
Знание продвинутого синтаксиса SQL необходимо и новичку, и опытному дата-инженеру или аналитику данных.
В связи с бурным ростом объема данных все более важным становится умение очень быстро их анализировать.
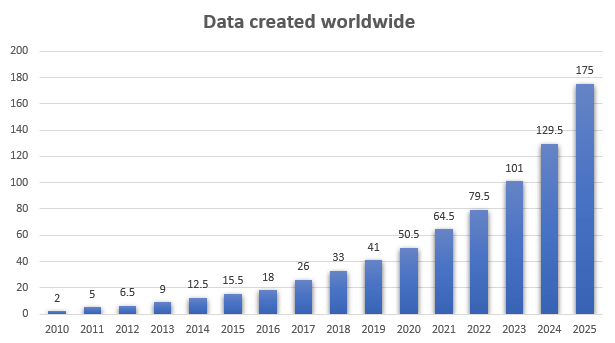
Объем данных на этом графике показан в зеттабайтах.
1 зеттабайт = 1 триллион гигабайтовЕсть много очень вместительных нереляционных хранилищ, которые отлично выполняют свою работу, поддерживая массовое горизонтальное масштабирование с низкими затратами. Однако они не заменяют высококачественные хранилища на основе SQL, а лишь дополняют их.
Высококачественными и очень надежными для относительно естественного моделирования данных их делают ACID-свойства SQL.
Я и сам дата-инженер, давно использую SQL и знаю, как важно быстрее писать сложные запросы. И продвинутый синтаксис SQL будет здесь очень кстати.
В примерах использованы данные таблицы bill («Счет»):
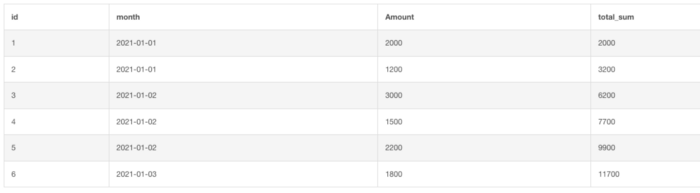
Нарастающий итог
На практике часто приходится подсчитывать нарастающий итог по таблице, т. е. как меняется промежуточная сумма каждый раз при добавлении нового значения.
Нарастающим итогом называется сумма значений во всех ячейках столбца до следующей ячейки в этом конкретном столбце.
Вот запрос на эту сумму:
SELECT id,month
, Amount
, SUM(Amount) OVER (ORDER BY id) as total_sum
FROM billА вот как будет выглядеть результат:
Обобщенные табличные выражения
Обобщенные табличные выражения используются ради большего удобства для восприятия человеком сложных запросов, требующих соединения, и подзапросов.
Фактически это временный именованный результирующий набор данных, на который можно ссылаться внутри оператора SELECT, INSERT, UPDATE или DELETE.
Рассмотрим простой запрос:
SELECT *
FROM bill
WHERE id in
(SELECT DISTINCT id
FROM id
WHERE country = "US"
AND status = "Y"
)Представьте, что мы задействуем этот подзапрос многократно в последующем запросе. Не проще ли использовать его как временную таблицу? Именно эту задачу и решают обобщенные табличные выражения.
WITH idtempp as (
SELECT id as id
FROM id
WHERE country = "US"
AND status = "Y"
)
SELECT *
FROM bill
WHERE id in (SELECT id from idtempp)Упорядочение данных
Дата-инженерам и аналитикам данных очень часто приходится упорядочивать значения по каким-либо параметрам, например зарплате, затратам и т. д. И это экономит много времени при поиске точного запроса.
SELECT
id,
Amount,
RANK() OVER (ORDER BY Amount desc)
FROM billВ этом запросе набор данных упорядочен по столбце amount («Сумма»).
Вместо RANK() используется также DENSE_RANK(). Он аналогичен, но не пропускает следующее по порядку значение, если у двух строк одинаковое значение.
Добавление подытогов
Наличие промежуточного итога (подытога) помогает оценить данные в контексте общего итога.
Это расширенная версия оператора GROUP BY: здесь есть возможность добавления к данным промежуточных и общих итогов.
SELECT
Type,
id,
SUM (Amount) AS total_amount
FROM bill
GROUP BY Type,id WITH ROLLUP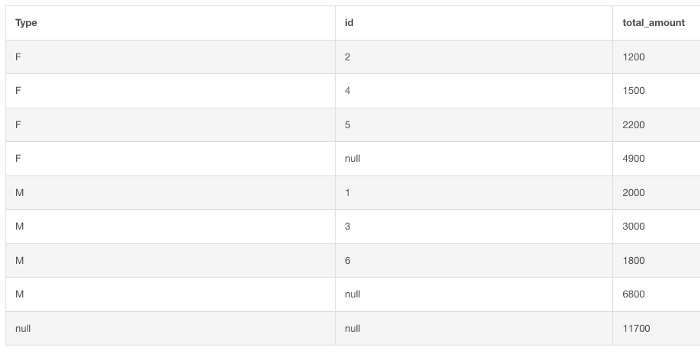
Примечание: это запрос в MySQL. Для других синтаксис свертки может отличаться.
Здесь в запросе строка со значениями null и для типа, и для идентификатора — это итог. Есть также подытоги со значениями null только в столбце идентификатора: это 4-я и предпоследняя строки.
Временные функции
Временные функции позволяют легко менять данные без использования огромных операторов case.
В следующем примере временная функция применяется для преобразования типа в род. Это можно было сделать с помощью встроенного в запрос оператора case, но тогда было бы неудобно читать.
CREATE TEMPORARY FUNCTION get_gender(type varchar) AS (
CASE WHEN type = "M" THEN "male"
WHEN type = "F" THEN "female"
ELSE "n/a"
END
)
SELECT
name,
get_gender(Type) as gender
FROM billДисперсия и среднеквадратическое отклонение
Для получения этих значений есть специальные агрегатные функции: VARIANCE, VAR_POP и VAR_SAMP. Они группируют данные и используются для определения дисперсии, дисперсии группы и дисперсии выборки набора данных по отдельности.
SELECT
VARIANCE(amount) AS var_amount,
VAR_POP(amount) AS var_pop_amount,
VAR_SAMP(amount) AS var_samp_amount,
STDDEV_SAMP(amount) as stddev_sample_amount,
STDDEV_POP(amount) as stddev_pop_amount,
FROM billVAR_POP — дисперсия совокупности;VAR_SAMP — дисперсия выборки;STDDEV_SAMP — среднеквадратическое отклонение для выборки;STDDEV_POP — среднеквадратическое отклонение для совокупности.
Это были основные SQL-команды, которые я постоянно использовал, работая дата-инженером, и которые пришлись очень кстати при решении многих бизнес-задач.
Stats подтверждает, что экосистема инструментов SQL, которая включает в себя все: от Excel и Tableau до SparkSQL — используется в более чем 60 % организаций. Это настоящий подвиг для SQL, особенно учитывая его возраст.
Уверен, что и вам как дата-инженеру эти команды будут полезны.
Читайте также:
- Как подключить базу данных MySQL к сайту на PHP
- SQL в науке о данных
- Руководство по анализу данных с SQL
Читайте нас в Telegram, VK и Дзен
Перевод статьи Cinto: 6 SQL Queries Every Data Engineer Should Be Aware of





