
Прежде чем перейти непосредственно к теме, хочу дать определение бессерверных вычислений. Бессерверные вычисления — это модель, в рамках которой такая инфраструктура, как серверы и лежащее в их основе программное обеспечение, принадлежит облачным вычислительным платформам и управляется ими. Организации или частные лица могут арендовать инфраструктуру на столько времени, на сколько пожелают. Следует помнить, что у каждого арендуемого ресурса есть дополнительные ограничения.
По сути, аренда инфраструктуры означает владение кодом, который мы хотим запустить. При этом нам не нужно заморачиваться о покупке компьютера, на котором этот код должен выполняться.
Такая модель имеет ряд преимуществ:
- Мы платим только за те ресурсы, которые используем. Например, если у нас есть большой объем кода, для выполнения которого на очень мощном компьютере требуется 10 секунд, нам не нужно резервировать или покупать этот компьютер на целый день, месяц или год. Мы можем просто заплатить за те 10 секунд, в течение которых наш код фактически работал на этом устройстве.
- На каждом компьютере есть программное обеспечение, например, операционная система. Обычно организации сами управляют обновлением ПО, следовательно, они должны нанимать системного администратора для настройки, управления и обновления системы. Это не только стоит денег, но и, что более важно, отнимает много времени. Однако бессерверная структура предусматривает передачу этих задач облачным платформам.
- В последнее время технологическая отрасль переходит на архитектуру микросервисов. Это означает, что вместо монолитной кодовой базы, состоящей из тысяч строк многоцелевого кода, функции распределяются в виде микросервисов, причем каждый из них является независимым и служит для выполнения одной или нескольких задач. Такая модель довольно устойчива: например, если один сервис выходит из строя или дает сбой, это никак не отражается на приложении в целом. Бессерверные вычисления очень хорошо вписываются в эту схему: мы располагаем множеством ресурсов, которые мы используем для связи друг с другом, но в то же время они не зависят друг от друга. Этот метод также называется разделением приложения.
- Наконец, с помощью бессерверной архитектуры у нас есть возможность увеличивать или уменьшать количество запросов, которые обслуживает наше приложение. Это означает, что система сможет обслужить миллионы пользователей, которые заходят на сайт, без существенной задержки. Происходит это благодаря горизонтальному масштабированию, т. е. выделению большего количества ресурсов для обслуживания большего количества запросов.
Учитывая все вышеперечисленные моменты, лично я предпочитаю использовать эту архитектуру там, где это возможно.
Итак, перед нами стоит следующая задача, требующая решения: нам нужен конвейер, собирающий данные с сайта нашей организации и хранит их либо в базе данных, либо в файловой системе, которая является простой в использовании и надежной в управлении.
Для демонстрационных целей будем использовать специальный веб-сайт, куда можно поместить наши файлы данных и конвейеры. Задача конвейера состоит в том, чтобы обнаруживать любое изменение состояния нашего источника данных и запускать серию событий для сохранения файла в озере данных.
Если выполняются определенные условия, т.е. если файл содержит информацию о пользователе, конвейер также будет запускать серию событий для сохранения данных в базе.
Код приложения:
https://github.com/VachanAnand/ML-Ops-pipeline-AWS.git
Схема архитектуры:
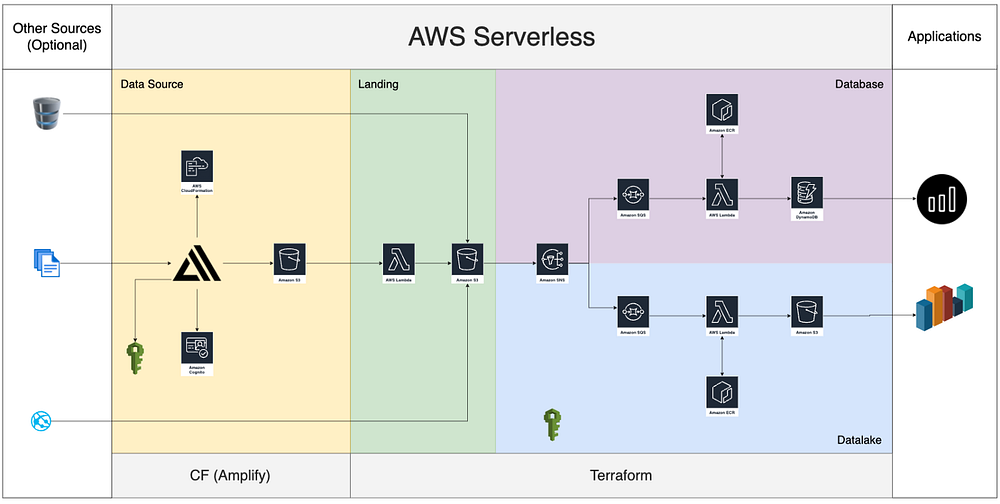
Эту модель-решение можно разделить на 5 уровней или зон:
- Уровень источников данных. В левой части схемы на светло-оранжевом фоне располагаются источники данных. Здесь генерируются данные. В нашем случае они генерируются с веб-сайта, который мы создали с помощью Amplify.
- Посадочный уровень. В середине схемы на зеленом фоне мы видим посадочную зону. Сюда “приземляются” данные из различных источников. Это так называемые “сырые”, т.е. необработанные данные из различных систем-источников.
- База данных / Структурированный уровень. В правом верхнем углу на фиолетовом фоне виден слой базы данных. Здесь структурированные данные попадают в базу данных.
- Озеро данных / Неструктурированный уровень. В правом нижнем углу на голубом фоне находится слой озера данных. Здесь данные из различных источников хранятся в виде файлов (это решение удачно с точки зрения управления).
- Уровень приложения. В крайнем правом углу белым цветом выделен уровень приложения. Он потребляет данные из базы данных или озера данных для создания бизнес-ценностей.
В приведенной выше схеме архитектуры мы используем следующие технологии:
- Amplify;
- Cognito;
- Cloud Formation;
- веб-служба Simple Storage Solution (S3);
- лямбда-функции;
- сервис посылки уведомлений Simple Notification Service (S.N.S);
- сервис принятия очереди сообщений для хранения Simple Queue Service (S.Q.S);
- реестр Elastic-контейнеров;
- Dynamo DB;
- управление доступом к идентификационным данным (I.A.M.).
Дополнительно используются также Docker и Terraform.
Теперь разберемся, что делает каждая из упомянутых выше технологий и как она используется в нашем конвейере данных. Начнем слева направо — в этом же направлении идет поток данных в рассматриваемом нами решении.
Amplify
Amplify — это сервис, который помогает легко создавать фулстек приложения. В целях демонстрации мы будем использовать его для репликации источника данных. Мы создадим интерфейс, и пользователь сможет поместить туда файл, который будет принят нашим конвейером данных.
Подготовленный нами интерфейс выглядит следующим образом
Там предусмотрена кнопка, с помощью которой можно выбрать файл на локальном компьютере и добавить его в конвейер.
Cognito
Cognito — это сервис, который используется для настройки и предоставления пользователям доступа к приложению. Мы используем Cognito для аутентификации пользователей перед предоставлением им доступа к нашему сайту.
Cloud Formation
Cloud Formation — это сервис, предоставляющий инфраструктуру в виде кода. Подробнее об этом пойдет речь, когда мы будем говорить о Terraform, еще одном инструменте для подачи инфраструктуры в виде кода, который не является AWS-сервисом.
В нашей демонстрационной модели мы не создаем ресурсы с помощью Cloud Formation. Однако мы используем сервис Amplify, который генерирует множество ресурсов, задействуя шаблоны Cloud Formation.
Веб-служба Simple Storage Service (S3)
Simple Storage Service — это высокомасштабируемое, доступное и надежное облачное решение для хранения данных на AWS. В самом простом виде оно представляет собой файловую систему в облаке. В рамках системы S3 используются специальные корзины. Это своеобразные каталоги, в которых хранятся данные.
Мы широко используем S3 в нашей демонстрационной модели. Это решение применяется для обеспечения работы:
- уровня источника данных (там хранятся данные для нашего фулстек приложения);
- посадочного уровня (поступление данных из различных источников данных в одно место);
- уровня озера данных (хранение файла в хорошо управляемом месте, куда обеспечен легкий доступ).
Кроме того, технология S3 снабжена крайне полезной функцией Event Based Notification. Она оказывается полезной при направлении ресурсу уведомления (сообщения) на основе определенного условия. Мы используем эту функцию для направления сообщения сервисам, таким как лямбда-функции или S.N.S., чтобы сообщить этим сервисам о попадании файла данных в источник данных. Такие уведомления работают как триггер, воздействующий на конвейер и побуждающий его приступать к обработке новых данных.
Лямбда-функции
Лямбда-функция в AWS — это сервис бессерверных вычислений. Это процессорный ресурс в облаке, на котором работает наше бэкенд-приложение / код конвейера данных. Мы также широко используем лямбда-функцию в нашей демонстрационной модели. Она применяется на следующих уровнях:
- посадочном (для получения данных из источника данных и хранения их в посадочной корзине);
- на уровне базы данных (для получения данных из посадочной корзины и хранения их в базе данных);
- на уровне озера данных (для получения данных из посадочной корзины и хранения их в управляемом озере данных S3).
Сервис посылки уведомлений Simple Notification Service (S.N.S)
Simple Notification Service, как следует из названия, является сервисом обмена сообщениями. Она получает сообщение от отправителя (т. е. ресурса, от которого оно исходит) и доставляет это сообщение ряду потребителей (т. е. ресурсу / ресурсам, для которых оно предназначено).
Мы используем S.N.S на посадочном уровне для получения сообщения от S3 о том, что файл попал в корзину, и доставки этого сообщения нескольким потребителям — базе данных и озеру данных; после этого начинается обработка файла.
Сервис принятия очереди сообщений для хранения Simple Queue Service (S.Q.S)
Это сервис похож на технологию S.N.S, описанную выше. Его цель — доставить сообщение от отправителя к получателю, однако в отличие от S.N.S здесь есть только один получатель.
Назначением S.Q.S является разделение ресурсов в микросервисной архитектуре. Тандем S.N.S + S.Q.S образует архитектуру разветвления, которая очень эффективна в плане повышения надежности решения.
Мы используем S.Q.S в следующих случаях:
- на уровне базы данных (для доставки сообщения лямбда-функции и вызова загрузки данных в базу данных);
- на уровне озера данных (для доставки сообщения лямбда-функции и вызова загрузки данных в озеро данных).
Реестр Elastic-контейнеров (E.C.R.)
E.C.R — это полностью управляемый реестр контейнеров в AWS. Контейнер представляет собой легкий, автономный, исполняемый пакет для запуска приложения. Концептуально он напоминает транспортный контейнер, в котором хранится груз (в нашем случае код). Груз можно перевозить на разных машинах, точно так же и код можно запускать на разных компьютерах.
Мы используем E.C.R для хранения кода, используемого нашими лямбда-функциями в озере данных и на уровне базы данных.

Dynamo DB
Dynamo DB — это высокопроизводительная база данных NoSQL в AWS. Она хранит данные в виде пары ключ-значение. В отличие от традиционной базы данных SQL, Dynamo DB не обязательно должна соответствовать табличной структуре, поэтому каждая запись в базе данных может иметь разное количество столбцов.
Хотя DynamoDB и является базой данных NoSQL, в нашей демонстрационной модели мы храним хорошо структурированные данные.
Управление доступом к идентификационным данным (I.A.M.)
I.A.M, на мой взгляд, является основой AWS. Эта технология используется для предоставления доступа пользователям, чтобы они могли выполнять определенные задачи. В контексте множества различных ресурсов система I.A.M применяется для предоставления разрешений каждому ресурсу; таким образом они могут получать доступ к другим нужным ресурсам и взаимодействовать с ними.
Docker
Контейнер Docker — это технология, которая используется для сборки кода приложения в виде легкого, автономного и исполняемого пакета. Контейнеры довольно эффективны при создания масштабируемых продуктов и широко используются в Kubernetes.
Мы используем контейнеры Docker при передаче образов контейнеров лямбда-функции и хранения их в Amazon E.C.R.
Terraform
В нашей демонстрационной модели нам пришлось создать в совокупности 11 ресурсов на посадочном уровне, уровнях базы данных и озера данных. Каждому ресурсу мы должны были назначить роль I.A.M. К каждой роли следовало прикрепить политику I.A.M. В нашей демо-версии мы использовали минимальное количество ресурсов, но при этом нам пришлось задействовать большое количество сервисов. Подготовку каждого сервиса к работе можно было выполнять вручную через консоль.
Но если бы речь шла о реальном решении, нам пришлось бы использовать сотни ресурсов. Более того, обычно архитектура реплицируется в различных средах, таких как dev (разработка), test (тестирование) и production (производство). Управлять всеми этими ресурсами через консоль довольно сложно и в какой-то степени неэффективно.
Чтобы решить эту проблему, мы используем инфраструктуру как код, т. е. создаем эти ресурсы с помощью кода, что упрощает управление, поддержку и репликацию ресурсов в различных средах.
Код приложения:
https://github.com/VachanAnand/ML-Ops-pipeline-AWS.git
Читайте также:
- Обработка событий по времени в бессерверной архитектуре
- Добавление личного домена в AWS WebSocket
- Развертывание Cloud Functions в GCP с помощью Terraform
Читайте нас в Telegram, VK и Дзен
Перевод статьи Vachan Anand, Introduction to Data Pipeline with Serverless Architecture





