
Из этой статьи вы узнаете о способах извлечения текста из цифровых изображений с использованием python и библиотеки pytesseract. Изображение должно иметь текст внутри, чтобы получить выходной текст.
Для извлечения текста с помощью pytesseract необходимо установить библиотеки в среду системы. Приведенные ниже команды помогут установить необходимые библиотеки в системе.
Команда для установки библиотеки OpenCV:
pip install opencv-pythonКоманда для установки библиотеки pytesseract-ocr:
pip install pytesseractНеобходимо также установить конфигурационный файл tesseract, чтобы получить файл tesseract.exe по следующей ссылке:
https://github.com/UB-Mannheim/tesseract/wiki
Скачайте вышеуказанный файл в соответствии с конфигурацией системы, затем установите его. Файл tesseract.exe будет располагаться по следующему пути:
C:\Program Files\Tesseract-OCR\tesseract.exe"Посмотрим на входное изображение, из которого нужно извлечь текст:

На этом примере рассмотрим способ извлечения текста из полутонового изображения, а на следующем примере — из цветного изображения с ограничительной рамкой.
Извлечение текста из полутонового изображения
Для начала импортируем необходимые библиотеки:
from PIL import Image
from pytesseract import pytesseractТеперь будем использовать библиотеку pillow для открытия/чтения изображения:
image = Image.open('ocr.png')
image = image.resize((400,200))
image.save('sample.png')Примечания:
- Метод
openиспользуется для чтения изображения из рабочего каталога. - Метод
resizeиспользуется для изменения размера изображения. - Метод
saveиспользуется для сохранения изображения после изменения размера.
Определим путь к бинарному файлу tesseract, как показано ниже:
path_to_tesseract = r"C:\Program Files\Tesseract-OCR\tesseract.exe"
pytesseract.tesseract_cmd = path_to_tesseractПришло время использовать метод image_to_string класса tesseract для извлечения текста из изображения:
text = pytesseract.image_to_string(image)
#печать текста построчно
print(text[:-1])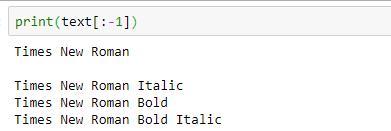
Обнаружение и извлечение текста из цветного изображения
На этот раз будем извлекать текст из цветного изображения. Образец цветного изображения показан ниже.

В этом примере будем использовать ограничительную рамку и другие методы OpenCV.
Установите необходимые библиотеки:
import cv2
from pytesseract import pytesseractТеперь определим путь к бинарному файлу tesseract, как показано ниже:
path_to_tesseract = r"C:\Program Files\Tesseract-OCR\tesseract.exe"
pytesseract.tesseract_cmd = path_to_tesseractЧтение изображения с помощью метода OpenCV:
img = cv2.imread("color_ocr.png")Преобразование цветного изображения в полутоновое для лучшей обработки текста:
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)Теперь преобразуем полутоновое изображение в бинарное, чтобы повысить вероятность извлечения текста:
ret, thresh1 = cv2.threshold(gray, 0, 255, cv2.THRESH_OTSU |
cv2.THRESH_BINARY_INV)
cv2.imwrite('threshold_image.jpg',thresh1)Здесь метод imwrite используется для сохранения изображения в рабочем каталоге.

Чтобы задать размер предложений или даже слов изображения, понадобится метод структурных элементов в OpenCV с размером ядра в зависимости от площади текста:
rect_kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (12, 12))Следующий шаг — применение метода расширения двоичного изображения для получения границ текста:
dilation = cv2.dilate(thresh1, rect_kernel, iterations = 3)
cv2.imwrite('dilation_image.jpg',dilation)
Можно увеличить число итераций в зависимости от пикселей переднего плана, т.е. белых пикселей, чтобы получить правильную форму ограничительной рамки.
Теперь воспользуемся методом find contour для получения площади белых пикселей.
contours, hierarchy = cv2.findContours(dilation, cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_NONE)Чтобы выполнить некоторые операции с изображением, скопируйте его в другую переменную:
im2 = img.copy()Теперь пришло время магического преобразования изображения. Для этого получим координаты области белых пикселей и нарисуем вокруг нее ограничительную рамку, а также сохраним текст с изображением в текстовый файл:
for cnt in contours:
x, y, w, h = cv2.boundingRect(cnt)
# Рисуем ограничительную рамку на текстовой области
rect=cv2.rectangle(im2, (x, y), (x + w, y + h), (0, 255, 0), 2)
# Обрезаем область ограничительной рамки
cropped = im2[y:y + h, x:x + w]
cv2.imwrite('rectanglebox.jpg',rect)
# открываем текстовый файл
file = open("text_output2.txt", "a")
# Использование tesseract на обрезанной области изображения для
получения текста
text = pytesseract.image_to_string(cropped)
# Добавляем текст в файл
file.write(text)
file.write("\n")
# Закрываем файл
file.closeВывод изображения с ограничительной рамкой.

Результат работы с текстовым файлом.
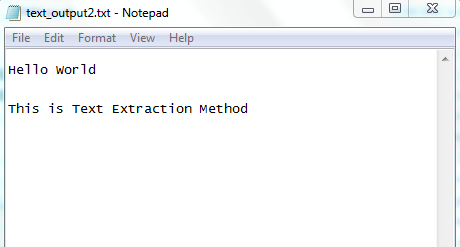
Учтите следующую закономерность: если число итераций равно 1, то текст не сохраняется в текстовом файле; результат получается после увеличения числа итераций до 3.
Если код работает правильно, но результат не выводится, проверьте или измените размер ядра и число итераций.
Чтобы извлечь изображение каждой ограничительной рамки, выполните следующие действия:
crop_number=0
for cnt in contours:
x, y, w, h = cv2.boundingRect(cnt)
# Рисуем ограничительную рамку на текстовой области
rect = cv2.rectangle(im2, (x, y), (x + w, y + h), (0, 255, 0), 2)
# Обрезаем область ограничительной рамки
cropped = im2[y:y + h, x:x + w]
cv2.imwrite("crop"+str(crop_number)+".jpeg",cropped)
crop_number+=1
cv2.imwrite('rectanglebox.jpg',rect)
# открываем текстовый файл
file = open("text_output2.txt", "a")
# Использование tesseract на обрезанной области изображения для
получения текста
text = pytesseract.image_to_string(cropped)
# Добавляем текст в файл
file.write(text)
file.write("\n")
# Закрываем файл
file.close
Читайте также:
- Разворачиваем декораторы
- Как быстро найти проблемы с Python-типами через Pytype
- Знакомство с Anaconda: что это такое и как установить
Читайте нас в Telegram, VK и Яндекс.Дзен
Перевод статьи Amit Chauhan, Text Detection and Extraction From Image with Python





