
Аналитический труд всегда читается больше одного раза. Поговорим о том, как добиться удобного и надежного обмена проектами в области Data Science с повторным применением коллективных наработок спустя годы.
Специалисты в области науки о данных много времени тратят на продуктовую аналитику. Несмотря на широкий спектр доступных программных инструментов, таких как Jupyter Notebook с Python, Tidyverse, Superset и даже Java UDFs, продуктовая аналитика все равно нуждается в SQL.
Но как происходит сама работа с SQL, где записываются команды и запросы? Например, сначала — написание запроса во встроенной IDE Superset и внесение правок до момента ответа на поставленный вопрос, затем — внесение результатов в Google Doc вместе с другими документами.
А в итоге — отправка результатов через электронное письмо или сообщение в Slack и полное исчезновение в море корпоративного шума.
Содержание руководства:
- Проблематика командной работы в Data Science.
- Разбор нарушений в обмене наработками.
- Замкнутый цикл благодаря открытым записям.
1. Проблематика командной работы в Data Science
Как и следовало ожидать, спустя недели или месяцы продуктовый аналитик сталкивается с подобными вопросами организации рабочего процесса и, не найдя в памяти свои прошлые работы, переписывает один и тот же SQL-запрос. В результате можно прийти к пониманию суровой истины:
Самое трудное в работе аналитика — это не выполнение работы, а ее повторение на следующей неделе.
Из руководства вы узнаете, как решить проблему с регулярным переписыванием одних и тех же запросов.
Ода давно забытым достоинствам организованного сотрудничества в аналитических командах, любовное письмо современному рабочему пространству документов (а-ля Notion, Dropbox Paper, Confluence и т. д.), а также взгляд на мотивацию нового рабочего пространства документов для аналитиков, hyperquery.
Но сперва обсудим поломку, а потом уже попытаемся ее исправить.
2. Разбор нарушений в обмене наработками
После того, несколько SQL-запросов уже написаны, найдены идеи, работа сделана — в душе вы уже знаете, что теперь вам предстоит сделать свою работу понятной для окружающих (хотя, возможно, время от времени вы пытаетесь заглушить напоминание).
Поэтому лучшие из нас напишут Google-документ, документирующий идеи и SQL-запросы, а затем поделятся им через электронное письмо или Slack, чтобы коллеги ознакомились с результатами. “Научное сотрудничество, свершилось!” — вы можете подумать, но описанный рабочий процесс представляется следующим образом:
- Ответ на вопрос.
- Написание работы.
- Распространение результатов.
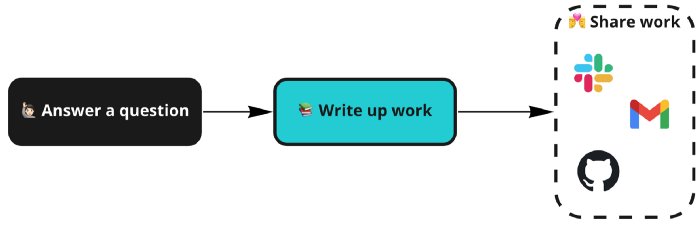
Именно на этапе обмена результатами дела принимают мрачный оборот (зловещие пунктирные линии на диаграмме выше). Этап передачи инсайта полностью во власти инструментов, хорошо подходящих для точечного обмена, в ущерб последующей воспроизводимости.
Slack, Gmail? Не начинайте рассказывать про Github для обмена инсайтами. Сегодня какие-то сервисы популярны, а завтра — их нет, не говоря уже о том, что они совершенно не подходят в качестве платформ для воспроизведения SQL. И где проблема? Проблема в том, что жизненный цикл результатов работы аналитика данных редко заканчивается на этапе презентации, зачастую ваши труды продолжают жить как часть процесса разработки следующих аналитических проектов.
Оставив команде лишь след доказательств, что уже выработали над проблемой раньше, вы уже считаете свою работу завершенной. На самом деле вы оставляете коллегам не более чем хлебные крошки, по которым они смогут найти наработки, когда они снова станут актуальны. Воспроизводимость критически важна для масштабирования аналитических организаций, но именно здесь и кроется суть проблемы.
Напрасные и повторные усилия возникают в результате потери знаний.
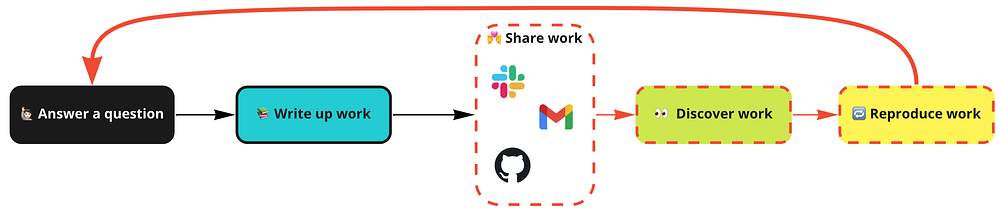
Как выглядит стандартный, ничем не нарушенный процесс доставки инсайта? Ответ на вопрос, написание решения, распространение решения среди коллег, после чего все наработки обнаруживаются и воспроизводятся при необходимости.
3. Замкнутый цикл благодаря открытым записям
Универсальное средство от разрыва в цикле весьма простое — замкнуть цикл, а замыкается цикл разработки инструментом, способным удобно организовать и быстро обнаружить аналитические работы прошлого.
Хотя это и не новаторство, но замечательное (хотя и частичное, об этом позже) решение проблемы — современные рабочие пространства документов, вроде Confluence, Notion, Dropbox paper и Hyperquery. Они предлагают пользователям возможность не просто записывать, но и организовывать результаты в осмысленном для всей команды контексте.
Более того, богатые возможности поиска по рабочим пространствам документов позволяют находить информацию гораздо легче, чем в блокнотах с поддержкой Git. Проблематика может показаться незначительной, однако пользовательский опыт улучшается существенно.
Там, где раньше оставался лишь тонкий след из шепота сообщений Slack, ведущий к непонятному документу из облака Google, теперь представлен альманах SQL-запросов, инсайтов и принятых в результате работы бизнес-решений.
Более оптимальный, замкнутый цикл разработки, обеспечиваемый надежным и современным совместным пространством:
- Ответ на вопрос.
- Написание аналитики.
- Обнаружение результатов коллегами.
- Воспроизведение аналитики.
- Ответ на вопрос.
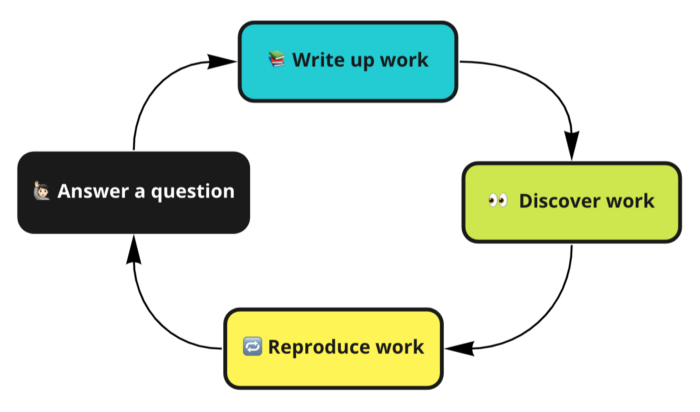
Хорошая доступность наработок — это не просто незначительная часть поведенческого дизайна в жизни аналитиков, а ключ к плодотворному аналитическому сотрудничеству.
Инновации последних лет в области совместной работы нацелены на легкость и доступность широкого спектра возможностей для технического сотрудничества, как в Google Colab. Правда, подобный инструментарий тяжело назвать удобным именно для продолжительной совместной работы команды аналитиков.
Сотрудничество — это не просто два собранных в одном месте пользователя, пишущих запросы на SQL, Python или R.
Аналитическое сотрудничество — это обмен знаниями, доступность и воспроизводимость наработок.
Hyperquery, новое рабочее пространство документов, еще сильнее замыкает цикл разработки, позволяя писать SQL и обмениваться знаниями в рамках единой экосистемы. Но было бы упущением отсутствие упоминаний о других вариантах.
Если экосистема Google Docs для вас привычна, то вам подойдет Library. Для рабочих процессов на базе Jupyter Notebook пригодится knowledge-repo от Airbnb, хотя трения вокруг парадигмы обмена знаниями на базе Git весьма болезненны.
Какой бы инструмент вы ни выбрали, согласитесь, что улучшение и ускорение обмена знаниями — важный шаг в сокращении избыточной работы. Ешьте овощи, тщательнее продумывайте места для хранения наработок и повышайте уровень своей команды аналитиков!
Выводы
- Всегда записывайте свои SQL-запросы.
- Поместите записи в такое место (рабочее пространство документа), где их легко и удобно искать не только вам.
Ключ к сокращению повторной работы заключается в заблаговременном облегчении поиска прошлых наработок, а рабочее пространство документов, вроде Confluence, Notion, Dropbox paper и Hyperquery — это полезный, востребованный каждым аналитиком данных инструмент.
Читайте также:
- 6 SQL-запросов, о которых должен знать каждый дата-инженер
- Кэширование в связке Spring Boot + Redis + PostgreSQL
- Основы SQLite на примере практической задачи
Читайте нас в Telegram, VK и Дзен
Перевод статьи Robert Yi: Why You Should Rethink Where You Write Your SQL





