
Самым важным компонентом проекта или продукта в области науки о данных являются данные. Чем они понятнее, тем точнее и надежнее конечный продукт. Именно по этой причине значительная часть времени в проекте тратится на их очистку и эксплораторный анализ.
Pandas — одна из наиболее широко используемых библиотек для анализа и манипулирования данными. Она предоставляет богатый выбор функций, помогающих их исследовать.
Степень детализации процесса эксплораторного анализа данных определяется его задачами. Выбор метода исследования данных зависит от их динамики. Однако в большинстве случаев выполняются определенные фундаментальные операции.
В этой статье мы рассмотрим 6 функций Pandas для быстрого эксплораторного анализа данных. Для этого воспользуемся датасетом продаж, наполненный имитационными данными.
Начнем с создания датафрейма Pandas из этого набора данных.
import pandas as pd
sales = pd.read_csv("sales.csv")
sales.head()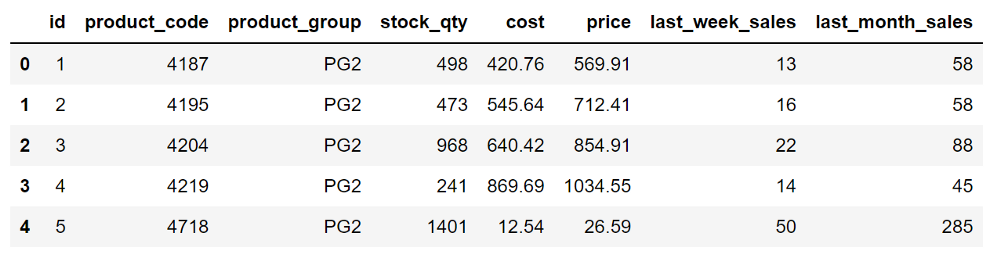
Набор данных содержит информацию о запасах, затратах, ценах и продажах товаров в розничном магазине.
1. Shape
Метод shape возвращает кортеж, показывающий количество строк и столбцов в датафрейме.
sales.shape
(1000, 8)Датафрейм продаж включает 1000 строк и 8 столбцов. В Pandas также есть метод size, который возвращает общее количество ячеек (т. е. количество строк, умноженное на количество столбцов).
sales.size
80002. Dtypes
Важно использовать типы данных, соответствующие каждому столбцу, по трем основным причинам.
- Некоторые функции и методы более эффективно работают с определенными типами данных.
- Некоторые функции и методы могут быть использованы только для определенных типов данных.
- Некоторые типы данных потребляют больше памяти, чем необходимо.
Метод dtypes возвращает тип данных каждого столбца.
sales.dtypes
id int64
product_code int64
product_group object
stock_qty int64
cost float64
price float64
last_week_sales int64
last_month_sales int64
dtype: objectЕсли столбец не имеет соответствующего типа данных, можно изменить его с помощью функции astype.
3. Isna
Существует множество причин отсутствия значений в данных, например некорректный ввод, ошибки при их преобразовании или просто их отсутствие.
Какой бы ни была причина, перед обработкой проекта необходимо сначала обработать отсутствующие значения. Способ их обработки зависит от характеристик данных и задачи. Однако в любом случае первым шагом будет проверка наличия в данных пропущенных значений.
Функция isna проверяет каждую ячейку и возвращает True для ячеек с отсутствующим значением. Необработанный результат функции isna не очень полезен для получения общего представления о данных с учетом пропущенных значений.
Можно использовать функцию isna вместе с sum, чтобы увидеть количество пропущенных значений в каждом столбце.
sales.isna().sum()
id 0
product_code 0
product_group 0
stock_qty 0
cost 0
price 0
last_week_sales 0
last_month_sales 0
dtype: int64Если изменить значение параметра axis функции sum на 1, получим количество отсутствующих значений в каждой строке.
sales.isna().sum(axis=1)
0 0
1 0
2 0
3 0
4 0
..
995 0
996 0
997 0
998 0
999 0
Length: 1000, dtype: int644. Describe
Функция describe оценивает столбцы с числовым типом данных (int или float) и возвращает статистические данные, которые дают представление о распределении значений.
sales.describe().round(2)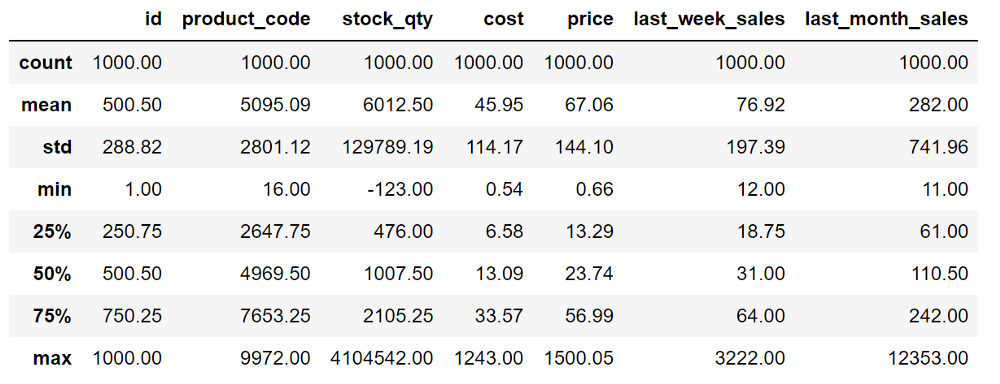
Здесь также использована функция round, чтобы придать выводу более привлекательный вид.
Мы можем игнорировать столбцы id (идентификатор) и product code (код продукта), потому что они не имеют количественных значений. Это просто цифры для идентификации продуктов.
Для тех, кто не знаком с приведенными выше статистическими показателями, расшифруем их значения.
- Count — количество значений.
- Mean — среднее значение.
- Std — стандартное отклонение значения.
- Min — минимальное значение.
- Max — максимальное значение.
- 25% — первый квартиль, означающий, что 25% значений в столбце ниже этого значения.
- 50% — медиана, означающая, что половина значений в столбце ниже этого значения.
- 75% — третий квартиль, означающий, что 75% значений в столбце ниже этого значения.
Эти показатели помогают понять, как распределены значения в столбце. Они также позволяют увидеть, есть ли в столбце какие-либо выбросы. Например, максимальное значение в столбце stock quantity (количество запасов) явно является выбросом.
5. Value_counts
Функция value_counts позволяет проверить распределение категориальных столбцов. Она возвращает различные значения в столбце вместе с количеством их вхождений.
sales["product_group"].value_counts()
PG4 349
PG5 255
PG6 243
PG2 75
PG3 39
PG1 39
Name: product_group, dtype: int64Результаты упорядочены по количеству вхождений, что также полезно.
Кроме того, можно узнать процентную долю каждого значения с помощью параметра normalize.
sales["product_group"].value_counts(normalize=True)
PG4 0.349
PG5 0.255
PG6 0.243
PG2 0.075
PG3 0.039
PG1 0.039
Name: product_group, dtype: float6434,9% значений относятся к PG4.
Функция value_counts по умолчанию игнорирует отсутствующие значения. Если вам нужно также видеть количество отсутствующих значений, просто установите параметр dropna на False.
6. Groupby
Функция groupby помогает получить общее представление о данных и выявить взаимосвязи между переменными.
На следующем изображении показано, что делает функция groupby.
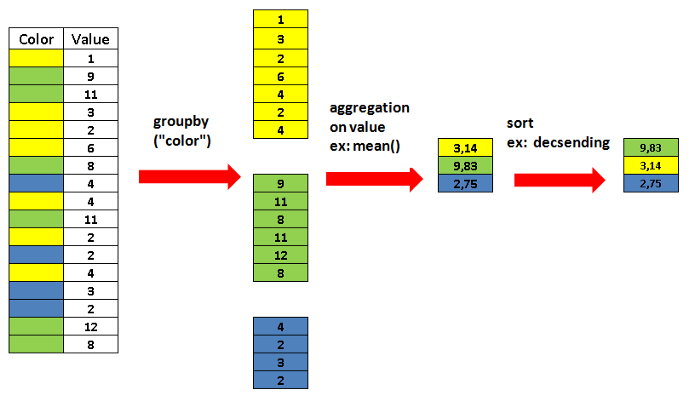
Строки группируются в соответствии со значениями в столбце, используемом для группировки. Можно также рассчитать агрегированные значения, такие как среднее значение, сумма и прочие.
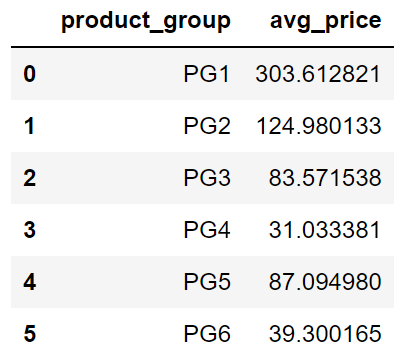
Например, можно определить среднюю цену для каждой группы продуктов следующим образом:
sales.groupby("product_group", as_index=False).agg(
avg_price = ("price","mean")
)
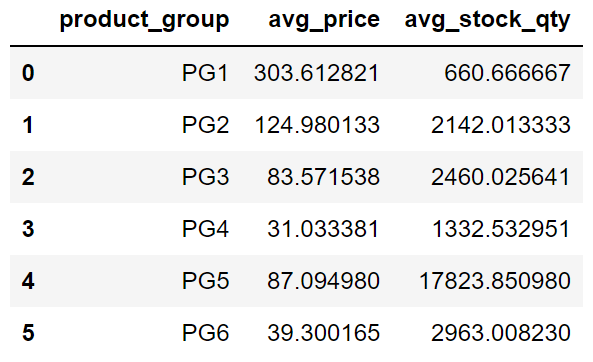
Можно также вычислить агрегированные значения по нескольким столбцам:
sales.groupby("product_group", as_index=False).agg(
avg_price = ("price","mean"),
avg_stock_qty = ("stock_qty","mean")
)
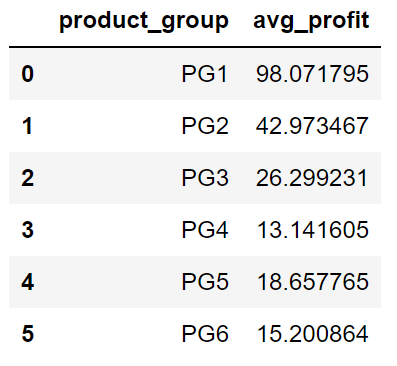
Возможности не ограничиваются использованием встроенных агрегирующих функций, таких как среднее значение и сумма. Можете вычислять более конкретные агрегации с помощью функции apply.
В следующем фрагменте кода используется лямбда-функция, которая вычисляет среднюю прибыль для каждой группы товаров.
sales.groupby("product_group", as_index=False).apply(
lambda x: pd.Series((x.price - x.cost).mean(),
index=["avg_profit"])
)
Заключение
Процесс эксплораторного анализа данных обычно гораздо более подробный по сравнению с описанным в этой статье. Однако приведенные 6 функций дают общее представление и могут быть использованы в качестве основы для любого анализа.
Читайте также:
- От Pandas к Pyspark
- Качество превыше количества: создание идеального проекта в науке о данных
- Alteryx - достойная платформа обработки данных?
Читайте нас в Telegram, VK и Дзен
Перевод статьи Soner Yıldırım: 6 Pandas Functions for a Quick Exploratory Data Analysis





