
Архитектура системы высокого уровня Netflix
Мы все знакомы с сервисами Netflix. Компания предлагает широкий спектр кино- и телепродуктов, и пользователи готовы ежемесячно вносить абонентскую плату за доступ к этому контенту. У Netflix более 180 миллионов подписчиков в более чем 200 странах.
Netflix осуществляет свою деятельность на двух облачных платформах: AWS и Open Connect. Обе они работают одновременно как высокопропускная сетевая магистраль Netflix. Обе отвечают за обеспечение подписчикам высококачественным видео.
Основу приложения Netflix составляют 3 компонента:
- Клиент: Устройство (пользовательский интерфейс) для просмотра и воспроизведения видео Netflix. В качестве подобных девайсов могут использоваться телевизор, XBOX, ноутбук, мобильный телефон и т. д.
- OC (Open connect) или CDN Netflix: CDN — это сеть серверов, распределенных по разным географическим точкам; Open Connect — это собственная глобальная CDN Netflix (сеть доставки контента). Она обрабатывает все, что связано с потоковой передачей видео в разных точках мира. Как только вы нажмете кнопку воспроизведения, видеопоток из этого компонента отобразится на вашем устройстве. Если вы хотите воспроизвести видео, находясь в Северной Америке, видеопоток будет передаваться с ближайшего открытого подключения (или сервера) вместо исходного сервера (более быстрый ответ с ближайшего сервера).
- Серверная часть (база данных): В этой части обрабатывается все, что не связано с потоковой видеопередачей (до того, как вы нажмете кнопку воспроизведения), например, ввод нового контента, его обработка и распространение на серверах, расположенных в разных частях мира, управление сетевым трафиком. Большинство этих процессов выполняются веб-службами Amazon.
Интерфейс Netflix написан на ReactJS по трем основным причинам:
- скорость запуска;
- производительность;
- модульность.
Теперь уделим внимание каждому компоненту Netflix и посмотрим, как работает вся система.
Как Netflix загружает фильм/видео?
Netflix получает сверхкачественный контент от кино- и телепроизводителей. Прежде чем показывать видео пользователям, компания выполняет его предварительную обработку. Netflix поддерживает более 2200 устройств, у каждого из которых свои требования по разрешению и формату. Чтобы сделать видео доступным для просмотра на разных устройствах, Netflix выполняет перекодирование или кодирование, которое включает в себя поиск ошибок и адаптирование исходного видео к различным форматам и разрешениям.
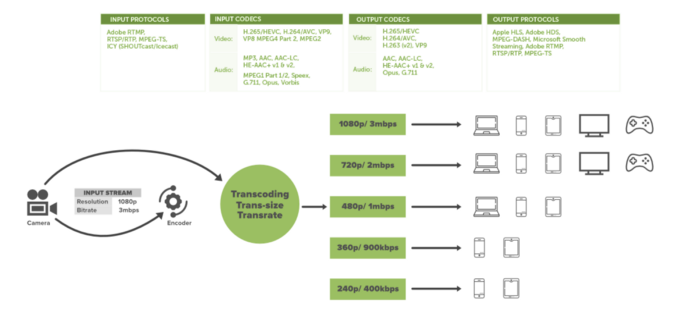
Netflix также создает файлы, оптимизированные под различные скоростные возможности сети. Чем выше скорость сети, тем лучше качество видео. Netflix создает несколько реплик (примерно 1100–1200) для одного и того же фильма с разным разрешением. Эти реплики требуют большого количества перекодировок и предварительных обработок. Netflix разбивает исходное видео на мелкие фрагменты и с помощью параллельных рабочих процессов в AWS преобразует каждый из них в том или ином формате (например, mp4, 3gp) и разрешении (например, 4k, 1080p).
Полученные после перекодирования несколько копий файлов одного и того же фильма передаются на сервера Open Connect, расположенные в разных местах по всему миру.
Когда пользователь загружает приложение Netflix на свое устройство, сначала появляются экземпляры AWS. На них возлагается ряд задач:
- вход в систему;
- рекомендации;
- поиск;
- пользовательская история;
- домашняя страница;
- выставление счетов;
- поддержка клиента.
Когда пользователь нажимает кнопку воспроизведения видео, Netflix анализирует скорость сети и стабильность соединения. Затем определяется ближайший к пользователю и наиболее подходящий для его устройства открытый сервер подключения. Отсюда на пользовательское устройство передается видео в формате, соответствующем типу устройства и размеру экрана. Возможно, вы замечали, что иногда во время просмотра видео изображение становится мозаичным и через некоторое время возвращается в HD. Это происходит потому, что приложение продолжает искать подходящий сервер потокового открытого подключения и перебирает различные форматы (для лучшего просмотра), когда это необходимо.
В AWS сохраняются некоторые пользовательские данные, например:
- поисковые запросы;
- просмотры;
- местоположение;
- применяемые устройства;
- отзывы;
- лайки.
Netflix собирает их для создания рекомендаций по фильмам, а также для пользователей моделей машинного обучения или Hadoop.
Преимущества Open Connect:
- меньше затрат;
- выше качество;
- более высокая масштабируемость.
Теперь, после рассмотрения работы системы Netflix, пора познакомиться с особенностями ее дизайна.
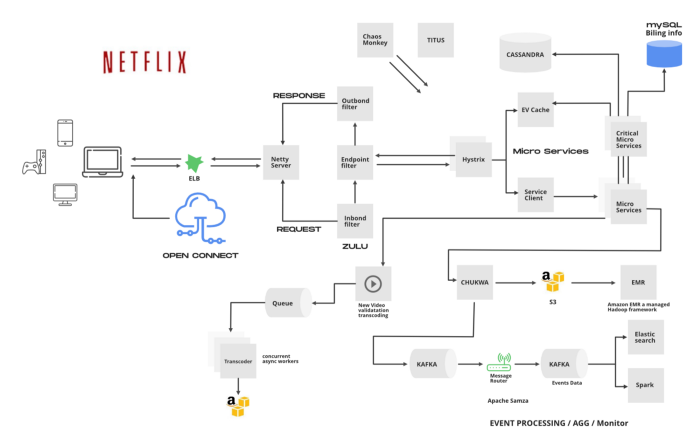
1. ELB
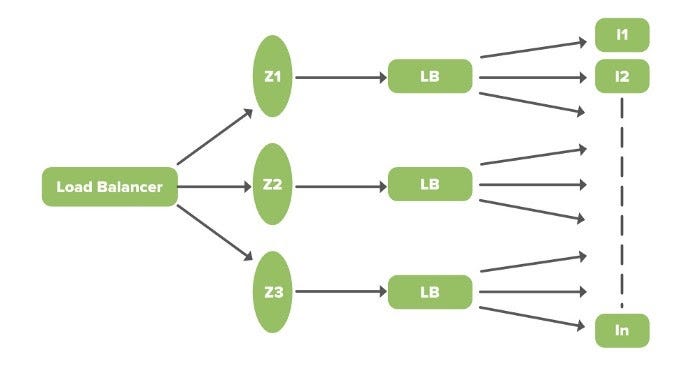
ELB (Elastic Load Balancer; упругий балансировщик нагрузки) в Netflix отвечает за маршрутизацию трафика на интерфейсные сервисы. Сначала нагрузка распределяется по зонам, а затем по экземплярам (серверам). Двухуровневая схема балансировки нагрузки работает следующим образом:
- Первый уровень отвечает за базовую циклическую балансировку нагрузки, основанную на DNS. Попадая на этот уровень (см. схему выше), запрос путем циклического алгоритма находит оптимальное соотношение с одной из зон, на использование которой настроен ELB.
- Второй уровень обеспечивает циклическую балансировку нагрузки в массиве экземпляров. Здесь запрос распределяется между соответствующими экземплярами, находящимися в пределах одной и той же зоны.
2. ZUUL
ZUUL — это сервис шлюзов, который обеспечивает динамическую маршрутизацию, мониторинг, отказоустойчивость и безопасность системы. Он отвечает за беспрепятственное прохождение трафика с учетом параметров запросов, URL-адресов, путевых имен.
Разберемся в работе его частей:
- Сервер Netty обеспечивает обработку сетевого протокола, связь с веб-сервером, управление подключениями и проксированием. С сервера Netty запросы перенаправляются на входящие фильтры.
- Входящие фильтры отвечают за аутентификацию, маршрутизацию или оформление запросов. Затем они перенаправляют запросы в фильтры конечных точек.
- Фильтры конечных точек используются для возврата статического ответа или пересылки запроса в серверную службу (или источник, как мы ее называем). При получении ответа от серверной службы, запросы отправляются в фильтры исходящего трафика.
- Фильтры исходящего трафика используются для архивирования контента, вычисления показателей или добавления/удаления настраиваемых заголовков. После этого ответ отправляется обратно на сервер Netty, а затем принимается клиентом.
Преимущества ZUUL:
- Создание правил разделения трафика и распределение разных его частей по разным серверам.
- У разработчиков есть возможность выполнять нагрузочное тестирование в недавно развернутых кластерах на нескольких машинах. Они также могут маршрутизировать определенный трафик в эти кластеры и проверить нагрузку, которую способен выдержать конкретный сервер.
- Командам разработчиков предоставляется возможность протестировать работу новых/обновленных сервисов с запросами API в режиме реального времени: можно развернуть конкретный сервис на отдельном сервере и перенаправить часть трафика на новый сервис для проверки его работы в режиме реального времени.
- Установка настраиваемых правил в фильтре конечных точек или брандмауэре позволяет отфильтровать неверные запросы.
3. Hystrix
В сложной распределенной системе один сервер может зависеть от ответа другого сервера. Взаимозависимости между этими серверами способны приводить к временным задержкам. Кроме того, вся система может перестать работать, если в какой-то момент один из серверов внезапно выйдет из строя. Чтобы решить эту проблему, необходимо застраховать host-приложение от внешних сбоев. Библиотека Hystrix предназначена как раз для выполнения этой задачи. Она помогает контролировать взаимодействие между распределенными службами путем внесения в систему логики допуска задержек и отказоустойчивости. Hystrix делает это, изолируя точки доступа между службами, удаленной системой и сторонними библиотеками.
Hystrix позволяет:
- предотвращать каскадные сбои в сложной распределенной системе;
- отслеживать задержки и сбои во взаимозависимых серверах, к которым осуществляется доступ (обычно по сети) через сторонние клиентские библиотеки;
- осуществлять быстрое прекращение и оперативно возобновлять работу;
- переходить в аварийный или низкофункциональный режим, когда это возможно;
- проводить мониторинг, оповещение и оперативный контроль в близком к реальному времени;
- вести кэширование запросов с учетом параллелизма и автоматическое пакетирование с помощью сворачивания запросов.
4. Микросервисная архитектура Netflix
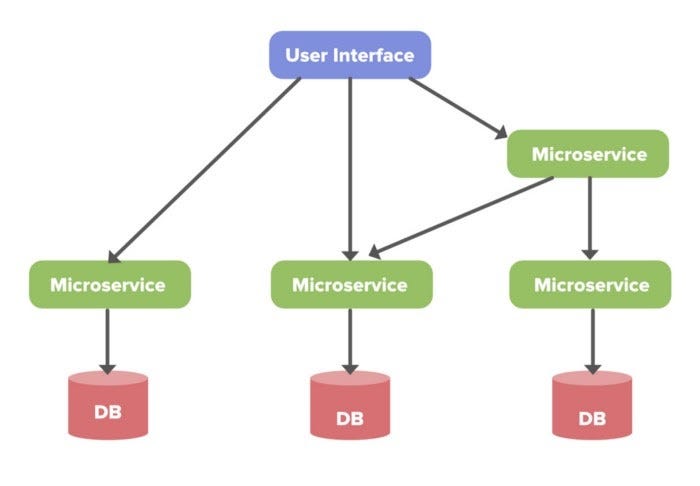
Архитектурный стиль Netflix создан как коллекция служб. Такая микросервисная архитектура обеспечивает поддержку всех API, необходимых для мобильных и веб-приложений. Поступая в конечную точку, запрос вызывает другие микросервисы для получения необходимых данных. Эти микросервисы также могут запрашивать данные у различных микросервисов. После этого полный ответ на запрос API отправляется обратно в конечную точку.
В микросервисной архитектуре все службы должны быть независимы друг от друга. Например, служба хранения видео будет отделена от службы, ответственной за перекодирование видео.
Что делает микросервисную архитектуру надежной:
- Использование Hysterix (объяснение дано выше).
- Разделение критически важных микросервисов: Можно выделить некоторые критически важные службы (конечные точки/API) и сделать их менее зависимыми или независимыми от других служб. Можно также сделать некоторые важные службы зависимыми только от других надежных служб. При выборе важных микросервисов следует включить все основные функции, такие как поиск видео, переход к видео, нажатие и воспроизведение видео. Так обеспечивается максимальный доступ к конечным точкам, и даже в наихудших ситуациях пользователь сможет выполнять хотя бы основные действия.
- Отношение к серверам как к не сохраняющим состояние: Эта концепция может показаться странной. Чтобы понять ее, сравните свои серверы со стадом коров и признайте, что вам небезразлично, сколько литров молока вы получаете каждый день. Если однажды вы заметите, что надоили меньше молока от коровы, вам просто следует заменить эту корову (производящую меньше молока) другой коровой. Вам не нужно зависеть от конкретной коровы, чтобы получить необходимое количество молока. Теперь вам будет легче связать этот пример с приложением Netflix. Ее службы спроектированы таким образом, что, если одна из конечных точек выдает ошибку или не обслуживает запрос своевременно, можно переключиться на другой сервер и выполнить свою работу. Вместо того, чтобы полагаться на определенный сервер и сохранять состояние на этом сервере, можно направить запрос на другой экземпляр службы и автоматически запустить новый узел для его замены. Если сервер перестанет работать, он будет заменен другим.
5. Кэш EV
В большинстве приложений обычно используется определенный объем данных. Для более быстрого ответа эти данные могут быть кэшированы во многих конечных точках и могут быть извлечены из кэша без участия исходного сервера. Это снижает нагрузку с исходного сервера, но проблема в том, что если узел выходит из строя, весь кэш выходит из строя, и это может повлиять на производительность приложения. Чтобы решить эту проблему, Netflix создала свой собственный слой кэширования, называемый Кэш EV. Основанный на Memcached, Кэш EV, по сути, является оболочкой Memcached.
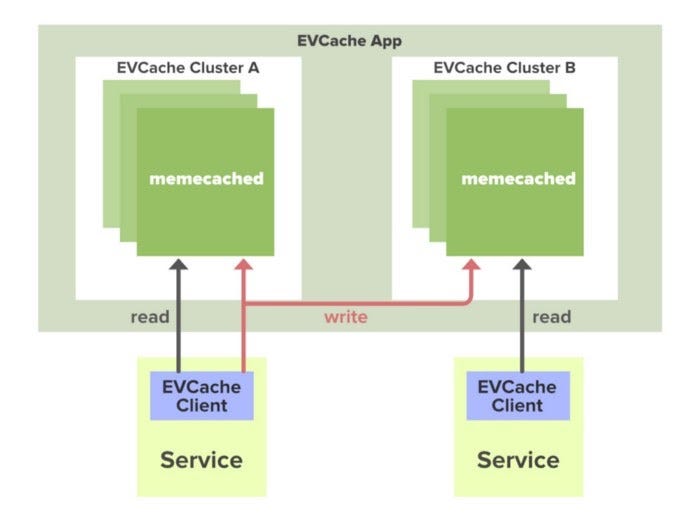
Netflix развернул множество кластеров в ряде экземпляров AWS EC2. В этих кластерах много узлов Memcached, а также клиентов кэша. Данные распределяются по кластеру в пределах одной зоны; несколько копий кэша хранятся в разделенных узлах. Каждый раз, когда производится запись из клиента, все узлы во всех кластерах обновляются, но чтение, которое выполняется из кэша, отправляется только в ближайший кластер (не во все кластеры и узлы) и его узлы. В случае, если узел недоступен, считывание данных осуществляется с другого доступного узла. Такой подход повышает производительность, доступность и надежность.
6. База данных
Netflix использует для разных целей две базы данных — MySQL(RDBMS) и Cassandra(NoSQL)
MySQL с развертыванием EC2
Netflix сохраняет в MySQL данные о биллинге, пользователях и транзакциях, поскольку эта библиотека соответствует требованиям ACID. Netflix создала для MySQL настройку “ведущий-ведущий” и развернула ее на крупных экземплярах Amazon EC2 с использованием InnoDB.
Настройка выполняется по “Протоколу синхронной репликации”, в соответствии с которым запись, произведенная на основном ведущем узле, реплицируется на другой ведущий узел. Подтверждающее уведомление отправляется только в случае подтверждения записи, произведенной как на основном, так и на удаленном ведущих узлах. Это обеспечивает высокую доступность данных.
Netflix настроила реплику чтения для каждого узла (как локального, так и межрегионального). Это гарантирует не только высокую доступность, но и масштабируемость.
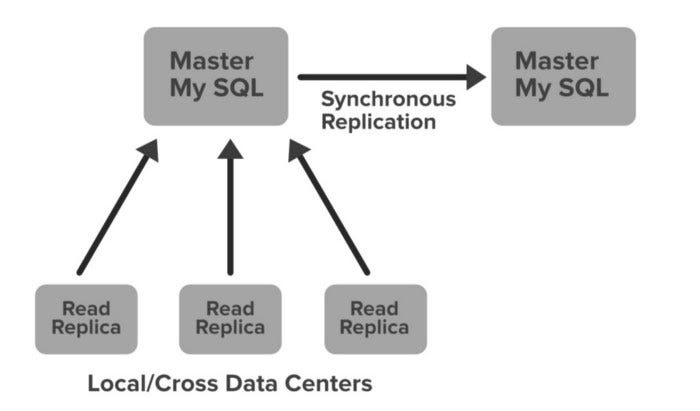
Все запросы на чтение перенаправляются на реплики чтения, и только запросы на запись перенаправляются на ведущие узлы. В случае сбоя первичного ведущего узла MySQL, вторичный ведущий узел возьмет на себя основную роль, и запись route53 (конфигурация DNS) для базы данных будет изменена на этом новом первичном узле. Запросы на запись также будут перенаправлены на этот новый первичный ведущий узел.
Cassandra
Cassandra — это база данных NoSQL, которая может обрабатывать большие объемы информации, а также интенсивно выполнять запись и чтение. Когда Netflix начала приобретать больше пользователей, данные истории просмотров каждого участника также начали увеличиваться. В результате возросло общее количество данных историй просмотров, и Netflix стало сложно обрабатывать такой огромный объем данных. Netflix изменила масштаб хранилища данных историй просмотров, преследуя две основные цели:
- уменьшение объема памяти;
- достижение стабильной производительности чтения/записи по мере увеличения количества просмотров на одного участника (соотношение записи и чтения данных историй просмотров в Cassandra составляет примерно 9:1).
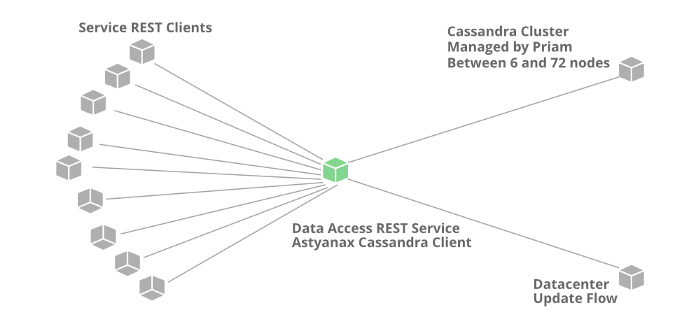
Совокупная денормализованная модель данных:
- более 50 кластеров Cassandra;
- более 500 узлов;
- более 30 ТБ ежедневных резервных копий;
- самый большой кластер — 72 узла;
- 1 кластер — более 250 тыс. записей в секунду.
Изначально история просмотров хранилась в Cassandra в одной строке. Когда количество пользователей Netflix начало расти, размеры строк, а также общий массив данных увеличились. Это привело к увеличению объема хранилища, росту эксплуатационных затрат и снижению производительности приложения. Решением проблемы стало сжатие старых строк.
Netflix разделил данные на две части:
- Истории просмотров в реальном времени (LiveVH): В этот раздел включено небольшое количество последних данных о просмотрах пользователей с частыми обновлениями. Данные обычно используются для выполнения ETL-задач и хранятся в несжатом виде.
- Сжатые истории просмотров (CompressedVH): В этом разделе классифицировано большое количество старых записей о просмотрах с редкими обновлениями. Данные хранятся в одном столбце для каждого ключа строки в сжатом виде, чтобы уменьшить объем памяти.
7. Обработка данных в Netflix с использованием Kafka и Apache Chukwa
Когда вы включаете видео, на обработку данных у Netflix уходит менее наносекунды. Как же протекает конвейерная обработка данных на Netflix?
Netflix использует Kafka и Apache Chukwa для приема данных, которые создаются в другой части системы. Netflix обеспечивает обработку почти 500 миллиардов событий, потребляющих 1,3 ПБ/сут. В пиковое время обрабатываются 8 миллионов событий, потребляющих 24 ГБ/сек.
Эти события включают в себя следующую информацию:
- журналы ошибок;
- действия пользовательского интерфейса;
- события производительности;
- мероприятия по просмотру видео;
- устранение неполадок и диагностические мероприятия.
Apache Chukwa — это система с открытым исходным кодом для сбора данных в виде журналов или событий из распределенной системы. Она создана на основе HDFS и фреймворка Map-Reduce. Система поставляется платформой Hadoop с функциями масштабируемости и устойчивости. Кроме того, она включает в себя множество мощных и гибких инструментов для отображения, мониторинга и анализа результатов. Chukwa собирает события из разных частей системы. С помощью Chukwa можно осуществлять мониторинг, анализ или использовать панель мониторинга для просмотра событий. Chukwa записывает события в формате последовательности файлов Hadoop (S3). После этого команда Больших Данных обрабатывает эти файлы Hadoop S3 и записывает в Hive в формате данных Parquet. Этот процесс называется пакетной обработкой, которая в основном сканирует все данные с почасовой или ежедневной частотой.
Чтобы загружать онлайн-события в EMR/S3, Chukwa также направляет трафик на Kafka (главный пропускной пункт в обработке данных в режиме реального времени). Kafka отвечает за перемещение данных с фронтального кластера Kafka в различные приемники: S3, Elasticsearch и вторичный кластер Kafka. Маршрутизация этих сообщений выполняется с помощью платформы Apache Samja. Трафик, отправляемый Chukwa, доставляется полными или отфильтрованными потоками, поэтому иногда может потребоваться дополнительная фильтрация потоков Kafka. Именно по этой причине мы рассматриваем маршрутизатор для перехода от одной темы Кафки к другой.
8. Эластичный поиск
В последние годы мы наблюдаем значительный рост использования Elasticsearch в Netflix. Netflix запускает примерно 150 кластеров эластичного поиска и 3500 хостов с экземплярами.
Netflix использует эластичный поиск для визуализации данных, поддержки клиентов и обнаружения некоторых ошибок в системе. Например, если клиент не может воспроизвести видео, работник техподдержки решит эту проблему. Команда Playback перейдет к эластичному поиску и найдет пользовательское устройство. Получив полную информацию и проанализировав события, относящиеся к этому конкретному пользователю, специалисты определят, что вызвало ошибку в видеопотоке. Эластичный поиск также используется администрацией для отслеживания некоторой информации. Кроме того, его применяют для мониторинга используемых ресурсов и обнаружения проблем с регистрацией или входом в систему.
9. Apache Spark для рекомендации фильмов
Netflix использует Apache Spark и машинное обучение для рекомендаций фильмов. Разберемся, как это работает, на примере. Когда вы загружаете первую страницу, вы видите несколько строк, состоящих из названий различных фильмов. Netflix персонализирует эти данные и решает, какие строки с какими фильмами должны отображаться конкретному пользователю. Эта информация основана на данных пользовательских историй и предпочтений. Кроме того, для каждого пользователя Netflix выполняет сортировку фильмов и определяет рейтинг релевантности (для рекомендаций) фильмов, доступных на платформе.
Apache Spark используется Netflix для рекомендаций по контенту и персонализации. Большинство конвейеров машинного обучения выполняются на больших Spark-кластерах. Эти конвейеры затем используются для выбора строк, их сортировки, ранжирования релевантности заголовков и персонализации художественных произведений.
Персонализация художественных произведений
Открывая главную страницу Netflix, вы наверняка замечали изображения к каждому видео. Эти картинки называются изображениями заголовка (эскизами). Netflix стремится получить максимальное количество пользовательских кликов для каждого видео, а эти клики зависят от изображений заголовков. Netflix должен выбрать самое привлекательное изображение заголовка для конкретного видео. Для этого Netflix создает несколько художественных изображений для определенного фильма и представляет их пользователям в произвольном порядке. Изображения к одному и тому же фильму могут быть разными для разных пользователей. Основываясь на ваших предпочтениях и истории просмотров, Netflix пытается понять, какие фильмы/актеры вам нравятся больше всего. В соответствии с вашими вкусами, у вас будут отображаться те или иные изображения.
Предположим, вы видите 9 различных изображений к вашему любимому фильму “Умница Уилл Хантинг”, расположенных в три ряда (если вам нравятся комедии, то будут показаны изображения Робина Уильямса из этого фильма; если вы любитель романтических фильмов, то Netflix покажет вам образы Мэтта Деймона и Минни Драйвер). Затем Netflix вычисляет количество кликов, которые получает определенное изображение. Если количество кликов по центральному изображению фильма составит 1 500, а другие изображения наберут меньше кликов, то Netflix навсегда сделает центральное изображение в качестве заголовка для фильма “Умница Уилл Хантинг”. Этот подход называется “ориентация на данные”, и Netflix выполняет анализ данных с его помощью. Для принятия правильного решения данные рассчитываются на основе количества просмотров, связанных с каждой картинкой.
Система рекомендаций видео
Система рекомендаций Netflix помогает пользователям находить свои любимые фильмы или видео. Чтобы создать эту систему, Netflix прогнозирует интересы пользователей, собирая различные виды пользовательских данных:
- взаимодействие каждого пользователя с сервисом (история просмотров и оценки);
- отслеживание других участников с аналогичными вкусами и предпочтениями;
- метаданные из ранее просмотренных пользователем видео (названия, жанры, категории, актеры, годы выпуска фильмов и т.д.);
- устройство пользователя, в какое время он более активен и как долго.
Netflix использует два разных алгоритма для построения системы рекомендаций:
- Совместная фильтрация: Идея этой фильтрации заключается в том, что если у двух пользователей одинаковая история рейтингов, то в будущем они будут вести себя одинаково. Логика простая: если одному из этих двух людей фильм понравился (он поставил ему хорошую оценку), значит, с большой вероятностью его “напарник” сделает то же самое.
- Фильтрация на основе контента: Идея состоит в том, чтобы отбирать для конкретного пользователя видео, похожие на те, которые понравились ему раньше. Фильтрация на основе контента сильно зависит от детальной информации о продукте, такой как название фильма, год выпуска, актеры, жанр и т. п. Поэтому для ее реализации важно собрать максимум данных о продукте, а также изучить профиль пользователя с описанием его предпочтений.
Заключение
Именно так Netflix, YouTube и аналогичные приложения для потоковой передачи видео отслеживают и загружают свой контент, чтобы показать его миллионам пользователей. Некоторые из этих приложений обладают какими-то специфическими функциями, которые делают их уникальными, но основной функционал подчиняется схожим алгоритмам.
Читайте также:
- Чем веб-дизайн отличается от front end разработки?
- 17 успешных примеров дизайна логотипов для различных бизнес-целей
- Психологические принципы для продуктового дизайнера
Читайте нас в Telegram, VK и Дзен
Перевод статьи Aditya Gupta, Netflix System Design




