
Всем известно о новых функциях, которыми нас порадовал JDK 8, и, вероятно, трудно найти Java-разработчика, который не знает, что такое Java Streams, лямбды или CompletableFutures. Итак, все эти приятности появились несколько лет назад вместе с JDK 8, но что произошло немного раньше, когда состоялся выпуск JDK 7?
Даже если мы заглянем в раздел “Новые функции в релизе JDK 7”, то все еще будет непросто определить одну из самых важных представленных функций. Чтобы увидеть наконец то, что мы ищем, придется перейти в раздел “Утилиты параллелизма”.
Само собой, мы говорим о выпуске в JDK7 фреймворка ForkJoinPool, что, на мой взгляд, не получило заслуживаемой огласки. Я бы сказал, что многие Java-разработчики сейчас вообще незнакомы с ForkJoinPool и где его применять.
В этой статье мы рассмотрим внутренние компоненты фреймворка ForkJoinPool, объясним, почему он так важен, и воздадим должное этой забытой части JDK.
Вступление
Что же из себя представляет фреймворк ForkJoinPool? Это детализированный фреймворк для эффективного распараллеливания выполнения задач. Как уже говорилось, он был представлен как часть релиза JDK 7.
Хотя в большинстве случаев мы не пользуемся им явно, ForkJoinPool скрыто работает во многих хорошо известных фреймворках и компонентах, например в CompletableFuture и параллельных потоках . Стоит отметить, что ForkJoinPool также используется в таких языках, как Kotlin и Scala.
Что же такого интересного в ForkJoinPool? Что он дает нам, чего не могут дать существующие исполнители задач? На этот вопрос можно ответить двумя словами: кража работы (work stealing)!
Дизайн ForkJoinPool основан на фреймворке work-stealing, созданном для Cilk. Если вас интересует оригинальный дизайн, вы можете прочитать об этом здесь.
В Java есть предопределенный общий ForkJoinPool, который можно создать, вызвав ForkJoinPool.commonPool. Именно этот пул задействован некоторыми компонентами в CompletableFuture и потоках Java.
Как работает ForkJoinPool
Дизайн ForkJoinPool на самом деле прост и в то же время очень эффективен. Он основан на алгоритме “Разделяй и властвуй”: каждая задача разбивается на подзадачи по максимуму, затем они выполняются параллельно, и как только все из них завершаются, происходит объединение результатов.
Звучит знакомо? Да, параллельные потоки Java выполняются очень похожим образом.
Итак, у нас есть фреймворк, который следует вычислительной модели делимых задач, где каждая из них соответствует шаблону, подобному этому фрагменту псевдокода:

Эту задачу можно рекурсивно разделять на несколько подзадач до тех пор, пока не будет достигнуто заранее определенное состояние, когда уже можно счесть, что задача достаточно мала и ее можно выполнять. Примерно это и называется моделью Fork-Join.
Модель Fork-Join
Как мы сказали только что, модель fork-join — это метод, в котором мы разделяем каждую задачу (fork), а затем ждем объединения (join) всех получившихся подзадач и получаем результат.
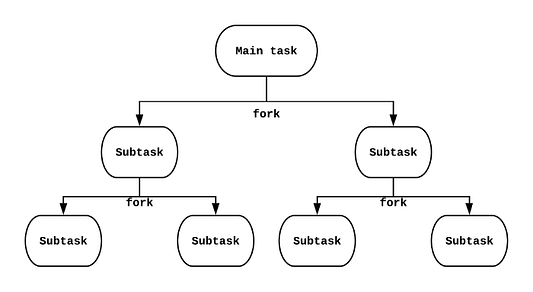
На рисунке выше видно, как каждая задача разделяется всякий раз, когда вызывается fork. Точно так же, когда все задачи завершаются, они объединяются посредством join для получения конечного результата.
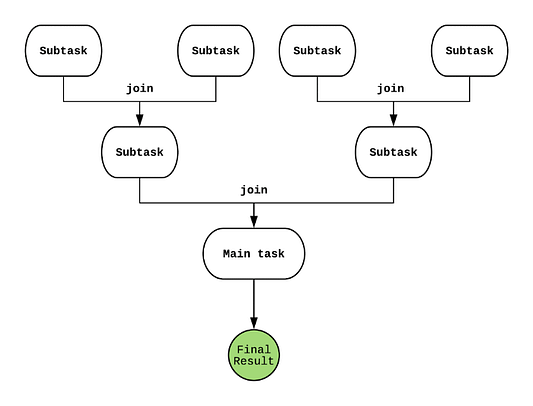
Теперь, когда мы понимаем, как работает эта модель, перейдем к самой важной части: как ForkJoinPool выполняет эти задачи внутри себя?
Внутреннее устройство ForkJoinPool
ForkJoinPool, как и любой пул потоков, состоит из заранее заданного числа потоков или рабочих групп. Когда мы создаем новый ForkJoinPool, уровень параллелизма по умолчанию (количество потоков) будет равен количеству доступных процессоров в системе. Их число возвращается методом Runtime.availableProcessors(). Имейте в виду: в нынешние времена, когда многократно задействована виртуализация (облачные виртуальные машины и Docker), у вашей JVM зачастую не будет столько доступных процессоров, сколько их есть на базовой машине.
Вы также можете создать свой собственный ForkJoinPool, указав, сколько потоков вам нужно. Только помните, что пул с числом потоков, превосходящим количество доступных процессоров, для задач с интенсивным использованием процессора полезен не будет. Однако, если у вас задачи интенсивного ввода-вывода (то есть им придется часто ждать завершения операций ввода-вывода), большой пул все-таки может пригодиться.
Каждый рабочий поток имеет собственную двухстороннюю рабочую очередь (deques) типа WorkQueue.
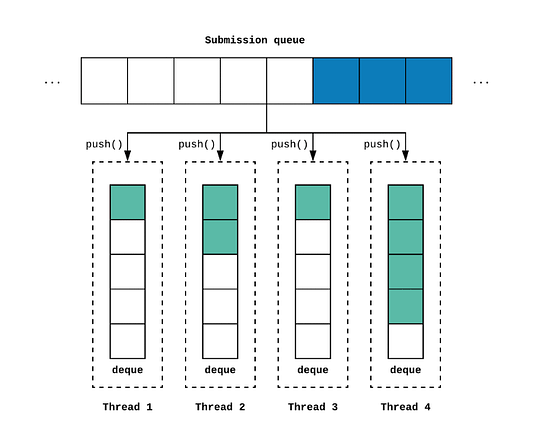
Таким образом, каждый из рабочих потоков продолжает сканировать доступные для выполнения подзадачи. Основная цель в том, чтобы как можно больше нагружать рабочие потоки и максимизировать использование ядер процессора. Поток блокируется только тогда, когда нет доступных для выполнения подзадач.
Что происходит, когда рабочий поток не может найти задачи для запуска в своей собственной очереди? Он будет пытаться “украсть” задачи у тех процессоров, которые загружены сильнее!
Вот тут-то и возникает интересный вопрос: как фреймворк гарантирует, что владелец очереди и “похититель” не будут мешать друг другу, если они попытаются перехватить задачу в одно и то же время?
Чтобы свести к минимуму конкуренцию и сделать ее более эффективной, как владелец очереди, так и “похитители” захватывают задачи из разных частей очереди.
Для вставки задач в очередь используется метод push(), а владелец очереди захватывает задачу, вызывая метод pop(). Таким образом, владельцем очереди сама очередь используется в качестве стека, и элементы извлекаются из его верхней части, как показано на рисунке:
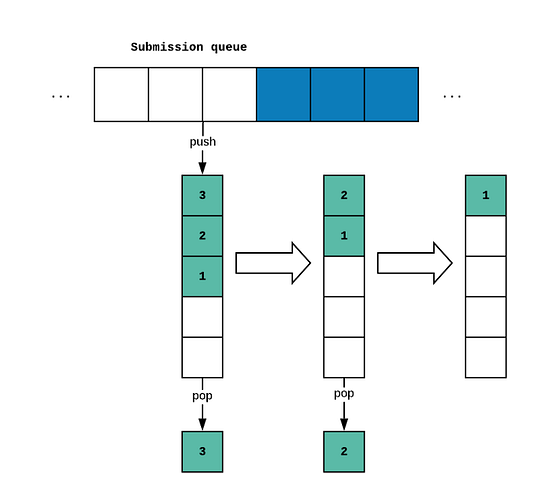
Здесь представлен метод LIFO — Last In, First Out (“последним вошел — первым вышел”). Почему именно так? Разве не разумнее было бы сначала обработать задачи, которые дольше пробыли в очереди?
Нет, не совсем. Основная причина — повышение производительности. Всегда, выбирая самую последнюю задачу, мы увеличиваем шансы на то, что ресурсы задачи все еще будут распределены в кэшах процессора, а это значительно повысит производительность. Это обычно называют локальностью ссылок.
С другой стороны, когда у рабочего потока заканчиваются задачи, он всегда будет забирать задачи из хвоста очереди другого воркера, вызывая метод poll().
В этом случае мы уже следуем подходу FIFO (“первым вошел — первым вышел”). Это в основном служит для уменьшения конкуренции, необходимой для синхронизации как владельцу очереди, так и “похитителю”.
Еще одна хорошая причина в том, что из-за природы самих делимых задач более старые задачи в очереди, скорее всего, будут больше по объему, поскольку еще не подверглись разделению.
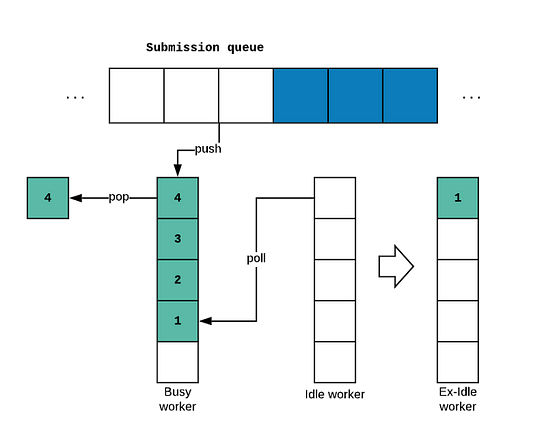
Методы push и pop вызываются только владельцем очереди, а метод poll вызывается только процессором, пытающимся “украсть” работу у другого процессора.
Методы push и pop — это операции CAS (Compare-and-Swap, сравнение с обменом) без ожидания, так что они весьма эффективны. Однако метод poll не всегда свободен от блокировки. Он блокируется в тех случаях, когда очередь почти пуста, поскольку требуется некоторая синхронизация для гарантии, что только владелец или похититель выберет данную задачу, но не оба сразу.
У этого фреймворка действительно любопытный дизайн.
Сводим все воедино
Учитывая то, что мы рассмотрели, становится совершенно очевидно, что для использования этой структуры нам понадобятся задачи, которые легко могут разделяться.
Вот где более чем уместны коллекции Java. Начиная с JDK 8, Java-коллекции можно легко делить, поэтому Java Streams и ForkJoinPool — идеальные партнеры!
Благодаря фреймворку ForkJoinPool параллельные потоки Java могут работать очень эффективно, оптимизируя использование доступных ядер!
Но что если для обработки нужного типа задачи неприменимы потоки Java? В этом случае можно создавать свои собственные “делимые” задачи, просто расширяя класс ForkJoinTask.
Что такое ForkJoinTask? ForkJoinTask — это Java-класс, который ведет себя аналогично потоку Java, но он гораздо более легкий. В основном потому, что ему не приходится поддерживать свой собственный стек времени выполнения или счетчики программ.
Существует три подтипа ForkJoinTask: RecursiveAction, RecursiveTask и CountedCompleter. Выбор того или иного подтипа будет зависеть от типа задач, которые вы пишете. Изучите документацию, чтобы понять, какой из них лучше всего соответствует вашим потребностям.
Стоит отметить, что эти три класса не являются функциональными интерфейсами, главным образом потому, что ForkJoinPool был выпущен в JDK7. Поэтому, к сожалению, лямбда-выражениями воспользоваться будет нельзя. Однако платформа параллельного потока Java 8 предоставляет функциональный API для прозрачного использования ForkJoinPool.
Давайте попробуем реализовать простую задачу с помощью ForkJoinTask. Напишем вычисление чисел Фибоначчи.
package com.theboreddev.examples.forkjoin;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.ForkJoinTask;
import java.util.concurrent.RecursiveTask;
public class ForkJoinExample {
public static void main(String[] args) {
final int numberOfProcessors = Runtime.getRuntime().availableProcessors();
final ForkJoinPool forkJoinPool = new ForkJoinPool(numberOfProcessors);
final ForkJoinTask<Integer> result = forkJoinPool.submit(new Fibonacci(30));
System.out.println("The result is : " + result.join());
}
static class Fibonacci extends RecursiveTask<Integer> {
private final int number;
public Fibonacci(int number) {
this.number = number;
}
@Override
protected Integer compute() {
if (number <= 1) {
return number;
} else {
Fibonacci fibonacciMinus1 = new Fibonacci(number - 1);
Fibonacci fibonacciMinus2 = new Fibonacci(number - 2);
fibonacciMinus1.fork();
return fibonacciMinus2.compute() + fibonacciMinus1.join();
}
}
}
}Вот и все. Наша задача будет разделена на несколько подзадач, и рабочие потоки ForkJoinPool будут действовать вместе, чтобы решить их все до одной.
Обратите внимание: в примере нам пришлось использовать BigInteger ради возможности обрабатывать большие числа, но это всего лишь одна из потенциальных реализаций ForkJoinTask.
Очень хорошая практика, которую стоит применять при написании ForkJoinTasks, — это всегда писать их как чистые функции, не разделяя состояние и избегая мутации объектов. Это лучший способ гарантировать, что подзадачи выполняются безопасно и независимо.
Также имейте в виду, что ForkJoinPool позволяет отправлять не только ForkJoinTasks, но также вызываемые (Callable) или выполняемые (Runnable) задачи, поэтому вы можете применять ForkJoinPool таким же образом, как и другие существующие исполнители. Единственное отличие в том, что ваша задача не будет разделяться сама по себе, но вы можете извлечь выгоду из повышения производительности кражи работы, если будет отправлено несколько задач и у некоторых потоков будет меньше загрузка, чем у других.
Если вам хочется лучше понять параллелизм и многопоточность, а также то, почему сейчас мы делаем всё именно таким образом, а не по-другому, я бы рекомендовал прочитать книгу “Параллелизм Java на практике” Брайана Гетца.
Заключение
Как мы убедились сегодня, модель Fork Join — эффективный способ обработки задач с использованием метода “Разделяй и властвуй”. Вместе с функцией “кражи работы” этот метод делает ForkJoinPool мощным инструментом для распараллеливания Java-кода.
В наше время ForkJoinPool несложно и прозрачно применяется вместе с Java Streams или CompletableFutures, поэтому, скорее всего, нам разве что изредка придется писать собственные делимые задачи. В любом случае всегда полезно понимать, как работает этот функционал, и знать, что такая возможность есть.
Спасибо за прочтение!
Читайте также:
- Состояния потоков в Java
- Новый подход к пониманию RxJava
- Избегаем исключения Null Pointer Exception в Java с помощью Optional
Читайте нас в Telegram, VK и Яндекс.Дзен
Перевод статьи: The Bored Dev, “The Unfairly Unknown ForkJoinPool”





