
Приложение для прогнозирования COVID-19: от и до
Похоже, коронавирус не спешит уходить из нашей жизни. Но мы можем не только носить маски и мыть руки. Давайте разработаем API на Python и приложение машинного обучения, быстренько напишем алгоритм прогнозирования COVID-19, развернём его и выложим на маркетплейс. Хотите узнать, как это сделать? Читайте дальше это пошаговое руководство.
Содержание
- Введение
- Предупреждение
- Инструментарий
- 1. Создаём всё необходимое для проекта
- 2. Разрабатываем решение
- Правильная установка пакетов и отслеживание файлов jupyter
- Выработка решения задачи
- Создание сервера для выполнения функции с REST
- БОНУС: обеспечение воспроизводимости с помощью Docker
- 3. Развёртываем на AWS
- Настройка zappa
- Настройка AWS
- 4. Настраиваем Rapidapi
- Итоговый результат
- Ссылки на исходный код и Rapidapi
Введение
В рамках проекта разберём ряд непростых вопросов:
- Контент, связанный с машинным обучением. В приложении выполняются основные этапы построения модели машинного обучения. Помимо подготовки, это ещё и прогнозирование.
- Своевременная оценка (а не своевременное обучение) прогноза. Это означает, что происходит получение свежего набора данных и прогнозирование выполняется на основе последней информации.
- Развёртывание. Развёртывание приложения машинного обучения сопряжено с различными трудностями. В статье мы решили вопрос с передачей обученной модели на AWS.
- Это не только API, но и небольшой фронтенд.
В статье показан процесс разработки API на Python от начала и до конца с разъяснением наиболее сложных частей, например настройки с помощью AWS Lambda.
При работе над проектом я и сам столкнулся с рядом трудностей, которые только помогли мне больше узнать о процессе создания и развёртывания. Кроме того, подобным образом можно создавать и другие проекты и даже попробовать заработать немного денег.
Как видно из содержания, статья состоит из 4 основных частей, а именно:
- Настройка среды.
- Создание решения с помощью Python.
- Настройка AWS.
- Настройка Rapidapi.
Весь код открыт на Github:
Итоговый результат можно найти здесь на Rapidapi:
Предупреждение
Я не считаю себя экспертом, поэтому, возможно, в статье будут упущены некоторые моменты. Кроме того, всегда следите за своими расходами на AWS: не платите за то, о чем вы не знаете.
Некоторые разделы предложенного руководства также можно улучшить и развить дальше. Например, часть проекта, связанная с машинным обучением, не слишком проработана, подготовка сыровата, а многие этапы отсутствуют. Но в одной статье всего ведь не распишешь.
Что касается термина «руководство»
Я считаю эту статью пошаговым руководством. Хоть и не эксперт, кое-какими знаниями определённых инструментов могу поделиться. Благодаря этим инструментам пошаговое руководство может помочь создать даже продвинутое приложение.
Понадобятся знания о:
- Python;
- Git;
- Jupyter Notebook;
- Команды терминала/команды оболочек Shell/Unix.
Инструментарий
Будем использовать:
- Github (для хранения кода);
- Anaconda (для управления зависимостями и средой);
- Docker (для возможного дальнейшего использования в микросервисах);
- Jupyter Notebook (разработка кода и документация);
- Python (язык программирования);
- AWS, особенно AWS Lambda и S3 (для развёртывания);
- Rapidapi (маркетплейс для продажи).
1. Создаём всё необходимое для проекта
Тут всегда одно и то же, но всё нужное. Делаем по пунктам:
- Создадим локальную папку
mkdir NAME. - Создадим новый репозиторий на Github с
NAME. - Создадим среду conda
conda create --name NAME python=3.7. - Активируем среду conda
conda activate PATH_TO_ENVIRONMENT. - Создадим гит-репозиторий
git init. - Подключимся к репозиторию на GitHub. Добавим файл Readme, закоммитим его
git remote add origin URL_TO_GIT_REPO
git push -u origin master
2. Разрабатываем решение
- Правильная установка пакетов и отслеживание файлов jupyter.
- Выработка решения задачи.
- Создание сервера для выполнения функции с REST.
- БОНУС: обеспечение воспроизводимости с помощью Docker.
Потребуется Jupyter Notebook, ведь мы разрабатываем приложение машинного обучения.
Правильная установка пакетов и отслеживание файлов Jupyter
Установим Jupyter Notebook и jupytext:
pip install notebook jupytext
Зарегистрируем новую среду в Jupyter ipython kernel install --name NAME--user.
Установим хук в .git/hooks/pre-commit для правильного отслеживания изменений в git:
touch .git/hooks/pre-commit
code .git/hooks/pre-commitСкопируем это в файл:
#!/bin/sh
# Для каждого файла ipynb в индексе git добавим представление в Python
jupytext --from ipynb --to py:light --pre-commitЗатем сделаем этот хук исполняемым (на Mac):
chmod +x .git/hooks/pre-commit
Выработка решения задачи
Раз уж пандемическая зараза не торопится уходить, я подумал: почему бы не использовать один из многочисленных наборов данных для выявления случаев заболевания Covid-19? С учётом структуры такого набора данных попробуем спрогнозировать количество новых случаев инфицирования в день по стране.
pip install -r requirements.txt
Этой командой установим все необходимые пакеты. Заглянем в /development/predict_covid.ipynb и узнаем, какие там есть библиотеки.
Самые важные библиотеки:
- pandas для преобразования набора данных;
- sklearn для машинного обучения.
Для более подробной информации о следующих подзаголовках перейдите, пожалуйста, по ссылке Jupyter Notebook:
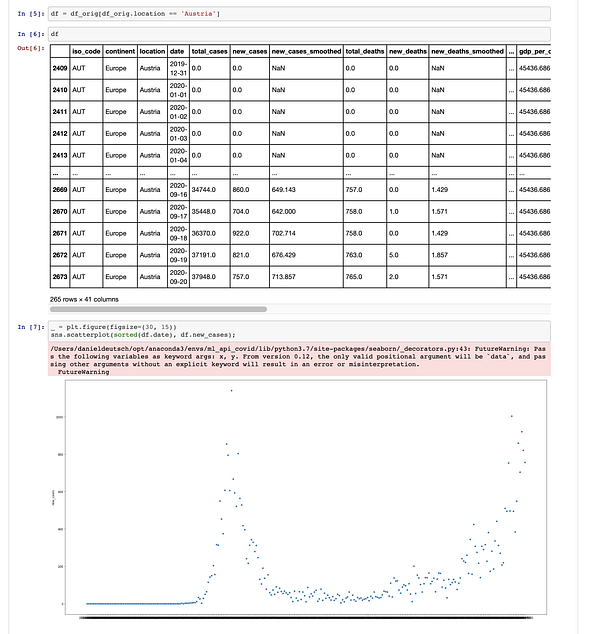
Загрузка данных
Будем использовать набор данных из https://ourworldindata.org/coronavirus-source-data в формате csv.
- Лицензия на использование данных Attribution 4.0 International (CC BY 4.0).
- Исходный код доступен на Github.
Подготовка
Если вкратце, вот что я сделал:
- Проверил, есть ли недостающие данные.
- Удалил колонки, где отсутствует более 50 % данных.
- Удалил оставшиеся незаполненными строки типа continent или isocode (не критично для нашего приложения, в котором нужны страны).
- Закодировал категориальные данные с помощью меток.
- Вместо остальных недостающих числовых данных оставил среднее значение по столбцу.
- Разделил данные на наборы для обучения и тестирования.
Создание классификатора и прогнозирование
- Создадим случайный регрессионный лес.
- Обучим его на данных и произведём оценку.
- Выполним настройку гиперпараметров с помощью RandomizedSearchCV.
- Сохраним обученную модель.
- Спрогнозируем количество новых случаев по стране.
Создание сервера для выполнения функции с REST
Для функциональности API будем использовать сервер Flask (в app.py).
Базовый фронтенд
@app.route('/')
def home():
return render_template("home.html")Который обслуживает базовый файл HTML и CSS:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Predict Covid</title>
<link type="text/css" rel="stylesheet" href="{{ url_for('static', filename='./style.css') }}">
</head>
<body>
<div class="page">
<form if="form" action="{{ url_for('predict')}}"method="POST">
<input type="text" name="country" placeholder="Country" required="required" /><br>
<h3 class='res'>{{pred}}</h3>
<button id="button" type="submit" class="btn btn-primary btn-block btn-large">Predict</button>
</form>
</div>
</body>
</html>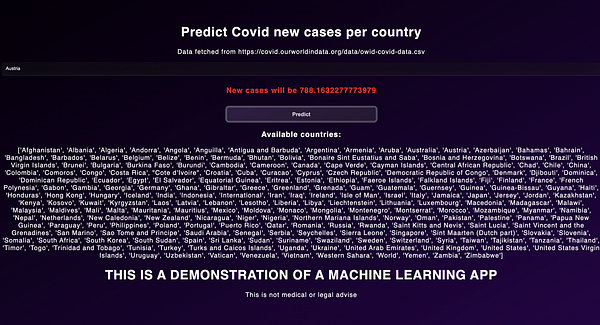
Прогнозирование нагрузки
Это немного сложнее.
Ключевой маршрут таков:
@app.route('/predict',methods=['POST'])
def predict():
input_val = [x for x in request.form.values()][0]
rf = load_model(BUCKET_NAME, MODEL_FILE_NAME, MODEL_LOCAL_PATH)
if input_val not in available_countries:
return f'Country {input_val} is not in available list. Try one from the list! Go back in your browser', 400
to_pred = get_prediction_params(input_val, url_to_covid)
prediction = rf.predict(to_pred)[0]
return render_template('home.html',pred=f'New cases will be {prediction}')Но прежде чем мы сможем вернуть результат прогнозирования, нужно получить последние данные и снова подвергнуть их предварительной обработке. Вот как это делается:
def pre_process(df):
cols_too_many_missing = ['new_tests',
'new_tests_per_thousand',
'total_tests_per_thousand',
'total_tests',
'tests_per_case',
'positive_rate',
'new_tests_smoothed',
'new_tests_smoothed_per_thousand',
'tests_units',
'handwashing_facilities']
df = df.drop(columns=cols_too_many_missing)
nominal = df.select_dtypes(include=['object']).copy()
nominal_cols = nominal.columns.tolist()
for col in nominal_cols:
col
if df[col].isna().sum() > 0:
df[col].fillna('MISSING', inplace=True)
df[col] = encoder.fit_transform(df[col])
numerical = df.select_dtypes(include=['float64']).copy()
for col in numerical:
df[col].fillna((df[col].mean()), inplace=True)
X = df.drop(columns=['new_cases'])
y = df.new_cases
return X, y
def get_prediction_params(input_val, url_to_covid):
df_orig = pd.read_csv(url_to_covid)
_ = encoder.fit_transform(df_orig['location'])
encode_ind = (encoder.classes_).tolist().index(input_val)
df_orig[df_orig.location == input_val]
X, _ = pre_process(df_orig)
to_pred = X[X.location == encode_ind].iloc[-1].values.reshape(1,-1)
return to_predВ процессе предварительной обработки (pre-process) снова происходит преобразование загруженного набора данных для целей машинного обучения, в то время как get_prediction_params принимает входное значение (страна, по которой делается прогноз) и URL-адрес последнего набора данных.
Всё это делает более точным прогноз для последних данных, но вместе с тем и замедляет приложение.
У вас может возникнуть вопрос: для чего здесь вот это rf = load_model(BUCKET_NAME, MODEL_FILE_NAME, MODEL_LOCAL_PATH)? Чтобы загрузить предварительно обученную модель из корзины AWS S3 и сэкономить память при выполнении всего с помощью AWS Lambda. Подробнее об этом чуть дальше в статье.
Если же развёртывать в облаке не нужно, то можно просто выполнить вот это joblib.load(PATH_TO_YOUR_EXPORTED_MODEL). В notebook экспортируем модель с помощью joblib.dump. Более подробная информация об экспорте моделей содержится в документации sklearn.
Такая она, функциональность сервера FLAK: предоставляет маршрут для обслуживания HTML-шаблона и маршрут для прогнозирования. Очень просто!
С помощью
env FLASK_APP=app.py FLASK_ENV=development flask run
запустим сервер:

БОНУС: обеспечение воспроизводимости с помощью Docker
Возможно, вы захотите масштабировать приложение или упростить его тестирование для других. Для этого можно создать контейнер Docker. Не будем подробно расписывать, как он работает. Если вам интересно, пройдите по одной из ссылок в конце статьи (пункт «Дополнительные ссылки»).
Внимание: это приложение может работать и без контейнера Docker!
Создание Dockerfile
FROM python:3.7
ENV PYTHONDONTWRITEBYTECODE=1
ENV PYTHONUNBUFFERED=1
ENV FLASK_APP=app.py
ENV FLASK_ENV=development
# установка системных зависимостей
RUN apt-get update \
&& apt-get -y install gcc make \
&& rm -rf /var/lib/apt/lists/*s
RUN python3 --version
RUN pip3 --version
RUN pip install --no-cache-dir --upgrade pip
WORKDIR /appCOPY ./requirements.txt /app/requirements.txt
RUN pip3 install --no-cache-dir -r requirements.txt
COPY . .
EXPOSE 8080
CMD ["gunicorn", "--bind", "0.0.0.0:8080", "app:app"]Примечание: последняя строчка предназначена для запуска сервера Flask.
Создав Dockerfile, запустим:
docker build -t YOUR_APP_NAME .
А затем:
docker run -d -p 80:8080 YOUR_APP_NAME
После чего приложение можно увидеть на http://localhost/.
3. Развёртываем на AWS
- Настройка zeppa.
- Настройка AWS.
- Учётные данные AWS.
- Развёртывание.
- AWS API Gateway — ограничение доступа.
Пока что всё было очень легко. Ничего сложного, ничего особенного. Самое интересное и сложное начнётся сейчас, когда приложение будет развёртываться.
Опять же не будем вдаваться в подробности, остановимся лишь на том, что может вызвать вопросы.
Настройка zappa
Создав приложение локально, приступим к настройке хостинга на реальном сервере. Будем использовать zappa.
Zappa позволяет очень легко создавать и развёртывать бессерверные, событийно-ориентированные приложения на Python (включающие, помимо прочих, веб-приложения стандарта WSGI) на AWS Lambda + API Gateway. Можно считать это «бессерверным» веб-хостингом для приложений на Python. А это бесконечное масштабирование, отсутствие простоев и обслуживания — намного меньше ваших возможных теперешних затрат на развёртывание!
pip install zappa
Мы используем среду conda. Укажем её:
which python
Получаем /Users/XXX/opt/anaconda3/envs/XXXX/bin/python (для Mac).
Удалим bin/python/ и экспортируем:
export VIRTUAL_ENV=/Users/XXXX/opt/anaconda3/envs/XXXXX/
Теперь мы можем ввести следующий код, чтобы настроить конфигурацию.
zappa init
Проходим всё и получаем вот такой zappa_settings.json:
{
"dev": {
"app_function": "app.app",
"aws_region": "eu-central-1",
"profile_name": "default",
"project_name": "ml-api-covid",
"runtime": "python3.7",
"s3_bucket": "zappa-eyy4wkd2l",
"slim_handler": true,
"exclude": [
"*.joblib", "development", "models"
]
}
}ВНИМАНИЕ: Не вводите имя для корзины s3, так как она не может быть найдена. Не знаю, в чём проблема с именем корзины s3, у меня так и не получилось с этим разобраться. Несколько раз появлялись ошибки в операторах, и я не смог решить эту проблему. Лучше оставьте то имя, которое есть, и всё будет работать нормально.
Но мы всё ещё не готовы к развёртыванию. Первым делом нужно получить учётные данные AWS.
Настройка AWS
Здесь придётся повозиться. И пусть вас не сбивает с толку сложность AWS и её управление политиками.
Учётные данные AWS
Сначала вам нужно получить access key id (идентификатор ключа доступа) и access key (ключ доступа) AWS.
Установим учётные данные с пользователями и правами в IAM
Разберём здесь всё подробно:
- В консоли AWS вводим
IAMв поле поиска. IAM — это панель, на которой отображаются пользователи и права доступа AWS. - Создаём группу.
- Присваиваем группе название (например, zappa_group).
- Создаём свою собственную встроенную политику для группы.
- Во вкладке Permissions (разрешения) в пункте Inline Policies (встроенные политики) выбираем ссылку для создания новой встроенной политики.
- В окошке Set Permissions (установка разрешений) нажимаем на переключатель Custom Policy (пользовательская политика) и кнопку справа Select (выбрать).
- Создаём пользовательскую политику, написанную в формате json.
- Прочтите и скопируйте политику отсюда: https://github.com/Miserlou/Zappa/issues/244.
- Посмотрите, как выглядит моя пользовательская политика (чуть ниже представлен её фрагмент).
- Вставив и заменив json на номер своей учётной записи AWS, нажимаем на кнопку Validate Policy (проверить политику) и убеждаемся, что скопирован валидный json. Затем нажимаем на кнопку Apply Policy (применить политику), чтобы закрепить за группой встроенную политику.
- Создаём пользователя и добавляем его в группу.
- Возвращаемся к панели IAM и создаём нового пользователя с помощью пункта меню слева Users (пользователи) и кнопки Add User (добавить пользователя).
- В окошке Add User (добавить пользователя) вводим имя нового пользователя и выбираем Access Type (тип доступа) для программного доступа. Затем нажимаем на кнопку Next: Permissions (далее: разрешения).
- В окошке Set Permissions (установка разрешений) выбираем группу, созданную ранее в пункте Add user to group (добавить пользователя в группу), и нажимаем на кнопку Next: Tags (далее: теги).
- Теги ставить необязательно. Добавив теги, нажимаем на кнопку Next: Review (далее: обзор).
- Просматриваем данные пользователя и нажимаем на кнопку Create user (создать пользователя).
- Копируем ключи пользователя.
- Окно AWS IAM пока не закрываем. На следующем этапе скопируем и вставим эти ключи в файл. А сейчас не помешает скопировать эти ключи в текстовый файл и сохранить в каком-нибудь безопасном месте. Убедитесь, что не сохраняете ключи под контролем версий.
Моя пользовательская политика:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"iam:AttachRolePolicy",
"iam:GetRole",
"iam:CreateRole",
"iam:PassRole",
"iam:PutRolePolicy"
],
"Resource": [
"arn:aws:iam::XXXXXXXX:role/*-ZappaLambdaExecutionRole"
]
},
{
"Effect": "Allow",
"Action": [
"apigateway:DELETE",
"apigateway:GET",
"apigateway:PATCH",
"apigateway:POST",
"apigateway:PUT",
"events:DeleteRule",
"events:DescribeRule",
"events:ListRules",
"events:ListRuleNamesByTarget",
"events:ListTargetsByRule",
"events:PutRule",
"events:PutTargets",
"events:RemoveTargets",
"lambda:AddPermission",
"lambda:CreateFunction",
"lambda:DeleteFunction",
"lambda:DeleteFunctionConcurrency",
"lambda:GetAlias",
"lambda:GetFunction",
"lambda:GetFunctionConfiguration",
"lambda:GetPolicy",
"lambda:InvokeFunction",
"lambda:ListVersionsByFunction",
"lambda:RemovePermission",
"lambda:UpdateFunctionCode",
"lambda:UpdateFunctionConfiguration",
"cloudformation:CreateStack",
"cloudformation:DeleteStack",
"cloudformation:DescribeStackResource",
"cloudformation:DescribeStacks",
"cloudformation:ListStackResources",
"cloudformation:UpdateStack",
"cloudfront:UpdateDistribution",
"logs:DeleteLogGroup",
"logs:DescribeLogStreams",
"logs:FilterLogEvents",
"route53:ListHostedZones"
],
"Resource": [
"*"
]
},
{
"Effect": "Allow",
"Action": [
"s3:CreateBucket",
"s3:ListBucket",
"s3:ListBucketMultipartUploads",
"s3:ListAllMyBuckets",
"s3:GetObject"
],
"Resource": [
"arn:aws:s3:::zappa-*",
"arn:aws:s3:::*"
]
},
{
"Effect": "Allow",
"Action": [
"s3:DeleteObject",
"s3:GetObject",
"s3:PutObject",
"s3:AbortMultipartUpload",
"s3:ListMultipartUploadParts"
],
"Resource": [
"arn:aws:s3:::zappa-*/*"
]
}
]
}Как видите, я добавил политики, связанные с S3. Ведь предварительно обученную модель придётся загружать из S3. Более подробно об этом чуть дальше.
Добавляем учётные данные в проект
В корневом каталоге создаём папку .aws/credentials с помощью:
mkdir ~/.aws
code ~/.aws/credentialsВставляем свои учётные данные из AWS:
[dev]
aws_access_key_id = YOUR_KEY
aws_secret_access_key = YOUR_KEYТо же самое и с config:
code ~/.aws/config
# и добавляем:
[default]
region = YOUR_REGION (eg. eu-central-1)Обратите внимание: для открытия папки code используется vscode, выбранный мной в качестве редактора.
Сохраняем назначенные пользователю идентификатор ключа доступа и секретный ключ доступа AWS, которые были созданы в файле ~/.aws/credentials. Каталог .aws/ должен находиться в вашем домашнем каталоге, а файл учётных данных не имеет расширения.
Развёртывание
Теперь можно развернуть API с помощью команды:
zappa deploy dev
Но при этом следует учитывать, что:
- Zappa упакует всю среду вместе со всем содержимым корневого каталога. И это будет довольно большой объём.
- Имеется ограничение загрузки для AWS Lambda.
Уменьшаем размер загрузки
Существуют разные мнения о том, как можно уменьшить размер загрузки с zappa. Ознакомиться с ними можно в конце статьи (пункт «Дополнительные ссылки»).
Первым делом нужно уменьшить размер подгружаемого пакета.
Поместим всю исследовательскую часть в отдельную папку с названием development (разработка). Затем можно указать исключённые файлы и папки в zappa_settings.json с помощью exclude:
{
"dev": {
...
"slim_handler": true,
"exclude": [
"*.ipynb", "*.joblib", "jupytext_conversion/", ".ipynb_checkpoints/",
"predict_covid.ipynb", "development", "models"
]
}
}Можно добавить всё, что не было упаковано для развёртывания.
Дальше надо разобраться с зависимостями среды. В нашем случае имеется несколько зависимостей, которые не нужны для развёртывания. Создаём новый файл requirements_prod.txt. В нём должны быть только те зависимости, которые необходимы в AWS.
Обязательно экспортируем имеющиеся пакеты:
pip freeze > requirements.txt
После этого все пакеты удаляем:
pip uninstall -r requirements.txt -y
Устанавливаем новые пакеты для развёртывания и сохраняем их в файле:
pip install Flask pandas boto3 sklearn zappa
pip freeze > requirements_prod.txt
Теперь при вводе zappa deploy dev размер пакета должен быть значительно меньше.
Вы могли заметить, что я выставил slim_handler=true. Это позволяет загружать более 50 МБ. А тем временем Zappa уже помещает контент в свою корзину S3. Более подробную информацию читайте в документации zappa.
Загружаем модель в корзину S3
Теперь нам нужно откуда-то взять модель, которая была исключена из загрузки AWS Lambda. Будем использовать AWS S3 корзину.
В процессе разработки мы пытались загрузить её туда программным образом, но в итоге сделали это вручную: так было просто быстрее. Тем не менее вы можете попробовать загрузить — у меня в репозитории ещё есть закомментированный файл.
Перейдём к https://console.aws.amazon.com/s3/.
- Создаём корзину.
- Присваиваем ей название, остальное оставляем по умолчанию. Проверяем наличие достаточных разрешений.
- Создаём корзину.
Проверяем, есть ли подходящая политика для взаимодействия с корзиной и boto3. Должно получиться что-то вроде этого:
{
"Effect": "Allow",
"Action": [
"s3:CreateBucket",
"s3:ListBucket",
"s3:ListBucketMultipartUploads",
"s3:ListAllMyBuckets",
"s3:GetObject"
],
"Resource": [
"arn:aws:s3:::zappa-*",
"arn:aws:s3:::*"
]
}Отладка и обновления
Никаких ошибок больше быть не должно. А если они есть, можно выполнить отладку:
zappa status
# и
zappa tailНаиболее распространенные ошибки связаны с разрешениями (и тогда проверяем политику разрешений) или с несовместимыми библиотеками Python. В любом случае при отладке в zappa выдаются достаточно понятные сообщения об ошибках. Среди ошибок можно выделить такие:
- Проблемы политики, связанные с пользователем из IAM.
- Zappa и проблемы с размером.
- Boto3 и проблемы с разрешением/местоположением файлов.
При обновлении кода не забывайте обновлять также и развёртывание:
zappa update dev
AWS API Gateway — ограничение доступа
Прежде чем выводить API на рынок (маркетплейс), сначала нужно ограничить его использование API-ключом.
Разберём здесь всё подробно:
- Переходим в консоль управления AWS и в API gateway.
- Нажимаем на свой API.
- Нужно создать x-api-key для ограничения нежелательного доступа к API и введения лимитированного его использования.
- Создаём план использования API с ограничениями на количество запросов и квот.
- Создаём соответствующий API stage.
- Добавляем API-ключ.
- В разделе API key overview (обзор API-ключа) нажимаем на show (показать) в API-ключе и копируем его.
- Затем привязываем этот ключ к API, и дальше все запросы, которые приходят без этого ключа, будут игнорироваться.
- Возвращаемся к API overview (обзору API). Во вкладке resources (ресурсы) нажимаем на / any и переходим к method request (запросу метода). После чего в настройках устанавливаем для API key required значение true.
- То же самое делаем для методов /{proxy+}.
Теперь доступ к API ограничен.
4. Настройка Rapidapi
- Добавляем новый API.
- Тестируем конечную точку с rapidapi.
- Создаём код для использования API.
Итоговый результат
Типичные проблемы
- https://github.com/Miserlou/Zappa/issues/1927 (ошибка с пакетом: python-dateutil).
- https://stackabuse.com/file-management-with-aws-s3-python-and-flask/.
- https://ianwhitestone.work/zappa-zip-callbacks/ (удаление ненужных файлов в zappa).
- https://stackoverflow.com/questions/62941174/how-to-write-load-machine-learning-model-to-from-s3-bucket-through-joblib.
Ссылки на исходный код и Rapidapi
Открытый исходный код: https://github.com/Createdd/ml_api_covid.
На Rapidapi: https://rapidapi.com/Createdd/api/covid_new_cases_prediction.
Читайте также:
- Когда ИИ или машинное обучение неуместны
- 25 наборов аудиоданных для исследований
- Крутые наборы данных для машинного обучения
Читайте нас в Telegram, VK и Яндекс.Дзен
Перевод статьи Daniel Deutsch: Develop and sell a Machine Learning app — from start to end tutorial





