
Цепочка обязанностей или цепочка команд — это шаблон проектирования, позволяющий передавать запросы по цепочке Handlers. Каждый Handler решает, нужно ли обработать и расширить запрос или же передать его следующему Handler.
Это позволяет добиться хорошей изоляции между каждым шагом и избежать наличия бизнес-логики посреди технической логики. Это также дает возможность скорректировать порядок цепочки, если вдруг потребуется изменить поведение приложения.
Звучит интересно, но зачем нам нужна настраиваемость?
Причина лежит в возможности быстрого изменения поведения приложения без развертывания кода.
Предположим, что у нас в сервисе есть набор Handlers:

Как видите, здесь простой конвейер, где мы связываем Handlers для обработки запроса. Его можно легко представить подобной конфигурацией:
root: step1
steps:
step1:
type: handlerImpl1
next: step2
step2:
type: handlerImpl2
next: step3
step3:
type: handlerImpl3Но, предположим, что мы находимся в продакшене и хотим добавить перед вызовом step3 слой кэша. Здесь нам повезло, потому что Handler для управления кэшированием уже существует для другого конвейера.
Изменив конфигурацию, можно легко получить модифицированный конвейер с этапом кэширования:
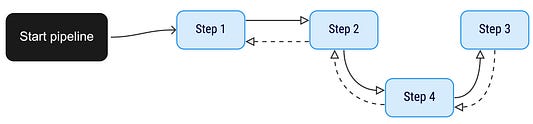
root: step1
steps:
step1:
type: handlerImpl1
next: step2
step2:
type: handlerImpl2
next: step4
step3:
type: handlerImpl3
step4:
type: RewriteHandler
next: step3Реальный пример использования
Представим, что создаем поисковый API. Базово он просто получает запрос поиска и отвечает на него.
Этот API находится на вершине Elasticsearch, поэтому по факту мы вызываем ES напрямую из API (очень просто). Спустя какое-то время вы видите, что некоторые наиболее популярные поисковые запросы происходят слишком часто, в связи с чем решаете добавить перед вызовом ES кэш Redis. Давайте также предположим, что вы хотите дополнительно повысить скорость и создать локальный кэш в приложении, чтобы отвечать на эти популярные запросы еще быстрее.
Для этого можно использовать три Handler, как показано ниже. Каждый из них будет отвечать за одно действие и сможет переходить либо не переходить к следующему шагу в зависимости от необходимости:
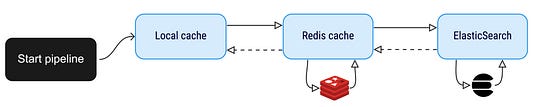
Возможность настройки также позволяет в любое время удалять этап кэширования, не изменяя код. Например, если вы видите, что локальный кэш потребляет слишком много памяти, и хотите от него избавиться, то можете просто изменить файл конфигурации, и запросы смогут поступать напрямую в кэш Redis.
Как это реализовать
Если хотите увидеть весь код, можете перейти сразу к следующему разделу. Здесь же мы рассмотрим его по частям.
Обработка файла конфигурации
Первым шагом идет загрузка конфигурации из соответствующего файла. В этом примере я использую файл YAML, размещенный на gist.
Его формат будет следующим:
root: handler1_name
steps:
handler1_name:
type: handlerImpl1
next: handler2_name
handler2_name:
type: handlerImpl2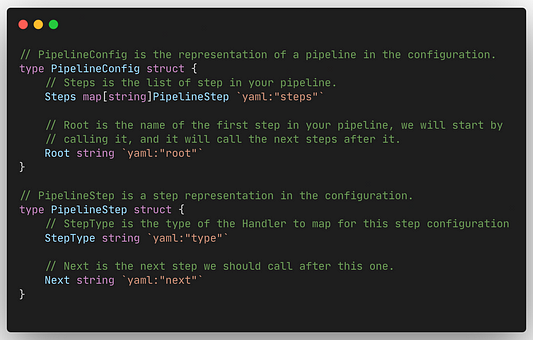
Далее первым шагом функции main мы выполняем демаршалинг конфигурации в структуру:
Создание конвейера
Конфигурация готова. С ней мы создадим уже сам конвейер, для чего вызовем NewPipeline из функции main:
pipeline, _ := NewPipeline(pipelineConfig)
Функция NewPipeline будет преобразовывать файл конфигурации в структуру конвейера с инициализированным Handler, готовым к использованию по запросу.
Для этого она преобразует StepType в фактический Handler и вызывает функцию init для каждого Handler с существующим Next Handler при наличии дальнейшего шага:
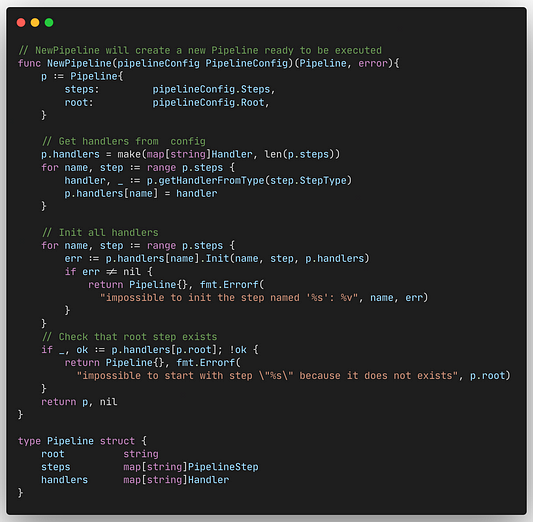
Сопоставление между StepType и используемым Handler происходит в функции getHandlerFromType():
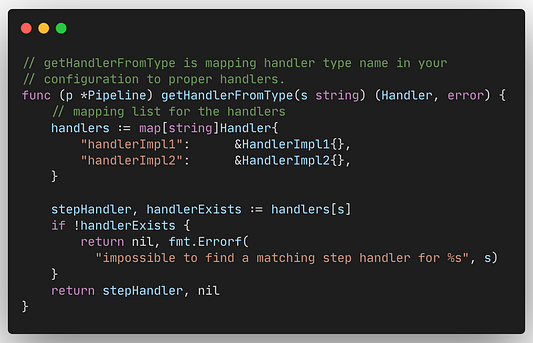
Создание обработчика
Создается Handler просто и соответствует следующему интерфейсу:
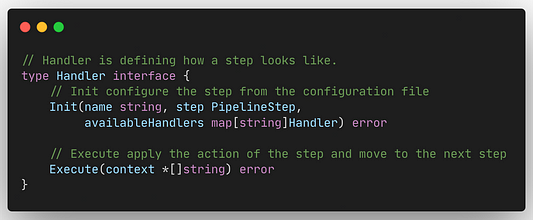
Функция init используется для инициализации следующего Handler для этого шага на основе конфигурации.
Применение фактической логики происходит через вызов функции Execute. В ней принимается решение о необходимости перехода к следующему шагу. Как видите, она получает параметр context. Этот параметр определяется для каждого Handler и может быть расширен на каждом шаге. В данном примере им является *[]string, но он может быть указателем на что угодно.
Пример Handler:
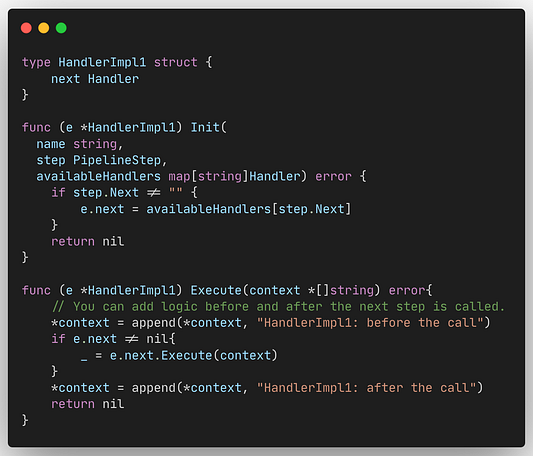
Как видите, в процессе вызова функции Execute() из next Handler мы передаем контекст. При получении результата этого шага мы также можем предпринять какое-либо действие.
Выполнение конвейера
Последним шагом идет вызов функции Execute() самого конвейера:
Она получает шаг root и выполняет связанный с ним Handler. Таким образом, происходит выполнение всей цепочки, потому что каждый Handler знает, что идет следующим.
Код
Ниже приведена полная реализация. В этом примере Handlers просты, но вы можете использовать в них более сложную логику и начать выстраивать цепочку:
package main
import (
"fmt"
"gopkg.in/yaml.v3"
"io"
"net/http"
)
// PipelineConfig - это представление конвейера в конфигурации.
type PipelineConfig struct {
// Steps - это список шагов конвейера.
Steps map[string]PipelineStep `yaml:"steps"`
// Root - это имя первого шага в конвейере. Мы начинаем с // его вызова, после чего он уже продолжит совершение остальных // вызовов.
Root string `yaml:"root"`
}
// PipelineStep - это представление шага в конфигурации.
type PipelineStep struct {
// StepType - это тип Handler, сопоставляемого с // конфигурацией этого шага. Список доступных типов находится в // методе getHandlerFromType.
StepType string `yaml:"type"`
// Next - это следующий шаг, который нужно вызвать. Этот // параметр обязателен.
Next string `yaml:"next"`
}
// ------------------------------------------------------------------------------------------------------
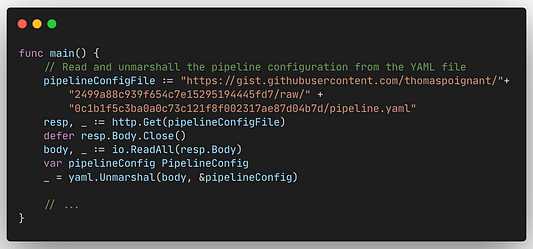
func main() {
// Считываем и демаршалируем конфигурацию конвейера из файла YAML.
pipelineConfigFile := "https://gist.githubusercontent.com/thomaspoignant/2499a88c939f654c7e15295194445fd7/raw/" +
"0c1b1f5c3ba0a0c73c121f8f002317ae87d04b7d/pipeline.yaml"
resp, _ := http.Get(pipelineConfigFile)
defer resp.Body.Close()
body, _ := io.ReadAll(resp.Body)
var pipelineConfig PipelineConfig
_ = yaml.Unmarshal(body, &pipelineConfig)
// Создаем на основе конфигурации конвейер.
pipeline, _ := NewPipeline(pipelineConfig)
// Можно задействовать объект context, который будет // доступен для использования в каждом шаге.
context:= make([]string,0)
pipeline.Execute(&context)
// Проверяем выполненные всеми шагами действия.
fmt.Println(context)
}
// ------------------------------------------------------------------------------------------------------
// NewPipeline создаст новый Pipeline, готовый к выполнению.
func NewPipeline(pipelineConfig PipelineConfig)(Pipeline, error){
p := Pipeline{
steps: pipelineConfig.Steps,
root: pipelineConfig.Root,
}
// Получаем обработчиков из конфигурации.
p.handlers = make(map[string]Handler, len(p.steps))
for name, step := range p.steps {
handler, _ := p.getHandlerFromType(step.StepType)
p.handlers[name] = handler
}
// Инициализируем всех обработчиков.
for name, step := range p.steps {
err := p.handlers[name].Init(name, step, p.handlers)
if err != nil {
return Pipeline{}, fmt.Errorf("impossible to init the step named '%s': %v", name, err)
}
}
// Проверяем существование шага root.
if _, ok := p.handlers[p.root]; !ok {
return Pipeline{}, fmt.Errorf("impossible to start with step \"%s\" because it does not exists", p.root)
}
return p, nil
}
type Pipeline struct {
root string
steps map[string]PipelineStep
handlers map[string]Handler
}
// getHandlerFromType сопоставляет имя типа обработчика в // конфигурации с соответствующими обработчиками.
func (p *Pipeline) getHandlerFromType(s string) (Handler, error) {
// Список сопоставления для обработчиков.
handlers := map[string]Handler{
"handlerImpl1": &HandlerImpl1{},
"handlerImpl2": &HandlerImpl2{},
}
stepHandler, handlerExists := handlers[s]
if !handlerExists {
return nil, fmt.Errorf("impossible to find a matching step handler for %s", s)
}
return stepHandler, nil
}
// Получаем и выполняем первый шаг для запуска конвейера поиска.
func (p *Pipeline) Execute(context *[]string) error {
return p.handlers[p.root].Execute(context)
}
// ------------------------------------------------------------------------------------------------------
// Handler определяет структуру шага.
type Handler interface {
// Init настраивает шаг из файла конфигурации.
Init(name string, step PipelineStep, availableHandlers map[string]Handler) error
// Execute применяет действие текущего шага и переходи к // следующему.
Execute(context *[]string) error
}
// ------------------------------------------------------------------------------------------------------
type HandlerImpl1 struct {
next Handler
}
func (e *HandlerImpl1) Init(name string, step PipelineStep, availableHandlers map[string]Handler) error {
// Это упрощенная версия метода init. Можете убедиться, что // следующий шаг не отделен, и что обработчик доступен.
if step.Next != "" {
e.next = availableHandlers[step.Next]
}
return nil
}
func (e *HandlerImpl1) Execute(context *[]string) error{
// Можно добавить логику до и после вызова следующего шага.
*context = append(*context, "HandlerImpl1: before the call")
if e.next != nil{
_ = e.next.Execute(context)
}
*context = append(*context, "HandlerImpl1: after the call")
return nil
}
// ------------------------------------------------------------------------------------------------------
type HandlerImpl2 struct {
next Handler
}
func (e *HandlerImpl2) Init(name string, step PipelineStep, availableHandlers map[string]Handler) error {
if step.Next != "" { e.next = availableHandlers[step.Next] }
return nil
}
func (e *HandlerImpl2) Execute(context *[]string) error{
*context = append(*context, "HandlerImpl2 called")
if e.next != nil{
return e.next.Execute(context)
}
return nil
}Заключение
В статье я показал, каким образом шаблон “цепочка ответственности” в Go может оказаться очень эффективным и стать хорошим способом разделения логики.
К тому же возможность его настройки извне кода позволяет вносить различные изменения при условии, что Handlers будут достаточно обобщенными для перемещения в другие места цепочки.
Из собственного опыта скажу, что если у вас есть один продукт, который вы можете настраивать для разных потребителей, то данная техника в этом отлично поможет. Изначально вы, конечно, потратите время на создание обработчиков, но в итоге у вас получится полноценный набор, который позволит просто выбирать правильную цепочку, ни прибегая к дополнительной разработке.
Читайте также:
- Go. Прорабатываем 25 основных вопросов собеседования
- Почему Dockerfile больше не нужен для создания контейнера в Go
- Как стать разработчиком Go: в 6 шагах от карьеры
Читайте нас в Telegram, VK и Яндекс.Дзен
Перевод статьи Thomas Poignant: Build a Configurable Chain of Responsibility in Go





