
Последние десять лет я почти целиком провел в специализированной продуктовой компании, создавая высокопроизводительные системы ввода-вывода. У меня была возможность наблюдать за быстрым, решительным развитием технологии хранения. Говорить о хранилище и его эволюции было все равно что учить ученого.
В этом году я сменил работу. Оказавшись в крупной компании с разработчиками из разных кругов, я был удивлен: хотя каждый из моих коллег, безусловно, умен, большинство из них неправильно представляли себе, как лучше всего применять производительность современных технологий хранения данных. Это приводило к появлению неоптимальных конструкций, даже если люди были осведомлены о растущем совершенствовании технологий хранения.
Причина таких заблуждений в основном в том, что если бы коллеги потратили время на проверку своих предположений с помощью контрольных показателей, то данные бы продемонстрировали, что предположения верны или, по крайней мере, кажутся верными на первый взгляд.
Распространенные примеры таких заблуждений:
- “Ничего страшного, если сделать копию памяти и выполнить дорогостоящее вычисление — это экономит нам одну операцию ввода-вывода, которая еще дороже”.
- “Я разрабатываю систему, которая должна работать быстро. Поэтому всё должно находиться в памяти”.
- Если разделить целое на несколько файлов, всё замедлится, потому что программа будет генерировать случайные шаблоны ввода-вывода. Нужно оптимизировать программу для последовательного доступа и чтения из одного файла”.
- “Прямой ввод-вывод очень медленный. Он работает только для специализированных приложений. Без собственного кэша вы обречены”.
Тем не менее, если вы заглянете в спецификации современных NVMe-устройств, то увидите вышедшие на рынок устройства с задержками в диапазоне микросекунд и пропускной способностью в несколько ГБ/с, поддерживающие несколько сотен тысяч случайных IOPS. Так где же разрыв?
В этой статье показывается, что, хотя аппаратное обеспечение сильно поменялось за последнее десятилетие, API не изменились или, по крайней мере, изменились недостаточно. Обремененные копиями памяти, распределением памяти, чрезмерно оптимистичным кэшированием упреждающего чтения и всевозможными дорогостоящими операциями, устаревшие API мешают извлечь максимум эффективности из современных устройств.
В ходе написания этой статьи мне выпало удовольствие получить ранний доступ к одному из устройств Optane следующего поколения от Intel. Хотя они еще не примелькались на рынке, но, безусловно, представляют собой венец тенденции на пути к всё более быстрым устройствам. Цифры, которые вы увидите в этой статье, были получены именно на данном устройстве.
В интересах экономии времени акцент в статье будет сделан на операциях чтения. У записей есть свой собственный уникальный набор проблем — а также возможности для улучшений, которые достойны отдельного материала.
Проблемы
С традиционными файловыми API есть три основных проблемы:
- Они выполняют много дорогостоящих операций, потому что “ввод-вывод стоит дорого”.
Когда устаревшим API нужно считать данные, которые не закешированы в памяти, они генерируют ошибку страницы. Затем, когда данные готовы, происходит прерывание. Наконец, для традиционного чтения на основе системных вызовов в пользовательский буфер поставляется дополнительная копия, а для операций на основе mmap приходится обновить отображения виртуальной памяти.
Ни одна из этих операций — ошибка страницы, прерывание, копирование или обновление отображения виртуальной памяти — не обходится дешево. Но много лет назад они все еще были примерно в сто раз дешевле, чем стоимость самого ввода-вывода, так что такой подход считался приемлемым. Теперь это уже не так, поскольку задержка современных устройств стремится к одноразрядным значениям в микросекундах. Эти операции теперь одного порядка с операцией ввода-вывода.
Быстрый расчет “на пальцах” показывает, что в худшем случае менее половины общей стоимости загрузки составляет стоимость связи с устройством как таковая. Это не считая всего, что тратится зря, что подводит нас ко второй проблеме:
- Усиление чтения.
Хотя я опущу здесь некоторые детали (например, память, используемая файловыми дескрипторами или различные кэши метаданных в Linux), если современные NVMe поддерживают множество параллельных операций, нет никаких оснований полагать, что чтение из многих файлов обходится дороже, чем чтение из одного. Однако совокупный объем прочитанных данных, безусловно, имеет значение.
Операционная система считывает данные с постраничным разбиением, что означает: она может читать только минимум 4 КБ за раз. Если вам нужно прочитать ввод величиной 1 КБ, разделенный на два файла по 512 байт каждый, это то же самое, как если вы читаете 8 КБ, чтобы обслужить 1 КБ, тем самым тратя впустую 87% прочитанных данных. На практике ОС также будет выполнять упреждающее чтение 128 КБ (настройка по умолчанию) для сохранения ваших циклов на случай, если вам позже понадобятся оставшиеся данные. Но если вам они не нужны, как это часто бывает при случайном вводе-выводе, то вы просто прочитаете 256 КБ, чтобы обслужить 1 КБ, и потратите впустую 99% из них.
Если у вас возникло искушение проверить мои слова, что чтение из нескольких файлов не будет принципиально медленнее, чем чтение из одного файла, вы можете в итоге убедиться в собственной правоте, но только потому, что усиление чтения значительно увеличило объем эффективно считываемых данных.
Поскольку проблема в кэше страниц ОС, то что произойдет, если вы при прочих равных условиях просто откроете файл с прямым вводом-выводом? К сожалению, скорее всего, быстрее не станет. Но это из-за третьего и последнего номера в списке проблем:
- Традиционные API не извлекают преимуществ из параллелизма.
Файл рассматривается как последовательный поток байтов, и независимо от того, находятся данные в памяти или нет, они прозрачны для читателя. Традиционные API будут ждать, когда стартует взаимодействие с нерезидентными данными, прежде чем выполнять операцию ввода-вывода. Операция ввода-вывода может быть больше объема, запрошенного пользователем, из-за упреждающего чтения, но все равно это всего лишь одна операция.
Однако, как бы ни были быстры современные устройства, они все равно медленнее процессора. Пока устройство ждет возврата операции ввода-вывода, процессор ничего не делает.
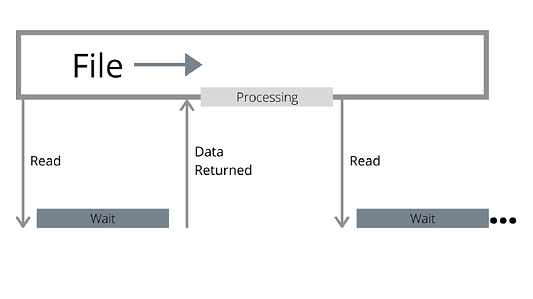
Задействование нескольких файлов — шаг в правильном направлении, поскольку это дает более эффективное распараллеливание: пока один читатель ждет, другой, по идее, может продолжить. Но если не проявить осторожность, то вы просто усилите одну из предыдущих проблем:
- Несколько файлов означают несколько буферов упреждающего чтения, что повышает коэффициент потерь для случайного ввода-вывода.
- В API на основе опроса потоков несколько файлов означают несколько потоков, что увеличивает объем работы, выполняемой за одну операцию ввода-вывода.
Не говоря о том, что во многих ситуациях вам оно не нужно: у вас может просто не быть такого количества файлов.
По направлению к лучшему API
В прошлом мне уже доводилось писать о том, насколько революционен io_uring. Но так как это интерфейс довольно низкого уровня, на самом деле он — всего лишь одна часть головоломки API. Вот почему:
- Ввод-вывод, отправленный через io_uring, все равно страдает от большинства перечисленных выше проблем, если задействованы буферизованные файлы.
- Прямой ввод-вывод содержит множество подводных камней, и io_uring, будучи “сырым” интерфейсом, даже не пытается (и не должен) скрыть какие-то из них: например, память должна быть организована правильно, и то же самое относительно позиции, откуда вы начинаете чтение.
- Он также очень низкоуровневый и сырой. Чтобы io_uring приносил пользу, нужно накапливать ввод-вывод и отправлять его партиями. Необходима настройка политики, когда это делать, и некоторая форма цикла событий, откуда следует, что io_uring лучше работает с фреймворком, в который уже встроены такие механизмы.
Для решения проблем с API я разработал Glommio (ранее известный как Scipio), библиотеку Rust, ориентированную на прямой ввод-вывод потоков на ядро. Glommio опирается на io_uring и поддерживает многие из его расширенных функций, таких как зарегистрированные буферы и основанные на опросах (без прерываний) завершения, что доводит прямой ввод-вывод до блеска. Для удобства Glommio поддерживает буферизованные файлы, поставляемые кэшем страниц Linux, наподобие стандартного API Rust (с которыми мы будем здесь проводить сравнение), но он ориентирован на то, чтобы привлечь внимание к прямому вводу-выводу.
В Glommio есть два класса файлов: файлы с произвольным доступом (Random access files) и потоки (Streams).
Файлы произвольного доступа занимают позицию аргумента, что снимает необходимость поддерживать курсор поиска. Но что еще более важно: они не принимают буфер в качестве параметра. Вместо этого они используют предварительно зарегистрированную буферную область io_uring для выделения буфера и возврата пользователю. Это означает, что нет отображения памяти, нет копирования в пользовательский буфер — есть только копия с устройства в буфер glommio, и пользователь получает ссылку на указатель. А поскольку мы знаем, что это случайный ввод-вывод, нет необходимости читать больше данных, чем запрошено.
pub async fn read_at<'_>(&'_ self, pos: u64, size: usize) -> Result<ReadResult>
Потоки, с другой стороны, предполагают, что вы в конечном итоге пройдете через файл целиком, и потому могут позволить себе больший размер блока и коэффициент опережения чтения.
Потоки разработаны так, чтобы по большей части сочетаться с AsyncRead, который по умолчанию применяется в Rust, поэтому они реализуют черту AsyncRead и все равно будут считывать данные в пользовательский буфер. Все преимущества прямого считывания на основе ввода-вывода по-прежнему в наличии, но присутствует копия между нашими внутренними буферами упреждающего чтения и пользовательским буфером. Это налог на удобство стандартного API.
Если нужна дополнительная производительность, glommio предоставляет API в поток, который также открывает необработанные буферы, сохраняя дополнительную копию.
pub async fn get_buffer_aligned<'_>(
&'_ mut self,
len: u64
) -> Result<ReadResult>Испытываем считывание
Для демонстрации этих API у glommio есть программа-пример, которая выдает ввод-вывод с различными настройками, применяя все эти API (буферизованный, прямой ввод-вывод, случайный, последовательный), и оценивает итоговую производительность.
Начнем с файла, размер которого составляет около 2,5x размера памяти, и просто прочитаем его последовательно как обычный буферизованный файл:
Buffered I/O: Scanned 53GB in 56s, 945.14 MB/s
Неплохо, конечно, учитывая, что этот файл не помещается в памяти, но вся заслуга принадлежит исключительной производительности Intel Optane и бэкенду io_uring. Параллелизм по-прежнему эффективно показывает себя один раз при отправке ввода-вывода, и хотя размер страницы ОС составляет 4 КБ, упреждающее чтение позволяет эффективно увеличить размер ввода-вывода.
И в самом деле, если бы мы попытались эмулировать подобные параметры с помощью API прямого ввода-вывода (буферы 4 КБ, параллелизм одного потока), результаты разочаровали бы нас, “подтверждая” подозрение, что прямой ввод-вывод действительно намного медленнее.
Direct I/O: Scanned 53GB in 115s, 463.23 MB/s
Но, как мы уже обсуждали, прямые потоки файлов ввода-вывода glommio могут принимать явный параметр опережения чтения. Если активный glommio будет выдавать запросы ввода-вывода до того, как позиция считана, то параллелизм устройства выйдет поставить себе на службу.
Упреждающе чтение Glommio работает иначе, чем упреждающее чтение на уровне ОС: наша цель — задействовать параллелизм, а не просто увеличить размер ввода-вывода. Вместо того, чтобы потреблять весь буфер упреждающего чтения и только затем отправлять запрос на новый пакет, glommio отправляет новый запрос, как только содержимое буфера полностью израсходовано, и всегда будет пытаться сохранить фиксированное количество буферов в обработке, как показано на рисунке ниже:
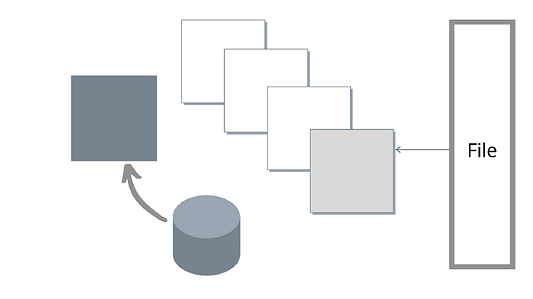
Как и предполагалось изначально, как только мы правильно применили параллелизм, установив коэффициент опережения чтения, прямой ввод-вывод окажется не только на равных с буферизованным вводом-выводом, но даже намного быстрее.
Direct I/O, read ahead: Scanned 53GB in 22s, 2.35 GB/s
В этой версии по-прежнему задействованы интерфейсы Asyncreadext Rust, которые заставляют дополнительную копию перемещаться из буферов glommio в пользовательские буферы.
API get_buffer_aligned дает необработанный доступ к буферу, чем избавляет от этой последней копии памяти. Если воспользоваться этим в нашем теперешнем тесте чтения, то мы получим улучшение производительности на достойные 4%
Direct I/O, glommio API: Scanned 53GB in 21s, 2.45 GB/s
Последний шаг — увеличить размер буфера. Поскольку это последовательное считывание, нет необходимости ограничиваться размером в 4 КБ, за исключением сравнения с версией кэша страниц ОС.
Теперь подведем итог всему, что происходит за кулисами с glommio и io_uring, в следующем тесте:
- каждый запрос ввода-вывода имеет размер 512 КБ;
- многие (5) из этих запросов хранятся в обработке для обеспечения параллелизма;
- память предварительно выделена и предварительно зарегистрирована;
- дополнительная копия в пользовательский буфер не выполняется;
- io_uring настроен на режим опроса, то есть нет копий памяти, нет прерываний, нет переключателей контекста.
Результаты?
Direct I/O, glommio API, large buffer: Scanned 53GB in 7s, 7.29 GB/s
Это более чем в семь раз лучше, чем стандартный подход с буфером. И что еще важнее, ни разу не было затрачено больше памяти, чем та величина, которую мы установили в качестве коэффициента опережения чтения, умноженного на размер буфера. В данном примере — 2,5 МБ.
Случайные чтения
Сканирование, как известно, губительно сказывается на кэше страниц ОС. Как мы справляемся со случайным вводом-выводом? Чтобы проверить, что мы будем читать столько, сколько сможем за 20 секунд, сначала ограничимся первыми 10% доступной памяти (1,65 ГБ).
Buffered I/O: size span of 1.65 GB, for 20s, 693870 IOPS
Для прямого ввода-вывода:
Direct I/O: size span of 1.65 GB, for 20s, 551547 IOPS
Прямой ввод-вывод происходит на 20% медленнее, чем буферизованное чтение. В то время как чтение полностью из памяти все еще быстрее — что никого не должно удивлять —, это далеко от ожидаемой катастрофы. На самом деле, если иметь в виду, что буферизованная версия сохраняет 1,65 ГБ резидентной памяти для достижения цели, в то время как прямой ввод-вывод использует только 80 КБ (20 x 4 КБ буфера), это даже предпочтительнее для определенного класса приложений, которым лучше задействовать эту память где-то еще.
Как сказал бы любой разработчик по производительности, хороший тест чтения должен считывать данные до той степени, чтобы добраться до конца. В конце концов, “хранилище медленное”. Таким образом, если мы теперь читаем из всего файла, буферизованная производительность резко падает — на 65%
Buffered I/O: size span of 53.69 GB, for 20s, 237858 IOPS
В то время как прямой ввод-вывод, как и ожидалось, сохраняет одинаковую производительность и одинаковое использование памяти независимо от объема считываемых данных.
Direct I/O: size span of 53.69 GB, for 20s, 547479 IOPS
Если взять более крупные сканы в качестве точки сравнения, то прямой ввод-вывод происходит в 2,3 раза быстрее (не медленнее), чем буферизованный.
Вывод
Современные NVMe-устройства меняют природу того, как лучше выполнять ввод-вывод в приложениях с отслеживанием состояния. Эта тенденция заметна уже некоторое время, но до сих пор была замаскирована тем, что API , особенно более высокого уровня, не эволюционировали в соответствии с тем, что происходило в устройствах — а в последнее время и на уровне ядра Linux. При правильном наборе API прямой ввод-вывод — это новый черный.
Современные устройства, такие как новейшее поколение Intel Optane, просто скрепляют сделку. Не существует сценария, в котором стандартный буферизованный ввод-вывод бесспорно превосходит прямой.
Производительность хорошо адаптированных API на основе прямого ввода-вывода в том, что касается сканирования, просто намного выше. И хотя стандартные API буферизованного ввода-вывода работают на 20% быстрее для случайных считываний, которые полностью помещаются в память, это происходит за счет двухсоткратного увеличения использования памяти, что делает компромисс не вполне бесспорным.
Приложения, которые действительно нуждаются в дополнительной производительности, все равно захотят кэшировать некоторые результаты, и обеспечение простого способа интеграции специализированных кэшей для дальнейшей работы с прямым вводом-выводом для glommio находится в разработке.
Читайте также:
- 7 Лучших курсов и книг по программированию на Rust для начинающих в 2021 году
- Rust или Си: кто Усэйн Болт в мире программирования?
- Rust: реализация двоичного дерева
Читайте нас в Telegram, VK и Яндекс.Дзен
Перевод статьи Glauber Costa: “Modern storage is plenty fast. It is the APIs that are bad”





