
На какую же задачу дата-сайентисты тратят больше всего времени? Согласно исследованию CrowdFlower, они тратят 80% своего времени на очистку данных. Это неудивительно, ведь от того, насколько чистыми будут данные, зависит судьба всего проекта.
Существуют методы, позволяющие сократить время очистки данных за счет использования специальных пакетов. Что это за пакеты и как они работают? Давайте разбираться.
1. Pyjanitor
Pyjanitor — это реализация пакета Janitor R для очистки данных с помощью цепочечных методов в среде Python. Пакет прост в использовании благодаря интуитивно понятному API, подключенному непосредственно к пакету Pandas.
Исторически сложилось так, что Pandas уже предусматривает множество полезных функций очистки данных, таких как dropnaдля избавления от нулевых значений и to_dummiesдля категориального кодирования. Следует заметит, что Pyjanitor расширяет возможности “чистящего” API Pandas, а не заменяет его.
Как работает Pyjanitor? Попробуем применить Pyjanitor в нашем процессе очистки данных.
В качестве примера проекта я использовал набор данных Coffee meet Bagel review с сайта Kaggle:
import pandas as pd
review = pd.read_csv('data_review.csv')
review.info()
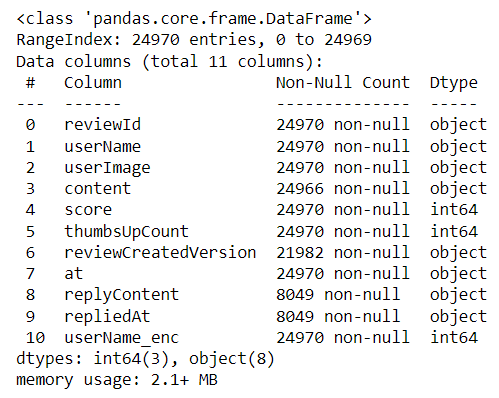
В нашем наборе данных есть 11 столбцов с объектными и числовыми данными. На первый взгляд кажется, что некоторые данные отсутствуют, а названия столбцов не стандартизированы. Давайте попробуем очистить набор данных с помощью Pandas и Pyjanitor.
Прежде чем начать, нам нужно установить пакет Pyjanitor:
pip install pyjanitor
После завершения установки нам остается только импортировать пакет, и API-функция сразу становится доступной через API Pandas. Попробуем использовать пакет Pyjanitor с нашим набором данных:
import janitor
jan_review = review.factorize_columns(column_names=["userName"]).expand_column(column_name = 'reviewCreatedVersion').clean_names()
В приведенном выше примере кода API Pyjanitor выполнил следующие действия:
- Факторизация столбца userName для преобразования категориальных данных в числовые (
factorize_columns). - Расширение столбца reviewCreatedVersion или процесс однократного кодирования (One-Hot Encoding) (
expand_column). - Очищение имен столбцов путем преобразования их в нижний регистр, а затем замены всех пробелов символами подчеркивания (
clean_names).
Выше приведен пример действий, которые мы можем выполнить с помощью Pyjanitor. У этого пакета есть еще множество полезных функций:
- очистка имен столбцов (доступны также мультииндексы);
- удаление пустых строк и столбцов;
- идентификация записей-дубликатов;
- категориальное кодирование столбцов;
- расщепление данных на фичи и цели (для машинного обучения);
- добавление, удаление и переименование столбцов;
- объединение нескольких столбцов в один;
- конвертирование даты (из matlab, excel, unix) в питоновский формат datetime;
- расширение столбца, имеющего ограничивающие категориальные значения, до фиктивно закодированных переменных;
- конкатенация и деконкатенация столбцов на основе разграничителя;
- синтаксический сахар для фильтрации датафрейма на основе запросов к столбцам;
- экспериментальные субмодули для таких областей, как финансы, биология, химия, проектирование; работа с pyspark.
Кроме того, цепочечный метод также работает с оригинальным API Pandas. Вы можете комбинировать оба метода для получения нужных вам чистых данных.
2. Klib
Klib — это пакет Python с открытым исходным кодом для импорта, очистки и анализа. Это универсальный пакет, используемый для легкого понимания данных и их предварительной обработки. Klib полезен для оценки данных, так как располагает функцией интуитивной визуализации и простыми в использовании API.
Поскольку в этой статье речь идет только об очистке данных, давайте сосредоточимся на API, предназначенном для этой цели.
При очистке данных Klib полагается на API data_cleaning для автоматической очистки датафрейма. Попробуем использовать API на примере нашего набора данных. Сначала нам нужно установить пакет:
pip install klib
После установки мы передадим набор данных API data_cleaning:
import klib
df_cleaned = klib.data_cleaning(review)
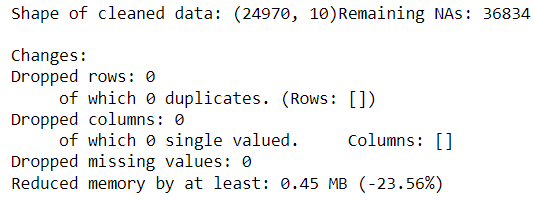
Приведенная выше функция выдает информацию об очистке данных, выполненной для нашего пробного датасета. Процедура Klib data_cleaningвыполняет следующие шаги:
- очистка имен столбцов;
- удаление пустых и практически пустых столбцов;
- удаление одиночных кардинальных столбцов.
- удаление дублирующихся строк;
- сокращение объема памяти.
3. DataPrep
DataPrep — это пакет Python, созданный для подготовки данных. В его основные задачи входит следующее:
- исследование данных;
- очистка данных;
- сбор данных.
Рассмотрим API очистки данных в DataPrep.
DataPrep cleaning предлагает более 140 API для очистки и проверки данных. Я покажу все доступные API в GIF (см. ниже).
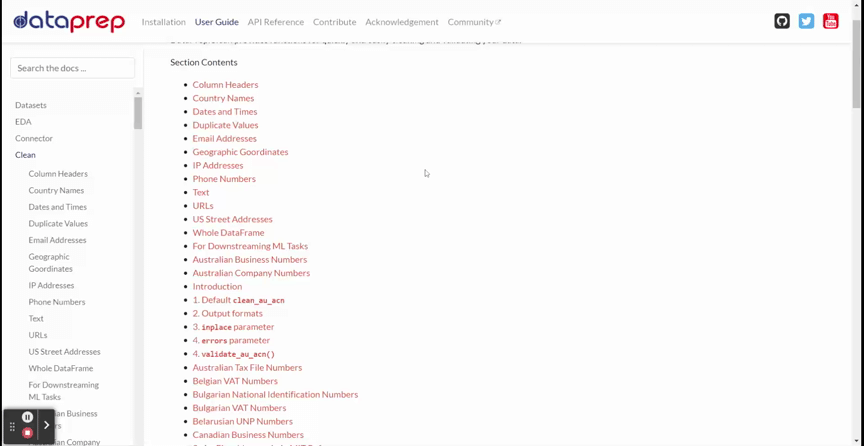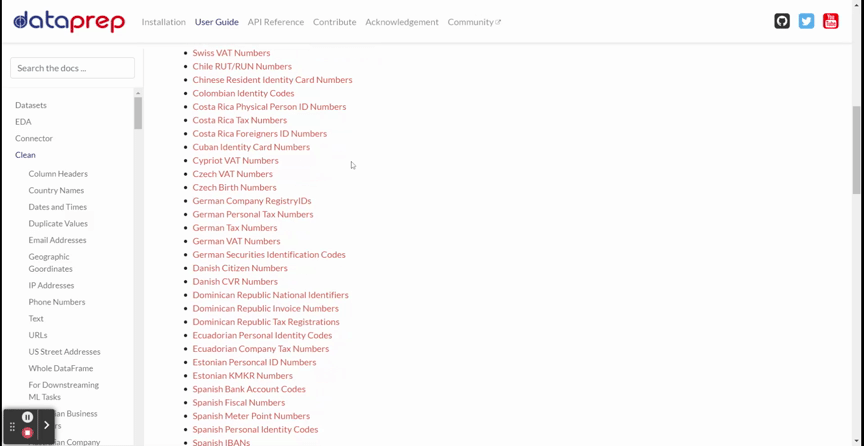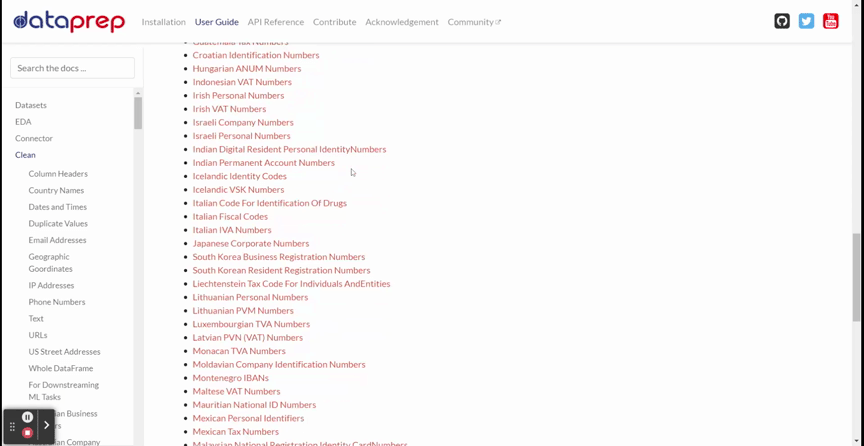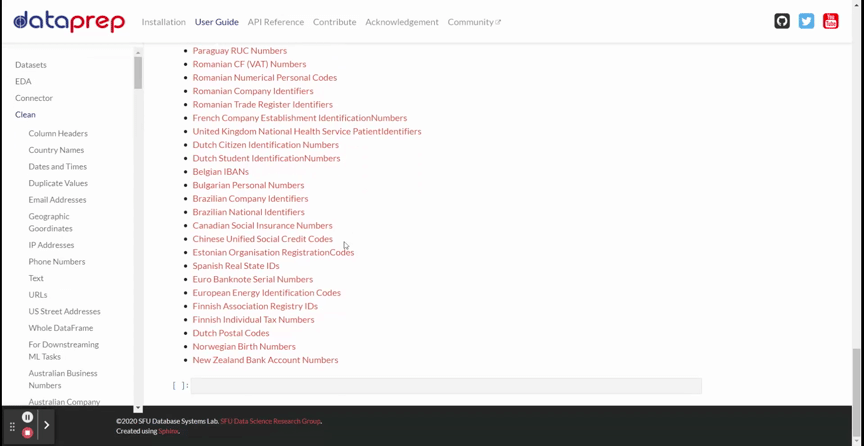
Из приведенного GIF видно, что инструмент располагает различными API, такими как Заголовки Столбцов, Названия Стран, Дата и Время и многими другие. Здесь есть все API, необходимые для очистки данных.
Если вы не уверены, что именно нужно очистить, вы всегда можете положиться на API clean_dfот DataPrep, который автоматически очищает данные и позволяет пакету определиться с тем, что вам нужно. Испытаем API на практике, чтобы узнать о нем больше.
Сначала нам нужно установить пакет DataPrep:
pip install dataprep
После установки пакета мы можем применить API clean_dfв отношении предыдущего пробного датасета:
from dataprep.clean import clean_df
inferred_dtypes, cleaned_df = clean_df(review)
API будет иметь два выхода — предполагаемый тип данных и очищенный датафрейм. Помимо этого, в процессе также будет создана сводка по очистке фрейма данных.

Из вышеуказанного отчета мы можем узнать о том, какие типы данных были обработаны, какие заголовки столбцов были очищены и насколько сократился объем памяти. Если вы считаете, что нужная степень очистки достигнута, можете использовать очищенный датафрейм для следующего шага. В противном случае используйте доступный API для дальнейшей очистки.
4. scrubadub
Scrubadub — это пакет Python с открытым исходным кодом для удаления персональной информации из текстовых данных. Scrubadub работает путем удаления обнаруженных персональных данных и замены их текстовым идентификатором, таким как {{EMAIL}} или {{NAME}}.
В настоящее время Scrubadub способен удалять следующие персональные данные:
- имя;
- адрес электронной почты;
- адрес/почтовый код (США, Великобритания, Канада);
- номер кредитной карточки;
- дату рождения;
- URL;
- номер телефона;
- комбинации “имя пользователя” — ”пароль”;
- имя пользователя в Скайпе/Твиттере;
- номер социального страхования (США и Великобритания);
- идентификационный номер налогоплательщика (Великобритания);
- номер водительского удостоверения (Великобритания).
Попробуем очистить наш набор данных с помощью Scrubadub. Сначала установим пакет:
pip install scrubadub
С помощью Scrubadub можно удалить различные персональные данные, например, имена и адреса электронной почты. Воспользуемся образцом данных, который содержит имя и адрес электронной почты:
review['replyContent'].loc[24947]

Данные содержат имя и электронную почту, которые мы хотели бы удалить. Используем для этого Scrubadub:
sample = review['replyContent'].loc[24947]
scrubadub.clean(sample)

Итак, в очищенных данных удален адрес электронной почты и заменен на идентификатор {{EMAIL}}. Но у нас все еще есть данные об имени. Как же Scrubadub может удалить имя?
Чтобы улучшить идентификатор имени Scrubadub, нам нужно добавить средства обнаружения имени из других пакетов. Для работы с нашим примером добавим детектор из TextBlob:.
scrubber = scrubadub.Scrubber()
scrubber.add_detector(scrubadub.detectors.TextBlobNameDetector)
scrubber.clean(sample)

Мы удалили имя и заменили его идентификатором {{NAME}}. Если хотите больше узнать о Scrubadub, изучите официальную документацию пакета.
Заключение
Очистка данных — это процесс, который занимает больше всего времени в работе исследователя данных. Есть множество пакетов Pyhton, разработанных специально для этой цели. Я описал лучшие из них:
- Pyjanitor;
- Klib;
- DataPrep;
- Scrubadub.
Надеюсь, статья была вам полезна!
Читайте также:
- Битва 4 инструментов визуализации данных на языке Python
- Python для Android: Как начать делать кроссплатформенные приложения с Kivy
- Введение в линейное программирование на Python
Читайте нас в Telegram, VK и Дзен
Перевод статьи Cornellius Yudha Wijaya, Top Data Cleaning Python Packages





