
Независимо от того, приходилось ли вам разрабатывать на Java, вы, вероятно, слышали о виртуальной машине Java (JVM).
JVM — ядро экосистемы Java. Она позволяет программам на базе Java следовать принципу “написал один раз, запустил где угодно”. Вы можете написать Java-код на одной машине и запустить его на любой другой благодаря JVM.
JVM изначально разрабатывалась исключительно для поддержки Java. Однако со временем на платформе Java обосновались многие другие языки, такие как Scala, Kotlin и Groovy. Все они в совокупности называются языками JVM.
В этой статье мы расскажем больше о JVM: как она работает и из каких компонентов состоит.
Что такое виртуальная машина?
Прежде чем переходить к JVM, остановимся на самой концепции виртуальной машины (ВМ).
Виртуальная машина — это виртуальное представление физического компьютера. Виртуальную машину можно назвать гостевой, а физический компьютер, на котором она работает, — хост-машиной.
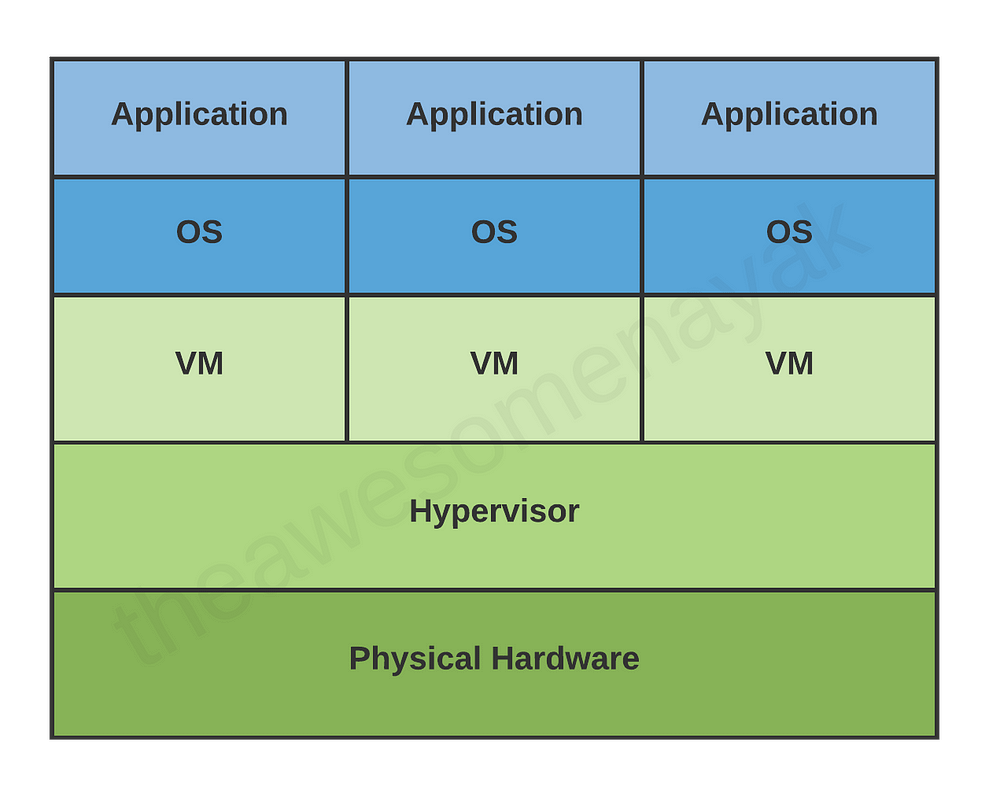
На одной физической машине может работать несколько виртуальных, каждая со своей собственной операционной системой и приложениями. Эти виртуальные машины изолированы друг от друга.
Что такое виртуальная машина Java?
В языках программирования, таких как C и C++, код сначала компилируется в машинный для конкретной платформы. Эти языки называются компилируемыми языками.
С другой стороны, в таких языках, как JavaScript и Python, компьютер выполняет инструкции напрямую, без необходимости компиляции. Эти языки называются интерпретируемыми.
Java использует комбинацию обоих методов. Код Java сначала компилируется в байтовый код и генерирует файл класса (.class). Этот файл класса затем интерпретируется виртуальной машиной Java для базовой платформы. Один и тот же файл класса может выполняться на любой версии JVM, на любой платформе и операционной системе.
Подобно обычным виртуальным машинам, JVM создает изолированное пространство на хост-машине. Это пространство может использоваться для выполнения Java-программ независимо от платформы или операционной системы компьютера.
Архитектура виртуальной машины Java
JVM состоит из трех отдельных компонентов:
- загрузчик классов;
- область памяти/данных среды выполнения;
- механизм выполнения.
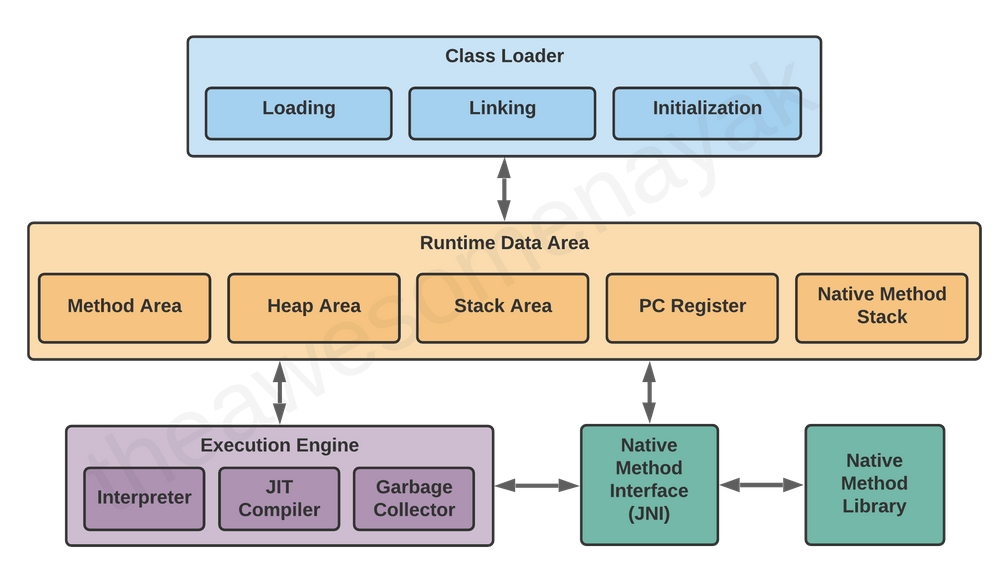
Рассмотрим каждый из них более подробно.
Загрузчик классов
Когда вы компилируете исходный файл .java, он преобразуется в байт-код как файл .class. Когда вы вызываете этот класс у себя в программе, загрузчик классов загружает его в основную память.
Как правило, первым в память загружается класс, содержащий метод main().
Процесс загрузки класса состоит из трех этапов: загрузка, связывание и инициализация.
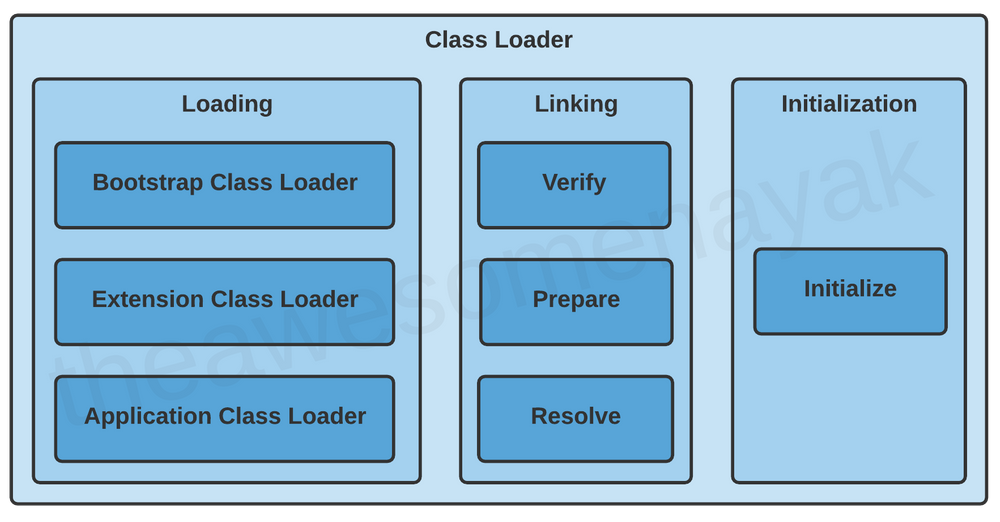
Загрузка
Загрузка включает бинарную репрезентацию (байт-код) класса или интерфейса с определенным именем и создание на его основе исходного класса или интерфейса.
В Java доступны три встроенных загрузчика классов:
- Загрузчик классов начальной загрузки (Bootstrap Class Loader) — корневой загрузчик классов. Это суперкласс загрузчика классов расширений, который загружает стандартные пакеты Java, такие как
java.lang,java.net,java.util,java.ioи так далее. Эти пакеты находятся внутриrt.jarи других основных библиотек, присутствующих в каталоге$JAVA_HOME/jre/lib. - Загрузчик классов расширений (Extension Class Loader) — подкласс загрузчика классов начальной загрузки и суперкласс загрузчика классов приложений. Он загружает расширения стандартных библиотек Java, которые присутствуют в каталоге
$JAVA_HOME/jre/lib/ext. - Загрузчик классов приложений (Application Class Loader) — конечный загрузчик классов и подкласс загрузчика классов расширений. Он загружает файлы, которые находятся в пути к классам (classpath). По умолчанию путь к классу устанавливается как текущий каталог приложения. Путь к классу также можно изменить, добавив параметр командной строки
-classpathили-cp.
JVM использует метод ClassLoader.loadClass() для загрузки класса в память. Он пытается загрузить класс на основе полного имени.
Если родительский загрузчик классов не может найти класс, он делегирует работу дочернему загрузчику классов. Если последний загрузчик также не может загрузить класс, он создает исключение NoClassDefFoundError или ClassNotFoundException.
Связывание
После загрузки класса в память происходит процесс связывания. Связывание класса или интерфейса предполагает объединение различных элементов и зависимостей программы.
Связывание включает следующие шаги.
- Проверка. На этом этапе проверяется структурная корректность файла
.classпутем проверки его на соответствие набору ограничений и правил. Если проверка по какой-либо причине завершается неудачей, выбрасывается исключениеVerifyException.
Например, если код был создан на Java 11, но выполняется в системе, где установлена Java 8, этап проверки завершится неудачно.
- Подготовка. На этом этапе JVM выделяет память для статических полей класса или интерфейса и инициализирует их значениями по умолчанию.
Предположим, что вы объявили в классе следующую переменную:
private static final boolean enabled = true;На этапе подготовки JVM выделяет память для переменной enabled и устанавливает ее значение в значение по умолчанию для логического значения, которое равно false.
- Решение. На этом этапе символические ссылки заменяются прямыми, присутствующими в пуле констант времени выполнения.
Например, если у вас есть ссылки на другие классы или постоянные переменные, присутствующие в других классах, они разрешаются на этом этапе и заменяются их фактическими ссылками.
Инициализация
Инициализация включает выполнение метода инициализации класса или интерфейса (известного как <clinit>). Сюда может входить вызов конструктора класса, выполнение статического блока и присвоение значений всем статическим переменным. Это заключительный этап загрузки класса.
К примеру, ранее мы объявили следующее:
private static final boolean enabled = true;На этапе подготовки переменной enabled было присвоено значение по умолчанию false. На этапе инициализации этой переменной присваивается ее фактическое значение true.
Примечание: JVM имеет многопоточный характер. Может случиться так, что несколько потоков одновременно пытаются инициализировать один и тот же класс. Это может привести к проблемам параллелизма. Чтобы гарантировать правильную работу программы в многопоточной среде, необходимо обеспечить потокобезопасность.
Область данных среды выполнения
В области данных среды выполнения есть пять компонентов:
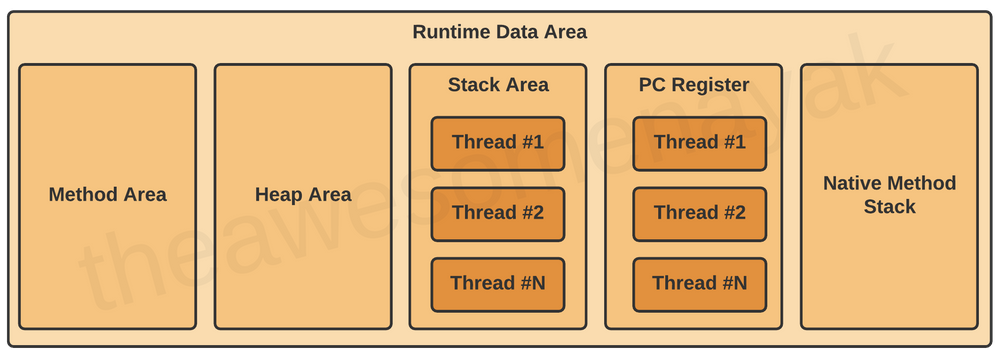
Рассмотрим каждый из них в отдельности.
Область метода
Здесь хранятся все данные уровня класса, такие как пул констант времени выполнения, данные полей и методов, а также код методов и конструкторов.
Если памяти, доступной в области метода, недостаточно для запуска программы, JVM выдает ошибку OutOfMemoryError.
Например, предположим, что мы объявили следующий класс:
public class Employee {
private String name;
private int age;
public Employee(String name, int age) {
this.name = name;
this.age = age;
}
}В этом примере данные уровня поля, такие как name и age, а также сведения о конструкторе загружаются в область метода.
Область метода создается при запуске виртуальной машины, и на каждую виртуальную машину приходится только одна область метода.
Область кучи
Здесь хранятся все объекты и соответствующие им переменные экземпляра. Это область данных времени выполнения, из которой выделяется память для всех экземпляров классов и массивов.
Например, предположим, вы объявили следующий экземпляр:
Employee employee = new Employee();В этом примере создается экземпляр класса Employee и загружается в область кучи.
Куча создается при запуске виртуальной машины, и на каждую виртуальную машину приходится только одна область кучи.
Примечание: поскольку области метода и кучи совместно используют одну и ту же память для нескольких потоков, данные, хранящиеся здесь, не потокобезопасны.
Область стека
Всякий раз, когда в JVM создается новый поток, одновременно создается отдельный стек среды выполнения. Все локальные переменные, вызовы методов и частичные результаты хранятся в области стека.
Если для обработки в потоке требуется больший размер стека, чем доступно, JVM выдает ошибку StackOverflowError.
Для каждого вызова метода в памяти стека делается одна запись, которая называется фреймом стека. Когда вызов метода завершен, фрейм стека уничтожается.
Фрейм стека разделен на три части.
- Локальные переменные. Каждый фрейм содержит массив переменных, известных как его локальные переменные. Здесь хранятся все локальные переменные и их значения. Длина этого массива определяется во время компиляции.
- Стек операндов. Каждый фрейм содержит стек последним-вошел-первым-вышел (last-in-first-out, LIFO), известный как стек операндов. Он действует как рабочая область среды выполнения для любых промежуточных операций. Максимальная глубина этого стека определяется во время компиляции.
- Данные фрейма. Здесь хранятся все символы, соответствующие методу. Здесь также хранится информация о блоке
catchна случай исключений.
К примеру, есть следующий код:
double calculateNormalisedScore(List<Answer> answers) {
double score = getScore(answers);
return normalizeScore(score);
}
double normalizeScore(double score) {
return (score – minScore) / (maxScore – minScore);
}В этом примере кода переменные, такие как answers и score, помещаются в массив локальных переменных. Стек операндов содержит переменные и операторы, необходимые для выполнения математических операций вычитания и деления.
Примечание: поскольку область стека не является общей, она по своей сути потокобезопасна.
Регистры счетчика программ
JVM поддерживает многопоточность. Каждый поток имеет собственный регистр счетчика программ для хранения адреса выполняемой в данный момент инструкции JVM. Как только инструкция выполнена, регистр обновляется следующей инструкцией.
Стеки нативных методов
JVM содержит стеки, которые поддерживают нативные методы, то есть такие методы, которые написаны на языке, отличном от Java, например C или C++. Для каждого нового потока также выделяется отдельный стек нативных методов.
Система выполнения
Как только байт-код загружен в основную память, и подробная информация становится доступна в области данных среды выполнения, наступает следующий этап — запуск программы. Механизм выполнения делает это, выполняя код из каждого класса.
Однако перед выполнением программы байт-код необходимо преобразовать в инструкции машинного языка. В качестве механизма выполнения JVM может задействовать интерпретатор или JIT-компилятор.
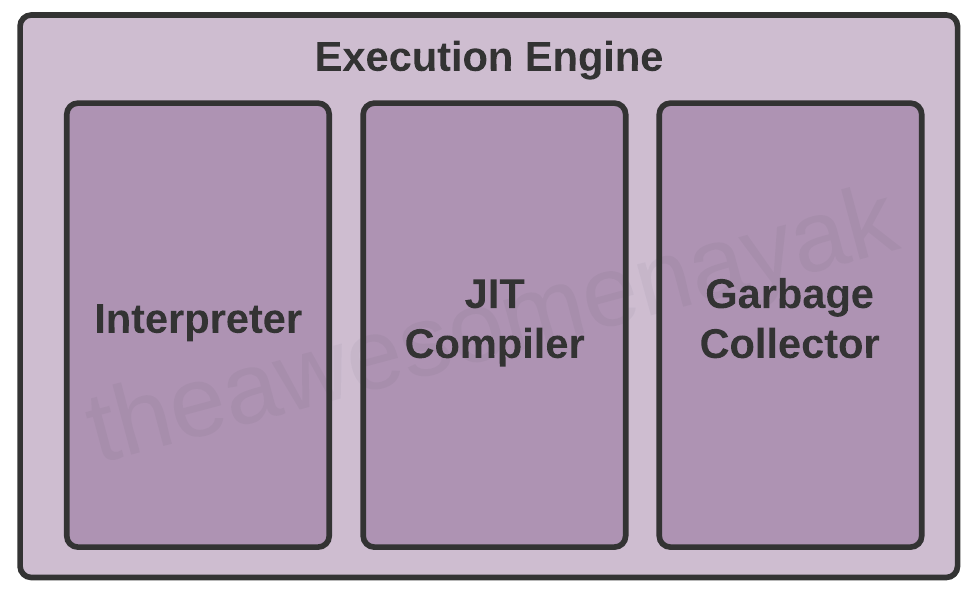
Интерпретатор
Интерпретатор считывает и выполняет инструкции байт-кода строка за строкой. Из-за построчного выполнения интерпретатор работает сравнительно медленнее.
Еще один недостаток интерпретатора — при многократном вызове метода каждый раз требуется новая интерпретация.
JIT-компилятор
JIT-компилятор преодолевает недостаток интерпретатора. Механизм выполнения сначала использует интерпретатор для выполнения байт-кода, но когда он находит какой-то повторяющийся код, то задействует JIT-компилятор.
Затем JIT-компилятор компилирует весь байт-код и изменяет его на собственный машинный код. Этот собственный машинный код используется непосредственно для повторных вызовов методов, что повышает производительность системы.
JIT-компилятор содержит следующие компоненты.
- Генератор промежуточного кода — генерирует промежуточный код.
- Оптимизатор кода — оптимизирует промежуточный код для повышения производительности.
- Генератор целевого кода — преобразует промежуточный код в собственный машинный код.
- Профилировщик — находит горячие точки (код, который выполняется повторно).
Чтобы лучше понять разницу между интерпретатором и JIT-компилятором, предположим, что у вас есть следующий код:
int sum = 10;
for(int i = 0 ; i <= 10; i++) {
sum += i;
}
System.out.println(sum);Интерпретатор будет извлекать из памяти значение sum для каждой итерации в цикле, добавлять к нему значение i и записывать обратно в память. Это дорогостоящая операция, потому что каждый раз при входе в цикл происходит обращение к памяти.
Однако JIT-компилятор распознает, что в этом коде есть “горячая точка”, и выполнит оптимизацию. Он сохранит локальную копию sum в регистре для потока и будет продолжать добавлять значение i в цикле. Как только цикл завершится, компилятор запишет значение sum обратно в память.
Примечание: компилятору требуется больше времени для компиляции кода, чем интерпретатору для интерпретации кода строка за строкой. Если вы намерены запустить программу только один раз, интерпретатор будет предпочтительнее.
Сборщик мусора
Сборщик мусора (Garbage Collector, GC) собирает и удаляет объекты без ссылок из области кучи. Это процесс автоматического восстановления неиспользуемой памяти во время выполнения путем уничтожения мусорных объектов.
Сборка мусора делает память Java эффективной, потому что удаляет объекты без ссылок из памяти кучи и освобождает место для новых объектов. Она включает два этапа:
- Пометка — на этом этапе GC идентифицирует неиспользуемые объекты в памяти.
- Очистка — на этом этапе GC удаляет объекты, идентифицированные на предыдущем этапе.
Сборка мусора выполняется JVM автоматически через регулярные промежутки времени и не требует отдельной обработки. Ее также можно запустить вызовом System.gc(), но выполнение не гарантируется.
JVM содержит три различных типа сборщиков мусора.
- Последовательная сборка мусора. Это самая простая реализация GC. Она предназначена для небольших приложений, работающих в однопоточных средах. Для сборки мусора используется один поток. Запуск приводит к событию “остановки мира”, когда все приложение приостанавливает работу. Аргумент JVM для запуск последовательного сборщика мусора:
-XX:+UseSerialGC. - Параллельная сборка мусора. Это реализация GC по умолчанию, также известная как сборщик пропускной способности. Для сборки мусора в нем используется несколько потоков, но работа приложения все равно приостанавливается при запуске. Аргумент JVM для параллельного сборщика мусора:
-XX:+UseParallelGC. - Garbage First (G1). G1 был разработан для многопоточных приложений с большим доступным размером кучи (более 4 ГБ). Он разбивает кучу на набор областей одинакового размера и использует несколько потоков для их сканирования. G1-сборщик определяет регионы с наибольшим количеством мусора и сначала выполняет сбор мусора в них. Аргумент JVM для этого сборщика мусора:
-XX:+UseG1GC.
Примечание: существует другой тип сборщика мусора, называемый сборщиком параллельных меток (CMS). Однако он устарел начиная с Java 9 и полностью удален в Java 14, и его место занимает сборщик G1.
Нативный интерфейс Java (Java Native Interface, JNI)
Иногда необходимо задействовать в работе нативный (не Java) код (например, написанный на C/C++). К примеру, в тех случаях, когда нужно взаимодействовать с физическим оборудованием или преодолевать ограничения по управлению памятью и производительности в Java. Java поддерживает выполнение нативного кода через нативный интерфейс Java (JNI).
JNI действует как мост для предоставления вспомогательных пакетов другим языкам программирования, таким как C, C++ и так далее. Это особенно полезно в тех случаях, когда нужно написать код, который не полностью поддерживается Java, например, некоторые специфичные для платформы функции могут быть написаны только на C.
Вы можете воспользоваться ключевым словом native, чтобы указать, что реализация метода будет предоставлена нативной библиотекой. Также потребуется вызвать System.LoadLibrary(), чтобы загрузить общую нативную библиотеку в память и сделать ее функции доступными для Java.
Нативные библиотеки методов
Нативные библиотеки методов — это библиотеки, написанные на других языках программирования, таких как C, C++ и ассемблер. Эти библиотеки обычно представлены в виде файлов .dll или .so. Такие библиотеки можно загружать через JNI.
Распространенные ошибки JVM
ClassNotFoundException. Происходит, когда загрузчик классов пытается загрузить классы с помощьюClass.forName(),ClassLoader.loadClass()илиClassLoader.findsystemclass(), но определение класса с указанным именем не найдено.NoClassDefFoundError. Происходит, когда компилятор успешно скомпилировал класс, но загрузчик классов не может найти файл класса во время выполнения.OutOfMemoryError. Происходит, когда JVM не может выделить объект из-за нехватки памяти, и сборщик мусора не может предоставить больше памяти.StackOverflowError. Происходит, если в JVM не хватает места при создании новых кадров стека во время обработки потока.
Заключение
В этой статье мы обсудили архитектуру виртуальной машины Java и ее компоненты. Часто мы не вникаем глубоко во внутреннюю механику JVM или не интересуемся, как она работает, пока работает код.
Только когда что-то идет не так, и нам нужно настроить JVM или устранить утечку памяти, мы пытаемся понять ее внутреннее устройство.
Это также очень популярный вопрос во время интервью на роль бэкенд-разработчика — как младшего, так и старшего уровня. Глубокое понимание JVM поможет вам лучше писать код и избегать подводных камней, связанных со стеком и ошибками памяти.
Читайте также:
- 9 вещей, которыми следует заняться Java программисту в 2018 году
- Превратите свой Java-код в полностью асинхронный
- Циклы Java в сторону - даешь потоки!
Читайте нас в Telegram, VK и Дзен
Перевод статьи Siben Nayak: JVM Tutorial — Java Virtual Machine Architecture Explained for Beginners





