
С большими наборами данных работать сложно, особенно при отсутствии необходимых ресурсов. У большинства из нас нет доступа к распределенному кластеру, GPU-установкам или более 8 ГБ оперативной памяти. Это не значит, что мы не можем работать с большими данными. Просто нужно обрабатывать их по одному фрагменту за раз, то есть при итерации полного набора данных работать с отдельно с каждым подмножеством.
Набор данных
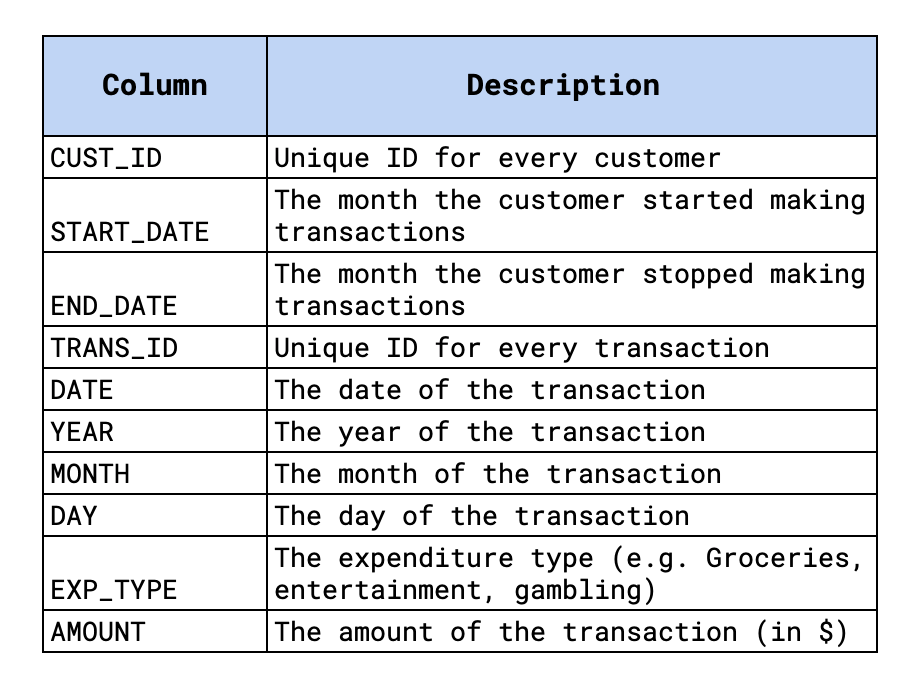
Посмотрим, как это можно сделать на примере большого набора данных о транзакциях (генерируемого случайным образом). Набор данных содержит более 260 миллионов транзакций для 75 000 клиентов. Транзакции охватывают период с 2010-го по 2020 год. Каждая транзакция связана с одним из 12 типов расходов (например, бакалея). Более подробная информация отражена на рисунке 1, а полный набор данных представлен на Kaggle. Кроме того, можно найти ноутбук для этого руководства на GitHub.
Наша задача — использовать пакетную обработку для создания различных агрегаций этих данных. В частности, необходимо вычислить:
- общее количество транзакций;
- общие годовые расходы;
- среднемесячные расходы на развлечения в 2020 году
В конце обсудим способы ускорения процесса создания этих агрегаций.
Пакетная обработка
Для выполнения поставленной задачи понадобятся стандартные пакеты Python. Необходимо также установить NumPy и Pandas для работы с данными и matplotlib для простой визуализации.
#импортирование
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
Для начала попробуем загрузить весь набор данных с помощью Pandas. Через некоторое время получим сообщение об ошибке (рис. 2). Имея всего 8 ГБ оперативной памяти, невозможно загрузить весь набор данных.
df = pd.read_csv('../data/transactions.csv')
Чтобы обойти эту проблему, придется загружать отдельные подмножества из большого набора данных. Для этого будем использовать параметры skiprows и nrows в функции read_csv. Ниже показано, что значения этих параметров установлены на 1000 и 2000 соответственно. Это означает, что необходимо пропустить первые 1000 строк CSV и загрузить следующие 2000 строк. Потребуется также передать имена столбцов в качестве параметров из-за пропуска первых строк имен в CSV.
names = ['CUST_ID', 'START_DATE', 'END_DATE', 'TRANS_ID', 'DATE', 'YEAR',
'MONTH', 'DAY', 'EXP_TYPE', 'AMOUNT']
#Load rows 1001 to 3000
df = pd.read_csv('../data/transactions.csv',
skiprows=1000,
nrows=2000,
names=names)
Можем использовать эти параметры для итерирования набора данных. Для этого создадим функцию get_rows, приведенную ниже. Она будет возвращать подмножества набора данных. Каждое подмножество будет содержать количество строк, определяемое параметром step. Параметр count будет изменяться при возврате очередного подмножества на каждом шаге. Чтобы понять, как использовать эту функцию, подсчитаем общее количество транзакций в наборе данных.
def get_rows(steps,count,names,path='../Data/transactions.csv'):
"""
Возвращает подмножество строк из CSV. Первые [шаги]*[счетчик]
строки пропускаются, а следующие [шаги] строки возвращаются.
параметры
------------
шаги (steps): количество возвращенных строк
счетчик (count): переменная count обновляется каждую
итерацию
имена (names): имена столбцов набора данных
путь (path): расположение csv
"""
if count ==0:
df = pd.read_csv(path,
nrows=steps)
else:
df = pd.read_csv(path,
skiprows=steps*count,
nrows=steps,
names=names)
return df
Подсчет количества транзакций
Функция get_rows будет использоваться в цикле while. В конце каждой итерации цикла будем обновлять счетчик, загружая новое подмножество набора данных. Количество шагов устанавливаем таким образом, чтобы каждый раз возвращалось 5 миллионов строк. Однако количество строк в наборе данных не кратно 5 миллионам. Это означает, что на последней итерации возвращается менее 5 миллионов строк. Будем использовать это для завершения цикла while.
steps = 5000000
names = ['CUST_ID', 'START_DATE', 'END_DATE', 'TRANS_ID', 'DATE', 'YEAR',
'MONTH', 'DAY', 'EXP_TYPE', 'AMOUNT']
#Инициализация количества транзакций
n = 0
#Инициализация count
count = 0
while True:
#Возврат подраздела набора данных
df = get_rows(steps,count,names)
#Обновление количества транзакций
n+=len(df)
#Обновление count
count+=1
#Выход из цикла
if len(df)!=steps:
break
#Выходное количество строк
print(n)
Для каждой итерации вычисляем длину подмножества и прибавляем ее к общему количеству транзакций. В итоге приходим к выводу, что существует 261 969 720 транзакций. Представление о том, как обрабатывать набор данных пакетно, позволит вам перейти к более сложным агрегациям.
Общие годовые расходы
Для данной агрегации нужно сложить все суммы транзакций за каждый год. Будем следовать процессу, аналогичному предыдущему. Теперь для каждой итерации необходимо обновлять итоговую сумму для каждого года в наборе данных. Создадим серию pandas, где индексом будет год, а значениями — общие суммы расходов. Начнем с суммарных расходов, равных 0 для каждого года.
При каждой итерации складываем суммы расходов по годам. В результате получается еще одна серия, exp, с тем же индексом, что и total_exp. Это позволяет перебирать данные за каждый год и обновлять итоговые значения.
#Инициализация годовых итогов
total_exp = pd.Series([0.0]*11, index=range(2010,2021))
count = 0
while True:
df = get_rows(steps,count,names)
#Получение годовых итогов по подразделу
exp = df.groupby(['YEAR'])['AMOUNT'].sum()
#Проход по периоду с 2010 до 2020 гг.
for year in range(2010,2021):
#Update yearly totals
total_exp[year] += exp[year]
count+=1
#Выход из цикла
if len(df)!=steps:
break
Визуализируем эту агрегацию с помощью приведенного ниже кода. Результат показан на рисунке 3: за исключением 2020 года, общие расходы стабильно растут из года в год. Для этой агрегации все вычисления выполняются в цикле while (как выяснится при следующем агрегировании, это не всегда так).
#Агрегирование графика
plt.figure(figsize=(10, 5))
plt.plot(total_exp.index,total_exp/1000000000)
plt.ylabel('Total expenditure ($ billion)',size=15)
plt.xlabel('Year',size=15)
plt.ylim(bottom=0)

Среднемесячные расходы на развлечения в 2020 году
Для большинства агрегаций данных недостаточно просто суммировать объемы транзакций. Для этой агрегации сначала нужно рассчитать общую сумму, потраченную на развлечения каждым клиентом в каждом месяце. Затем для каждого месяца можно будет рассчитать среднее значение по всем клиентам.
Для начала создадим пустой датафрейм pandas. Для каждой итерации отбираем только транзакции, связанные с развлечениями в 2020 году. Затем сложим суммы по клиентам и месяцам и добавим полученную таблицу к total_exp. В результате данные по клиентам и месяцам могут повторяться. Это связано с тем, что не все транзакции клиентов обязательно будут охвачены в течение одной итерации. Поэтому снова агрегируем таблицу.
#Создание пустого датафрейма с данными об общих расходах
total_exp = pd.DataFrame(columns=['CUST_ID','MONTH','AMOUNT'])
count = 0
while True:
df = get_rows(steps,count,names)
#Подсчет итоговых показателей за месяц для каждого клиента
df_2020 = df[(df.YEAR==2020) & (df.EXP_TYPE=='Entertainment')]
sum_exp = df_2020.groupby(['CUST_ID','MONTH'],as_index=False)['AMOUNT'].sum()
#Сложение ежемесячных итогов
total_exp = total_exp.append(sum_exp)
#Повторная агрегация для придания CUST_ID и MONTH уникальности
total_exp = total_exp.groupby(['CUST_ID','MONTH'],as_index=False)['AMOUNT'].sum()
count+=1
#Выход из цикла
if len(df)!=steps:
break
#Финальные агрегации
avg_exp = total_exp.groupby(['MONTH'])['AMOUNT'].mean()
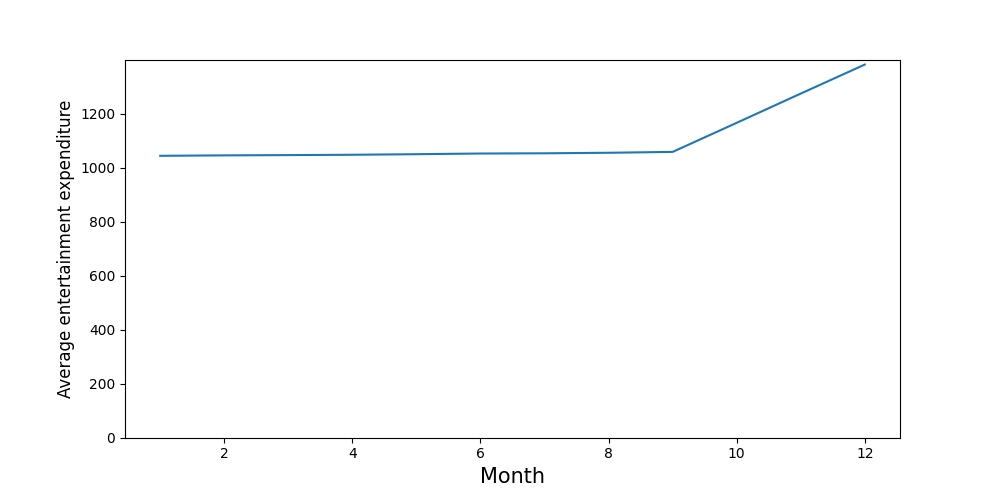
Теперь получаем таблицу с ежемесячными итогами по каждому клиенту. Последний шаг — вычисление средней суммы за каждый месяц. Динамика этого показателя отражена на рисунке 4: в начале года значения средней суммы стабильны, а затем увеличивается в октябре, ноябре и декабре.
Ничего, кроме времени
Итак, даже при ограниченных ресурсах можно проанализировать большой набор данных. Самой главной проблемой являются временные затраты, необходимые для выполнения каждого подмножества. Для работы с одним из них может понадобиться около 50 минут! Поэтому так важно попытаться максимально ускорить процесс.
Больше всего времени занимает загрузка строк с помощью функции get_rows. Она загружает данные из CSV на жестком диске в память/ОЗУ. Чтобы сократить время загрузки, вместо того, чтобы использовать несколько циклов while, попробуйте выполнить много агрегаций в одном цикле. Таким образом, вам нужно будет только один раз считывать данные с диска.
Читайте также:
- Эффективное итерирование по строкам в Pandas DataFrame
- Как создать хранилище данных за 5 шагов
- 6 функций Pandas для быстрого эксплораторного анализа данных
Читайте нас в Telegram, VK и Дзен
Перевод статьи Conor O’Sullivan, Batch Processing 22GB of Transaction Data with Pandas




