
Если вы программист, то наверняка слышали слово “компилятор”. Но знаете ли вы, что это такое на самом деле? Вы когда-нибудь задумывались, что происходит под капотом, когда вы запускаете команду javac(если у вас код на Java)? Вы когда-нибудь хотели создать свой собственный язык программирования? — и просто заводили бесполезный репозиторий GitHub, где все равно есть только один readme.md, потому что вы даже не знаете, с чего начать. Я думаю, что начинать стоит с этого: узнать больше о компиляторе.
Итак, в этой статье мы разберёмся, что представляет собой компилятор. Если вы опытный программист, который знает про компилятор каждую мелочь, то извините, эта статья не для вас. Но если вы — тот самый парень из абзаца выше, то вперёд за мной, в кроличью нору. На протяжении статьи я буду обсуждать следующие подтемы:
- введение в компилятор;
- типы компиляторов;
- архитектура компилятора.
Мне хочется, чтобы к концу статьи вы могли понимать, что происходит под капотом, когда вы запускаете команду javac, а также получили некоторое представление о том, как написать свой собственный язык программирования.
Вступление
Компилятор — это не что иное, как переводчик исходного кода.
Задача компилятора — перевести исходный код с одного языка на другой. Это означает, что если вы скормите компилятору исходный код Java, то сможете получить исходный код Python (не самый лучший пример, просто для понимания сути. На самом деле вы получите байт-код Java, который можно запустить на JVM). Для выполнения этого процесса у компилятора есть несколько взаимосвязанных компонентов.
Типы компиляторов
Мы можем классифицировать компиляторы по-разному. В этой статье я расскажу о двух способах классификации компиляторов, однако особенно углубляться в это не буду.
Классификация компиляторов в соответствии с этапами компиляции
Здесь мы рассмотрим количество этапов, которые проходит компилятор. Некоторые компиляторы непосредственно преобразуют высокоуровневый исходный код в машинный код, а некоторые — сначала преобразуют высокоуровневый исходный код в промежуточное представление перед преобразованием в машинный код.
Таким образом, в соответствии с этой классификацией можно выделить три типа компиляторов:
- Однопроходной компилятор.
- Двухпроходной компилятор.
- Многопроходной компилятор.
Если вы хотите узнать больше об этой классификации компиляторов, посмотрите сюда.
Классификация компиляторов в соответствии с исходным кодом и целевым кодом
Для преобразования исходного кода в целевой применяются разные подходы. Некоторые компиляторы преобразуют код на высокоуровневом языке в машинный. Некоторые компиляторы преобразуют с одного языка высокого уровня на другой язык высокого уровня. Таким образом, здесь выделяются следующие типы:
- Кросс-компиляторы — такие компиляторы работают на одной платформе и производят код для запуска на другой платформе. Например, компилятор работает на платформе X и создает код для запуска на платформе Y. Такими компиляторами пользуются разработчики встроенных систем.
- Традиционные компиляторы — нам лучше всего знаком именно этот тип компиляторов. Такие компиляторы преобразуют исходный код языка высокого уровня в исходный код машинного языка. Набор компиляторов GCC преобразует эти языки в низкоуровневые, которые выполняются на этих платформах.
- Транспилеры — они преобразуют исходный код языка высокого уровня в исходный код другого языка высокого уровня. Например, Babel transpiler преобразует ECMAScript 2015+ в JavaScript.
- Декомпиляторы — они принимают низкоуровневый исходный код в качестве входных данных и пытаются создать высокоуровневый исходный код, который может быть успешно перекомпилирован.
Архитектура компилятора
Когда компилятор компилирует (переводит) исходный код, он проходит несколько этапов:
- Исходный код.
- Лексический анализ.
- Синтаксический анализ.
- Семантический анализ.
- Промежуточная генерация кода.
- Оптимизация кода.
- Генерация кода.
- Целевой код.
Мы можем разделить все эти этапы на две фазы, примерно как фронтенд и бэкенд. Эти фазы включают в себя следующие этапы:
Фронтенд
- Лексический анализ.
- Синтаксический анализ.
- Семантический анализ.
- Генерация промежуточного кода.
Бэкенд
- Оптимизация кода.
- Генерация кода.
В следующем разделе я кратко опишу, что происходит на каждой фазе. Если вы не программируете компиляторы, то нормально иметь о них лишь поверхностное представление, но если вы хотите разработать компилятор сами, то вам стоит подробно изучить их работу.
Лексический анализ
Теперь вы знаете, что компилятор — это программа, которая преобразует исходный код в другой исходный код. Компилятор получает исходный код в виде файла. Этот файл содержит код в текстовом формате, но компилятор не может работать с этим текстом. Необходимо преобразовать этот текст в некоторый другой формат, понятный компилятору. Для этого компилятор разбивает текст по маркерам. Помните, что эти маркеры заранее определены в грамматике языка. Маркеры пригодятся на следующих этапах процесса компиляции:
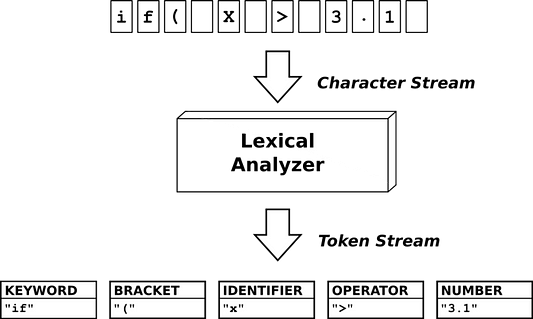
KEYWORD, BRACKET, IDENTIFIER, OPERATOR, NUMBER на приведенной выше диаграмме — это и есть маркеры. Компилятор использует лексический анализ для идентификации маркеров, и если он получает маркер, который не определен заранее в грамматике языка, то это будет считаться ошибкой.
Синтаксический анализ (парсинг)
На этом этапе компилятор проверяет, расположены ли идентифицированные ранее маркеры в правильном порядке. Для этого в каждом языке есть набор правил, называемый грамматикой. Во-первых, компилятор пытается построить структуру данных — дерево синтаксического анализа. Если компилятор смог успешно построить дерево синтаксического анализа в соответствии с заранее определенными правилами грамматики, то в исходном коде нет синтаксических ошибок. В противном случае возникают ошибки и компилятор их покажет.
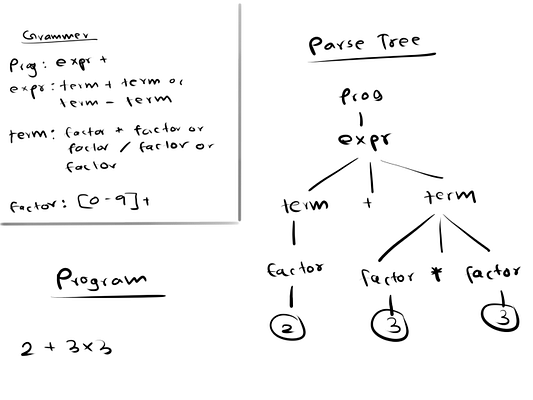
Здесь мы сначала определили грамматику. Затем компилятор пытается построить дерево синтаксического анализа для исходного кода 2 + 3 * 3. В этом случае компилятору удается построить дерево синтаксического анализа (с правой стороны) в соответствии с грамматикой, следовательно в этой программе нет синтаксических ошибок.
Семантический анализ
Просто потому, что программа не содержит синтаксических ошибок, код еще не может считаться правильным. Рассмотрим предложение ниже.
I love compilers
Теперь предположим, что все слова в этом предложении — правильные лексемы, идентифицированные на этапе лексического анализа. Как люди, мы знаем, что в предложении на английском языке есть порядок подлежащее -> сказуемое -> дополнение.

Компилятор при анализе синтаксиса может решить, что в этом предложении нет синтаксических ошибок, потому что маркеры (слова) расположены в правильном порядке.
Теперь рассмотрим предложение ниже.
I eat compilers
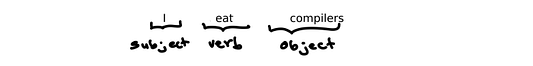
Предположим, что eat — правильный маркер в соответствии с грамматикой. Таким образом, предложение признается правильным на этапе лексического и синтаксического анализа, поскольку слова расположены в правильном порядке. Но в этом предложении нет никакого смысла — никто не может есть компиляторы.
Итак, согласно этапу семантического анализа, эта программа содержит ошибку. Мы называем эту разновидность ошибок семантическими ошибками. Взгляните на этот простой Java-код:
class SemanticAnalysis{
public static void main(String[] args){
int a = 5;
int b = 10;
int total = c + d;
}
}Здесь нет синтаксических ошибок. Все маркеры упорядочены правильно. Но на пятой строке int total = c + d — не имеет никакого значения, так как идентификаторы c и d не определены. Это и есть семантическая ошибка.
Генерация промежуточного кода
Любой компилятор может непосредственно генерировать машинный код из исходного. Так зачем же тогда нужна фаза генерации промежуточного кода?
Существуют различные типы машин. Таким образом, машинный код зависит от системы, а высокоуровневый исходный код — нет. Если компилятор непосредственно генерирует машинный код из исходного кода, то каждая машина нуждается в полной компиляции от фронта к бэку. Но когда компилятор генерирует промежуточный код (промежуточное представление), он уже может генерировать машинный код для каждой машины с его помощью, без повторения лексического анализа и парсинга для каждой машины.
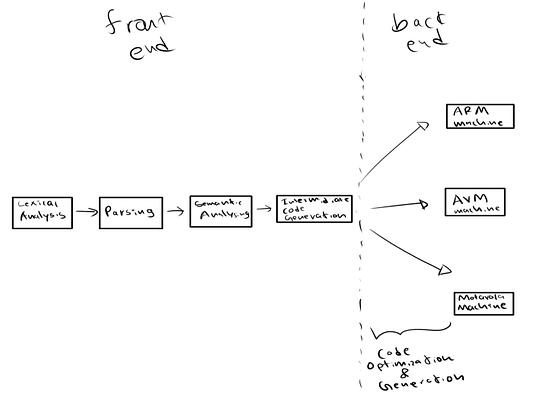
Существует два основных типа промежуточных представлений:
- Высокоуровневый — более близкий к высокоуровневому языку.
- Низкоуровневый — более близкий к машинному коду.
Существует также несколько способов представления промежуточного представления.
- AST — абстрактное синтаксическое дерево (графическое).
- Постфиксная нотация.
- Трехадресный код.
- Двухадресный код.
Оптимизация кода
Этап оптимизации кода выполняет две основные задачи: минимизация времени или минимизация ресурсов. Что все это значит? Когда пользователь пишет код, нет ничего, кроме инструкций. Когда процессор выполняет эти инструкции, требуют время и ресурсы памяти. Таким образом, целью этапа оптимизации кода становится сокращение времени выполнения и ресурсов, потребляемых программой. Оптимизатор кода всегда следует трем правилам:
- Выходной код никоим образом не должен изменять значение исходного кода.
- Минимизируйте либо время, либо ресурсы, либо и то и другое вместе.
- Фаза оптимизации кода сама по себе не должна занимать много времени и замедлять весь процесс компиляции.
Существует два способа оптимизации кода:
- Машинно-независимая оптимизация.
- Машинно-зависимая оптимизация.
Машинно-независимая оптимизация принимает промежуточное представление относительно входных данных и не заботится ни о каких регистрах процессора и ячейках памяти. Она происходит после генерации промежуточного кода.
При машинно-зависимой оптимизации кода компилятор заботится о регистрах процессора, расположениях памяти и архитектуре машины. Она происходит после генерации машинного кода.
Генерация кода
Генерация кода — это последний этап процесса компиляции. Да, после может следовать машинно-зависимая оптимизация кода. Но мы можем рассматривать и то, и другое вместе как генерацию кода. На этом этапе компилятор генерирует машинно-зависимый код. Генератор кода должен иметь представление о среде выполнения целевой машины и ее наборе команд.
На этом этапе компилятор выполняет несколько основных задач:
- Выбор инструкций — какую инструкцию использовать.
- Создание расписания инструкций — в каком порядке должны быть упорядочены инструкции.
- Распределение регистров — выделение переменных в регистры процессора.
- Отладка данных — отладка кода с помощью отладочных данных.
Итоговый машинный код, сгенерированный генератором кода, может быть выполнен на целевой машине. Именно так высокоуровневый исходный код, который мы пишем в нашем любимом редакторе кода, преобразуется в формат, который можно запустить на любой целевой машине.
В этой статье я предоставляю только краткое описание. Если вам хочется углубиться в эти концепции, к вашим услугам миллионы ресурсов в интернете.
Читайте также:
- Пять отличных Python-библиотек для data science
- Значение Data Science в современном мире
- Шесть рекомендаций для начинающих специалистов по Data Science
Читайте нас в Telegram, VK и Яндекс.Дзен
Перевод статьи Buddhika Chathuranga: “What is the Compiler”





