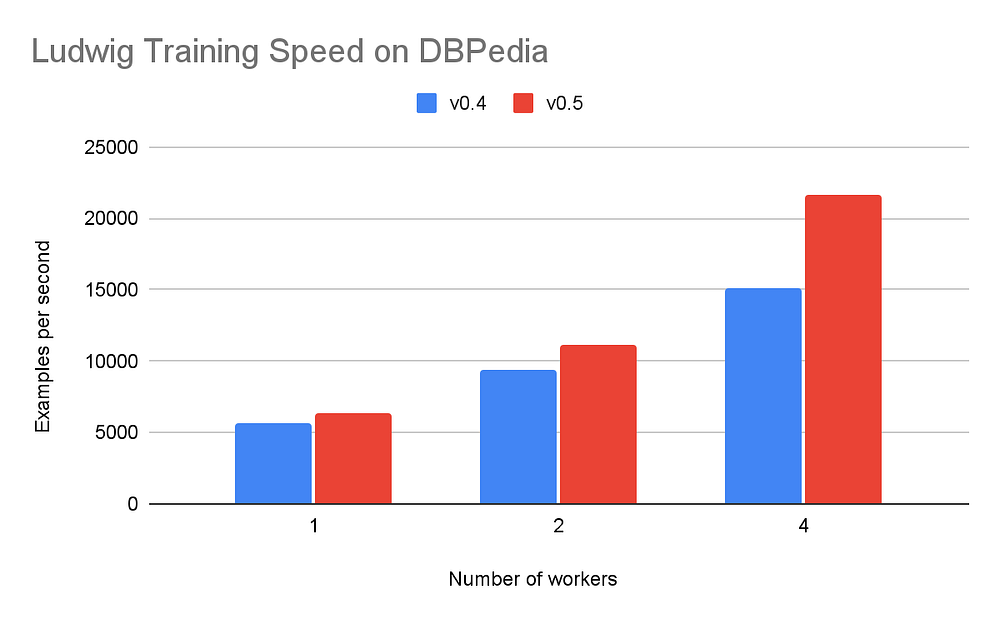
Используя Ludwig 0.5 на PyTorch, мы наблюдали очень быстрое время на период и общее время конвергенции модели. Эти различия становятся более выраженными по мере увеличения числа воркеров в условиях распределенного обучения с использованием T4 GPU.
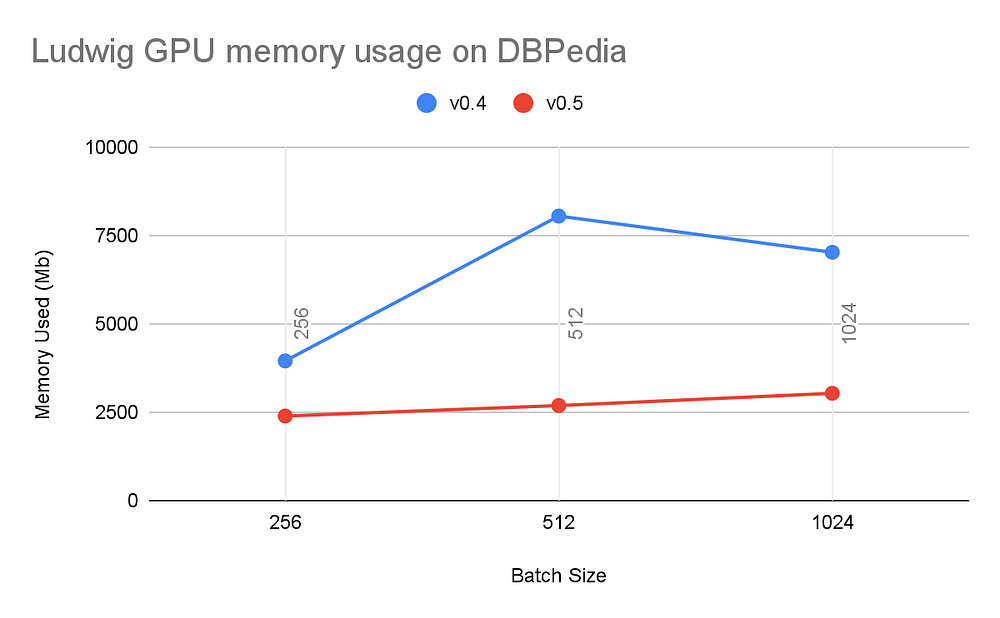
Мы также убедились в том, что перенос на PyTorch сохраняет точность модели и использование GPU как на одной машине, так и при распределенном обучении.
Что дальше?
После завершения основного перехода Ludwig на PyTorch мы переключимся на новые функции и начнем добавлять новые возможности, о которых просило сообщество.
У нас в разработке находится множество интересных функций, включая:
- автоматическое МО для большего количества задач;
- итеративное автоматическое МО;
- обучение посредством самообучения;
- хаб для моделей Ludwig.
Кроме того, мы работаем над созданием большего количества архитектур и предварительно обученных моделей, а также над повышением эффективности предварительной обработки.
Читайте также:
- 29 сниппетов Pytorch для ускорения цикла машинного обучения
- Руководство для начинающих исследователей данных
- Ускорение GPU в машинном обучении и больших данных
Читайте нас в Telegram, VK и Дзен
Перевод статьи Piero Molino: Ludwig on PyTorch





