
Введение
В этой статье я расскажу вам о методе максимального правдоподобия для оценки параметров и приведу простой пример, чтобы наглядно продемонстрировать этот принцип. Для полного понимания материала вам потребуется знание фундаментальных концепций вероятности, таких как совместная вероятность и независимость событий.
Что такое параметры?
В машинном обучении часто используется модель для описания процесса, в результате чего мы получаем данные и наблюдаем за ними. Так, мы можем использовать модель Random Forest для определения вероятности отписки клиентов от услуги. Есть также линейные модели для предварительного расчета прибыли, которая будет получена компанией в зависимости от рекламных расходов. Каждая модель содержит свой собственный набор параметров, которые в конечном итоге определяют, как она будет выглядеть.
Если речь идет о линейной модели, мы можем использовать уравнение y = mx + c. В данном примере x означает расходы на рекламу, а y — полученный доход. m и c — это параметры данной модели. Различные значения этих параметров приведут к разным линиям на графике (см. рисунок ниже).
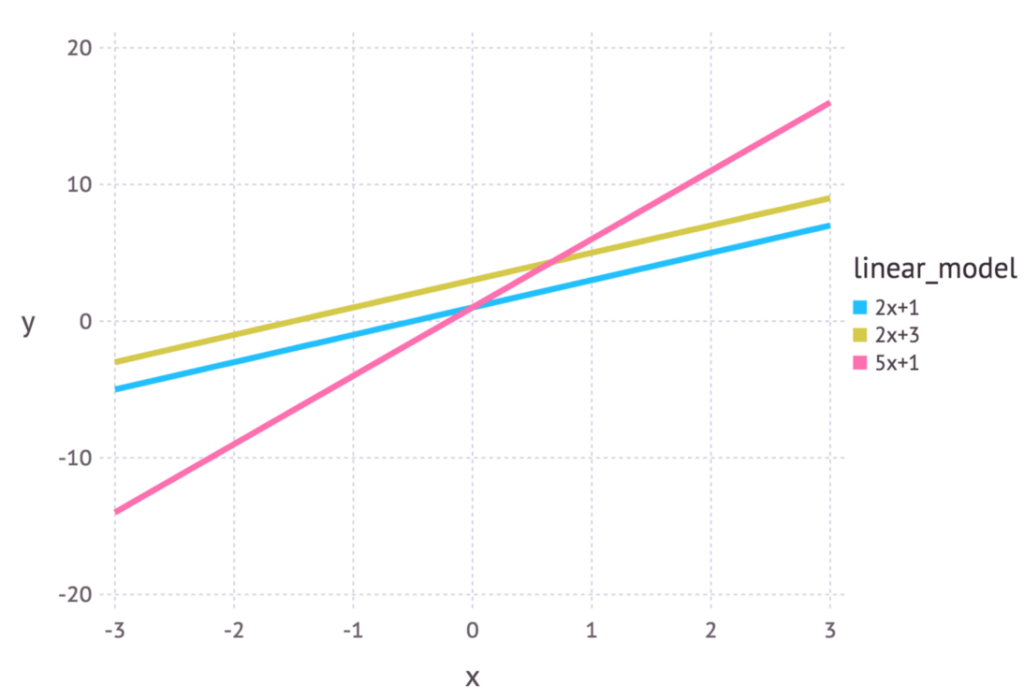
Таким образом, параметры определяют проект модели. Только когда для параметров выбираются конкретные значения, мы получаем конкретизацию модели, описывающую то или иное явление.
Интуитивное объяснение оценки максимального правдоподобия
Оценка максимального правдоподобия — это метод, который определяет значения параметров модели. Значения параметров находятся таким образом, чтобы они максимизировали вероятность того, что процесс, описываемый моделью, производил данные, за которыми велось наблюдение.
Приведенное выше определение может показаться несколько запутанным, поэтому давайте рассмотрим пример, который поможет нам понять, что к чему.
Предположим, мы наблюдаем 10 точек данных конкретного процесса. Пусть каждая точка данных означает время в секундах, которое требуется студенту, чтобы ответить на определенный экзаменационный вопрос. Эти 10 точек данных показаны на рисунке ниже.
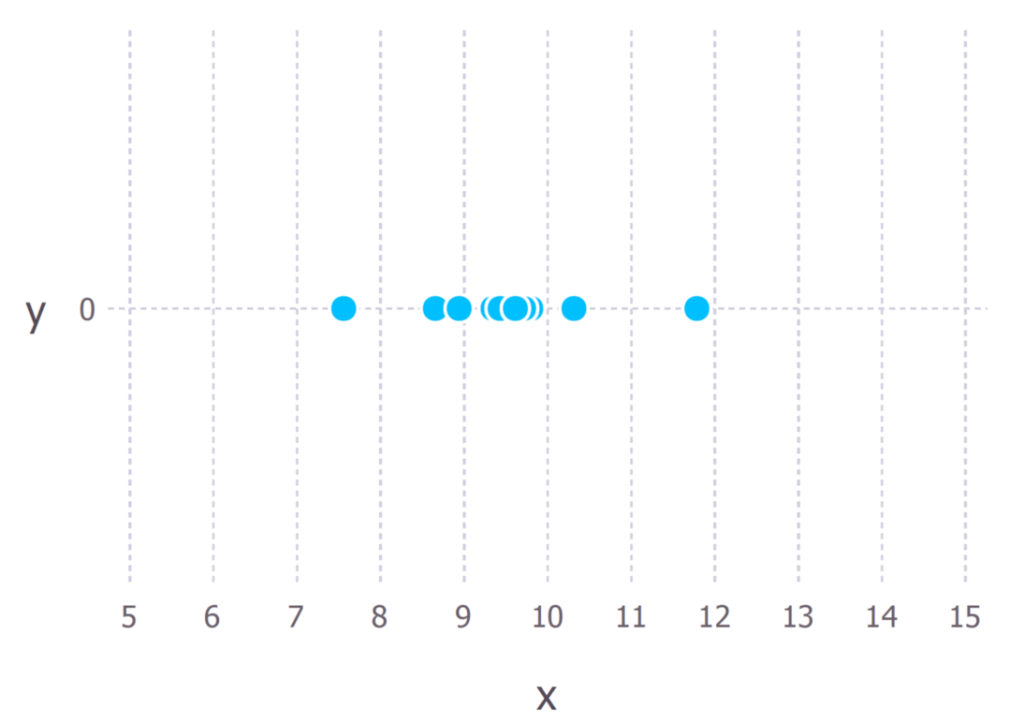
Сначала мы должны решить, какая модель, по нашему мнению, лучше всего описывает процесс генерирования данных. Этот момент очень важен. По крайней мере, мы должны иметь четкое понимание того, какую модель использовать. Обычно такие решения принимаются, исходя из некоторого опыта в данной сфере, но мы не будем подробно на этом останавливаться.
В нашем случае мы предположим, что процесс генерации данных может быть адекватно описан распределением Гаусса (нормальным распределением). Визуальный осмотр рисунка выше позволяет допустить, что здесь такое распределение оправданно, поскольку большинство из 10 точек сгруппированы в центре, а несколько других точек разбросаны слева и справа. Принимать подобное решение на лету, имея всего 10 точек данных, не рекомендуется, но, учитывая то, что я сгенерировал эти точки данных, мы согласимся с таким предположением.
Напомню, что распределение Гаусса имеет 2 параметра: среднее значение μ и стандартное отклонение σ. Различные значения этих параметров приводят к различным кривым (как и в случае с прямыми линиями выше). Мы хотим узнать, какая кривая с наибольшей долей вероятности привела к созданию наблюдаемых нами точек данных? (см. рисунок ниже). Оценка максимального правдоподобия — это метод, позволяющий найти значения параметров μ и σ, которые приводят к кривой, наилучшим образом соответствующей нашим данным.
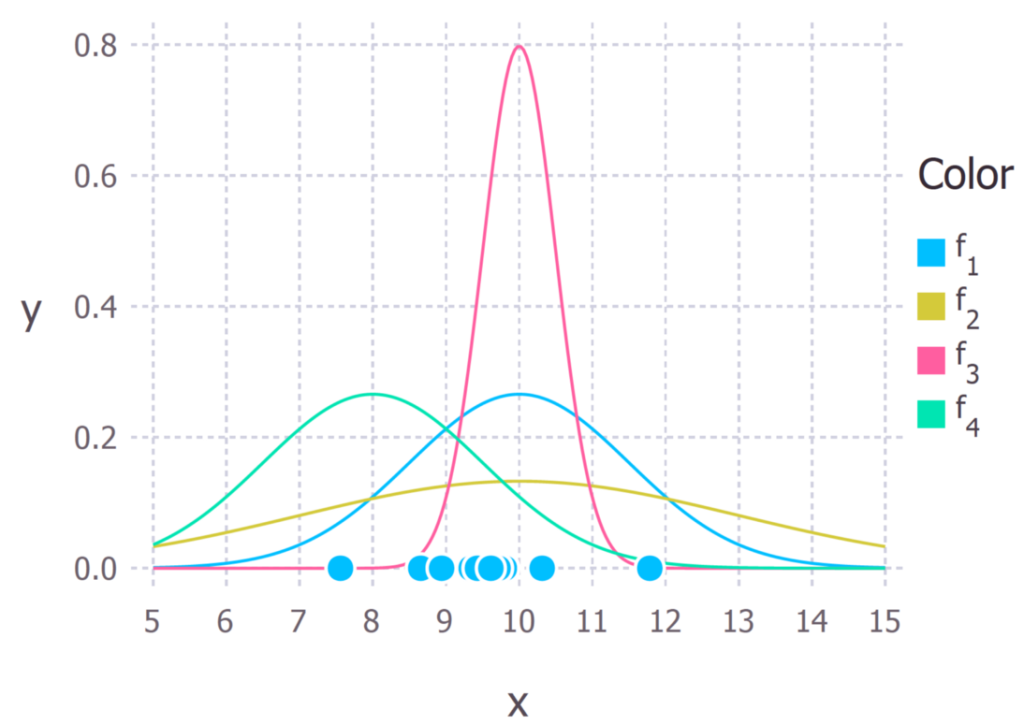
Истинным распределением, на основе которого получены данные, было f1 ~ N(10, 2,25). Оно показано на рисунке выше синей кривой.
Расчет оценок максимального правдоподобия
Теперь, когда у нас есть интуитивное понимание того, что такое оценивание максимального правдоподобия, мы можем перейти к вычислению значений параметров. Найденные нами значения будут называться оценками максимального правдоподобия (MLE).
Возьмем другой пример. Предположим, что на этот раз у нас есть три точки данных, и мы допускаем, что они были получены в результате процесса, который адекватно описывается распределением Гаусса. Эти точки имеют значения 9, 9,5 и 11. Как нам вычислить оценки максимального правдоподобия для значений параметров распределения Гаусса μ и σ?
Мы хотим вычислить общую вероятность наблюдения всех данных, то есть совместное распределение вероятностей всех наблюдаемых точек данных. Для этого нам потребуется вычислить некоторые условные вероятности, что может оказаться очень сложным. Поэтому здесь мы сделаем наше первое предположение. Оно заключается в том, что каждая точка данных генерируется независимо от других. Такое предположение значительно упрощает математические вычисления. Если события (т.е. процесс, генерирующий данные) независимы, то общая вероятность наблюдения всех данных равна произведению вероятностей наблюдения каждой точки данных по отдельности (т.е. произведению безусловных вероятностей).
Плотность вероятности наблюдения одной точки данных x, которая генерируется из распределения Гаусса, задается следующей формулой:
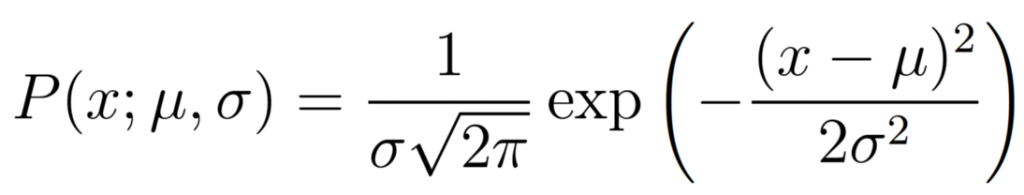
Точка с запятой в выражении P(x; μ, σ) используется для указания того, что символы, которые идут после него, являются параметрами распределения вероятности. Поэтому его не следует путать с выражением условной вероятности, которая обычно обозначается вертикальной линией, например, P(A| B).
В нашем примере общая (совместная) плотность вероятности наблюдения трех точек данных задается в виде следующего уравнения:
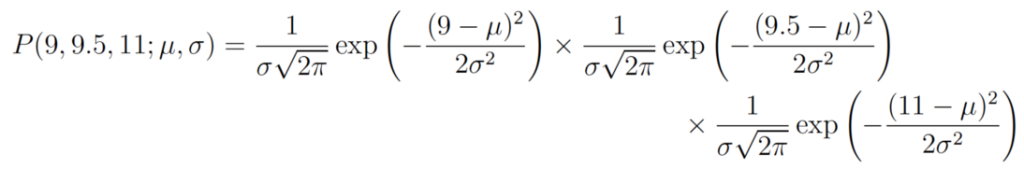
Нам остается только выяснить значения μ и σ, которые дают максимальное значение приведенного выше выражения.
Если вы проходили исчисления на уроках математики, то наверняка знаете, что существует метод, который помогает находить максимумы и минимумы функций. Он называется “дифференцирование”. Все, что нам нужно сделать, — это найти производную функции, приравнять ее к нулю, а затем перестроить уравнение так, чтобы интересующий нас параметр стал искомой величиной уравнения. И вуаля, мы получим значения MLE для наших параметров!
Я подробнее расскажу об этих шагах дальше. Предполагаю, что читатель знает, как проводить дифференцирование обычных функций. Если хотите получить более подробное объяснение, напишите об этом в комментариях.
Логарифмическое правдоподобие
Приведенное выше выражение для общей вероятности на самом деле довольно сложно дифференцировать. По этой причине его почти всегда упрощают, беря натуральный логарифм выражения. Это абсолютно нормальная практика, так как натуральный логарифм является монотонно возрастающей функцией. Она предполагает увеличение значения по оси y вместе с увеличением значения по оси x (см. рисунок ниже). Этот момент является важным, поскольку таким образом обеспечивается достижение максимального значения логарифма вероятности и исходной функции вероятности в одной точке. Так что мы можем работать с более простым логарифмическим правдоподобием вместо исходного правдоподобия.
Если взять логарифмы исходного выражения, то получим:
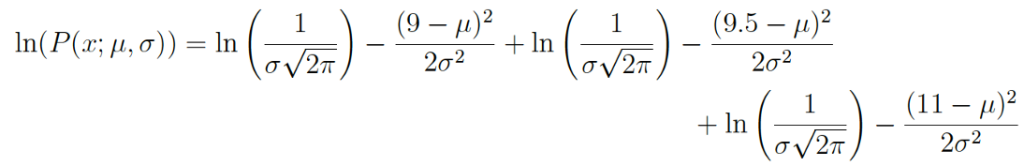
Это выражение можно еще более упростить, используя законы логарифмов. В результате получаем:
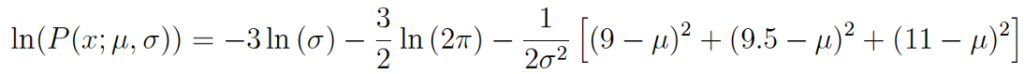
Данное выражение можно продифференцировать, чтобы найти максимум. В нашем примере мы вычислим MLE среднего значения, μ. Для этого возьмем частную производную функции по отношению к μ. В итоге получим следующее:
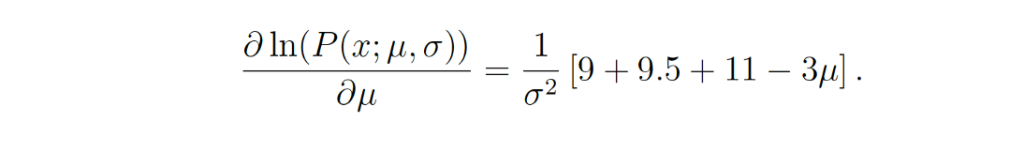
Наконец, приравнивание левой части уравнения к нулю и последующая перестановка величины μ дает такой результат:
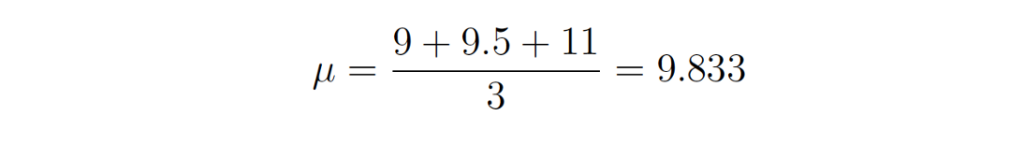
Так мы вычислили оценку максимального правдоподобия для μ. То же самое можно проделать и с σ, но тут читатель может поупражняться самостоятельно.
Заключительные мысли
Всегда ли оценка максимального правдоподобия может быть вычислена точно?
Если говорит вкратце, то нет. Скорее можно предположить, что в реальном мире производная функции логарифмического правдоподобия является аналитически неразрешимой задачей (т.е. слишком трудно/невозможно продифференцировать эту функцию вручную). Поэтому для поиска численных решений при оценке параметров используются итерационные методы, такие как алгоритмы максимизации ожидания. Однако общая идея остается прежней.
Так почему же максимальное правдоподобие, а не максимальная вероятность?
Дело в том, что специалисты по статистике — люди педантичные (и на то есть свои причины). Большинство людей обычно используют слова “вероятность” и “правдоподобие” как взаимозаменяемые понятия, но статистики и теоретики вероятности различают эти два термина. Чтобы понять причину путаницы, взгляните на это уравнение:
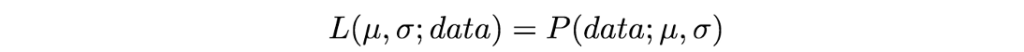
Эти выражения равны! Что же это значит? Давайте сначала дадим определение P( μ, σ; data). Это плотность вероятности наблюдения данных с параметрами модели μ и σ. Стоит отметить, что это выражение подходит для любого количества параметров и любого распределения.
L(μ, σ; data) означает вероятность того, что параметры μ и σ принимают определенные значения с учетом наблюдения нами множества данных.
Приведенное выше уравнение показывает, что плотность вероятности данных с учетом параметров равна вероятности параметров с учетом данных. Но, несмотря на то, что эти два выражения равны, правдоподобие и плотность вероятности требуют ответа на разные вопросы: одно спрашивает о данных, а другое — о значениях параметров. Именно поэтому метод называется “максимальное правдоподобие”, а не “максимальная вероятность”.
Когда минимизация по методу наименьших квадратов совпадает с оценкой по методу максимального правдоподобия?
Минимизация по методу наименьших квадратов — еще один распространенный метод оценки значений параметров для модели в машинном обучении. Если предполагается, что мы имеем модель Гаусса, как в примерах выше, оценки MLE будут эквивалентны результатам метода наименьших квадратов. Для более глубокого математического анализа посмотрите эти слайды.
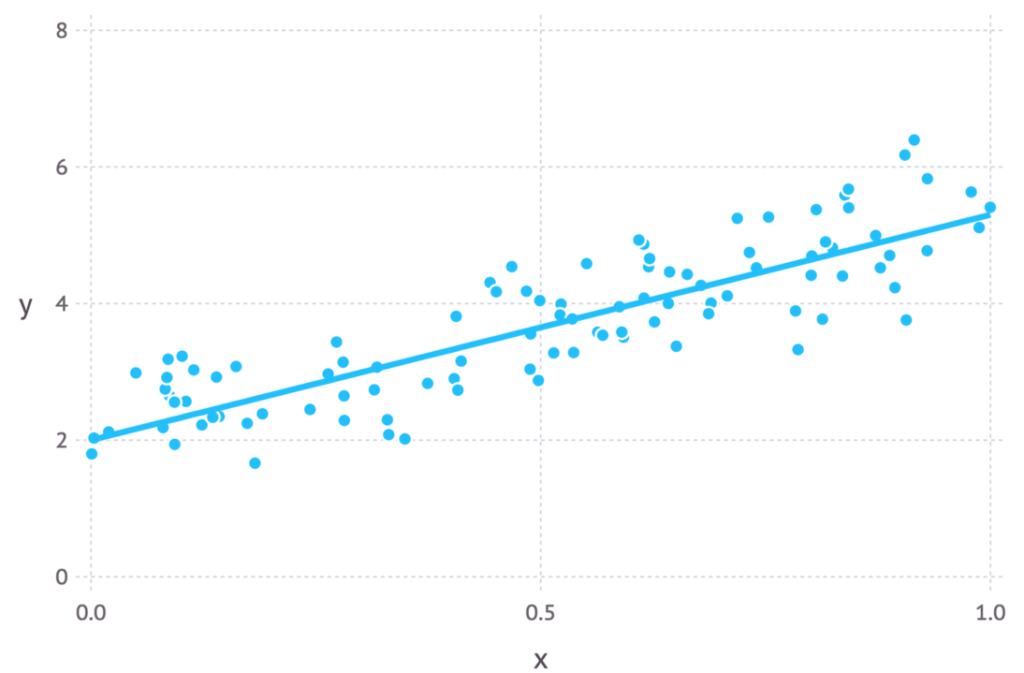
На интуитивном уровне мы сможем объяснить связь между этими двумя методами, если поймем их цели. При оценке параметров по методу наименьших квадратов мы стремимся найти линию, минимизирующую общее квадратичное расстояние между точками данных и линией регрессии (см. рисунок ниже). При оценке методом максимального правдоподобия мы хотим максимизировать общую вероятность данных. Если предполагается распределение Гаусса, то максимальная вероятность обнаруживается тогда, когда точки данных приближаются к среднему значению. Поскольку распределение Гаусса симметрично, это эквивалентно минимизации расстояния между точками данных и средним значением.
Если вам что-то непонятно или я допустил какие-то ошибки в статье, не стесняйтесь оставлять комментарии. Благодарю за прочтение!
Читайте также:
- Пять парадоксов с вероятностью, которые вас озадачат
- Плотность вероятности - это не сама вероятность
- Вероятность в Python: перестановки и сочетания
Читайте нас в Telegram, VK и Дзен
Перевод статьи Jonny Brooks-Bartlett: Probability concepts explained: Maximum likelihood estimation





