
Данные — это новое топливо цифровой эры. Однако с ростом их количества появляется необходимость извлекать из них смысл. В результате этого появилось множество профессий, связанных с управлением данными и их анализом для принятия более разумных бизнес-решений. Многие из этих профессий требуют умения управлять данными в базах данных.
Введение
Распространенным способом управления данными является использование системы управления реляционными базами данных. Реляционная база данных хранит данные в табличной форме, состоящей из строк и столбцов, и включает в себя как данные, так и метаданные. Данные — это информация, хранящаяся в таблицах, а метаданные — это данные, описывающие структуру данных или типы данных в базе данных.
Для прямого взаимодействия с этими базами данных используется SQL (язык структурированных запросов), с помощью которого выполняются такие задачи, как создание, чтение, обновление и удаление данных.
SQL — это декларативный и предметно-ориентированный язык, который используется бизнес-аналитиками, программистами, аналитиками данных и другими людьми, работающими с данными. Для освоения SQL не нужно быть программистом или знать Языки программирования. Синтаксис SQL схож с синтаксисом английского языка.
В этой статье мы ознакомимся с SQL и его концепциями, а также узнаем, как использовать запросы для обработки данных.
Установка базы данных
В этом руководстве мы будем использовать тестовую базу данных для написания собственных запросов и отредактируем ее с помощью редактора SQL W3school, не требующего установки.
Шпаргалка
Имея справочное руководство под рукой, вы сможете быстро разобраться в ключевых словах SQL, используемых при запросе таблиц. Здесь можно найти таблицу ключевых слов. Помните, что половина битвы за покорение зверя SQL состоит из заучивания ключевых слов.
Язык описания данных (DDL)
Большинство запросов связаны с тем или иным действием, выполняемым в таблице. Действия делятся на четыре категории: создание, вставка, обновление и удаление.
Создание таблицы
Для создания таблицы в базе данных используется оператор CREATE TABLE. Введите следующий код в редактор:
CREATE TABLE Countries(
Country_id int,
Country_name varchar(255),
Continent varchar(255),
Population int
);vЭтот фрагмент создает таблицу countries с четырьмя столбцами. Минимум, необходимый для создания таблицы в SQL — это указание названия столбца, типов данных и длины. Также можно указать больше характеристик, таких как Not Null, которое означает, что в таблицу не будет введено пустое значение, но это необязательные атрибуты.
Работа с таблицами
Вставка в таблицу
После создания таблицы можно вставить строки с помощью INSERT INTO. Введите следующий код:
INSERT INTO countries(Country_id,Country_name, Continent,Population)
VALUES (1,'Somalia','Africa',14000000);Это выражение добавляет новую страну Somali в таблицу countries. Рекомендуется указывать названия и значения столбцов при вставке строк в таблицу.
Чтение таблицы
Чтобы просмотреть данные, сохраненные в базе, используем оператор Select.
Select * from Countries;
Этот оператор возвращает таблицу со строкой, которая только что была вставлена с помощью оператора INSERT. Символ * означает «отобразить все строки таблицы». Чтобы в таблице отобразился только столбец Population, удаляем звездочку и заменяем ее названием столбца.
Select Population from Countries;
Обновление таблицы
Для изменения существующих записей в таблице используется оператор UPDATE.
UPDATE Countries
SET Country_name ='Kenya'
WHERE Country_id=1;Это выражение обновляет столбец country_name в строке с country_id от 1 до Kenya. Чтобы изменить только эту строку, необходимо указать ID страны. Если мы удалим оператор WHERE, SQL обновит все строки в таблице.
Удаление записей в таблице
Для удаления всех строк в таблице используется оператор DELETE FROM.
DELETE FROM Countries;
Для удаления таблицы, а не записей, используется оператор DROP TABLE.
DROP TABLE Countries;
Примечание: эта команда удаляет всю таблицу из базы данных и может привести к потере данных!
Фильтры
Если вас интересует лишь часть данных в таблице, то можно воспользоваться фильтрами. Есть несколько операторов для фильтрования таблиц. Фильтры выбирают строки, соответствующие определенным критериям, и возвращают результаты в виде отфильтрованного набора данных. Фильтрация таблиц не изменяет исходную таблицу.
WHERE
Предложение WHERE используется для фильтрации записей. В редакторе есть таблица Customers. Чтобы отфильтровать клиентов из “USA”, используется оператор WHERE.
SELECT * from Customers WHERE country = "USA";
AND, OR и NOT
В предыдущем примере было указано только одно условие: "WHERE country = "USA". Условия также можно комбинировать с помощью AND, OR и NOT. Например, если вам нужны клиенты из США или Бразилии, используйте оператор OR.
SELECT * from Customers WHERE country = "USA" OR country = "Brazil";
ORDER BY
В большинстве случаев при фильтрации таблицы возвращается неотсортированный набор данных. Отсортировать этот отфильтрованный набор данных можно с помощью оператора ORDER BY.
SELECT * from Customers WHERE country = "USA" OR country = "Brazil"
ORDER BY CustomerName ASC;Эта команда упорядочит результаты в алфавитном порядке. Чтобы отсортировать их в порядке убывания, заменяем ASC на DESC.
BETWEEN
Чтобы выбрать строки, значения которых удовлетворяют определенному диапазону, используется оператор BETWEEN.
SELECT * from Products
WHERE Price BETWEEN 10 AND 20;
Это выражение фильтрует товары, стоимость которых варьируется от 10 до 20.
Примечание: В операции BETWEEN нижняя и верхняя границы учитываются включительно.
LIKE
Чтобы отфильтровать таблицу с учетом конкретного шаблона используется оператор LIKE.
SELECT * from Customers
WHERE CustomerName LIKE 'A%';Это выражение фильтрует таблицу, отображая только тех клиентов, чье имя начинается с буквы А. Если перенести знак процента перед А, то SQL отобразит клиентов, чье имя заканчивается буквой А.
GROUP BY
GROUP BY группирует отфильтрованный набор результатов по сводным группам для каждого набора данных столбца.
SELECT COUNT(CustomerID), Country
FROM Customers
GROUP BY Country;Это выражение подсчитывает количество клиентов из каждой страны, а затем группирует его по странам. Чаще всего GROUP BY используется с агрегатными функциями, подробнее о которых мы поговорим ниже.
HAVING
HAVING был введен, поскольку оператор WHERE не работает с агрегатными функциями, а только с прямыми значениями в базе данных.
SELECT COUNT(CustomerID), Country
FROM Customers
GROUP BY Country
HAVING COUNT(CustomerID) > 3;Этот оператор выполняет те же действия, что и в последнем примере. Разница в том, что здесь включены только страны с более, чем тремя клиентами.
Объединения
Допустим, нам нужно узнать, какие товары заказал каждый клиент. Если база данных соответствует правильной технике нормализации, то товары, клиенты и заказы будут находиться в отдельных таблицах. Чтобы узнать, какие товары заказал каждый клиент, необходимо посмотреть ID клиента в таблице заказов, затем перейти к таблице клиентов и просмотреть покупки товаров, а затем использовать ID товара для просмотра таблицы товаров. Это огромная головная боль. Для упрощения этой задачи в SQL есть оператор под названием JOIN. Это предложение используется для объединения двух или более строк в таблице на основе общего соответствующего столбца.
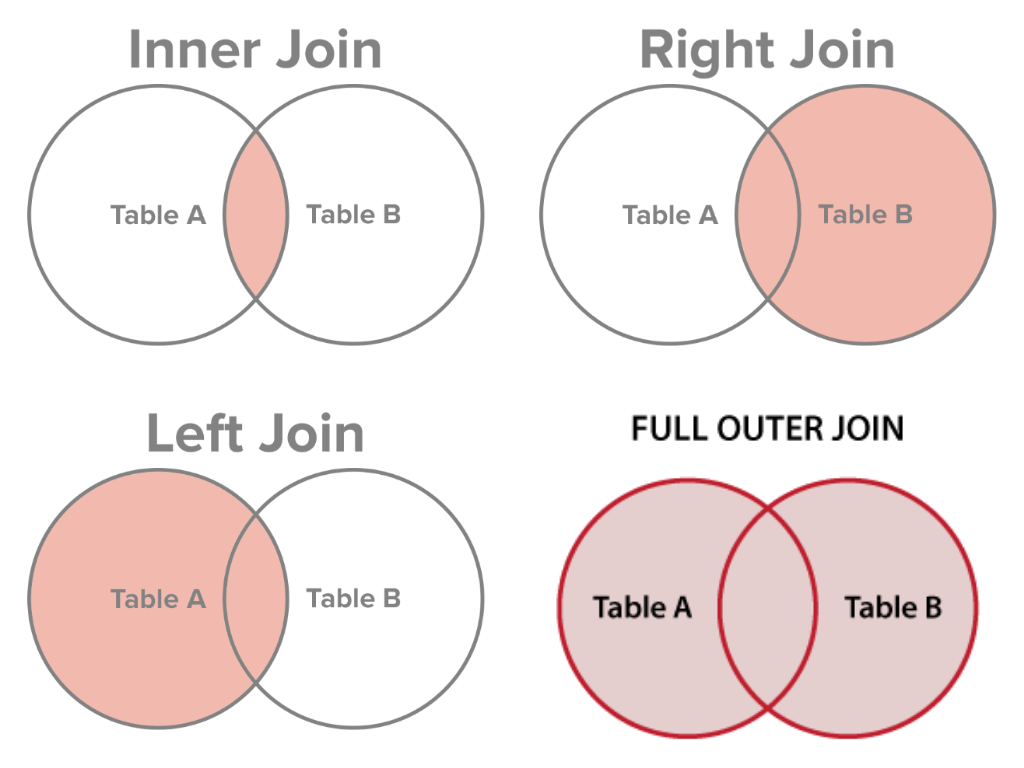
INNER JOIN
INNER JOIN, известный как просто JOIN, используется для объединения связанных таблиц в общем столбце в одну таблицу.
SELECT Orders.OrderID, Customers.CustomerName
FROM Orders
INNER JOIN Customers ON Orders.CustomerID = Customers.CustomerID;Оператор выше возвращает ID заказа столбца и имена клиентов. Мы объединяем таблицы заказов (слева) и клиентов (справа), но только те строки, которые соответствуют ID клиентов. Перечитайте это предложение, глядя на диаграмму Венна INNER JOIN, чтобы было легче разобраться.
LEFT JOIN
SELECT Customers.CustomerName, Orders.OrderID
FROM Customers
LEFT JOIN Orders ON Customers.CustomerID = Orders.CustomerID
ORDER BY Customers.CustomerName;Оператор LEFT JOIN объединяет левую таблицу (клиенты), а правая таблица (заказы) возвращает все строки из левой таблицы и соответствующие записи из правой таблицы.
RIGHT JOIN
SELECT Orders.OrderID, Employees.LastName, Employees.FirstName
FROM Orders
RIGHT JOIN Employees ON Orders.EmployeeID = Employees.EmployeeID
ORDER BY Orders.OrderID;RIGHT JOIN возвращает все строки из правой таблицы и соответствующие записи из левой таблицы. В результате мы получаем всех сотрудников и размещенные ими заказы.
OUTER JOIN
SELECT Customers.CustomerName, Orders.OrderID
FROM Customers
FULL OUTER JOIN Orders ON Customers.CustomerID=Orders.CustomerID
ORDER BY Customers.CustomerName;Этот оператор также известен как FULL OUTER JOIN и используется для объединения всех строк из одной или нескольких таблиц. Все строки будут включены в объединенные таблицы.
Агрегатные функции SQL
Функция — это набор действий, который принимает входные данные — и выстреливает выходными данными. Функция SQL — это набор операторов SQL, которые принимают входные данные и выполняют с ними действия SQL, а затем возвращают результаты в виде выходных данных.
В SQL есть два типа функций: функции set и функции value. Функция, которая манипулирует строками данных в таблице и возвращает одно значение, называется функцией set. Программисты обычно называют их агрегатными функциями, поскольку они берут строки в таблице и возвращают сводную информацию.
MIN
SELECT MIN(Price) AS LeastPricy
FROM Products;Эта функция SQL возвращает самую низкую цену из всех продуктов в таблице Products.
MAX
SELECT MAX(Price) AS MostExpensive
FROM Products;Эта функция SQL возвращает самую высокую цену из всех продуктов в таблице Products.
AVG
SELECT AVG(Price) AS AveragePrice
FROM Products;Эта функция SQL возвращает среднюю цену среди всех продуктов в таблице Products.
COUNT
SELECT COUNT(ProductID)
FROM Products;Эта команда возвращает количество продуктов в таблице Products.
SUM
SELECT SUM(Quantity)
FROM OrderDetails;Возвращает сумму всех заказов в таблице Order Details.
Индексы
Все рассмотренные выше запросы являются базовыми. С практической точки зрения, запросы, выполняемые ежедневно, обычно состоят из комбинации нескольких операторов или функций SQL. При наличии сложных операции это сократит время выполнения запросов.
К счастью, в SQL есть индексация, с помощью которой поиск можно ускорить. Индекс — это структура данных с указателем на данные в таблице. Без индекса поиск данных в таблице был бы линейным, то есть проходил бы одну строку за другой. Индексация хорошо подходит для табличных данных.
Создание индекса
CREATE INDEX idx_lastname
ON Persons (LastName);Эта команда создает индекс для быстрого поиска данных из столбца. Следует отметить, что индексы не хранятся в таблице и невидимы невооруженным глазом. Чаще всего индексы используются при наличии большого количества данных, извлекаемых из таблиц.
Транзакции базы данных
Транзакции — это набор операторов SQL, которые необходимо выполнить один за другим без сбоев. В случае сбоя хотя бы одной операции транзакция считается неудачной.
Типичным примером использования транзакций является банковский перевод денег с одного счета на другой. Чтобы перевод был успешным, деньги должны быть удалены со счета A и добавлены к счету B и наоборот. В противном случае транзакцию придется начинать заново.
Триггеры
Не все SQL-запросы индивидуальны и изолированы. Иногда нужно выполнить действие с таблицей A, в то время как другое событие происходит с таблицей B. В таком случае используется триггер
Триггер базы данных — это набор операторов SQL, которые выполняются, когда в базе данных происходит определенное событие. Триггеры запускаются при внесении изменений в данные таблицы, чаще всего до или после таких действий, как DELETE, UPDATE и CREATE. Наиболее распространенный вариант использования триггеров — проверка входных данных.
Советы
- Все зарезервированные слова SQL пишутся в верхнем регистре. Все остальное (таблицы, столбцы и т. д.) — в нижнем.
- Разделите запросы на несколько строк вместо одного длинного выражения в одной строке.
- Нельзя добавлять столбец в точно определенную позицию в таблице, поэтому будьте осторожны при проектировании.
- Будьте внимательны при использовании операторов alias (псевдонимов)
AS; столбцы не переименовываются в таблице. Псевдонимы появляются только в результирующем наборе данных. - SQL вычисляет в таком порядке:
FROM,WHERE,GROUP BY,HAVINGиSELECT. Следовательно, каждое предложение получает отфильтрованные результаты предыдущего фильтра. Выглядит это следующим образом:
SELECT(HAVING(GROUP BY(WHERE(FROM...))))
Заключение
Не забывайте, что лучший способ закрепить концепции и улучшить навыки в SQL — это практиковаться и решать проблемы на SQL. Вдохновением для некоторых из приведенных выше примеров послужила W3School. Больше интерактивных упражнений можно найти на таких веб-сайтах, как hackerrank и LeetCode.
Читайте также:
- SQL в науке о данных
- Руководство по SQL: Как лучше писать запросы
- Можно ли использовать бессерверные технологии для создания микросервисов?
Перевод статьи Muhsin Warfa: The Last SQL Guide for Data Analysis You’ll Ever Need





