
Главная идея потоков заключается в выполнении последовательности таких инструкций внутри программы, которые могут выполняться независимо от другого кода.
Так в чём же разница между потоковой и многопроцессорной обработкой данных? При одновременном выполнении нескольких задач обычно используется потоковая обработка, а при процессно-ориентированном параллелизме задействуется многопроцессорная обработка.
Задачи с ограничением скорости вычислений и ввода-вывода
Время выполнения задач, ограниченных скоростью вычислений, полностью зависит от производительности процессора, тогда как в задачах I/O Bound скорость выполнения процесса ограничена скоростью системы ввода-вывода.
В задачах с ограничением скорости вычислений программа расходует большую часть времени на использование центрального процессора, то есть на выполнение вычислений. К таким задачам можно отнести программы, занимающиеся исключительно перемалыванием чисел и проведением расчётов.
В задачах, ограниченных скоростью ввода-вывода, программы обрабатывают большие объёмы данных с диска в сравнении с необходимым объёмом вычислений. К таким задачам можно отнести, например, подсчёт количества строк в файле.
Проблема GIL на Python
Обычно на Python используется только один поток для выполнения нескольких записанных инструкций, то есть одновременно выполняется только один поток. Производительность однопоточного и многопоточного процессов здесь одинакова, и происходит это из-за GIL (Global Interpreter Lock — глобальной блокировки интерпретатора). Эта глобальная блокировка интерпретатора сама действует как поток и ограничивает другие потоки, делая невозможной многопоточность на Python.
Процессы ускоряют операции на Python, которые создают интенсивную вычислительную нагрузку на центральный процессор, используя сразу несколько ядер и избегая GIL, в то время как потоки лучше подходят для задач ввода-вывода или задач, связанных со внешними системами, потому что потоки могут более эффективно работать вместе. Для объединения процессов им нужно сериализовывать свои результаты, на что требуется время.
Потоки на Python не дают никаких преимуществ для задач, создающих интенсивную вычислительную нагрузку на процессор, именно из-за GIL.
Зачем нужен GIL?
Потоковый модуль использует потоки, многопроцессорный модуль использует процессы. Разница в том, что потоки выполняются в одном и том же пространстве памяти, а у процессов отдельная память. Это немного затрудняет совместное использование объектов процессами с многопроцессорной обработкой. В этом случае обычно выполняется сериализация объектов. Но потоки используют одну память, поэтому нужно быть осторожным, иначе два потока будут записывать данные в одну и ту же память одновременно. Именно для этого и существует глобальная блокировка интерпретатора.
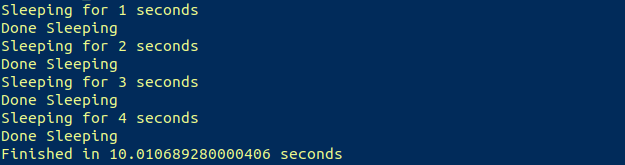
Если бы мы запустили на Python скрипт, выполняющий простую задачу — спать (ну очень времязатратную!), он выглядел бы так:
import time
start = time.perf_counter()
def please_sleep(n):
print("Sleeping for {} seconds".format(n))
time.sleep(n)
print("Done Sleeping")
for i in range(1,5):
please_sleep(i)
finish = time.perf_counter()
print("Finished in {} seconds".format(finish-start))Получаем результат, который и ожидали:
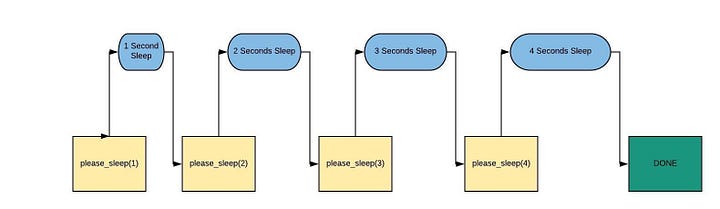
Рабочий процесс этого скрипта будет выглядеть примерно так:
Начнём с потокового модуля
Потоковый модуль
Рабочий процесс потоковой обработки можно представить в таком виде:
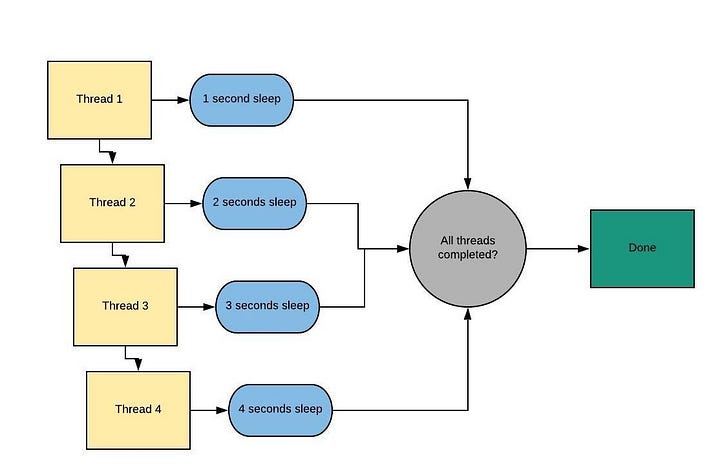
Сначала нужно импортировать потоковый модуль (это очевидно!).
Чтобы воспроизвести приведённый выше скрипт, используя потоки, потребуется создать несколько потоков. Это можно сделать многократным выполнением простого метода Thread (поток). Вот синтаксис этого метода:
thread1 = threading.Thread(target = method_name, args = [list of arguments])
После создания потоков нужно запустить их с помощью метода start:
thread1.start()
Давайте сначала возьмём простой пример, создав всего 2 потока, а затем попробуем повторить приведённый выше скрипт:
import time
import threading
start = time.perf_counter()
def please_sleep(n):
print("Sleeping for {} seconds".format(n))
time.sleep(n)
print("Done Sleeping")
t1 = threading.Thread(target = please_sleep, args = [1])
t2 = threading.Thread(target = please_sleep, args = [2])
t1.start()
t2.start()
finish = time.perf_counter()
print("Finished in {} seconds".format(finish-start))
Согласно рабочему процессу, этот фрагмент кода должен выполняться в течение примерно двух секунд. Теперь посмотрим, что он выведет на экран:

Результат не соответствует нашим ожиданиям. Такое поведение вызвано тем, что после запуска обоих потоков, в то время как потоки спали, наш скрипт работал в многопоточном режиме и продолжил выполнение с остальной частью скрипта. Это тут же привело к подсчёту времени до завершения.
Чтобы этого не допустить, надо задействовать метод join. При вызове метода join вызывающий поток (в нашем случае основной поток) блокируется до тех пор, пока не завершится объект потока (метод please_sleep), на котором он был вызван. Аналогично можно вызвать его в метод start:
thread1.join()
Повторим основной скрипт, используя всё то, что мы сейчас делали:
import time
import threading
start = time.perf_counter()
def please_sleep(n):
print("Sleeping for {} seconds".format(n))
time.sleep(n)
print("Done Sleeping for {} seconds".format(n))
threads = []
for i in range(1,5):
t = threading.Thread(target = please_sleep, args = [i])
t.start()
threads.append(t)
finish = time.perf_counter()
print("Finished in {} seconds".format(finish-start))Теперь выводится ожидаемый результат:
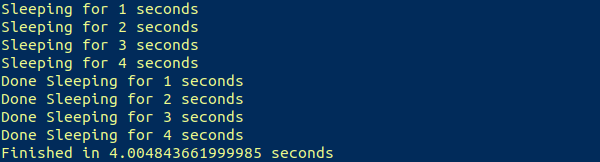
Примерно за четыре секунды успешно были выполнены четыре задачи, на которые первоначально уходило около десяти секунд.
Можно ли достигнуть тех же результатов с помощью модуля многопроцессорной обработки? Да, можно. Давайте в этом убедимся.
Модуль многопроцессорной обработки
Проиллюстрируем наши рассуждения примером с четырёхъядерным процессором. Вот рабочий процесс многопроцессорной обработки данных.
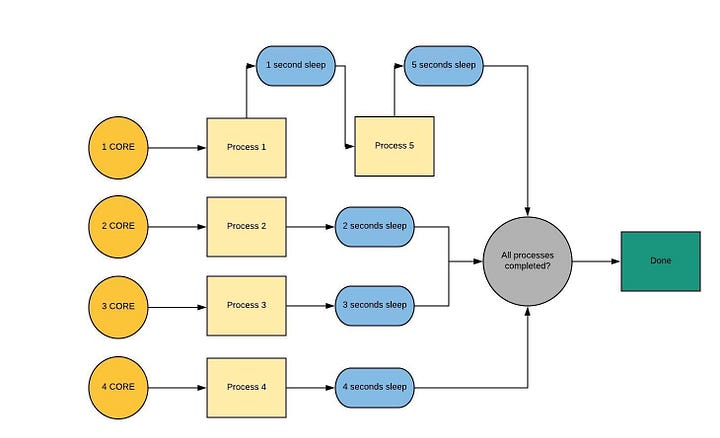
Процесс для запуска процесса ? происходит аналогично запуску потоков. Здесь мы первым делом импортируем многопроцессорный модуль, а затем вызываем метод Process, за которым следует метод start.
process1 = multiprocessing.Process(target = method_name, args = [list of arguments])
process1.start()
Потоки более легковесны и расходуют меньше вычислительных ресурсов по сравнению с процессами, а значит возникновение процессов происходит немного медленнее, чем порождение потоков. Вот пример:
import time
import multiprocessing
start = time.perf_counter()
def please_sleep(n):
print("Sleeping for {} seconds".format(n))
time.sleep(n)
print("Done Sleeping for {} seconds".format(n))
p1 = multiprocessing.Process(target = please_sleep, args = [1])
p2 = multiprocessing.Process(target = please_sleep, args = [2])
p1.start()
p2.start()
finish = time.perf_counter()
print("Finished in {} seconds".format(finish-start))Теперь вывод на экран показывает, что процессы были запущены после выполнения всего скрипта, подтверждая то, что было сказано ранее.

Метод join здесь тоже не даёт скрипту выполняться от момента вызова метода и до тех пор, пока процесс не будет завершен. Вызывается он так:
process1.join()
Давайте теперь создадим скрипт, который использует многопоточность для распараллеливания этого метода.
import time
import multiprocessing
start = time.perf_counter()
def please_sleep(n):
print("Sleeping for {} seconds".format(n))
time.sleep(n)
print("Done Sleeping for {} seconds".format(n))
processes = []
for i in range(1,6):
p = multiprocessing.Process(target = please_sleep, args = [i])
p.start()
processes.append(p)
for p in processes:
p.join()
finish = time.perf_counter()
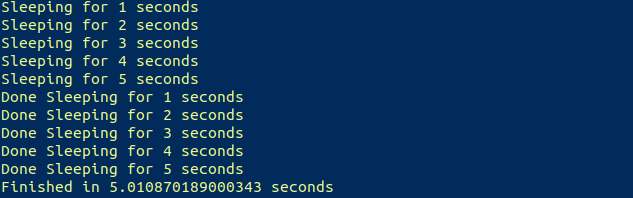
print("Finished in {} seconds".format(finish-start))Вывод теперь соответствует рабочему процессу:
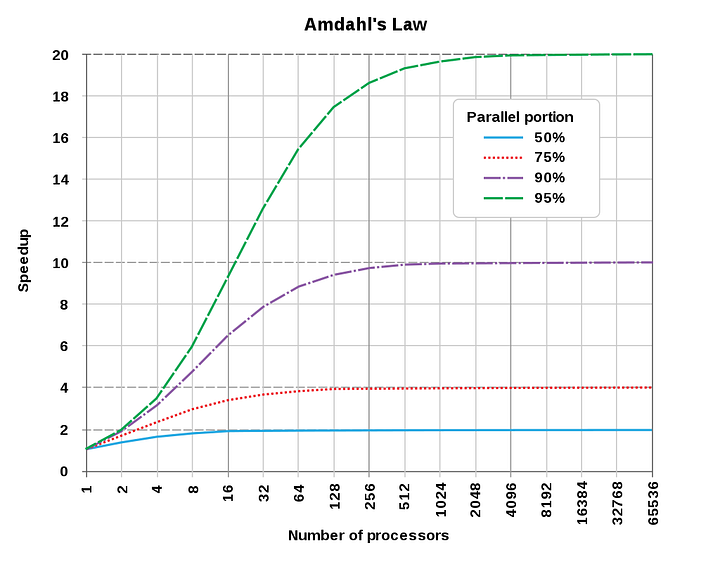
Использование параллелизма всегда приводит к потере эффективности, вынуждая расходовать больше ресурсов, поэтому общее время параллельных вычислений обычно оказывается больше, чем последовательных. Воспользовавшись законом Амдала, можно сказать, что параллельные вычисления с большим числом процессоров эффективны только для программ с высокой степенью распараллеливания.
Ценю ваше терпение и благодарю за то, что дочитали до конца.?
Читайте также:
- Вы умеете говорить на Python?
- Расширение Python с помощью C
- Анализ аудиоданных с помощью глубокого обучения и Python (часть 1)
Перевод статьи Hardik Ojha: Threading and Multiprocessing Modules in Python





