
Моделирование данных — это жизненно важная часть разработки ПО, а выбор подходящих структур данных или баз данных — основа успеха приложения или сервиса.
В этой статье мы рассмотрим ряд техник, используемых для моделирования областей данных с помощью графов. В частности, вы увидите, как размеченные графы свойств и графы баз данных могут послужить эффективным решением задач, с которыми мы сталкиваемся, когда используем в работе с сильно взаимосвязанными данными другие модели (например, реляционные БД).
К концу статьи мы создадим простую, но полностью рабочую реализацию размеченного графа свойств на Java, с помощью которого выполним несколько запросов для пробного набора данных.
Весь код вы можете найти на GitHub.
Предметная область: книжные отзывы
В качестве рабочего примера мы будем использовать набор данных из книжных отзывов. Он состоит из следующих CSV-файлов:
- BX-Users.csv, содержащего анонимные данные пользователей. Для каждого пользователя указан уникальный ID, место проживания и возраст.
- BX-Books.csv, содержащего ISBN (международный стандартный номер) каждой книги, её заголовок, автора, издателя и год издания. В этом файле также находятся ссылки на миниатюры обложек, но их мы использовать не будем.
- BX-Book-Ratings.csv, содержащего строку для каждого отзыва на книгу.
Если представить этот набор данных как ER-диаграмму, то выглядеть она будет так:

Некоторые поля денормализованы (например, Author, Publisher и Location). На данный момент невозможно сказать, подойдёт ли нам этот вариант (все будет зависеть от показателей производительности конкретных запросов), поэтому предположим, что данные нам нужны в нормальной форме. После нормализации ER-диаграмма приобретёт вот такой вид:
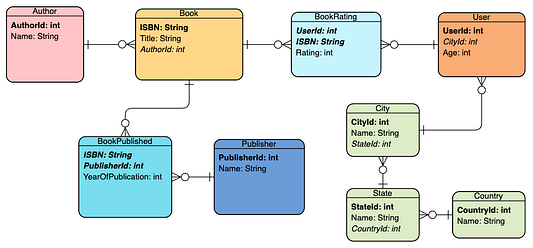
Обратите внимание, что мы разделили Location на 3 таблицы: City, State и Country, потому что исходное поле содержало три строки, например "San Francisco, California, USA".
Теперь предположим, что мы храним эти данные в реляционной БД. Как же выразить два следующих запроса с помощью SQL-кода?
- Запрос 1: получить средний рейтинг для каждого автора.
- Запрос 2: получить все отзывы о книге от пользователей из конкретной страны.
Если вы знакомы с SQL, то наверняка подумаете об операции соединенияjoin: всякий раз при наличии связей, охватывающих несколько таблиц, мы, как правило, перемещаемся по этим связям, соединяя пары таблиц с помощью главного и внешнего ключей.
Тем не менее, оба запроса задействуют нестандартное количество соединений, особенно второй. Это не всегда плохо — реляционные базы данных достаточно хорошо справляются с выполнением соединений. Однако слишком большое их число может привести к тому, что SQL-код станет трудно читать, поддерживать и оптимизировать.
Более того, чтобы перемещаться между связями “многих ко многим”, нужно соединить таблицы с помощью join tables(например, BookRating, BookPublished). Это стандартный шаблон, который, тем не менее, усложняет общую схему.
Можно денормализовать некоторые данные, но тогда возникнет побочный эффект, ограничивающий нас определённым представлением данных и снижающий гибкость модели.
Моделирование области с помощью классов Java
Теперь давайте предположим, что хотим сохранить весь набор данных в памяти. Выбранный нами вариант содержит менее миллиона записей, поэтому в памяти он легко поместится.
Сохранение данных в памяти идеально подходит для случаев, когда нужно поддерживать рабочую нагрузку только для чтения без гарантии последовательности и постоянства записи. Если всё же потребуется эту гарантию предоставить, то мы по-прежнему можем сохранить данные в памяти, но при этом, скорее всего, потребуется убедиться в потоковой безопасности структур данных и в сохранении изменений в энергонезависимой памяти.
Начнём с нескольких классов, например:
public class Book {
String isbn;
String title;
}
public class Author {
String name;
}Как нам связать эти классы и установить связь между книгами и авторами?
Допустим, что каждая книга написана только одним автором, и воспользуемся прямой ссылкой:
public class Book {
String isbn;
String title;
Author author; // прямая ссылка от книги к автору
}При таком подходе получить автора книги будет легко, однако обратный процесс (получение всех книг одного автора) обойдётся гораздо дороже, так как потребуется просканировать весь список книг. Например, чтобы найти все книги Дэна Брауна, нужно написать подобный запрос:
// Сканируем все книги, чтобы найти среди них те, что написаны Дэном Брауном. По большому счёту, это неэффективно
List<Book> danBrownBooks = books.stream()
.filter(b -> b.author.name.equals("Dan Brown"))
.collect(Collectors.toList());При наличии большого количества (скажем, миллионов) книг производительность будет низкой. Мы также могли бы сохранить ссылки на книги в самом классе Author:
public class Author {
String name;
List<Book> books; // прямая ссылка от автора к книге
}Однако и это решение недостаточно хорошее, так как изменять имя автора книги придётся в двух местах.
К тому же, как в таком случае обрабатывать связи, содержащие дополнительные данные? Например, связь между книгой и её издателем, которая содержит год издания — куда следует поместить это поле? Стоит ли объявить его в классе Book? Тогда как мы будем обрабатывать случаи, когда у книги есть несколько издателей и/или она издавалась несколько раз? Может, нам создать новый класс (например, BookPublished), применив шаблон join table реляционных баз данных?
Размеченные графы свойств
Реляционная модель и модель Java-ссылок определённо имеют общую черту: они представляют связи как данные сущности.
В обоих случаях сущность не только содержит атрибуты самой себя (например, таблица Book содержит свой заголовок и код ISBN), но также данные о том, как она связана с другими сущностями.
Такая сущностная (или табличная) модель, применяемая в RDBMS (системах управления реляционными базами данных), приносит хорошие результаты благодаря эффективности в хранении и извлечении огромного количества сущностей. Табличная модель справляется отлично в случаях, когда в данных есть много слабосвязанных сущностей. Однако если они содержат много связей, то представление их в качестве данных может привести к более сложным запросам и в конечном счёте снизить гибкость модели.
Графовые модели задействуют другой подход: в графе связи моделируются явно и аналогично сущностям рассматриваются как первичные составляющие модели данных.
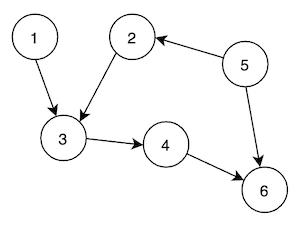
Вы можете припомнить из курса математики, что граф является набором узлов (иначе называемых вершинами), и рёбер (иногда называемых связями). Каждый узел хранит данные, а каждое ребро связывает два узла. Вот пример графа с 6 узлами и 6 рёбрами:
Модель размеченного графа свойств добавляет к нему ряд особенностей:
- Каждый узел и каждое ребро имеют метку, указывающую на их роль в модели данных.
- Каждый узел и ребро хранят набор свойств “ключ-значение”.
- У каждого ребра есть направление, т. е. граф направленный (в противоположность ненаправленным графам, где у рёбер направлений нет).
Эта модель используется в производственной среде такими графовыми базами данных, как Neo4j и Titan.
Как же смоделировать область книжных отзывов в виде размеченного графа свойств? Вот один из вариантов:
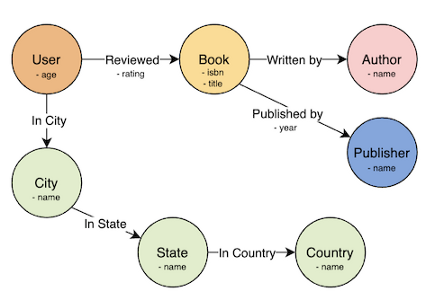
У узлов есть метки (например, узел Book отмечен как “Book”) и ряд свойств: к примеру, у узла Book есть два свойства: — isbn и title. Эти свойства соответствуют атрибутам сущности в ER-диаграмме.
У рёбер тоже есть метки (ребро, соединяющее User и Book отмечено как “Reviewed”). У некоторых рёбер к тому же имеются и свойства. Например, ребро Reviewed содержит свойство rating, которое хранит рейтинг, присвоенный пользователем книге, а у ребра Published by есть свойство year, указывающее год издания книги. У остальных рёбер свойств нет: к примеру, ребро In City, соединяющее пользователя с городом его проживания, не имеет свойств, так как дополнительные данные для этой связи не нужны.
На изображении выше вы видите схему модели графа. После создания его экземпляра и сохранения в нём данных выглядеть он будет уже так (это только подмножество всего графа):
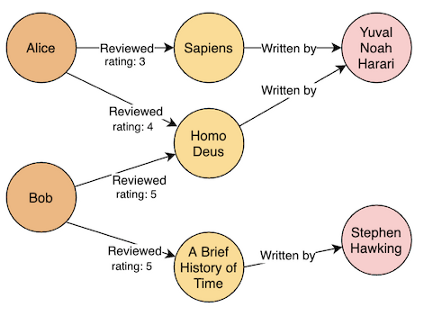
Эту схему можно легко нарисовать на доске. Когда дело доходит до связанных данных, применение графовой модели, пожалуй, будет весьма естественным и интуитивным.
Реализация размеченного графа свойств в Java
Весь код текущего раздела можно найти в репозитории на GitHub, где также содержится код для парсинга CSV-файлов с Kaggle.
Начнём мы с определения классов Node и Edge. Помимо них, мы определим стандартный суперкласс GraphElement, представляющий элементы с меткой и свойствами.
// У GraphElement есть метка и набор свойств
public class GraphElement {
public final String label;
public final Map<String, Object> properties = new HashMap<>();
public GraphElement(String label) {
this.label = label;
}
}
// Node является GraphElement с входящими и исходящими рёбрами
public class Node extends GraphElement {
public final String id;
public final List<Edge> outgoingEdges = new ArrayList<>();
public final List<Edge> incomingEdges = new ArrayList<>();
public Node(String label, String id) {
super(label);
this.id = id;
}
public Stream<Edge> incomingEdges(String edgeLabel) {
return incomingEdges.stream().filter(e -> e.label.equals(edgeLabel));
}
public Stream<Edge> outgoingEdges(String edgeLabel) {
return outgoingEdges.stream().filter(e -> e.label.equals(edgeLabel));
}
}
// Edge является GraphElement с исходным и целевым узлом
public class Edge extends GraphElement {
public final Node source;
public final Node target;
public Edge(String label, Node source, Node target) {
super(label);
this.source = source;
this.target = target;
}
}Здесь нет ничего удивительного, за исключением разве что полей outgoingRdges и incomingEdges в классе Node. Таким образом мы связываем узлы и рёбра и в дальнейшем будем перемещаться по графу для извлечения нужных данных, но об этом позже.
outgoingEdges и incomingEdges представлены в виде списков, но они также могут быть и множествами (как HashSet или TreeSet) либо другими структурами. Выбор зависит от ряда факторов, например, от наличия необходимости обеспечить уникальность каждого узла. Для приведённого здесь примера мы решили не усложнять задачу и использовали простые списки массивов.
Помимо этого, у каждого узла есть поле id. Очевидно, что главное назначение этого поля — гарантировать уникальность каждого узла.
Далее мы определим класс Graph, предоставляющий методы для создания узлов и рёбер:
// Graph содержит логику для создания узлов и рёбер, а также для извлечения узлов
public class Graph {
public final Map<String, Node> nodeIdToNode = new HashMap<>();
public final Map<String, Set<Node>> nodeLabelToNodes = new HashMap<>();
public Node createNode(String label, String id) {
if (nodeIdToNode.containsKey(id)) {
throw new DuplicateNodeException(id);
}
final Node n = new Node(label, id);
nodeIdToNode.put(id, n);
nodeLabelToNodes.get(label).add(n);
return n;
}
public Edge createEdge(String label, String fromNodeId, String toNodeId) {
final Node fromNode = getNode(fromNodeId);
final Node toNode = getNode(toNodeId);
final Edge e = new Edge(label, fromNode, toNode);
fromNode.outgoingEdges.add(e);
toNode.incomingEdges.add(e);
return e;
}
// ...
}Две карты nodeIdToNode и nodeLabelToNode позволяют извлекать узлы по их id и меткам. Это окажется особенно кстати при написании запросов.
Определяем класс BookReviewGraph как подкласс Graph:
public class BookReviewsGraph extends Graph {
// Метки узлов по сегментам
public static final String NODE_BOOK = "book";
public static final String NODE_AUTHOR = "author";
public static final String NODE_PUBLISHER = "publisher";
//...
// Метки рёбер по сегментам
public static final String EDGE_WRITTEN_BY = "writtenBy";
public static final String EDGE_PUBLISHED_BY = "publishedBy";
// ...
// Создаём узел book
private void addBook(String isbn, String title) {
// Используем ISBN в качестве id узла book
Node node = createNode(NODE_BOOK, isbn);
node.properties.put("isbn", isbn);
node.properties.put("title", title);
}
// Создаём между book и её author ребро 'writtenBy'
private void addWrittenBy(String isbn, String authorName) {
String id = "author-" + authorName;
Node node = createNodeIfAbsent(NODE_AUTHOR, id);
node.properties.put("name", authorName);
createEdge(EDGE_WRITTEN_BY, isbn, id);
}
// Создаём между book и её publisher ребро 'publishedBy'
private void addPublishedBy(String isbn, String publisher, int yearOfPublication) {
String id = "publisher-" + publisher;
createNodeIfAbsent(NODE_PUBLISHER, id);
Edge edge = createEdge(EDGE_PUBLISHED_BY, isbn, id);
edge.properties.put("year", yearOfPublication);
}
// ...
}Мы не используем случайно сгенерированные id (например, UUID). Вместо этого мы преобразовываем данные сущности в id, получая при этом два преимущества:
- облегчение отладки;
- облегчение выполнения запроса. Если мы будем искать книги по автору, то сможем просто запрашивать узел с id =
"author-" + authorName.
Примеры запросов
Основная реализация графа для области книжных отзывов завершена, а значит можно перейти к двум упомянутым выше запросам, а именно:
- Запрос 1: получить средний рейтинг каждого автора.
- Запрос 2: получить все книги, оценённые пользователями конкретной страны.
Шаблон для обоих запросов будет одинаков: начиная с узла (или набора узлов), мы проходим по рёбрам и узлам до тех пор, пока не достигнем данных, которые нужно вернуть.
В целом запрос к графу означает извлечение подграфа, т. е. конкретного шаблона узлов и рёбер, дающих желаемый ответ.
Запрос 1: средний рейтинг каждого автора
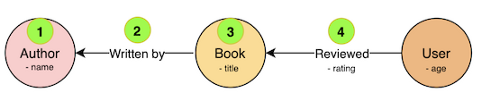
Этот запрос будет обходить раздел графа для извлечения нужных нам данных. Его можно разбить на 4 этапа:
- Начинаем с узла интересующего нас автора.
- Переходим через рёбра “Written by”, которые указывают на узел этого автора.
- Получаем исходные узлы рёбер “Written by”, которыми будут узлы книг.
- Переходим через рёбра “Reviewed”, которые указывают на узлы книг и извлекаем свойство
ratingкаждого из них.
Визуально это будет выглядеть так:
А в коде так:
// Возвращаем средний рейтинг по имени автора
public static double getAverageRatingByAuthor(BookReviewsGraph graph, String authorName) {
return graph
// (1) Начинаем с узла author
.getNodeById("author-" + authorName)
// (2) Из узла author берём входящие рёбра с меткой "EDGE_WRITTEN_BY"
.incomingEdges(BookReviewsGraph.EDGE_WRITTEN_BY)
// (3) Переходим к исходным узлам этих рёбер, т. е. к узлам book
.map(e -> e.source)
// (4) Из узлов book берём входящие рёбра с меткой "EDGE_REVIEWED"
.flatMap(n -> n.incomingEdges(BookReviewsGraph.EDGE_REVIEWED))
// Извлекаем свойство "rating" из каждого отношения отзыва
.mapToInt(e -> (int) e.properties.get("rating"))
// Берём среднее значение как двойное
.average()
// Если у автора нет рейтинга (и/или у нас неточные данные), просто возвращаем 0
.orElse(0.0);
}Используя этот запрос, можно легко найти средний рейтинг каждого автора:
// Возвращаем карту (отсортированную по рейтингу в порядке убывания) авторов и их рейтингов
public static LinkedHashMap<String, Double> getAuthorsByAverageRating(BookReviewsGraph graph) {
return graph
// Получаем всех авторов в графе
.getNodesByLabel(BookReviewsGraph.NODE_AUTHOR)
.stream()
// Получаем имя каждого автора
.map(a -> (String) a.properties.get("name"))
// Вычисляем средний рейтинг каждого автора
.map(a -> Map.entry(a, getAverageRatingsByAuthor(graph, a)))
// Сортируем по рейтингу в порядке убывания
.sorted(Comparator.comparingDouble(e -> -e.getValue()))
.collect(Collectors.toMap(Map.Entry::getKey, Map.Entry::getValue, (e1, e2) -> e1, LinkedHashMap::new));
}Вот вывод этого запроса при использовании нашего набора данных:
Gustavs Miller 10.0
World Wildlife Fund 10.0
Alessandra Redies 10.0
Christopher J. Cramer 10.0
Ken Carlton 10.0
Jane Dunn 10.0
Michael Easton 10.0
Howard Zehr 10.0
ROGER MACBRIDE ALLEN 10.0
Michael Clark 10.0
...Запрос 2: книги, оценённые пользователями из конкретной страны
Этот запрос применяет тот же шаблон, что и первый. Начинаем с узлов страны и обходим граф до тех пор, пока не получим узлы книг, после чего собираем их названия:
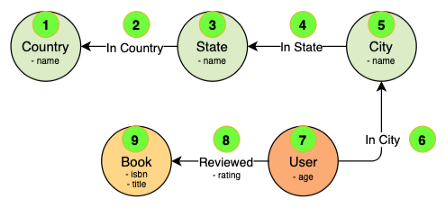
Код:
// Возвращаем названия всех оценённых пользователями книг по конкретной стране
public static Set<String> getBooksReviewedByUsersInCountry(BookReviewsGraph graph, String country) {
return graph
// (1) Получаем узел country, совпадающий с заданным названием страны
.getNodeById("country-" + country)
// (2) Берём входящие рёбра с меткой "EDGE_IN_COUNTRY"
.incomingEdges(BookReviewsGraph.EDGE_IN_COUNTRY)
// (3) Переходим к исходным узлам этих рёбер, т. е. к узлам state
.map(e -> e.source)
// (4) Берём входящие рёбра с меткой "EDGE_IN_STATE"
.flatMap(s -> s.incomingEdges(BookReviewsGraph.EDGE_IN_STATE))
// (5) Переходим к исходным узлам этих ребер, т. е. к узлам city
.map(e -> e.source)
// (6) Берём входящие рёбра с меткой "EDGE_IN_CITY"
.flatMap(c -> c.incomingEdges(BookReviewsGraph.EDGE_IN_CITY))
// (7) Переходим к исходным узлам этих рёбер, т. е. к узлам user
.map(e -> e.source)
// (8) Берём исходящие рёбра с меткой "EDGE_REVIEWED"
.flatMap(u -> u.outgoingEdges(BookReviewsGraph.EDGE_REVIEWED))
// (9) Переходим к целевым узлам этих рёбер, т. е. к узлам book
.map(e -> e.target)
// Извлекаем из узлов book свойство "title"
.map(b -> (String) b.properties.get("title"))
.collect(Collectors.toSet());
}Ниже вывод книг, оценённых в Италии:
La Tregua
What She Saw
Diario di un anarchico foggiano (Le formiche)
Kept Woman OME
Always the Bridesmaid
A Box of Unfortunate Events: The Bad Beginning/The Reptile Room/The Wide Window/The Miserable Mill (A Series of Unfortunate Events)
Aui, Language of Space: Logos of Love, Pentecostal Peace, and Health Thru Harmony, Creation and Truth
Pet Sematary
Maria (Letteratura)
Potemkin Cola (Ossigeno)
...Повышение производительности с помощью индексов
В обоих рассмотренных запросах начальной точкой графа является конкретный узел, который мы получаем через метод graph.getNodeById(). Однако этот способ работает лишь при наличии id стартового узла. При его отсутствии может потребоваться начать с набора узлов.
Предположим, что нам нужно написать код для следующего запроса:
- Запрос 3: получить средний возраст оценивших книгу пользователей по её названию.
Стартовый набор узлов составлен из книг с данным названием. Можно пройти по каждому узлу book и отфильтровать книги с несовпадающими названиями:
// Возвращаем средний возраст оценивших книгу пользователей по её названию
public static double getAverageAgeByBookTitle(BookReviewsGraph graph, String bookTitle) {
return graph
// Получаем все узлы с меткой book
.getNodesByLabel(BookReviewsGraph.NODE_BOOK).stream()
// Проходим по всем книгам и выбираем те, чьё название совпадает с заданным
.filter(b -> (b.properties.get("title").equals(bookTitle)))
.flatMap(b -> b.incomingEdges(BookReviewsGraph.EDGE_REVIEWED))
.map(e -> e.source)
.mapToInt(u -> (int) u.properties.get("age"))
.average()
.orElseThrow();
}В базах данных это называется полным сканированием таблицы: для того чтобы найти нужные книги, мы должны последовательно перебрать их все. Стоимость такой операции будет напрямую зависеть от количества книг, поэтому она может занять достаточно много времени.
Практически во всех случаях (за исключением разве что коротких последовательностей) увеличить производительность можно, используя карту, т. е. упрощённую версию индекса в базе данных.
Сначала мы создаём карту (booksByTitleIndex), которую обновляем при каждом добавлении новой книги:
public class BookReviewsGraph extends Graph {
// Индекс для быстрого поиска узлов книг по названию
public final Map<String, Set<Node>> booksByTitleIndex = new HashMap<>();
private void addBook(String isbn, String title) {
Node node = addNode(NODE_BOOK, isbn);
node.properties.put("isbn", isbn);
node.properties.put("title", title);
// Обновляем индекс books-by-title
booksByTitleIndex.computeIfAbsent(title, k -> new HashSet<>());
booksByTitleIndex.get(title).add(node);
}
}Теперь можно использовать этот индекс в начале нашего запроса:
// Возвращаем средний возраст оценивших книгу пользователей по её названию
public static double getAverageAgeByBookTitle(BookReviewsGraph graph, String bookTitle) {
return graph
// С помощью индекса находим книги, чьё название совпадает с заданным
.booksByTitleIndex.getOrDefault(bookTitle, Collections.emptySet())
.stream()
.flatMap(b -> b.incomingEdges(BookReviewsGraph.EDGE_REVIEWED))
.map(e -> e.source)
.mapToInt(u -> (int) u.properties.get("age"))
.average()
.orElseThrow();
}Вывод этого запроса для нашего набора данных при указании книги “Dracula”:
30.338983050847457
HashMap является хорошим выбором, когда нужно найти точные совпадения для конкретного свойства, так как средняя стоимость нахождения таких совпадений постоянна и составляет (O(1)).
Когда мы хотим найти сущности на основе общего порядка определённого свойства (к примеру, получить всех пользователей старше 25 лет), можно использовать другую структуру данных, например, TreeMap, где стоимость нахождения элементов логарифмична.
Если же нам понадобится найти элементы по префиксу, то для реализации индекса нужно будет использовать префиксное дерево.
Заключение
В этой статье мы рассмотрели моделирование области данных при помощи графов и реализацию простого размеченного графа свойств на Java. Приведённый код достаточно прост, и ему недостаёт обработки ошибок, а также потоковой безопасности, но при этом он послужит отличной отправной точкой для понимания и применения графового моделирования в областях данных.
В течение последних десяти лет в сообществе разработчиков ПО наблюдается рост интереса к графовым базам данных. Большая часть технологий, используемых в этих БД, не нова. К новому же можно отнести тот факт, что теперь у нас есть много взаимосвязанных данных, которые можно запрашивать, исходя из того, как связаны их элементы, а не просто по содержащимся в них значениям.
Читайте также:
- Микрооптимизации в Java. Enum - хороший, красивый и медленный
- 5 основных фреймворков для Java-разработчиков
- Аннотации для параллелизма в Java: расцвечивание потоков
Читайте нас в Telegram, VK и Яндекс.Дзен
Перевод статьи Alberto Venturini: Graph Data Modelling in Java





