
Визуализация данных облегчает понимание тенденций и позволяет принимать обоснованные решения. Для оптимального представления данных важно правильно выбрать вид диаграммы. Более того, некоторые диаграммы, такие как столбиковые и многолинейные, можно дополнительно настроить для лучшего разъяснения данных.
Помимо косметических преобразований графических изображений (с помощью цвета и шрифта), можно воспользоваться дополнительными функциями, такими как общее направление линий, прогнозы и двухосевая реализация. В этой статье мы расскажем, как использовать двухосевую линейную диаграмму, чтобы более наглядно продемонстрировать аудитории корреляции и тенденции между точками данных. Мы также кратко рассмотрим, как может выглядеть обычная диаграмма без двойной оси, чтобы вы могли решить, какое из двух графических представлений максимально соответствует вашим потребностям в визуализации.
Будем использовать библиотеку Plotly для визуализации данных на Python, а также Pandas для предварительной обработки некоторых исходных данных. Поэтому убедитесь, что у вас уже установлены эти два пакета. Затем импортируйте нижеуказанные пакеты и будьте готовы следовать дальше!
import pandas as pd
import plotly.express as px
import plotly.graph_objects as go
from plotly.subplots import make_subplots
import randomПростая реализация обычной линейной диаграммы с помощью Plotly
Сначала, чтобы сгенерировать образцы данных, выполните следующий код:
expense_data = {
"Person": random.choices(["A", "B"], k=20),
"Amount": random.sample(range(100, 200), 10) + random.sample(range(0, 99), 10),
"Category": ["Groceries"] * 10 + ["Restaurant"] * 10,
"Date": pd.to_datetime(pd.date_range('2020-01-01','2020-10-01', freq='MS').tolist() * 2)
}
df = pd.DataFrame(data=expense_data)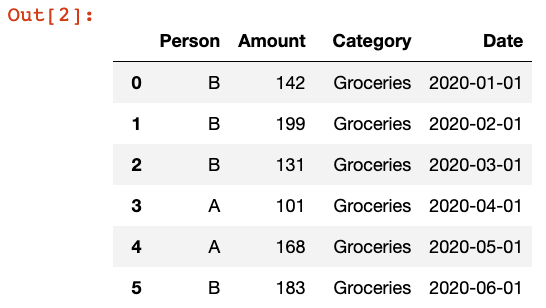
Данные, которые мы собираемся визуализировать, будут основаны на случайно сгенерированных данных о личных расходах. Как показано выше, мы создаем данные о расходах за 10 месяцев и загружаем их в Pandas DataFrame. Приведенный выше код должен вывести 20 строк данных.
Цель нашего анализа — сравнить расходы по категориям “Бакалея” и “Ресторан” в течение определенного промежутка времени. Поэтому сгруппируем данные по полям “Дата” и “Категория” с помощью нескольких строк Pandas.
df_grouped = df.groupby(by=[pd.Grouper(key="Date", freq="1M"), "Category"])["Amount"]
df_grouped = df_grouped.sum().reset_index()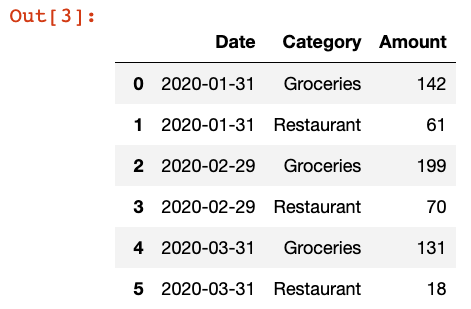
Наконец, используя всего одну строку Plotly Express, мы можем создать линейную диаграмму со сгруппированным DataFrame в качестве входных данных.
px.line(df_grouped, x="Date", y="Amount", color="Category")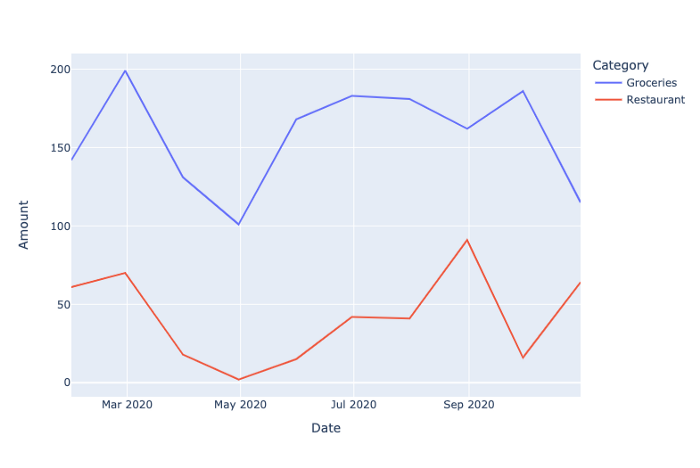
Plotly Express позволяет создать такую диаграмму всего одной строкой кода. В нее вводим DataFrame, значения оси X и Y, а также, по желанию, параметр цвета color, чтобы иметь несколько цветных линий на диаграмме — по одной для каждой категории.
Диаграмма выглядит довольно хорошо, но, как видите, сравнить две категории сложновато. По логике можно было бы ожидать, что люди в целом тратят ежемесячно больше денег на продукты питания, чем на походы в ресторан (к тому же мы жестко запрограммировали эту логику в коде, генерирующем выборочные данные, — можете перепроверить это выше).
Далее рассмотрим двухосевую реализацию, чтобы упростить сравнение двух категорий расходов.
Создание двухосевой линейной диаграммы с помощью Plotly
Прежде всего нужно создать пустую фигуру subplots с помощью make_subplots (который мы импортировали ранее). Определим также две переменные, чтобы назвать целевые категории.
# создание двойной оси и определение категорий
fig = make_subplots(specs=[[{"secondary_y": True}]])
category_1 = "Groceries"
category_2 = "Restaurant"Пока мы ничего не выводим, но стоит отметить, что в методе make_subplots мы передаем "secondary_y": True внутри specs, что позволит позже правильно реализовать двойную ось.
Теперь вручную создадим первую строку на линейной диаграмме.
# создание первой строки
fig.add_trace(
go.Scatter(
y=df_grouped.loc[df_grouped["Category"]==category_1, "Amount"],
x=df_grouped.loc[df_grouped["Category"]==category_1, "Date"],
name=category_1
),
secondary_y=False,
)Plotly Express позволяет легко сгенерировать все одной строкой, в то время как с обычной библиотекой Plotly придется написать немного больше кода. В приведенном выше фрагменте применен метод add_trace для объекта fig, который определен ранее, чтобы добавить данные из уже сгруппированного DataFrame. Мы также раннее импортировали plotly.graph_objects как go, поэтому можем передать значения столбцов X и Y. Наконец, мы настроили secondary_y на False, так как это первая линия на диаграмме.
Запустив fig.show(), вы увидите что-то вроде этого:
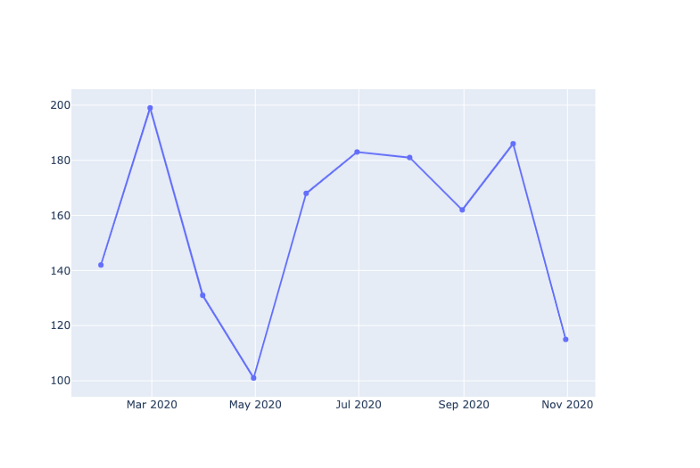
Немного упрощенно, но пока неплохо! Сейчас у нас есть только данные из категории “Бакалея”. Чтобы добавить вторую строку с данными категории “Ресторан”, выполним следующее.
# создание новой строки
fig.add_trace(
go.Scatter(
y=df_grouped.loc[df_grouped["Category"]==category_2, "Amount"],
x=df_grouped.loc[df_grouped["Category"]==category_2, "Date"],
name=category_2
),
secondary_y=True,
)Это почти тот же код, только мы используем category_2 и передаем в secondary_y=True. Снова запустив fig.show(), вы должны увидеть что-то вроде этого:
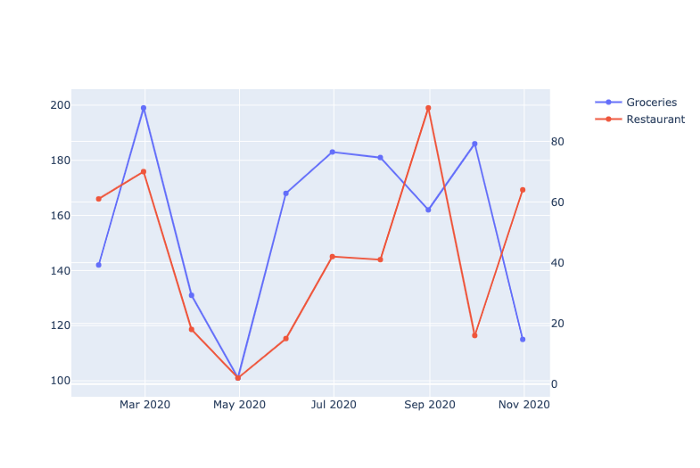
Выглядит еще лучше! В отличие от предыдущей диаграммы, тут уже лучше видно, как две категории данных о расходах ведут себя во времени относительно друг друга. Это просто случайно сгенерированные данные, но через несколько месяцев вы сможете увидеть тенденцию: когда расходы на продукты питания поднимаются, расходы на ресторан сравнительно снижаются (и наоборот).
Можно отразить эту тенденцию еще нагляднее, написав немного больше кода для добавления меток осей, например:
fig.update_yaxes(title_text=category_1, secondary_y=False)
fig.update_yaxes(title_text=category_2, secondary_y=True)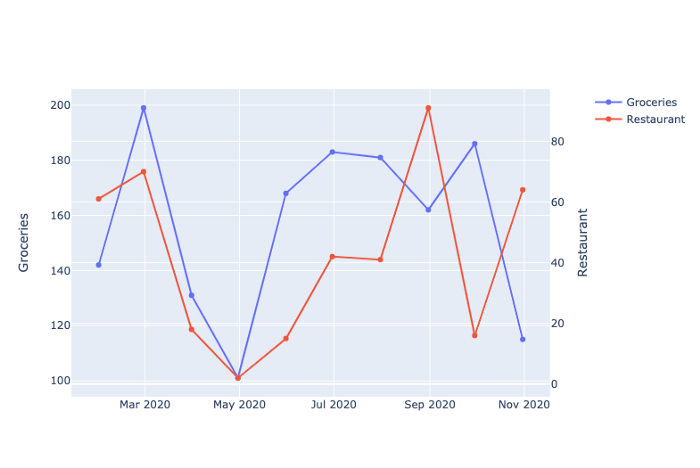
Здесь мы используем те же методы update_yaxes, но сначала передаем значение False, а затем значение True параметру secondary_y, чтобы соответствующим образом обозначить обе оси.
Пока все здорово, но стоит немного почистить код и перенести всю логику в одну функцию, пригодную для повторного использования. Вот реализация:
def create_dual_axis_graph(input_df, *args):
# создание исходного рисунка двойной оси
dual_axis_fig = make_subplots(specs=[[{"secondary_y": True}]])
# определение категорий из kwargs
categories = [*args]
assert len(categories) == 2, f"Must only provide two categories. You provided {len(categories)}."
# создание графа с циклом
for count, category in enumerate(categories):
dual_axis_fig.add_trace(
go.Scatter(
y=input_df.loc[input_df["Category"]==category, "Amount"],
x=input_df.loc[input_df["Category"]==category, "Date"],
name=category
),
secondary_y=count,
)
dual_axis_fig.update_yaxes(title_text=category, secondary_y=count)
return dual_axis_figМы делаем то же самое, что и раньше, только убираем часть повторений, которые были полезны в демонстрационных целях. Функция create_dual_axis_graph принимает input_df в качестве основного аргумента (где будет предоставлен сгруппированный DataFrame, как мы это делали ранее), затем *args в качестве имен двух категорий, которые нужно изучить.
Помещаем *args в список (проверяем, чтобы в нем было только два элемента). Затем проходим по этому списку и снова используем метод add_trace, чтобы добавить данные для осей X и Y. В этом циклическом процессе мы также будем использовать enumerate, чтобы в параметр secondary_y у методов add_trace и update_yaxes можно было передать либо 0, либо 1 (что является булевым значением), как мы делали ранее.
Запуск функции осуществляем всего одной строкой:
create_dual_axis_graph(df_grouped, "Groceries", "Restaurant").show()
У вас получится точно такая же двухосная диаграмма. Чтобы увидеть, как может выглядеть неправильная реализация, попробуйте это:
create_dual_axis_graph(df_grouped, "Groceries", "Restaurant", "Appliances").show()
Ранее мы определили AssertionError для передачи в список категорий только двух аргументов. Вы также можете определить более полный шаг проверки данных, чтобы убедиться в следующем:
- есть ли в DataFrame нужные столбцы;
- имеют ли значения столбцов нужные типы данных;
- действительно ли предоставленные категории находятся в DataFrame.
Однако для данного демонстрационного материала будет достаточно приведенной выше функции.
Вот и все, друзья!
Надеемся, что этот быстрый анализ данных и демонстрация визуализации были полезны для вас! Двухосная диаграмма позволяет действительно легко сравнивать две категории, не обязательно находящихся в одном масштабе.
Читайте также:
- Работа с панелью индикаторов. Руководство программиста Python
- Создание анимации Gapminder двумя строчками кода с помощью Plotly Express
- Создание дашбордов в Dash
Читайте нас в Telegram, VK и Дзен
Перевод статьи Byron Dolon: Better Data Visualization with Dual Axis Graphs in Python




