
Введение
Долгое время я был против использования языка R. Не только из-за того, что это не Python.
Но, поэкспериментировав с R последние несколько месяцев, понял: кое в чем R превосходит Python. Особенно он подходит для статистического анализа. Кроме того, в R есть несколько мощных пакетов, созданных крупнейшими технологическими компаниями мира. Ничего подобного нет на Python!
Рассмотрим 3 пакета R, которые стоит изучить и включить в свой арсенал инструментов (даже если вы используете только Python):
- Causal Impact (Google);
- Robyn (Facebook);
- Anomaly Detection (Twitter).
1. Causal Impact (Google)
Допустим, ваша компания хочет посмотреть, как повлияла на конверсии запущенная ею недавно телереклама Суперкубка. Библиотека Causal Impact (анализ причинно-следственных связей) позволит представить, что произошло бы, если бы рекламная кампания не проводилась. Это называется контрфактуалом (альтернативным сценарием).
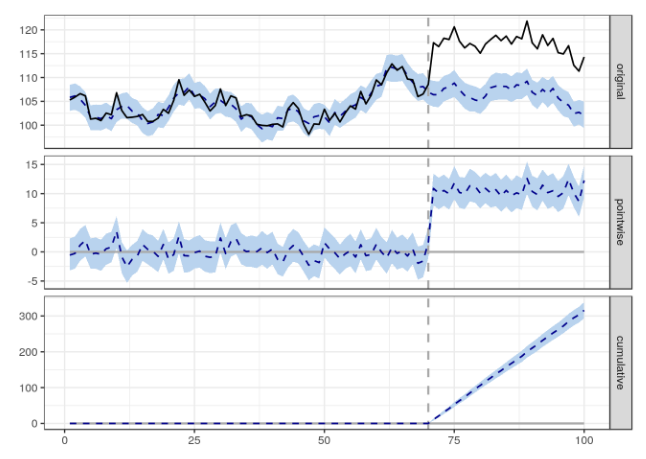
На приведенной выше визуализации пример того, как Causal Impact прогнозирует контрфактическое значение (изображенное синей пунктирной линией на верхнем графике), а затем сравнивает фактические значения с контрфактическим, чтобы оценить разницу.
Библиотека Causal Impact очень полезна для тестирования многих бизнес-кампаний, в том числе:
- маркетинговых инициатив;
- расширения деятельности в новых регионах;
- новых функций продукта.
2. Robyn (Facebook)
Моделирование маркетингового микса (МММ) — это современная технология, используемая для оценки влияния нескольких маркетинговых составляющих (каналов или кампаний) на целевую переменную, например конверсии и продажи.
Модели маркетингового микса чрезвычайно популярны, больше, чем модели атрибуции, поскольку позволяют оценить влияние таких неизмеримых каналов, как телевидение, билборды и радио.
Как правило, на построение моделей маркетингового микса с нуля уходят месяцы. Но Facebook выпустил новый пакет R под названием Robyn, который позволяет создать надежный МММ за несколько минут.
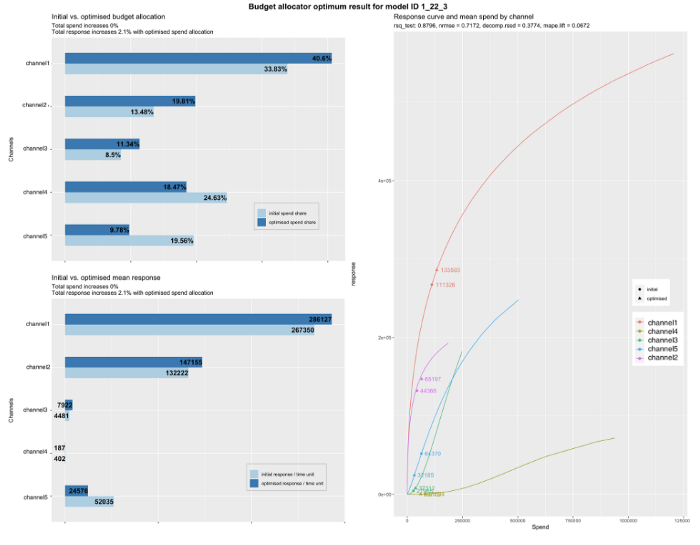
С помощью Robyn можно не только оценить эффективность каждого маркетингового канала, но и оптимизировать маркетинговый бюджет!
3. Anomaly Detection (Twitter)
Anomaly Detection (обнаружение аномалий, также известное как анализ выбросов) — это технология, позволяющая выявлять точки данных, которые значительно отличаются от остальных.
Подмножеством общего обнаружения аномалий является обнаружение аномалий в данных временных рядов, что представляет собой уникальную проблему, поскольку необходимо также учитывать тенденцию и сезонность данных.
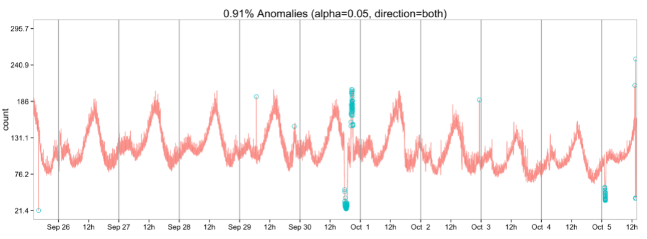
Twitter решил данную проблему, создав пакет Anomaly Detection, который делает все это за вас. Это сложный алгоритм, который может выявлять глобальные и локальные аномалии. Помимо временных рядов, он также может использоваться для обнаружения аномалий в векторе значений.
Читайте также:
- R - язык для статистической обработки данных.
- Биоинформатика? С R это легко!
- 5 крутых приемов, которые улучшат работу на R
Читайте нас в Telegram, VK и Дзен
Перевод статьи Terence Shin: Three R Libraries Every Data Scientist Should Know (Even if You Use Python)





