
Введение
Один из лучших способов доступа к данным сайта — через его API (интерфейс прикладного программирования). Но что, если у сайта нет API? Тогда стоит задействовать веб-скрейпинг. В этой статье мы пошагово разберем процесс создания простого веб-скрейпера с использованием Ruby. А кроме того, рассмотрим более сложные ситуации, в которых применяется веб-скрейпинг.
В качестве примера возьмем сайт Atlas Obscura: будем получать доступ к содержащейся на нем информации.

Настройка среды
Первым делом настроим среду для скрейпинга. Для этого используем модуль Open-URI и библиотеку Nokogiri — они задействуются в Ruby для скрейпинга данных. Сначала надо установить open-uri и nokogiri, а затем с помощью метода require затребовать их в файле, который будет использоваться для написания кода скрейпинга. Не будет лишним затребовать таким же образом библиотеку pry для добавления в код binding.pry, с помощью которого будет проверяться, работает ли код.
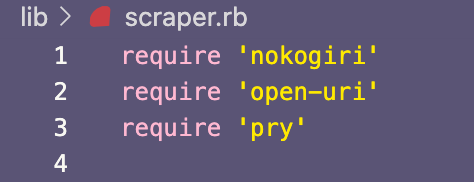
Для простого веб-скрейпера создаем два класса Ruby: Scraper и Place. Класс Scraper задействуется для выполнения всей тяжелой работы — получения данных с сайта Atlas Obscura и создания экземпляров класса Place. Класс Place довольно простой, в нем содержатся методы считывания и задания нужных нам атрибутов, а также методы для хранения новых экземпляров:
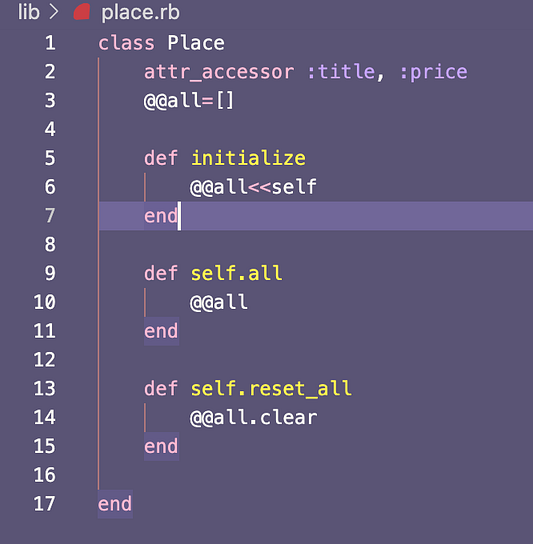
Кроме того, чтобы с помощью класса Scraper инстанцировать класс Place, нужно в файле scraper.rb посредством метода require затребовать place.rb:

Этапы создания веб-скрейпера
Настроив среду и файлы, будем приступать к скрейпингу. Для завершения процесса создания простого скрейпера проходим эти три этапа:
- Чтобы заполучить HTML сайта, задействуем nokogiri и open-uri.
- Чтобы заполучить нужные атрибуты для экземпляров класса
Place, задействуем селекторы CSS. - Создаем методы, которые инстанцируют новые экземпляры класса
Placeи присваивают атрибуты.
Первый этап процесса довольно прост: используем метод open из nokogiri и open-uri, чтобы заполучить HTML и задать его в виде переменной doc.

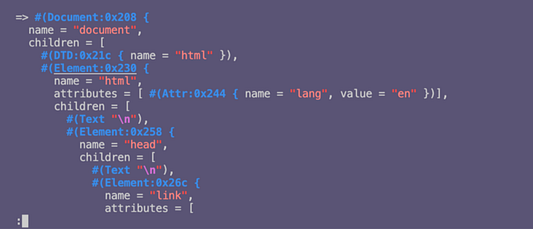
Задействование binding.pry для открытия сеанса pry и распечатки переменной doc дает такой вывод HTML:
Чтобы заполучить конкретные HTML-элементы для атрибутов, нужно знать их селекторы CSS. Для этого задействуется инспектор элементов в консоли браузера.
На этом этапе потребуется действовать методом проб и ошибок, досконально изучив все, чтобы получить абсолютно правильные элементы. Для этого придется поработать с селектором элементов в браузере и посмотреть, как определяется каждый элемент, а затем протестировать различные селекторы CSS в терминале.
В сеансе pry доступ к элементам получается с помощью методов .css и .text. Например, при запуске doc.css(“.Card”).first.text в ходе тщательного анализа HTML-документа захватываются все элементы с классом CSS Card, затем возвращается первый объект в этом массиве, после чего этот объект выдается в виде обычного текста. Дальше при желании детализируем, добавив еще селекторов CSS, например так: doc.css(“.Card”).first.css(“h3”).text.
Заметим опять же, что для получения правильных селекторов CSS на этом этапе придется много работать методом проб и ошибок и запастись терпением. А на более сложных сайтах порой потребуется использование более специфических селекторов CSS.
Разобравшись с селекторами CSS для нужных нам атрибутов, приступим к написанию методов для присвоения HTML-элементов экземпляру Place, а затем к выводу списка экземпляров Place:
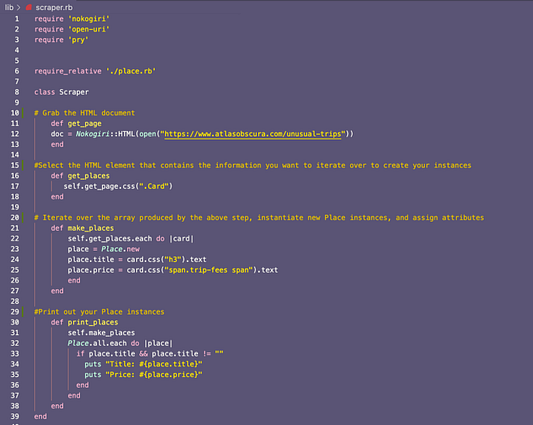
Добавив к коду внизу Scraper.new.print_places, при запуске этого файла в терминале получим список экземпляров Place. Вот как выглядит конечный вывод:
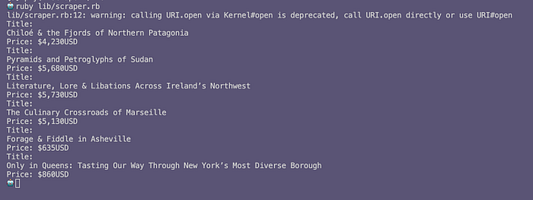
Заключение
В целом веб-скрейпинг — отличный инструмент, хотя для его правильного применения надо немало потрудиться. Легкодоступный и удобный в использовании API (при его наличии на сайте) явно предпочтительнее, нежели задействовать веб-скрейпинг. Тем более что последний сильно зависит от содержащегося на сайте HTML, в который внести изменения не составляет большого труда.
Однако у веб-скрейпинга есть одна очень крутая особенность: он позволяет не только создавать экземпляры классов Ruby, но и экспортировать данные в различных форматах, в том числе .csv и JSON. Эта функциональность дает веб-разработчикам возможность извлекать с сайтов общедоступные данные, сохранять эту информацию в формате JSON, а затем использовать ее для расширения API собственной серверной части, что в конечном итоге позволяет другим разработчикам легко получать доступ к данным, не прибегая к веб-скрейпингу!
Читайте также:
- Парсинг HTML из строки на Ruby On Rails
- Подробный разбор методов Ruby
- Google OAuth для реализации на Ruby
Читайте нас в Telegram, VK и Яндекс.Дзен
Перевод статьи Victoria Perkins: Making a simple web scraper in ruby





