
Примечание. В статье будет использован один и тот же пример для каждого шаблона.
Увеличивающаяся совокупность
Начнем с приложения для онлайн-секонд-хенда, где продавцы предлагают товары покупателям. Пока оно еще небольшое и содержит только одну совокупность объектов:
class Vendor {
name:string
country:string
products:{
offers:{
// ...
}[]
}[]
}Со временем начинают появляться задержки из-за того, что для доступа к любым данным приложения приходится загружать всю совокупность с X products и Y offers.
Когда пользоваться ленивой загрузкой
Первое, что можно испробовать, — отложенная или ленивая загрузка, при которой загружается только часть данных. На первый взгляд, это решает проблему.
В долгосрочной перспективе ленивая загрузка не обязательно окажется лучшим вариантом.
- Она может усложнить обслуживание, так как ошибки загрузки могут возникать с опозданием (при сохранении).
- С отложенной загрузкой автоматические тесты будет сложнее настраивать, а без нее они станут менее надежными.
- В некоторых случаях могут даже возникнуть проблемы с производительностью (несколько отложенных загрузок в каскаде).
Вернемся к классу Vendor. Если нужно работать только с одним Product, то ленивая загрузка не оптимальна: Product будет загружен полностью и сразу. Чтобы ограничить время загрузки, добавим ленивую загрузку в Offer. Однако теперь при работе с тем самым Product, придется подумать и о загрузке Offer.
Это называется случайной сложностью. В предыдущем абзаце речь шла лишь о технических проблемах, а не бизнес-задачах. Чтобы приложение оставалось работоспособным, стоит свести случайную сложность к минимуму.
Таким образом, шаблон ленивой загрузки подходит для простых приложений, но не для более сложных.
Дизайн зависит от случаев использования
Продолжим рассматривать на примере:
class Vendor {
vendor_id:string
name:string
country:string
products:{
offers:{
// ...
}[]
}[]
}Чтобы верно разделить этот агрегат, рассмотрим сначала простые варианты использования:
- изменить данные
Vendor; - изменить данные
Product; - добавить/изменить
OfferдляProduct.
В этих случаях использования мы видим, что можно отдельно работать над Vendor и над Product. Другими словами, при изменении состояния Vendor состояние Product не изменяется. Ничто не оправдывает нахождения этих двух объектов в одной транзакции.
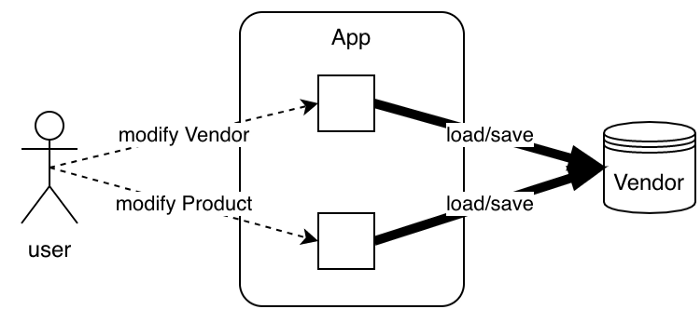
Аналогично, работать над Product вполне возможно отдельно от других экземпляров Product.
Таким образом, мы можем отделить Product от Vendor и создать следующие агрегаты:
class Vendor {
vendor_id:string
name:string
country:string
}
class Product{
product_id:string
vendor_id:string
name:string
offers:{
// ...
}[]
}После этого для работы над Product больше не требуется загружать ни Vendor, ни другие экземпляры Product. Никакой больше ленивой загрузки.
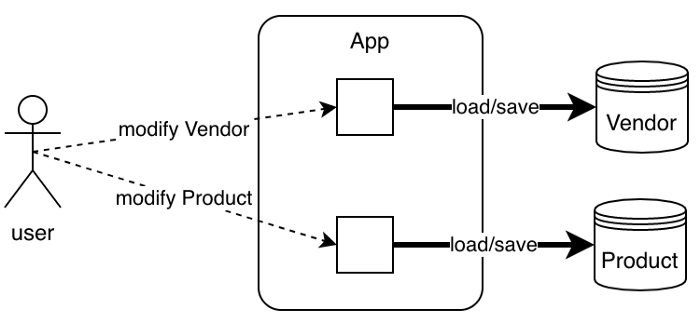
Агрегат — это данные, которые необходимо загружать вместе. Конкретика зависит как от вариантов использования, так и от производительности приложения.
Слишком много разделения ведет к анемичным объектам
Что касается Offer, мы могли бы сделать то же самое и убрать его из Product.
Чтобы усложнить наш пример, добавим больше вариантов использования.
- Цена
Offerдолжна быть выше, если состояние лучше, чем у другогоOffer(и наоборот). - Количество каждого
Offerв хранилище не может превышать лимит, определенный дляProduct.
Второе правило на самом деле не имеет реального смысла, даже если бы можно было представить себе контракт между продавцом и маркетплейсом. Но для данной статьи оно подходит.
В этом случае мы замечаем, что для изменения Offer необходимо загрузить Product и другие Offer. Кажется, что лучше сохранить совокупность Product и Offer в одном агрегате.
class Product{
//...
stock_limit:number
offers:{
price:number
condition:{
New, Refurbish, Used, //...
}
stock:number
// ...
}[]
}Несмотря на эти бизнес-правила, мы все равно могли бы выцепить Offer. Это технически возможно. Но будьте осторожны: не переусердствуйте в сокращении агрегатов, потому что вместо упрощения кода или улучшения времени загрузки можно получить противоположный эффект.
Мы будем умножать количество запросов — отсюда отрицательное влияние на нагрузку. В нашем примере вместо того, чтобы загружать Product и Offer сразу, сначала загрузится Product, а потом уже Offer.
Слишком сильное разделение также приводит к усложнению кода. Например, код, который проверяет согласованность Offer был помещен в родительский Product. Если разделить агрегаты, будет гораздо менее очевидно, где разместить код. Можно было бы создать доменный сервис. Если экстраполировать, то вся логика окажется внутри службы и вне агрегата. Агрегаты без логики — и есть анемичные объекты.
Сложность оправдывает CQRS
По мере добавления к приложению новых вариантов использования Product снова разрастается. Повторяется та же ситуация, что и в начале, но на этот раз в более сложном контексте.
Посмотрим на новые правила, касающиеся состояния Product.
- Не опубликован:
Productможет быть изменен. - Опубликован:
Productне подлежит изменению, есть возможность снова стать “Неопубликованным”,Offerможет быть изменен. - Архивирован: только после “Опубликован”.
ProductиOfferне подлежат изменению.
Конечно, я мог бы включить статус непосредственно в Product:
class Product{
// ...
status:{ Unpublished, Publish, Archived}
offers:{
// ...
}[]
}Поэтому, как только мы модифицируем Product, нужно заранее проверить статус, чтобы при необходимости разрешить изменение состояния. Однако агрегат разделяется на две части:
- либо мы обновляем данные
ProductилиOffer— тогдаstatusиспользуется, но не изменяется; - либо мы обновляем
status, а остальное не используется и не изменяется.
Таким образом, можно было бы создать еще один агрегат — ProductLifecycle — для обработки правил насчет статуса:
class Product{
product_id:string
// ...
modifiable:boolean
offers:{
// ...
modifiable:boolean
}[]
}
class ProductLifeCycle{
product_id:UUID
// ...
status:{ Unpublished, Publish, Archived}
}Это кажется излишним, но есть преимущество в разделении логики продукта и жизненного цикла продукта. Это также приближает модель к описанным выше правилам. Например, становится явно выражено, можно ли модифицировать Product или нет. Кроме того, легко представить, что на практике с изменением статуса будут ассоциироваться дополнительные данные (например, дата, пользователь, комментарий и т. д.).
Варианты использования для обновления статуса продукта немного сложнее. Для этого требуется извлечь и сохранить два агрегата. С другой стороны, для других вариантов использования загружаемые данные уменьшаются.
Это компромисс, на который необходимо пойти в зависимости от частоты и сложности вариантов использования.
Однако это влияет на время считывания данных (особенно для отображения). Для одного и того же отображения теперь необходимо загружать два агрегата вместо одного. Поскольку на одну операцию записи приходится десять операций чтения, увеличение задержки недопустимо.
Мы не будет перегруппировывать агрегаты. Именно здесь пригождается CQRS, поскольку он вводит модель чтения (RM) и модель записи (WM).
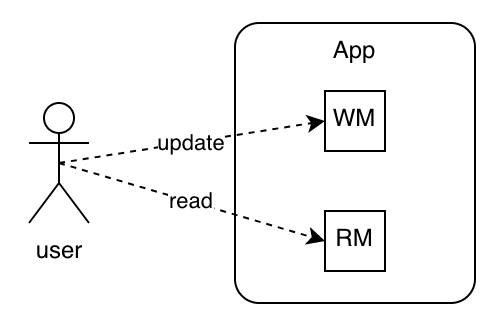
При каждом обновлении, выполняемом на стороне записи, модель чтения обновляется как проекция модели записи. У нее не обязательно должна быть такая же структура, как в примере ниже:
class ProductView{
product_id:string
modifiable:boolean
ordersCount:number
isPublish:boolean
isArchived:boolean
statusHistory:{
status:string
date:string
comment:string
}[]
// ...
}Этот объект больше не агрегат, это обыкновенный DTO — внутри него больше нет логики.
Таким образом, когда агрегат становится слишком большим, его можно разделить на несколько более мелких агрегатов. Параллельно, чтобы избежать снижения производительности, строится специальная модель чтения. Агрегаты теперь используются только на стороне записи.
Заключение
Важно понимать, что дизайн агрегатов зависит от размера приложения и вариантов использования. Приложение с сотней вариантов использования не разделяется таким же образом, как приложение с тысячами сложных вариантов использования.
Причины разделения — это, как правило, проблемы с производительностью. Однако использовать разделение слишком рано, чтобы предотвратить будущие проблемы, тоже не стоит: это увеличивает случайную сложность, а также риск того, что агрегаты не будут адаптированы к потребностям.
CQRS — шаблон, подходящий для крупных проектов. Кроме того, не обязательно пользоваться им везде в рамках приложения, его можно ввести частично.
Перейти на CQRS довольно легко. Есть несколько уровней внедрения CQRS с возрастающими трудностями. Самое главное — соблюдать совокупный шаблон и избегать ленивой загрузки.
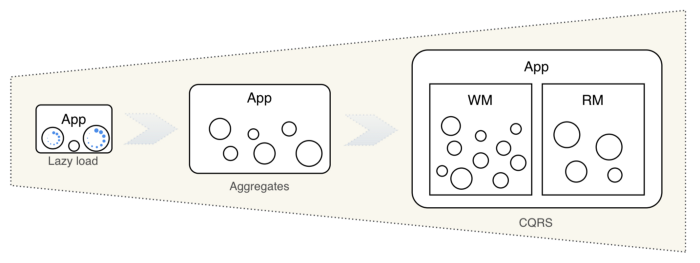
Приложение похоже на человека. Сначала оно маленькое, но его рост нужно контролировать. На определенных ключевых этапах полезно проводить глубокие преобразования, противоположные первоначальному выбору.
Читайте также:
- 5 ведущих шаблонов проектирования распределенных систем
- С нуля до разработчика игр: как начать создавать видеоигры, если у вас нет опыта
- Как обеспечить обмен данными между микросервисами
Читайте нас в Telegram, VK и Дзен
Перевод статьи MaxxP: Lazy Loading, Aggregate and CQRS





