
Python предлагает несколько упрощенных и универсальных кодов для реализации сложных задач в рамках минимальных кодовых блоков. В отличие от других языков программирования, имеющих довольно сложные аннотации для решения конкретной задачи, Python в большинстве случаев предлагает более простое решение. Каждый специалист по обработке данных должен знать определенные кодовые блоки, чтобы начать свои исследования в области науки о данных и машинного обучения.
Важно помнить, что некоторые строки кода или отдельные кодовые блоки всегда можно повторно использовать, причем в нескольких программах. Следовательно, программисты любого уровня — будь то новичок, разработчик среднего класса, продвинутый специалист или эксперт — должны выработать привычку запоминать полезные коды. Это позволит принимать более быстрые решения.
Основная цель этой статьи — представить кодовые блоки, которые могут регулярно использоваться специалистами по обработке данных независимо от того, над какими проектами, проблемами или задачами они работают. Семнадцать описанных ниже кодовых блоков предоставят вам отличную возможность повторного использования в большинстве задач с небольшими изменениями или без них.
Статья предназначена в первую очередь начинающим разработчикам. Однако энтузиасты науки о данных среднего и продвинутого уровня, переходящие на Python с другого языка программирования, также найдут ее полезной. Итак, без лишних слов, давайте приступим к описанию этих 17 кодовых блоков.
1. Условные и итерационные циклы
def even(a):
new_list = []
for i in a:
if i%2 == 0:
new_list.append(i)
return(new_list)
a = [1,2,3,4,5]
even(a)Условные и итерационные циклы — это код, который приветствует большинство пользователей на своем языке программирования. Несмотря на то, что эти кодовые блоки являются наиболее базовыми аспектами написания кода, они находят широкое применение во всех задачах, связанных с наукой о данных, в машинном обучении и глубоком обучении. Без них практически невозможно выполнять самые сложные задачи.
Приведенный выше блок кода является простым примером функции, которая использует как условный if-оператор, так и for-цикл. For-цикл выполняет перебор всех элементов, а условный if-оператор проверяет четные числа. Хотя этот блок кода является тривиальным примером, есть несколько других полезных опций, которые пользователь должен иметь в виду.
2. Списки
lst = ['one', 'two', 'three', 'four']
lst.append('five')
lstСписки являются ключевым аспектом структур данных. Большинство структур данных представляют собой набор различных элементов данных, которые определенным образом структурированы. Списки обладают некоторыми свойствами, которые позволяют использовать их практически в каждом отдельном проекте или сложной задаче, стоящей перед разработчиками. Видоизменяемость списков позволяет изменять или модифицировать их в соответствии с конкретным вариантом использования.
Для любой программы вам понадобится список для хранения некой информации или данных, связанных с конкретной выполняемой вами задачей. Чтобы сохранить дополнительные элементы в списке, вы часто будете использовать метод append вместе с for-циклом для повторения определенной команды и соответствующего хранения элементов.
3. Словари
# Dictionary with integer keys
my_dict = {1: 'A', 2: 'B'}
print(my_dict)
# Dictionary with string keys
my_dict = {'name': 'X', 'age': 10}
print(my_dict)
# Dictionary with mixed keys
my_dict = {'name': 'X', 1: ['A', 'B']}
print(my_dict)Еще одна важная структура данных, которую мы рассмотрим, — это словарь. Эта структура данных также находит частое использование в большинстве программ. Словари содержат набор неупорядоченных элементов. С помощью этих словарей вы можете хранить ключевую переменную, содержащую множество значений. Вызывая конкретный ключ, вы получите доступ ко всем соответствующим его значениям.
Словари легко создавать и хранить в любой программе. Разработчики в основном предпочитают эти структуры данных для различных задач, требующих хранения парных элементов. Каждая такая пара элементов состоит из ключа и значения.
4. Операторы break и continue
a = [1,2,3,4,5]
for i in a:
if i%2 == 0:
break
or j in a:
if j%2 == 0:
continueОператоры прерывания (break) и продолжения (continue) являются наиболее полезными для разработчиков и программистов при выполнении ими любой сложной задачи, связанной с наукой о данных. Эти операторы помогают завершить цикл или условную конструкцию либо продолжить операцию, пропустив ненужный элемент.
Приведенный выше блок кода дает представление о широком спектре задач, которые можно выполнить с помощью этих двух операторов. Если вы столкнулись с определенной переменной или условием и хотите завершить цикл, оператор break поможет справиться с этой задачей. Если же после ввода какого-то условия или переменной, вы хотите пропустить этот элемент, а затем продолжить операцию, то оператор continue — лучший выбор для вас.
5. Лямбда-функция
f = lambda x:x**2
f(5)Обычные функции, использующие ключевое слово def, преимущественно подходят для больших блоков кода. Однако, если вам нужно получить быстрые и эффективные результаты с минимальными временными и пространственными затратами, стоит воспользоваться лямбда-функцией.
Лямбда-функция вычисляет значение и немедленно выполняет возврат результата или выходного решения в однострочном коде. Следовательно, каждый разработчик должен рассмотреть возможность использования лямбда-функции для упрощения кода и выполнения соответствующей задачи с относительной легкостью и более высокой эффективностью.
6. Функция filter
a = [1, 2, 3, 4, 5]
even = list(filter(lambda x: (x%2 == 0), a))
print(even)Условие filter (фильтра) используется для упрощения большинства операций, при которых мы удаляем все ненужные элементы и сохраняем только самые важные, необходимые для конкретной задачи. Эффективность этой функции обусловлена тем фактом, что любая сложная задача может быть решена в пределах одной или нескольких строк кода.
В первом кодовом блоке, который важно запомнить всем разработчикам, мы обсудили пример выведения всех четных чисел. Заметьте, нами были использованы как условный оператор, так и итерационный цикл в процессе решения такой задачи. Однако в приведенном выше кодовом блоке мы можем выполнить ту же задачу выведения только четных чисел для списка элементов в однострочном коде.
7. Функция map
a = [1, 2, 3, 4, 5]
squares = list(map(lambda x: x ** 2, a))
print(squares)Map — это еще одна уникальная функция, которая учитывает все существенные элементы в конкретной структуре данных и соответствующим образом проходит по ним. Она выполняет определенное действие для каждого из упомянутых элементов в качестве аргумента для этой операции.
Если коротко, то map — это встроенная в Python функция, которая позволяет обрабатывать и преобразовывать все элементы в итерационном режиме без использования явного for-цикла. Приведенный выше блок кода выполняет операцию прохода по предоставленному списку и генерации квадратов каждого из заданных элементов соответственно.
8. Функция reduce
from functools import reduce
a = [1, 2, 3, 4, 5]
product = reduce(lambda x, y: x*y, a)
print(product)В отличие от двух предыдущих функций, а именно filter() и map(), функция reduce (сокращение) работает немного по-другому. Она проходит по списку повторяющихся чисел и возвращает только одно значение. Чтобы воспользоваться этой функцией, вам надо импортировать дополнительный модуль под названием functools. После этого можете приступать к использованию операции reduce. Функция reduce — последняя из анонимных функций, которые мы обсудим в этой статье.
9. NumPy
import numpy as np
X = np.array(X)
y = np.array(y)
y = to_categorical(y, num_classes=vocab_size)Numerical Python — одна из лучших библиотек для решения математических задач. Существует широкий спектр проблем и задач, которые разработчики и программисты могут решить с помощью этой удивительной библиотеки. Вы можете преобразовать сохраненные списки с целочисленными элементами в структуру numpy и начать выполнять с ними различные операции.
Приложения NumPy многочисленны в каждой отдельной области. В такой сфере, как компьютерное зрение, мы можем использовать массивы NumPy для визуализации цветовой модели RGB (красный-зеленый-синий) или оттенков серого в виде массива NumPy и соответствующего преобразования каждого из элементов. В большинстве разработанных проектов по обработке естественного языка мы обычно предпочитаем преобразование текстовых данных в форму векторов и чисел для повышения оптимизированных вычислений. Для выполнения следующей задачи вы можете без проблем импортировать библиотеку NumPy и продолжить преобразование текстовых данных в категорийные, как показано в приведенном выше блоке кода.
10. Pandas

Pandas — еще одна библиотека, которую вы будете постоянно использовать для интерпретации данных. Это одна из лучших библиотек для просмотра данных практически в любом формате, особенно в виде файлов CSV или excel. Она известна исключительной полезностью в задачах, связанных с обработкой и анализом данных в проектах машинного обучения.
Библиотека выполняет большинство задач, связанных с выравниванием данных, индексированием, получением срезов и настройкой очень больших наборов данных. К ней обращаются при решении сложнейших задач в структурированном формате. Вы можете просто прочитать доступные вам данные в однострочном коде и продолжить интерпретировать их удобным для вас способом.
11. Matplotlib
import matplotlib.pyplot as plt
plt.bar(classes, train_counts, width=0.5)
plt.title("Bar Graph of Train Data")
plt.xlabel("Classes")
plt.ylabel("Counts")
Окончательный алгоритм машинного обучения, который почти всегда сочетается с NumPy и Pandas, — это Matplotlib. Эта библиотека чрезвычайно полезна для визуализации. В то время как две другие библиотеки помогают рассматривать отдельные аспекты элементов данных структурным или числовым способом, библиотека Matplotlib позволяет охватить эти аспекты в форме визуального представления.
Визуальное представление числовых данных помогает использовать поисковые методы их анализа в задачах машинного обучения. С помощью этих методов анализа мы можем выбирать подходящие направления для решения конкретной проблемы. Блок кода представляет собой визуализацию ваших данных в виде гистограммы. Эта визуализация является широко используемым методом для просмотра данных.
12. Regular Expressions
import re
capital = re.findall("[A-Z]\w+", sentence)
re.split("\.", sentence)
re.sub("[.?]", '!', sentence)
x = re.search("fun.", sentence)Модуль Regular Expressions (регулярных выражений) — это предварительно встроенная библиотека на Python, которая предлагает разработчикам отличные способы решения любых задач по обработке естественного языка. Он предоставляет пользователям множество команд для упрощения доступных текстовых данных. С помощью Re-библиотеки вы можете импортировать их для выполнения нескольких операций с буквами, словами и предложениями.
13. Инструментарий обработки естественного языка
import nltk
sentence = "Hello! Good morning."
tokens = nltk.word_tokenize(sentence)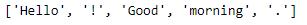
Операции с регулярными выражениями отлично подходят для начальных этапов проекта обработки естественного языка. Однако в дальнейшем на помощь разработчику приходит другая превосходная библиотека. Она будет эффективно выполнять большинство задач, таких как вывод, маркировка, лемматизация и другие подобные операции. Благодаря библиотеке Natural language processing toolkit (NLTK) пользователи могут легко разрабатывать проекты NLP.
Библиотека NLTK является одним из наиболее полезных инструментов для разработчиков. Этот модуль дает возможность упростить самые сложные задачи с помощью нескольких строк кода. Большинство функций, предоставляемых библиотекой, позволяют выполнять сложные настройки текстовых данных в пределах одной или нескольких строк кода. Приведенный выше блок кода с предоставленным выводом является одним из таких примеров.
14. Изображения с Pillow
# Importing the required libraries
import numpy as np
from PIL import Image
import PIL# Opening and analyzing an image
image1 = Image.open('Red.png')
print(image1.format)
print(image1.size)
print(image1.mode)Работа с изображениями является важным аспектом для специалистов по обработке данных, которые заинтересованы в дальнейшем изучении областей компьютерного зрения и обработки изображений. Pillow — одна из таких библиотек на Python, которая предлагает пользователям универсальные возможности для управления изображениями и фото.
Пользователи могут выполнять с помощью библиотеки Pillow множество задач. Пример, показанный в приведенном выше блоке кода, поможет вам открыть изображение заданным путем. При этом вы сможете изучить множество параметров изображения, таких как высота, ширина и количество каналов. У вас будет возможность соответствующим образом управлять изображением и манипулировать им и в конце концов сохранить его.
15. Изображения с Open-CV
import cv2 # Importing the opencv module
image = cv2.imread("lena.png") # Read The Image
cv2.imshow("Picture", image) # Frame Title with the image to be displayed
cv2.waitKey(0)Open-CV — одна из лучших библиотек, которая используется разработчиками на всех этапах для успешного решения задач, связанных с изображениями, фото, визуальными эффектами или видео. Эта библиотека, помимо прочего, используется для вычисления действий, связанных с работой веб-камеры в реальном времени.
Общая доступность и популярность этого модуля делают его незаменимым для большинства специалистов по обработке данных. Приведенный выше блок кода является примером визуализации изображения по указанному пути к каталогу.
16. Классы
class Derivative_Calculator:
def power_rule(*args):
deriv = sympy.diff(*args)
return deriv
def sum_rule(*args):
derive = sympy.diff(*args)
return deriv
differentiatie = Derivative_Calculator
differentiatie.power_rule(Derivative)Классы являются неотъемлемой частью объектно-ориентированных языков программирования. Python использует классы для объединения данных и функций. По сравнению с другими языками программирования, механика классификации в Python немного отличается. Это смесь алгоритмов классификации, взятых из в C++ и Modula-3.
Классы широко используются даже для разработки моделей глубокого обучения. При написании кодов TensorFlow вам может потребоваться создать пользовательский класс для соответствующего определения ваших моделей. Этот метод подклассов модели используется разработчиками на самом высоком этапе.
17. Random
import random
r = random.uniform(0.0,1.0)Библиотека Random, предварительно созданная и предлагаемая Python, является одним из наиболее важных модулей, которые помогут вам выполнить большинство задач, подразумевающих неопределенность или случайность. Они находят широкое применение в решении большинства задач программирования, связанных с предсказаниями в машинном обучении.
В отличие от людей, у большинства компьютеров есть диапазон значений для прогнозирования точных значений. Следовательно, случайная переменная и Random-библиотека являются одними из наиболее важных элементов в Python. Ведь проекты машинного и глубокого обучения требуют, чтобы пользователь указывал диапазон случайности, из которого могут быть получены наиболее точные значения.
Выводы
“Любой дурак может написать код, понятный компьютеру. Хорошие программисты пишут код, который могут понять люди”. — Мартин Фаулер
В любом языке программирования есть модули, которые вы будете использовать чаще других. В языке программирования Python также есть кодовые блоки, которые пользователи предпочитают остальным. Им и была посвящена эта статья. Правда, мы рассмотрели далеко не все элементы. В мире программирования на Python есть еще множество концепций, достойных изучения.
Читайте также:
- Как дизассемблировать код Python и повысить его производительность
- Как защитить учетные данные с помощью переменных среды в Python
- Пять отличных Python-библиотек для data science
Читайте нас в Telegram, VK и Дзен
Перевод статьи Bharath K: 17 Must Know Code Blocks For Every Data Scientist





