
Несколько недель назад я столкнулась с наглым обманом со стороны продавца-мошенника на известном коммерческом сайте. Хотя такое часто случается в современном киберпространстве, инцидент заставил меня задаться серьезным вопросом: “Могу ли я и дальше доверять этому сайту?”.
Если я перестану пользоваться этим ресурсом (и другие люди последуют моему примеру), пострадает рынок, но не обязательно тот продавец, который меня обманул. Мошенник наверняка найдет способ заманить новых жертв на другой сайт. Звучит неутешительно. Но давайте пока оставим наши страхи в стороне и попробуем трезво разобраться в проблеме.
Данные
Исходный набор данных был получен от Джеффри Мвуту Мабиламы на Kaggle (см. лицензию). Он содержит данные о продавцах и клиентах коммерческого сайта C2C. Чтобы подогнать этот набор данных под цели нашего анализа, я очистила его, провела предварительную обработку и внесла в него необходимые изменения. Чтобы получить более подробную информацию, можете ознакомиться с кодом здесь.
Обратите внимание на то, что столбца “Мошенничество” нет в исходном наборе данных. В измененном варианте я прикрепила этот столбец, чтобы указать, можно ли считать акт продажи мошенничеством или нет. Продажа признавалась мошеннической в том случае, если отправленный продукт не соответствовал своему описанию на этапе предварительной проверки.
Измененный набор данных выглядит примерно так (см. ниже).
Внимание: здесь показана сокращенная версия для предварительного просмотра, а не весь набор данных.
,socialNbFollowers,socialNbFollows,socialProductsLiked,productsListed,productsWished,productsBought,daysSinceLastLogin,seniority,_gender,_hasAnyApp,_hasProfilePicture,Fraud
9858,5.0,8.0,2.0,25.0,0.0,0.0,11.0,3203.0,0.0,1.0,1.0,0.0
9859,5.0,8.0,2.0,25.0,0.0,0.0,11.0,3203.0,0.0,1.0,1.0,0.0
9860,5.0,8.0,2.0,25.0,0.0,0.0,11.0,3203.0,0.0,1.0,1.0,0.0
9861,5.0,8.0,2.0,25.0,0.0,0.0,11.0,3203.0,0.0,1.0,1.0,1.0
9862,5.0,8.0,64.0,2.0,0.0,4.0,25.0,3202.0,1.0,0.0,0.0,0.0Код
Сначала импортируем необходимые библиотеки:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from mpl_toolkits import mplot3d
from mpl_toolkits.mplot3d import Axes3D
import sklearn as sk
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import make_scorer, roc_auc_score, classification_report, confusion_matrix, roc_curve
%matplotlib notebookТеперь загрузим данные:
clndf = pd.read_csv('final_data.csv')
clndf.describe()>> Выходные данные
В выходную ячейку печатается фрейм данных. Поскольку у вас могут возникнуть трудности с пониманием изображения на скриншоте, я преобразовала фрейм данных в CSV-файл и встроила его сюда.
,Unnamed: 0,socialNbFollowers,socialNbFollows,socialProductsLiked,productsListed,productsWished,productsBought,daysSinceLastLogin,seniority,_gender,_hasAnyApp,_hasProfilePicture,Fraud
count,12027,12027,12027,12027,12027,12027,12027,12027,12027,12027,12027,12027,12027
mean,6013,46.023,170.446,579.963,21.244,57.850,4.813,74.808,3072.821,0.222,0.731,0.550,0.226
std,3472.04,79.427,1332.734,4811.941,38.380,224.143,18.867,143.552,166.069,0.416,0.443,0.497,0.418
min,0,3,0,0,0,0,0,11,2852,0,0,0,0
25%,3006.5,9,8,1,1,0,0,11,2857,0,0,0,0
50%,6013,21,8,5,7,0,0,13,3196,0,1,1,0
75%,9019.5,52,10,46,23,8,1,43,3201,0,1,1,0
max,12026,744,13764,51671,244,1916,405,709,3205,1,1,1,1Обратите внимание на два важных момента. Во-первых, образовался лишний столбец “Unnamed: 0”. Во-вторых, столбец “Мошенничество” (целевая переменная величина в этом проекте) имеет среднее значение ниже 0,5. У этого столбца есть только два уникальных значения (“1” для обозначения мошеннической деятельности в сфере продаж и “0” в случае отсутствия таковой). Низкое среднее значение указывает на то, что набор данных несбалансирован и смещен в сторону класса “0”. Исправим все эти проблемы поочередно.
Удаляем ненужный столбец:
clndf.drop(['Unnamed: 0'],axis=1,inplace=True)Указываем функции и цель:
target_data = clndf['Fraud']
feature_data = clndf.drop(labels = ['Fraud'],axis = 1,inplace = False)Выполняем разделение на train и test:
feature_train, feature_test, target_train, target_test = train_test_split(feature_data, target_data, test_size=0.30, random_state=101)
feature_test1, feature_test2, target_test1, target_test2 = train_test_split(feature_test, target_test, test_size=0.40, random_state=101)Вы можете задаться вопросом, почему мы разделяем тестовый набор данных на две отдельные части. Это станет ясно чуть позже.
Формируем модель:
model = RandomForestClassifier()
paramdict = {'criterion':['gini','entropy'],'min_samples_leaf':range(1,5),'class_weight':['balanced','balanced_subsample'],'max_features':['sqrt','log2'],'random_state':[101],'min_samples_split':range(2,6),'min_impurity_decrease':list(map(lambda x: x/10, range(0,5,1)))}
grid = GridSearchCV(model, paramdict, scoring=make_scorer(roc_auc_score),refit=True,verbose=0.2,cv=5,n_jobs=-1)
grid.fit(feature_train,target_train)Обратите внимание: мы включили параметр “class_weight” в ParamDict, чтобы остановить смещение набора данных в сторону класса “0”. Таким образом, мы снабжаем нашу модель инструментом эффективного обнаружения обоих классов. [Дополнительная информация].
Поскольку мы явно определили оценочную метрику, поиск по сетке параметров выдаст лучшую модель на основе оптимального показателя AUC, найденного в ходе перекрестной проверки. [Дополнительная информация].
Просматриваем лучший набор параметров:
grid.best_params_>>Выходные данные

Очевидно, что лучшее значение параметра “min_samples_leaf” предполагает верхний предел диапазона, установленного нами в ParamDict. Поэтому есть вероятность, что если указано более высокое его значение, этот параметр может работать лучше. Что ж, давайте увеличим его диапазон и снова выполним поиск по сетке.
Изменяем набор параметров и снова формируем модель:
model = RandomForestClassifier()
paramdict2 = {'criterion':['gini','entropy'],'min_samples_leaf':range(4,10),'class_weight':['balanced','balanced_subsample'],'max_features':['sqrt','log2'],'random_state':[101],'min_samples_split':range(2,6),'min_impurity_decrease':list(map(lambda x: x/10, range(0,5,1)))}
grid2 = GridSearchCV(model, paramdict2, scoring=make_scorer(roc_auc_score),refit=True,verbose=0.2,cv=5,n_jobs=-1)
grid2.fit(feature_train,target_train)Снова просматриваем лучший набор параметров:
grid2.best_params_grid2.best_params_>>Выходные данные

Отличные новости! Все лучшие параметры в этом случае находятся в рамках заданного нами диапазона, даже исключая их верхний и нижний пределы. Поэтому можно сделать следующий вывод: это лучшая модель, выявленная с помощью поиска по сетке.
Распечатываем отчет о классификации для второго тестового набора:
target_pred2_2=grid2.predict(feature_test2)
report2_2=classification_report(target_test2,target_pred2_2,output_dict=True)
pd.DataFrame(report2_2)>>Выходные данные
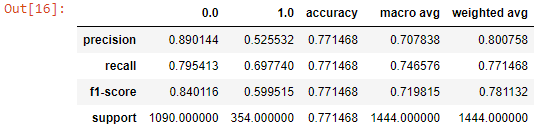
Итак, с помощью вышеуказанного алгоритма мы можем обнаружить только 69,77% случаев мошенничества (полнота для класса 1.0). Этого может оказаться недостаточно для реальной потребности. Пойдем по другому пути, чтобы повысить уровень обнаружения мошеннических схем.
Выбираем пороговое значение
Рассмотрим два неблагоприятных исхода работы нашей модели.
- Ложно-отрицательный результат: продавец оказывается мошенником, но модель не обнаруживает этого.
- Ложно-положительный результат: модель ошибочно распознает честного продавца как мошенника.
Хотя оба этих исхода указывают на провал модели, первый результат, по-видимому, более опасен по своим потенциальным последствиям. Клиент не особо пострадает, если избежит встречи с несколькими честными продавцами, ведь на рынке всегда хватает поставщиков товаров и услуг, готовых удовлетворить потребности покупателя. Но когда мы сталкиваемся с мошенничеством, мы переживаем настоящий кошмар. Поэтому кажется более безопасным выходом принять большее количество ложных срабатываний для увеличения полноты класса 1.
Формула 📎 :
Полнота/Чувствительность/Истинно-положительный результат для класса 1= Истинно-положительные результаты для класса 1/(Истинно-положительные результаты для класса 1 + Ложно-отрицательные результаты для класса 1)[ROC-кривая — Википедия]
С этой целью мы можем переместить порог вероятности на более желаемый для нас уровень. Давайте рассмотрим ROC-кривую для класса 1. Чтобы определить оптимальный порог, мы будем использовать первый тестовый набор, сохраненный ранее.
target_probabilities = grid2.predict_proba(feature_test1)
target_probabilities_class1 = target_probabilities[:,1]
roc_results = roc_curve(target_test1,target_probabilities_class1)
threshold_df = pd.DataFrame()
threshold_df['false_positive_rate'] = roc_results[0]
threshold_df['true_positive_rate'] = roc_results[1]
threshold_df['probability_threshold'] = roc_results[2]Таким образом, мы можем получить фрейм данных, в котором хранятся истинно-положительные и ложноположительные результаты с соответствующими пороговыми значениями вероятности для класса 1. Цель состоит в том, чтобы максимизировать долю истинно-положительных результатов. Давайте построим ROC-кривую, чтобы выбрать для этого подходящее пороговое значение. [Дополнительная информация].
ax.scatter(xs=threshold_df['false_positive_rate'][1:],ys=threshold_df['true_positive_rate'][1:],zs=threshold_df['probability_threshold'][1:],color='skyblue')
ax.plot(xs=[0.36,0.36],ys=[0.84,0.88],zs=[0.0,1.0],color='red')[0]
ax.plot(xs=[0.50,0.50],ys=[0.90,0.95],zs=[0.0,1.0],color='orange')[0]
ax.plot(xs=[0.60,0.60],ys=[0.94,0.98],zs=[0.0,1.0],color='green')[0]
ax.set_xlabel('\n False Positive Rate')
ax.set_ylabel('\n True Positive Rate')
ax.set_zlabel('\n Threshold')>>Выходные данные
Выходная ячейка генерирует интерактивный трехмерный график. Ниже я приложила два скриншота, на которых изображена получившаяся у нас кривая.
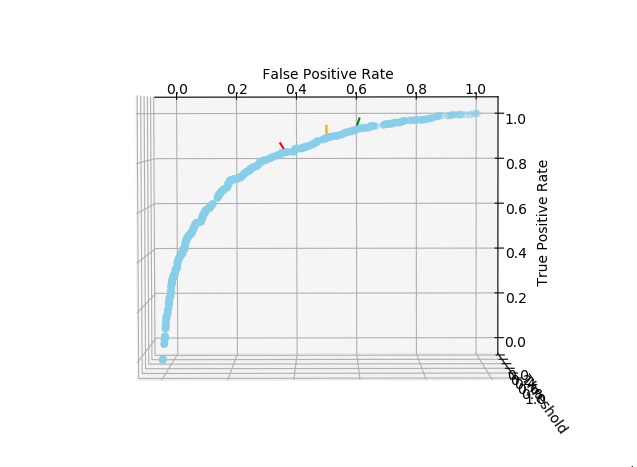
Чтобы переместить порог вероятности, нужно сначала посмотреть на ROC-кривую. Она содержит ложноположительные результаты (FPR) вдоль оси X и истинно-положительные результаты (TPR) вдоль оси Y. Нам нужно найти максимумы для TPR, не сильно увеличивая при этом FPR. Одним словом, наша задача — найти компромисс между значениями TPR и FPR.
Поиск оптимальных точек на ROC-кривой довольно субъективен и зависит от отношения клиента к FPR (как правило, отрицательного). Помня об этом, я отметила на кривой три точки красной, оранжевой и зеленой чертами.
Человек, который больше боится получить ложноположительный результат, может зафиксировать FPR на уровне около 36% (красная черта). Но если вы так поступите, то будете более уязвимы для мошенничества, чем в том случае, если бы приняли более высокое значение FPR (оранжевые и зеленые черты). Лично мне кажется оптимальным выбор зеленой черты, поскольку на коммерческих сайтах, как правило, предлагается множество вариантов для покупки.
После выбора подходящего уровня FPR, поверните график, чтобы увидеть соответствующий порог вероятности. Это должно выглядеть примерно так:
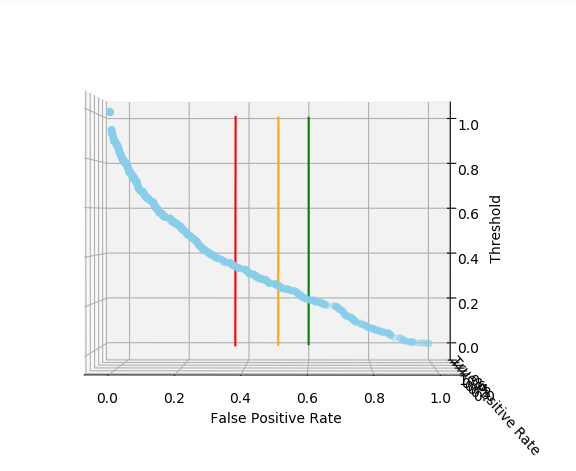
Таким образом, предпочтительными пороговыми значениями являются следующие (приблизительно):
- если вы выбрали красную черту, то 0,35;
- если оранжевую, то 0,25;
- если зеленую, то 0,20.
Итак, порог вероятности выбран. Теперь надо установить функцию для определения метрики полноты класса 1, предназначенную для другого тестового набора, на основе этого порогового значения.
def Recall_Class1(model, Chosen_threshold, feature_test_, target_test_):
target_probabilities_ = model.predict_proba(feature_test_)
target_probabilities_class1_ = target_probabilities_[:,1]
predicted_classlist_ = [1 if i >= Chosen_threshold else 0 for i in target_probabilities_class1_]
pred_test_ = pd.DataFrame()
pred_test_['Observed'] = target_test_
pred_test_['Predicted'] = predicted_classlist_
predicted_positives = 0
for i in pred_test_.index:
if pred_test_.loc[i,'Observed'] == pred_test_.loc[i,'Predicted'] and pred_test_.loc[i,'Observed'] == 1:
predicted_positives+=1
total_positives = len(pred_test_[pred_test_['Observed'] == 1.0])
Recall = predicted_positives/total_positives
return RecallМы можем вызвать эту функцию, чтобы вычислить новое значение полноты для второго тестового набора. Этот шаг имеет решающее значение для оценки эффективности сдвига порога и оптимизации прогнозирования.
for t in [0.35, 0.25, 0.20]:
print(f'Threshold = {t}, Recall = {Recall_Class1(grid2,t,feature_test2,target_test2)}')>>Выходные данные

Как видите, уровень полноты для класса 1 увеличился до 90,11%. Несомненно, это огромный прогресс по сравнению с первоначальным значением 69,77%.
Интерпретация
Итак, модель успешно обнаружила 90,11% от общего числа мошенничеств, присутствующих во внешнем тестовом наборе. Хотя ее эффективность может варьироваться в зависимости от различных тестовых наборов, процент обнаружения в данном случае кажется вполне удовлетворительным.
Читайте также:
- Как работает случайный лес?
- Где и как применить Python на практике? Три основные сферы его применения
- Обработка естественного языка для анализа отзывов онлайн-покупателей
Читайте нас в Telegram, VK и Дзен
Перевод статьи Koyel Chakraborty, Fraud Seller Detection in an Online Marketplace: Application of Random Forest Algorithm





