
Скорее всего, для большинства из вас эти две концепции означают одно и то же, или же вы затрудняетесь объяснить, в чём между ними разница. Однако на самом деле они совершенно разные. И понять, как происходит в наши дни обработка данных, очень важно.
В обоих случаях мы пытаемся ускорить процесс решения проблемы, увеличивая число работников, занятых определённой задачей, но ключевое отличие в том, как между ними распределяется работа.
Для эффективной, безопасной и безошибочной обработки данных очень важно понимать разницу до конца, и сейчас вы поймёте, почему.
Давайте разбираться.
Введение
Для начала вкратце рассмотрим, что следует понимать под параллелизмом и конкурентностью.
Конкурентность
Говоря простым языком, конкурентность — это ситуация, когда для решения проблемы одна задача обрабатывается одновременно несколькими процессами. Давайте представим большой массив, где есть несколько процессов Worker и каждый из них выполняет некоторую работу над следующим по очереди элементом в массиве — и так пока мы не доберёмся до конца этого массива.
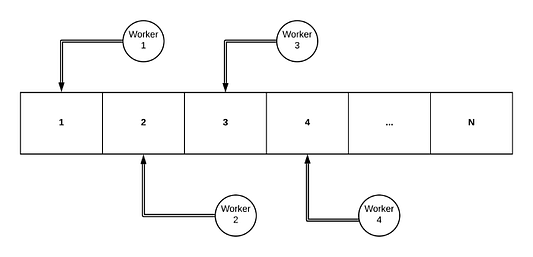
В ситуации конкурентности для доступа к ресурсу, который совместно используют все существующие процессы (в нашем примере это массив), требуется определённая синхронизация.
Сложность и излишние ресурсозатраты на производительность, связанные с этим подходом, могут оказаться очень значительными. Позже мы попытаемся это продемонстрировать.
Параллелизм
Параллелизм, с другой стороны, — это ситуация, когда для решения проблемы применяется подход “Разделяй и властвуй”, и проблема делится на некоторое количество проблем помельче. Это позволяет параллельно решать множество более мелких задач.
Как бы это выглядело на том же примере, который мы продемонстрировали выше? Представим, что у нас есть четыре процесса, работающих параллельно. Решение с помощью параллелизма будет выглядеть так:
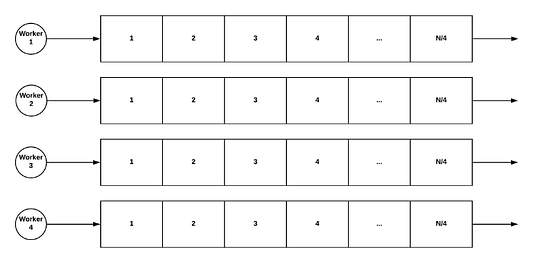
Как видите, разница существенная: теперь у нас четыре небольшие задачи, которые можно решать по отдельности. Зная это, можно утверждать: каждый процесс обрабатывает элементы последовательно! Когда все процессы завершают свою задачу, их результаты можно объединить и получить единственный окончательный результат.
Главное преимущество здесь в том, что не нужно синхронизировать доступ процессов к общему ресурсу, — теперь каждому процессу выделен свой, независимый от других, участок работы.
В стандартном последовательном процессе нашу задачу обрабатывал бы последовательно один Worker — это более распространённый подход, и в некоторых случаях он оказывается на удивление действенным.
Если вам хочется лучше понять, что такое параллелизм и многопоточность, а также почему сегодня мы работаем с ними так, а не иначе, рекомендуем к прочтению книгу Брайана Гетца “Java Concurrency in Practice”.
Решение задачи
Если мы сравним три имеющихся подхода с точки зрения производительности, то в большинстве случаев конкурентный подход гарантированно окажется намного менее эффективным. Почему? Как уже говорилось ранее, синхронизация потоков для доступа к общим ресурсам вызывает конфликты, что влияет на производительность.

Чтобы разобраться в причинах, рассмотрим пример.
Конкурентный подход
Задача, которую мы выберем для примера, заключается в сложении всех элементов в коллекции целых чисел. При конкурентном подходе мы будем использовать несколько потоков для добавления каждой пары элементов, чтобы попытаться ускорить процесс.
Прежде всего, создадим интерфейс для реализации решения с помощью различных подходов.
public interface Processor {
Integer process(List<Integer> input) throws InterruptedException;
}С учётом этого конкурентная реализация будет выглядеть так:
package com.theboreddev.concurrency;
import com.theboreddev.Processor;
import java.util.List;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicInteger;
import java.util.concurrent.atomic.LongAccumulator;
import java.util.stream.IntStream;
public class ConcurrentProcessor implements Processor {
private static final int THREADS = 4;
private final LongAccumulator result = new LongAccumulator(Long::sum, 0L);
private final AtomicInteger position = new AtomicInteger(0);
private final ExecutorService executor = Executors.newFixedThreadPool(THREADS);
@Override
public Integer process(List<Integer> input) throws InterruptedException {
processArrayConcurrently(input.toArray(new Integer[input.size()]));
return result.intValue();
}
private void processArrayConcurrently(Integer[] array) throws InterruptedException {
final Runnable runnable = () -> {
while (position.intValue() < array.length) {
addElements(array);
}
};
IntStream.rangeClosed(1, THREADS)
.forEach(threadNumber -> executor.submit(runnable));
executor.awaitTermination(1, TimeUnit.SECONDS);
}
private void addElements(Integer[] array) {
int current = position.getAndAdd(2);
final int sum = array[current] + array[current + 1];
result.accumulate(sum);
}
}Сделали мы по факту следующее: создали фиксированное количество потоков, где каждый поток добавляет пару элементов в массив до тех пор, пока не будет достигнут конец массива.
Заметьте, что мы использовали два важных класса Java, доступных в пакете java.util.concurrent.atomic(речь об AtomicInteger и LongAccumulator). Эти классы очень полезны, когда нужно синхронизировать доступ к текущей позиции и конечному результату. Однако они также могут оказать значительное влияние на итоговую производительность. Посмотрим же почему!
Внутренние атомарные переменные
Прежде всего, почему для поддержания текущей позиции мы решили применить AtomicInteger? Дело в том, что этот классхорошо подходит для ситуаций, когда несколько потоков видоизменяют одну переменную и (что ещё более важно) эта переменная читается очень часто.
AtomicInteger использует комбинацию “сравнения с обменом” и изменчивых переменных (volatile).
“Сравнение с обменом” — это улучшение в плане “синхронизированных” блоков, однако если поток попытается записать значение, которое уже изменилось, операция завершится неудачей, и ему придётся повторить попытку.
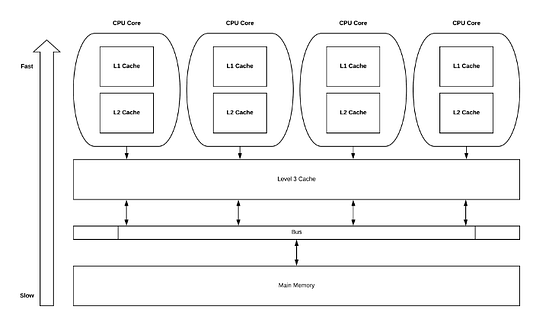
Кроме того, volatile-переменные подразумевают следующее: если к ним обращается поток, то в большинстве случаев их значение надо извлекать из основной памяти. Это значительно влияет на производительность, так как доступ к основной памяти стоит по ресурсам намного дороже, чем доступ на уровне кэша.
А что насчёт LongAccumulator? Этот тип класса полезен для ситуаций, когда несколько потоков записывают переменную, но она ни разу не читается до завершения операции. Как это работает? LongAccumulator умело использует неблокирующий подход, позволяя нескольким записям параллельно работать с отдельными счётчиками, а затем все они объединяются в конце процесса. Что-то вроде такого:
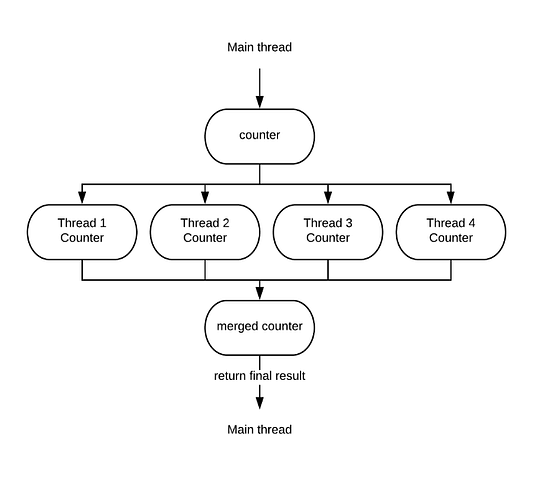
Разобравшись с тем, как работает решение на основе конкурентности, можно утверждать: узким местом данной реализации является синхронизация текущей позиции в массиве между различными потоками.
Теперь посмотрим на последовательную реализацию.
Последовательный подход
Последовательный подход незамысловат: мы просто обрабатываем каждый элемент последовательно в одном потоке. Вот как это выглядит:
package com.theboreddev.sequential;
import com.theboreddev.Processor;
import java.util.List;
public class SequentialProcessor implements Processor {
@Override
public Integer process(List<Integer> input) {
return input
.stream()
.reduce(Integer::sum)
.orElse(0);
}
}Мы перебираем элементы с помощью Java Stream и комбинируем их через метод reduce путём добавления каждой следующей пары.
Можно также задействовать стандартный цикл Java и проходить через каждый элемент итеративно, сохраняя сумму в отдельной переменной. В чём же проблема такого подхода? В основном в том, что его нелегко распараллелить. Для получения достоверного результата потребуется некоторый уровень синхронизации с применением конкурентного подхода.
Таким образом, последовательное решение не плохое по существу, хотя его можно улучшить в тех ситуациях, когда добавление большего количества потоков сократит время, необходимое для выполнения задачи. Это подводит нас к последнему подходу из списка, параллельному.
Параллельный подход
В прошлом реализовать параллельный подход было гораздо сложнее, но начиная с JDK 8, с появлением потоков Java, всё стало намного проще.
На самом деле параллельная реализация будет отличаться от последовательной одной-единственной строкой кода — за это спасибо Java Streams API:
package com.theboreddev.parallelism;
import com.theboreddev.Processor;
import java.util.List;
public class ParallelProcessor implements Processor {
@Override
public Integer process(List<Integer> input) {
return input
.parallelStream()
.reduce(Integer::sum)
.orElse(0);
}
}Проще простого, правда?
Итак, начинает казаться, что параллельное выполнение всегда будет быстрее последовательного. Вероятно, большинство из вас подумает, что это именно так, но, оказывается, не всё настолько очевидно. В чём же дело?
Для эффективной параллельной обработки необходимо учитывать различные аспекты, а это значит, что распараллеливание кода действительно улучшит производительность только при определённых условиях. Взглянем-ка на эти аспекты.

Параллельность против последовательности
Как уже говорилось, параллельный подход не всегда будет самым быстрым. Есть несколько нюансов, которые необходимо учесть, прежде чем распараллеливать код.
Достаточно ли велик объём данных, чтобы изменения на что-то повлияли?
Во многих случаях объём данных, которые нужно обработать, настолько мал, что к тому времени, когда данные будут разделены и распределены по нескольким потокам, последовательное выполнение с одним потоком уже завершится.
Легко ли поддаётся разделению источник данных?
Если данные не удастся легко разделить на равные части, это, вероятно, спровоцирует перерасход ресурсов, из-за чего мы лишимся всех преимуществ параллельного выполнения рабочих процессов.
Например, если источник данных — Iterator, то лёгкого разделения не выйдет. Однако, начиная с JDK 8, в Java для работы с разделяемым итератором был введён Spliterator.
Можно ли разделить данные на совершенно независимые, изолированные рабочие фрагменты?
Иногда каждый шаг зависит от результата выполнения предыдущего шага, и такую взаимозависимость невозможно разорвать. Такие задачи по сути своей последовательны, и будет абсолютно бессмысленно применять параллельный подход — никакой пользы это не принесёт.
Какова стоимость слияния результатов?
Объединить целые числа — не то же самое, что объединить несколько сложных деревьев, созданных разными потоками. Второе обойдётся очень дорого. Это всегда необходимо учитывать, так как при распараллеливании кода результаты могут оказаться неожиданными.
Нужно ли сохранять порядок, в котором обрабатываются элементы?
Возможности распараллеливания окажутся ограничены, если нужно сохранять порядок получения элементов. Необходимо знать, что потоки Java способны выполнять оптимизацию, когда известно, что данные не упорядочены.
Один из способов воспользоваться этим — применить unordered(), чтобы просигнализировать, что порядок нам безразличен. Это позволит оптимизировать многие непродолжительные операции, такие как findFirst(), findAny() или limit().
Промахи кэша
Реализация кода сказывается на производительности, и порой значительно. Например, структуры на основе массивов благоприятствуют распределению в кэшах центрального процессора. Когда мы получаем доступ к первому элементу, оборудование выделяет часть массива, потому что большую часть времени нам будет доступно большее количество элементов в массиве. Это положительно влияет на производительность, так как доступ к кэшу получить намного быстрее, чем к основной памяти.
Постоянные промахи кэша при параллельном выполнении приводят к тому, что наши потоки окажутся заблокированы в ожидании доставки данных из памяти, а значит потеряется часть преимуществ параллельных потоков.
Параллельное выполнение с потоками Java — почти что магия, но всё не так просто, как кажется на первый взгляд.
Итак, это были несколько аспектов, которые стоит иметь в виду при использовании параллельного выполнения. Теперь посмотрим на кое-какие показатели производительности для упомянутых выше реализаций и увидим, насколько осмысленна вся та теория, которую мы разобрали.
Сравнение производительности
В этом разделе мы продемонстрируем результаты тестов производительности на ранее рассмотренных нами реализациях и проверим, соответствует ли практический результат тому, что мы изучили.
JMH облегчает нам создание тестов. Из различных типов бенчмарков, доступных в JMH, был выбран бенчмарк “среднее время”.
Для первого запуска выберем размер в 1 000 000 элементов. Основываясь на его результатах, мы уже увидим, что делать дальше.
Первый бенчмарк: 1 000 000 элементов
Если хотите подробнее ознакомиться с тестами, исходный код можно найти здесь.
В общем, мы запустили две итерации для разогрева бенчмарка, чтобы дать JIT-компилятору достаточно времени на оптимизацию, а затем взяли результаты третьей итерации.
Итак, перейдём к сути — каковы эти результаты?
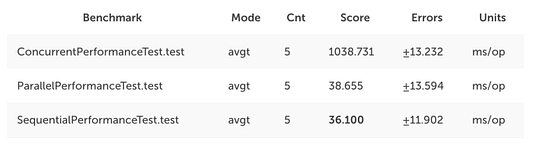
Как и ожидалось, конкурентный подход оказался наихудшим в смысле производительности: с ним выполнение занимает в среднем 1 секунду и 38 миллисекунд. Параллельный и последовательный подходы дали схожие результаты. Последовательный подход даже победил с опережением в две миллисекунды!
Как уже говорилось, не так-то просто написать эффективный параллельный код. Вероятно, одна из причин здесь в том, что данные были недостаточно большими. В таком случае давайте снова запустим наш бенчмарк, но уже с 10 000 000 элементов.
Второй бенчмарк: 10,000,000 элементов
Результаты:
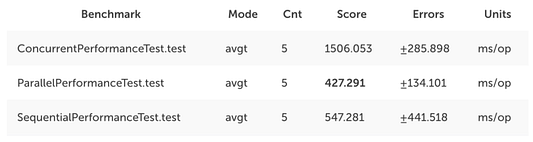
А вот теперь безусловным победителем становится параллельный подход. При этом также можно заметить, что значительно уменьшилось преимущество по сравнению с конкурентным подходом.
Таким образом, пришлось обработать целых 10 000 000 элементов, чтобы параллелизм дал какое-то значительное улучшение. Однако это всего лишь упрощённый пример — можно принять в рассмотрение другие аспекты и добиться дополнительных улучшений.
Заключение
Вот, что мы узнали: хотя потоки Java позволяют очень легко переключать код на параллельное выполнение, не всегда всё так просто.
Лучше всего всегда проводить тесты производительности, если она входит в число бизнес-требований, но не переусердствуйте с преждевременной оптимизацией. Если ускорение кода не приносит реальной пользы бизнесу, не тратьте зря свои время и силы.

И ещё кое-что: всегда полезно понимать, как работает каждый слой — от процессора до самой верхней части исходного кода приложения. Понимание внутренних механизмов и того, как они воздействуют на производительность, всегда помогает предвидеть сложности, возникающие в этом направлении.
Читайте также:
- Микрооптимизации в Java. Enum - хороший, красивый и медленный
- 5 основных фреймворков для Java-разработчиков
- Аннотации для параллелизма в Java: расцвечивание потоков
Читайте нас в Telegram, VK и Яндекс.Дзен
Перевод статьи: The Bored Dev, “When Parallelism Beats Concurrency”





