
Стратегия тестирования — это подход к автоматизированному тестированию вашего программного обеспечения. Она очень важна, и к ней следует отнестись серьезно. Я предложу визуальный способ ее представления, поскольку они способствуют обсуждению, формированию общего понимания и помогают в принятии решений.
“В мире, где полно технических специалистов и политиков с кардинально разным уровнем понимания, графическое представление часто становится единственным способом выразить свою точку зрения. Один график резкого падения обычно вызывает в десять раз более сильный отклик, чем куча таблиц с данными.” — “Цифровая крепость”
Прежде чем мы начнем…
…необходимо определиться с некоторой терминологией (вдохновленной тестовыми шаблонами xUnit). Я избегаю терминов “модульный тест” и “интеграционный тест”, поскольку считаю их двусмысленными и ограничивающими. Реальность больше похожа на спектр: меняется только тестируемая система (SUT, System Under Test), также известная как “объект тестирования”. По сути, это — всё то, что мы тестируем.
SUT может быть чем угодно, у чего есть интерфейс, будь то API или GUI: функцией, компонентом, страницей, системой… Не обязательно даже чем-то одним; это может быть несколько классов, два слоя, два приложения… Отсюда примечательное следствие: не все нужно проверять напрямую.
SUT может существовать вообще без зависимостей, но обычно одна или несколько всё же есть. Например, компонент React зависит от вызывателя службы, веб-обработчик — от случаев использования, одностраничное приложение — от API сервера, микросервис — от базы данных, система — от поставщика удостоверений… Все такие сущности называются компонентами с зависимостями (Depended-on Components, DoC).
В тестовой среде DoC могут вести себя непредсказуемо. Поскольку нам важна повторяемость тестов, мы прибегаем к тестовым дублерам — это обобщающий термин для макетов, заглушек, шпионов, мок-сервисов и фэйк-объектов. Рекомендую поинтересоваться их различиями.
Кроме того, важно упомянуть четырехфазную структуру теста (которая отражает структуру Arrange, Act, Assert либо Given, When, Then):
- Setup: Настройте SUT и тестовые дублеры; подготовьте тестовые фикстуры (для них может потребоваться какая-то прямая или косвенная точка взаимодействия).
- Exercise: Выполните операцию с SUT через контрольные точки (т.е. вызов метода, вызов API, действия с графическим интерфейсом).
- Verify: Проверьте результаты с помощью точек наблюдения (например, путем проверки SUT, файловой системы, базы данных, шпиона или макета).
- Teardown (при необходимости): Возможно, потребуется провести очистку данных, для чего также нужна точка взаимодействия (прямая или косвенная).
Взглянем на общую диаграмму концепций, которые мы только что рассмотрели:
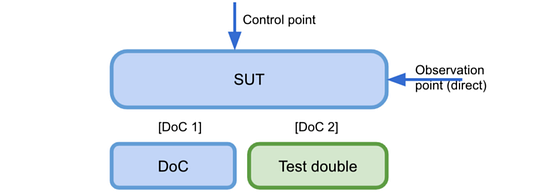
На диаграмме видно, что мы тестируем SUT, вызвав его через некоторую контрольную точку (общедоступный интерфейс).
Кроме того, обратите внимание, что в SUT есть два DoC. DoC-1 не заменяется, так что в некотором смысле является частью SUT, а потому, возможно, понадобится более реалистичный тест на фактический компонент. С другой стороны, DoC-2 был заменен тестовым дублером для лучшего контроля.
Мы воспользуемся точкой наблюдения для утверждений (assertions), в данном случае такая точка — открытый интерфейс SUT (вход).
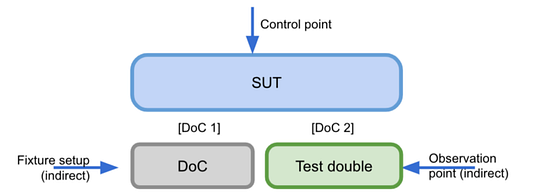
Приведенный выше пример показывает, что настройка фикстуры была выполнена с использованием механизма бэкдора (например, заполнение некоторой базы данных). Точка наблюдения основана на тестовом дублере DoC (например, фэйк-объекте).
Как видим, все виды автоматизированного тестирования, от тестирования неглубокого отрисованного компонента до распределенной системы, могут быть обобщены с использованием одного и того же языка.
Неважно, модульный это тест или сквозной; что меняется и имеет значение, так это размер SUT и ваш подход к зависимым компонентам.
Визуализация стратегии
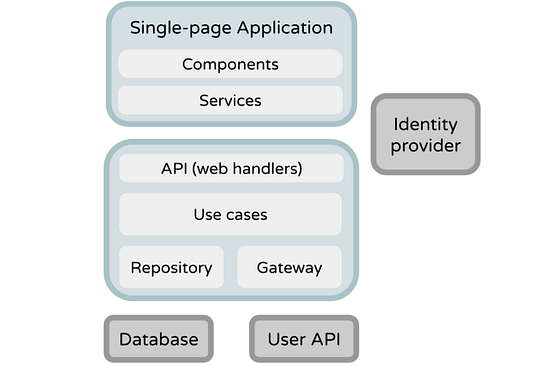
Хватит теории, рассмотрим несколько практических примеров. В качестве примера возьмем типичное клиент-серверное приложение: одностраничное приложение (React), которое запускается в браузере и взаимодействует с REST API (Kotlin). В свою очередь, API содержит несколько веб-обработчиков, вариантов использования и репозиториев; они зависят от базы данных (PostgreSQL). Основная цель — проанализировать выразительную силу диаграмм, а поэтому не будем заострять внимание на методах тестирования как таковых. Представленный порядок тестов также не имеет особого значения.
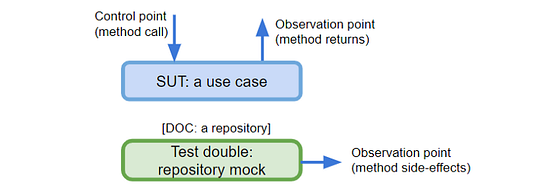
Тестирование варианта использования
Согласно принципам чистой архитектуры, вариант использования содержит некоторую бизнес-логику под управлением пользователя. Это наша SUT; в данном случае она зависит от хранилища (DoC). Мы подготовим мок-сервис, который будет действовать в качестве замены, и добавим его к SUT. Затем будем напрямую вызывать методы SUT (контрольная точка) и проверять результаты, подтверждая результаты метода и побочные эффекты, полученные из мок-сервиса (точки наблюдения).
Если бы вариант использования зависел еще и от шлюза, мы просто добавили бы новое поле и подумали, какой тип тестового дублера лучше подойдет на замену.
Чтобы легче создавать моки и шпионы на Java, воспользуйтесь Mockito; на Kotlin — попробуйте MockK.
Тестирование шлюза
Здесь SUT — это шлюз, адаптер для некой сторонней службы. Контрольными точками будут методы шлюза (например, getUserProfile, resetPassword). Первая точка наблюдения — результат вызова этих методов (полезно для запросов); вторая — вызовы, которые были сделаны тестовому дублеру, в данном случае — вызовы, записанные сервером тестирования (полезно для команд).
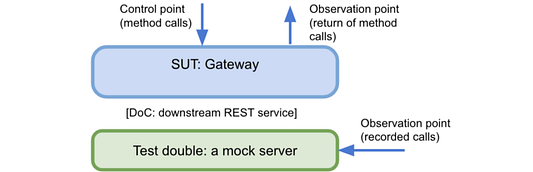
Типичные технологии для такого случая — e WireMock и MockServer. Также подойдет Javalin.
Тестирование хранилища
Цель в том, чтобы изолировать слой данных, в нашем случае — некое хранилище, и сосредоточиться только на его возможностях (обычно это называется модульным тестом). DoC для хранилища — это некая реальная база данных, и план в том, чтобы заменить ее тестовым дублером; для этого воспользуемся базой данных в памяти (in-memory)/встроенной базой данных.
Тесты будут вызывать методы тестируемого хранилища (контрольная точка). Затем уже можно делать утверждения, анализируя результаты или вызывая другие методы SUT (точка наблюдения). Например, можно сохранить пользователя, а затем получить данные о нем просто чтобы подтвердить, правильно ли он сохранился.
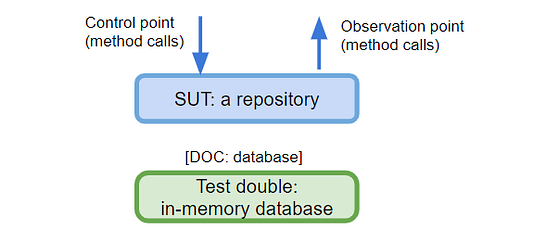
Пример этой техники есть на моем GitHub (в качестве тестового дублера задействован Wix Embedded MySql).
Тестирование бэкенд-приложения
Здесь мы тестируем бэкенд целиком: от веб-обработчиков до базы данных. Обычно это называется интеграционным тестом. SUT здесь — это серверное приложение.
В качестве контрольной точки воспользуемся REST API — чтобы наши тесты попадали на конечные точки REST API точно так же, как любой клиент (например, браузер). API также будет точкой наблюдения (для выполнения тестовых утверждений), если у нас есть для этого методы. Это означает, что тест будет проверять тело и HTTP-статус для каждого вызова.
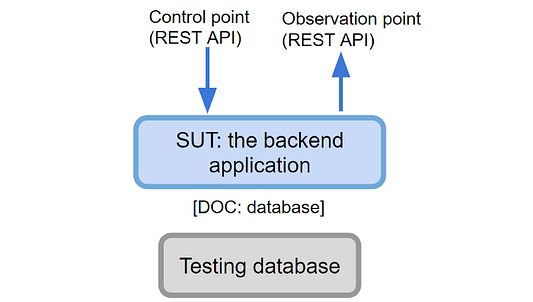
Не создавайте API-интерфейсы только ради тестирования! Если у вас их нет, рассмотрите другие точки наблюдения.
DoC — это база данных, поэтому для такого рода тестирования выберем реальную базу данных (конечно, тестовую), чтобы у нас была среда, достаточно близкая к продакшену.
📝 Два примера этой техники можно найти в моем GitHub: интеграционные тесты с MySQL и MongoDB, хотя и с in-memory базой данных.
Тестирование фронтенд-приложения
Можно протестировать интерфейс в целом и изолировать его от серверных API. Это означает, что фронтенд-часть, ваша SUT, должна быть запущена. Затем мы будем действовать как пользователь, взаимодействующий с графическим интерфейсом, который представляет собой контрольную точку. Графический интерфейс также будет и точкой наблюдения — поскольку необходимо проверить, как он ведет себя в ответ на взаимодействия. Если быть более точным, точка взаимодействия на самом деле — DOM API, хотя действия аналогичны тому, что пользователь будет делать в графическом интерфейсе.
📝 Поскольку мы хотим тестировать как пользователь, я настоятельно рекомендую воспользоваться библиотекой Testing Library, которая способствует поиску веб-элементов от лица пользователя, а не технических деталей, таких как селекторы CSS. Если вы работаете с Jest, подумайте о добавлении кастомных сопоставителей jest-dom.
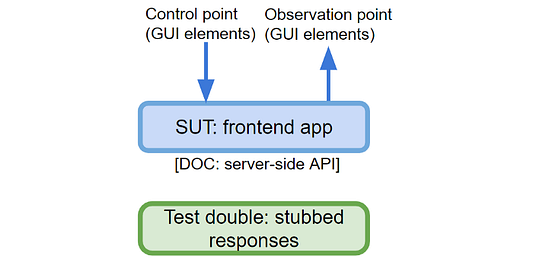
Адаптеры, зависящие от сервера, содержат набор ответов-заглушек для изоляции SUT, поэтому сетевые вызовы не задействованы.
В качестве примера рассмотрим тест, который подтверждает, что список пользователей сформирован успешно: переходим на страницу списка пользователей, SUT извлекает заглушку-ответ и подтверждает, что пользователи отображаются правильно.
Также можно было бы протестировать каждый компонент индивидуально. В этом случае SUT — произвольное дерево компонентов, а DoC — службы, которые подключаются к API сервера. Точки взаимодействия будут реализованы через DOM API. Другая альтернатива — тестирование отрисованных страниц, и в этом случае не нужно даже запускать SPA.
Тестирование системы целиком
Также это называется системным тестом или сквозным тестом. План состоит в том, чтобы запустить серверную часть, интерфейс и их DoC. Затем в тестах необходимо действовать как пользователь — предполагается, что графический интерфейс (посредством кнопок, ссылок и т.д.) содержит точки (контрольные и наблюдения) для действий и утверждения:
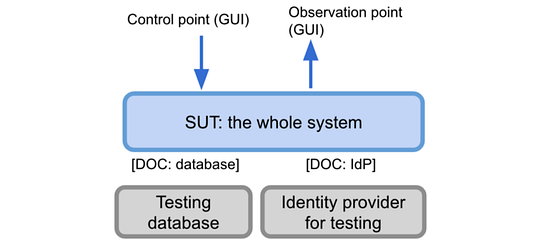
📝 Если речь о взаимодействии с веб-интерфейсом пользователя, типичными претендентами будут Protractor, Nightwatch.js, Cypress, а также Puppeteer. Привлечение Testing Library для этого рода тестов также очень важно.
Заключение
Разработка диаграмм заставляет задумываться о проблемах и озвучить их. На каждой диаграмме показаны SUT, ее документы и точки взаимодействия. Среди прочего, можно обсудить поддерживающие технологии с каждой диаграммы, шаблоны (например, “что применять, мок-объекты или фэйк-объекты?”), соотношение затрат и выгод (например, “стоит ли это того?”), размер SUT (например, “надо ли охватывать еще один слой?”). Наконец, каждую диаграмму можно снабдить всеми такими решениями вместе с другими метаданными.
Сумма всех диаграмм составляет стратегию тестирования, поэтому давайте немного уменьшим их количество. Что, если наложить диаграммы на схему архитектуры? С высоты птичьего полета заново переоценим сильные стороны и слабые места стратегии:
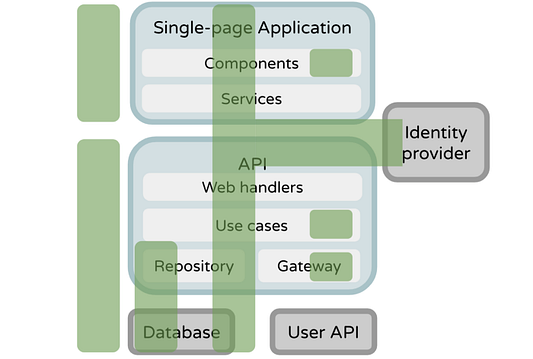
Теперь ясно видно, что интерфейсные службы и внутренние веб-обработчики не тестируются (по крайней мере, напрямую). Интеграция с пользовательским API также не тестируется. Это не всегда неправильно (не все обязательно тестировать), но теперь это видно взгляду.
Теперь проще обсуждать вопросы о системе безопасности тестирования: “Охватываем ли мы наиболее важные сценарии?”, “Какой тип теста защищает нас от изменения контракта на обслуживание?” или стратегические вопросы, такие как “В правильных ли местах мы варьируем параметры тестов?”, “Какие типы тестов разрабатывать с помощью TDD, а какие писать постфактум?”.
“Что делает решение “стратегическим”? Решение является стратегическим, если его “трудно изменить”. То есть стратегическое решение влияет на большое количество тестов, особенно таких, что многие или все тесты должны быть одновременно преобразованы во что-то другое. Иными словами, любое решение, которое может потребовать больших усилий для изменения, является стратегическим.” — Шаблоны тестирования xUnit, глава 6
Еще один интересный способ визуального представления — отображение типов тестов в тестовой пирамиде (чем больше SUT, тем ближе к вершине), что позволяет лучше понять форму SUT:
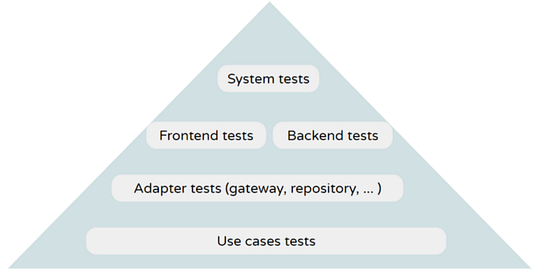
Рекомендую сохранять диаграммы (с помощью Miro, Mural, Google Drawings или аналогов) и держать ссылки на них в файле readme вашего проекта. Это поможет новичкам быстрее осваиваться в коллективе, команде достигать большей согласованности, а также потенциально послужит отправной точкой для итерации.
Это не означает, что обязательно следовать подходу к автоматизации тестирования под названием “большой дизайн прежде всего” (“big design upfront”, BDUF). BDUF — это почти всегда неправильный ответ. Скорее, полезно знать о необходимых стратегических решениях и принимать их “как раз вовремя”, а не “слишком поздно”. — Шаблоны тестирования xUnit, глава 6.
Читайте также:
- Тестирование уровня данных в Android Room с помощью Rxjava, LiveData и сопрограмм Kotlin
- Как протестировать код на Go с Github Actions
- Мутационное тестирование: создай мутанта и прокачай тест
Читайте нас в Telegram, VK и Яндекс.Дзен
Перевод статьи: Luís Soares, “Visualizing Your Automated Testing Strategy”





