
Введение
PyCaret — это библиотека машинного обучения с открытым исходным кодом на языке Python, которая автоматизирует рабочие процессы МО. Это всеобъемлющий инструмент машинного обучения и управления моделями, который экспоненциально ускоряет цикл экспериментов и способствует большей продуктивности разработчика.
В отличие от других библиотек машинного обучения с открытым исходным кодом, PyCaret является low-code библиотекой, с помощью которой можно заменить “тонны” кода всего несколькими строками. Благодаря этому, эксперименты проходят в разы быстрее и эффективнее. PyCaret представляет собой обертку Python для нескольких библиотек и фреймворков машинного обучения, таких как scikit-learn, XGBoost, LightGBM, CatBoost, spaCy, Optuna, Hyperopt, Ray и других.
Дизайн и простота PyCaret были вдохновлены разработками набирающих популярность специалистов, которых называют Citizen Data Scientists. Этот термин впервые использовали представители компании Gartner. Citizen Data Scientists — это опытные пользователи, которые могут выполнять как простые, так и умеренно сложные аналитические задачи, требовавшие раньше глубоких технических познаний.
Модуль временных рядов PyCaret
Новый модуль временных рядов PyCaret сейчас доступен в бета-версии. Как и все компоненты библиотеки PyCaret, он отличается простотой. Модуль совместим с имеющимся API и поставляется с большим количеством функциональных возможностей, среди которых:
- статистическое тестирование;
- обучение и выбор моделей (30+ алгоритмов);
- анализ моделей;
- автоматическая настройка гиперпараметров;
- логирование экспериментов;
- развертывание в облаке и многое другое.
И все это всего с помощью нескольких строк кода! Впрочем, на это же способны и другие модули Pycaret. Хотите в этом убедиться? Ознакомьтесь с официальным ноутбуком проекта.
Вы можете использовать pip для установки этой библиотеки. Если PyCaret установлена у вас в той же среде, то нужно создать отдельную среду для pycaret-ts-alpha, иначе возникнут конфликты зависимостей. pycaret-ts-alpha будет объединен с основным пакетом Pycaret в следующем крупном релизе.
pip install pycaret-ts-alphaПример рабочего процесса
Рабочий процесс в модуле временных рядов PyCaret очень прост. Начинать следует с функции setup, где вы определяете горизонт прогнозирования fh и количество папок (folds). Вы также можете определить стратегию fold_strategy как расширяющуюся (expanding) или скользящую (sliding).
После такой настройки функция compare_models, которая вам наверняка знакома, может обучить и оценить 30+ алгоритмов — от ARIMA до XGboost (TBATS, FBProphet, ETS и др.).
Функция plot_model используется либо до, либо после процесса обучения. Если применять ее до старта обучения, она может предоставить хорошую коллекцию графиков временных рядов EDA, построенных с помощью интерфейса plotly. При использовании совместно с моделью plot_model работает над тем, что осталось от модели, а также может пригодиться для ее подгонки.
А с помощью predict_model строятся прогнозы.
Загрузка данных
import pandas as pd
from pycaret.datasets import get_data
data = get_data('pycaret_downloads')
data['Date'] = pd.to_datetime(data['Date'])
data = data.groupby('Date').sum()
data = data.asfreq('D')
data.head()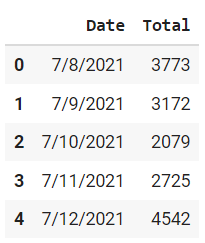
# построение графика данных
data.plot()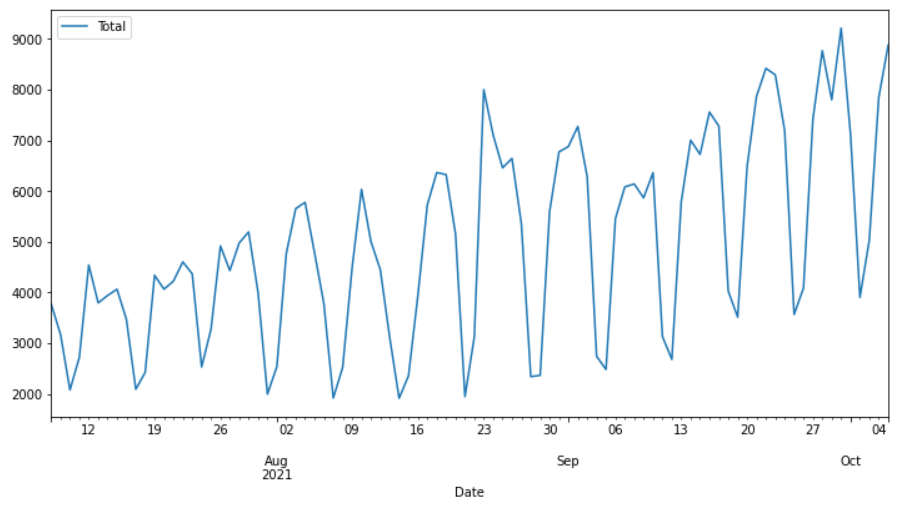
Этот временной ряд представляет собой количество ежедневных загрузок библиотеки PyCaret с pip.
Установка
# для функционального API
from pycaret.time_series import *
setup(data, fh = 7, fold = 3, session_id = 123)
# для API с ориентацией на новый объект
from pycaret.internal.pycaret_experiment import TimeSeriesExperiment
exp = TimeSeriesExperiment()
exp.setup(data, fh = 7, fold = 3, session_id = 123)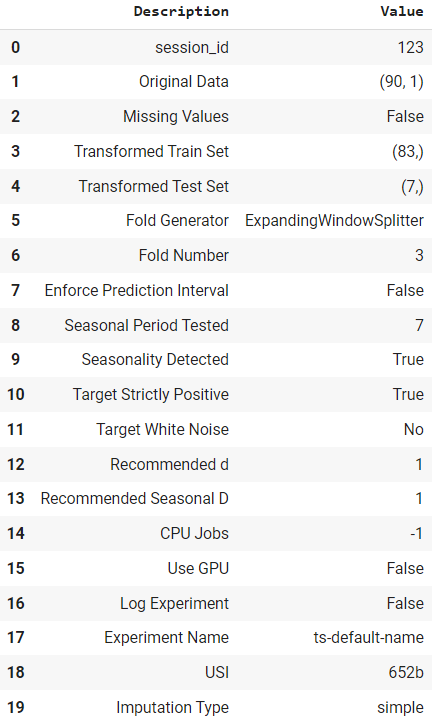
Статистическое тестирование
check_stats()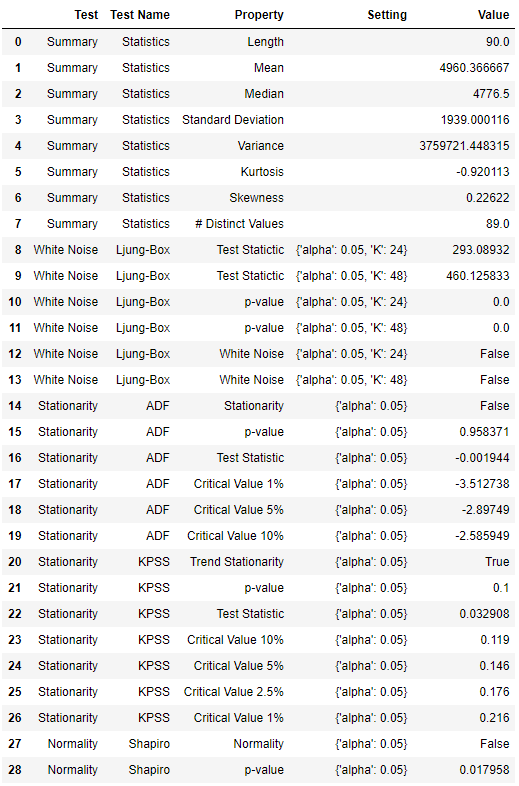
Разведочный анализ данных
# для функционального API
plot_model(plot = 'ts')
# для API с ориентацией на объект
exp.plot_model(plot = 'ts')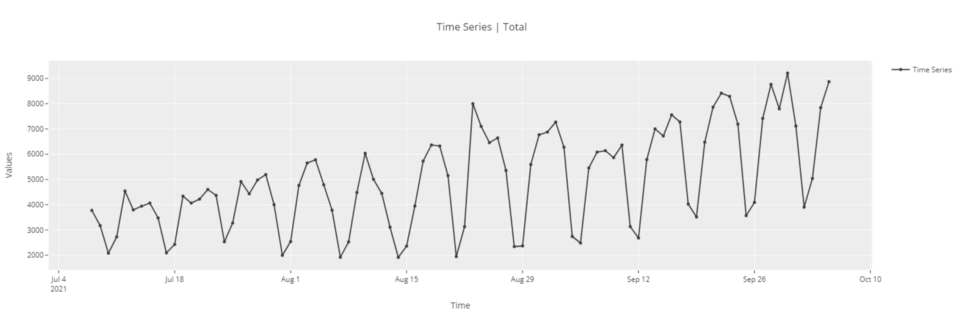
# график кросс-валидации
plot_model(plot = 'cv')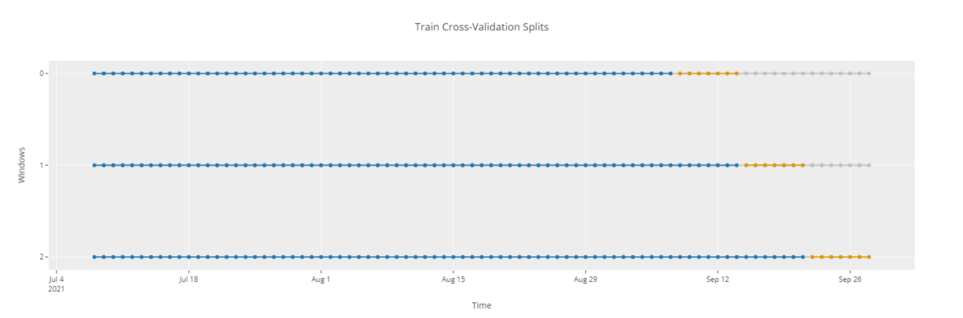
# График ACF
plot_model(plot = 'acf')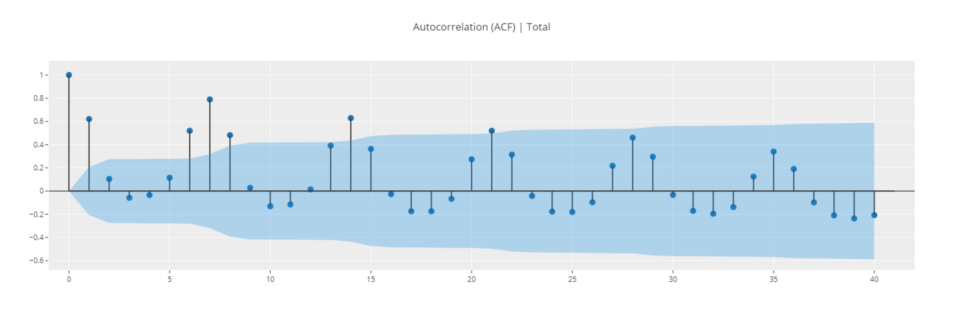
# График диагностики
plot_model(plot = 'diagnostics')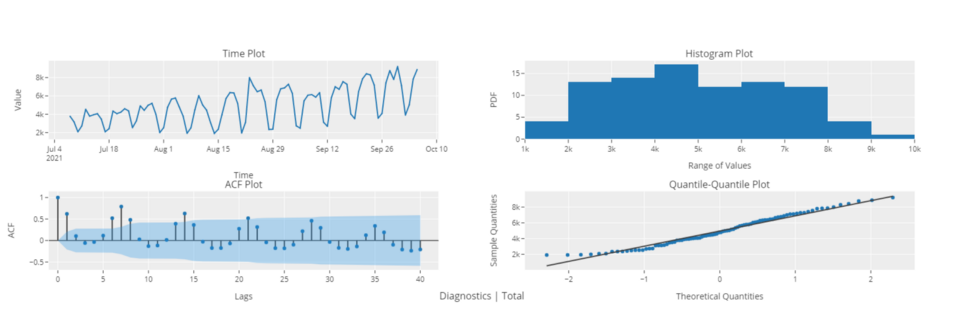
# График декомпозиции
plot_model(plot = 'decomp_stl')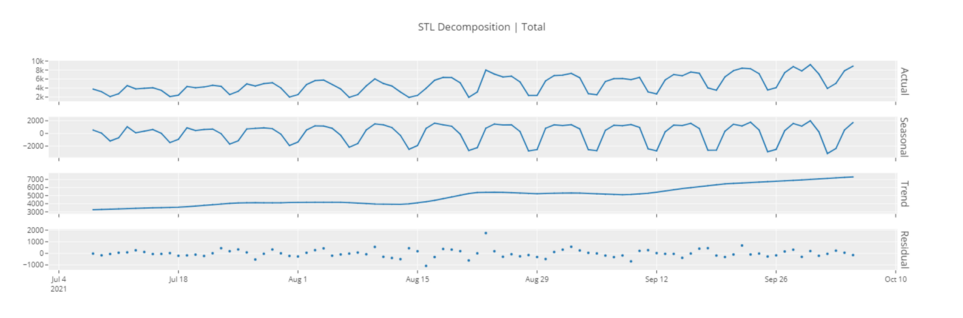
Обучение и выбор модели
# для функционального API
best = compare_models()
# для API, ориентированного на объект
best = exp.compare_models()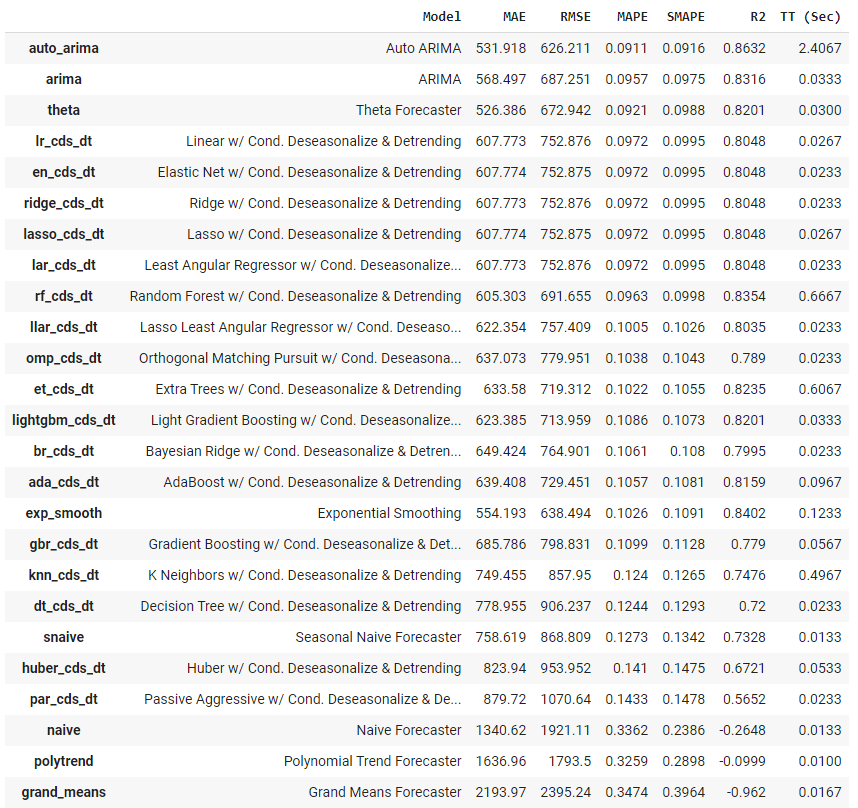
create_model в модуле временных рядов работает так же, как и в других модулях.
# создание модели fbprophet
prophet = create_model('prophet')
print(prophet)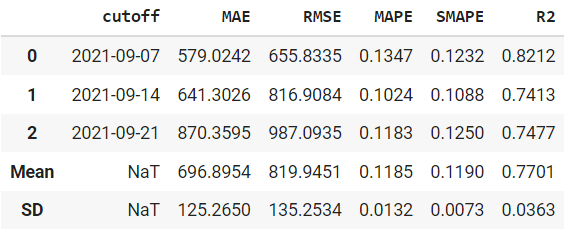

Почти аналогично проходит работа с tune_model.
tuned_prophet = tune_model(prophet)
print(tuned_prophet)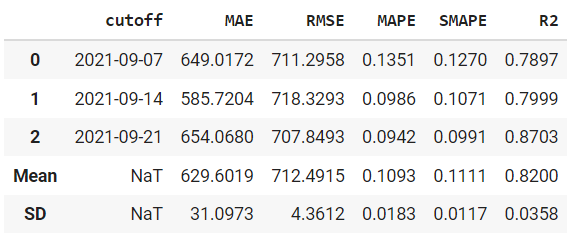

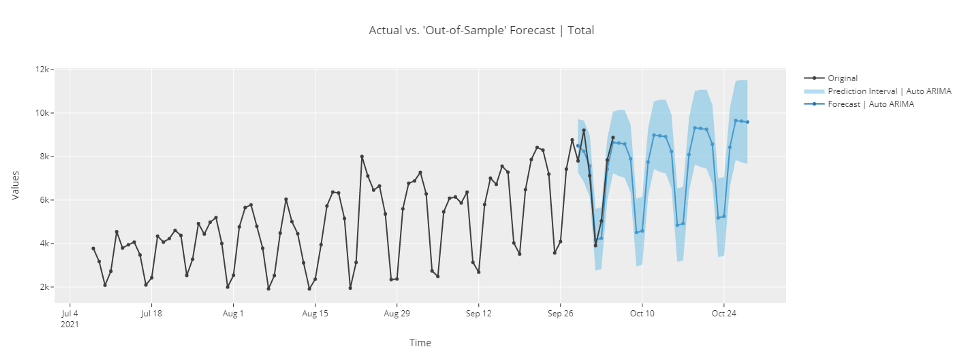
plot_model(best, plot = 'forecast')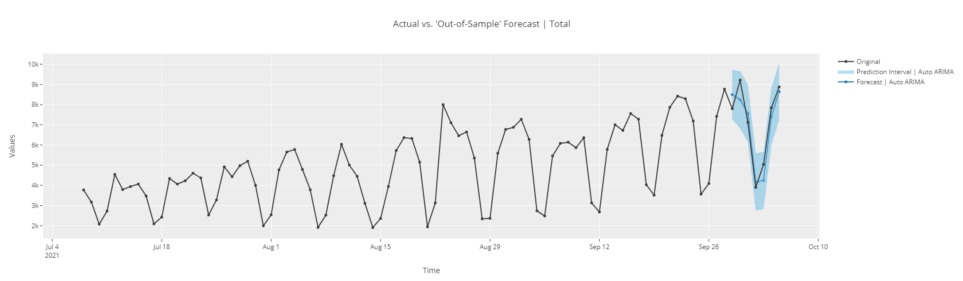
# прогноз в неизвестном будущем
plot_model(best, plot = 'forecast', data_kwargs = {'fh' : 30})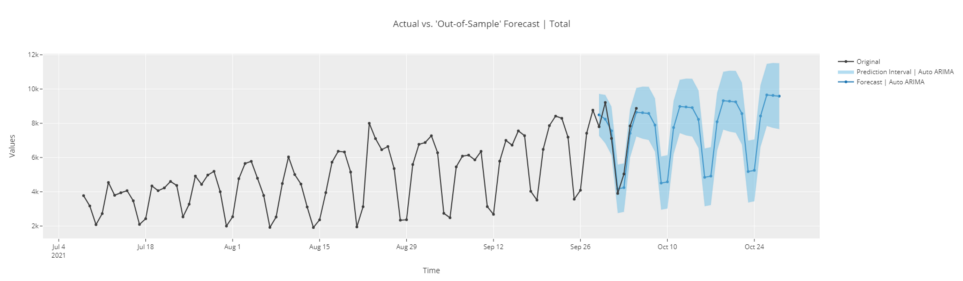
# график внутривыборочного периода
plot_model(best, plot = 'insample')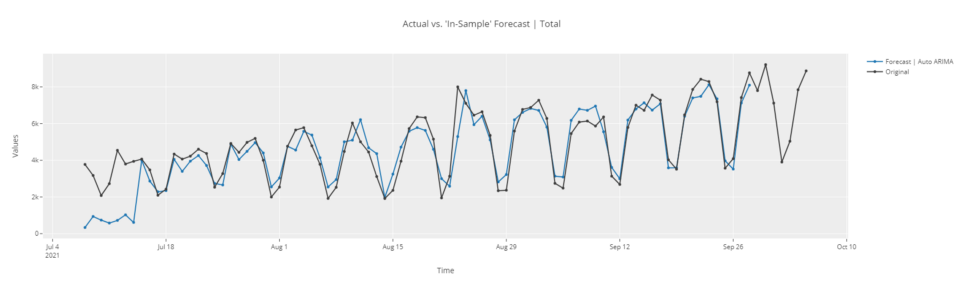
# график остатков
plot_model(best, plot = 'residuals')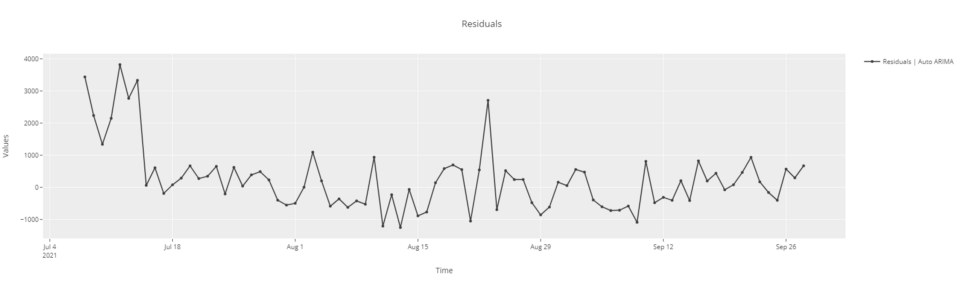
# график диагностики
plot_model(best, plot = 'diagnostics')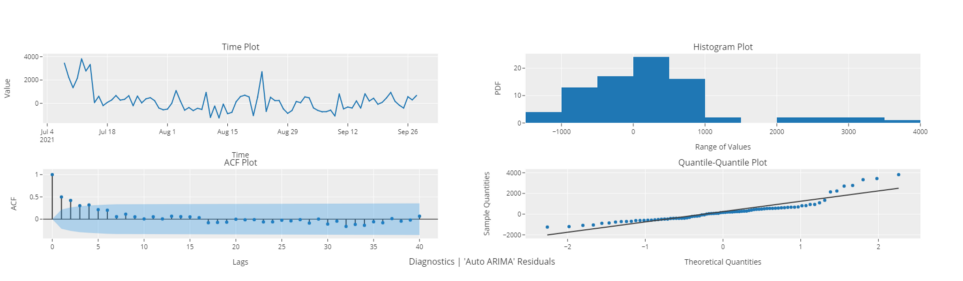
Развертывание
# доработка модели
final_best = finalize_model(best)
# создание прогнозов
predict_model(final_best, fh = 90)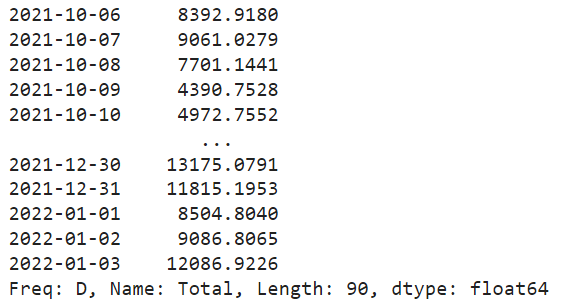
# сохранение модели
save_model(final_best, 'my_best_model')
Читайте также:
- Почему вы должны начать использовать .npy файл чаще…
- Обнаружение объектов с помощью цветовой сегментации изображений в Python
- Python для анализа данных: 8 концепций, о которых вы могли забыть
Читайте нас в Telegram, VK и Яндекс.Дзен
Перевод статьи Moez Ali: 📢 Announcing PyCaret’s New Time Series Module




