
Предварительно обученные модели представления языка
Существует два способа использования предобученных языковых моделей: извлечение признаков (feature-based), когда представления предварительно обученной модели используются в качестве дополнительных функций для архитектуры другой модели, и точная настройка (fine-tuning), при которой языковые представления используются для конкретных задач после точной настройки всех предварительно обученных параметров модели.
Знакомство с BERT
BERT (Bidirectional Encoder Representation Transformers), в переводе на русский “двунаправленная нейронная сеть-кодировщик” — модель представления языка, которая предназначена для предварительного обучения глубоких двунаправленных представлений на простых немаркированных текстах путем совмещения левого и правого контекстов во всех слоях. Это позволяет настраивать предварительно обученную модель BERT с помощью лишь одного дополнительного выходного слоя и получать наиболее актуальные результаты для широкого спектра задач.
Стандартные модели представления языка, существовавшие до BERT, например OpenAI GPT (генеративный предварительно обученный трансформатор), были однонаправленными. Это ограничивало выбор архитектур, которые можно использовать для предварительного обучения. Например, в OpenAI GPT каждый токен мог обслуживать только предыдущий токен (слева направо) в слое внутреннего внимания модели.
Такой подход создает ряд ограничений, поэтому для предварительного обучения BERT используют маскированную языковую модель (MLM): случайным образом маскируется некоторое количество токенов во входных данных, затем модель должна предсказать исходное значение замаскированных слов, исходя из контекста. Это предоставляет возможность совмещать левый и правый контексты, что в свою очередь позволяет предварительно обучить двунаправленную модель представлений.
Реализация
В структуре BERT есть два этапа:
1. Предварительное обучение — модель обучается на немаркированных данных, выполняя различные задачи.
2. Точная настройка — модель загружается с предварительно обученными параметрами и обучается на помеченных данных из последующих задач.
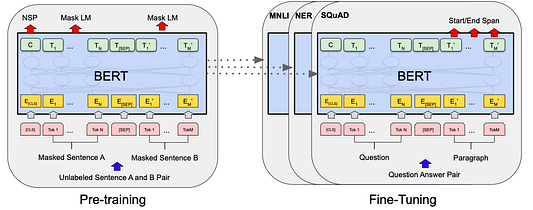
Представления на входе и выходе
Чтобы BERT научился обрабатывать различные задачи, на входе можно подавать как одно, так и пару предложений в одной и той же последовательности токенов. Модель использует эмбеддинг WordPiece со словарным запасом в 30 000 токенов. Первый токен в каждой последовательности — это специальный токен для классификации предложения [CLS], окончательное скрытое состояние которого используется в качестве представления совокупной последовательности для задач классификации. Предложения в последовательности различают двумя способами. Можно разделять их с помощью специального токена [SEP], а можно добавить заученный эмбеддинг к каждому токену, чтобы указать, принадлежит ли он предложению A или предложению B. Последний скрытый вектор специального токена обозначается как C, а последний скрытый вектор некоторого входного токенаi обозначается как Ti.
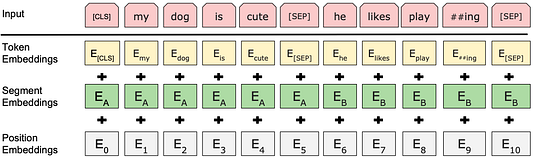
Для данного токена его входное представление строится путем суммирования соответствующих эмбеддингов токена, сегмента и позиции.
Задачи предварительного обучения
Задача 1 — маскированная языковая модель (MLM)
Стандартные модели можно обучать только слева направо или справа налево, в свою очередь двунаправленное обусловливание позволяет каждому слову непоследовательно видеть себя, а модель может тривиально предсказывать следующее слово в многослойном контексте. Чтобы обучить глубокое двунаправленное представление, случайный процент (15% в рассматриваемом примере) входных токенов маскируют и тренируют нейросеть предсказывать закрытые маской токены. Финальные скрытые векторы, соответствующие маскированным токенам, передаются в выходной softmax слой из словаря. Однако в результате получается несогласованность между предварительным обучением и точной настройкой, поскольку токен, используемый для маскировки [MASK], не появляется во время точной настройки. Чтобы исправить этот недостаток, маскированный токен заменяется на [MASK] в 80% случаев, заменяется случайным токеном в 10% случаев и остается неизменным в 10% случаев.
Задача 2 — предсказание следующего предложения (NSP)
Многие последующие задачи основаны на понимании отношений между предложениями. Это в какой-то степени отражает суть языкового моделирования. Чтобы обучить модель понимать отношения между предложениями, ее предварительно обучают бинаризованной задаче прогнозирования следующего предложения. При подготовке примеров предложений A и B для предварительного обучения в 50% случаев B — это фактическое следующее предложение, которое следует за A, а в 50% случаев B — случайное предложение из корпуса.
Данные для предварительного обучения
Корпуса, используемые для предварительного обучения:
1. BooksCorpus (800 млн слов)
2. English Wikipedia (2500 млн слов)
Точная настройка BERT
В BERT точная настройка выполняется путем простой замены соответствующих входных и выходных данных в зависимости от того, включают ли последующие задачи один текст или текстовые пары. Для каждой конкретной задачи подключают входные и выходные данные соответственно и полностью настраивают модель.
Результат предварительного обучения
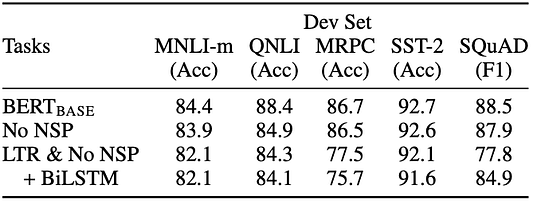
No NSP обучается без задачи прогнозирования следующего предложения. LTR & No NSP обучается как LM слева направо без задачи предсказания следующего предложения, как OpenAI GPT.
+ BiLSTM добавляет случайно инициализированный BiLSTM поверх модели LTR + No NSP во время точной настройки.
Влияние параметров архитектуры модели
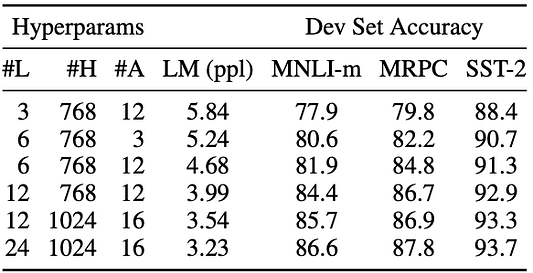
#L = количество слоев; #H = скрытый размер; #A = количество голов внимания. LM (ppl) — это степень неопределенности маскированной языковой модели LM удерживаемых обучающих данных.
Помимо этого в источнике подробно описываются несколько экспериментов с метриками BERT и feature-based подходк использованию BERT, которые мы не рассматриваем в этой статье.
BERT позволяет одной и той же предварительно обученной модели успешно решать самые разные задачи НЛП, такие как классификация текста, обнаружение сходства и многие другие.
Читайте также:
- ML-инженер или специалист по обработке данных? (Закат науки о данных?)
- Разработка и развёртывание приложения машинного обучения: полное руководство
- Когда ИИ или машинное обучение неуместны
Читайте нас в Telegram, VK и Яндекс.Дзен
Перевод статьи Vishal R: BERT — Read A Paper


")


