
Часть 1, Часть 2
Напомним, что в части 1 мы дали немного вводной информации о языке запросов GraphQL, о преимуществах GraphQL API в сравнении с REST API, а также создали корпус схем GraphQL.
Вопрос 1: Как выглядит типичная схема GraphQL?
Размеры типичной схемы
На диаграмме типа «ящик с усами» показаны размеры коммерческих и общедоступных схем (цифрами указано количество отдельных типов, которое схемы определяют).
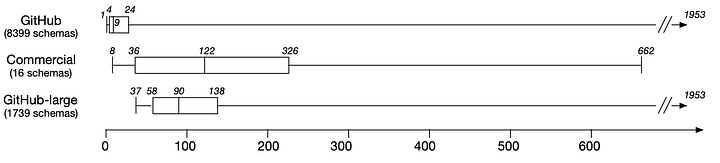
Мы заметили, что коммерческие схемы определяют гораздо больше типов, чем общедоступные (по средним значениям 122 против 9). Это натолкнуло на мысль, что некоторые схемы из GitHub-проектов могут быть пустышками. Для проведения сравнений между коммерческими и GitHub-схемами мы выделили внутри корпуса GitHub крупные GitHub схемы, схожие с коммерческими по количеству определений, и получили три подкорпуса схем:
- Коммерческие схемы: 16 схем получены от поставщиков GraphQL API.
- Всего GitHub-схем: 8,399 схем из GitHub-проектов.
- Крупные GitHub схемы: насчитывают 1,739 схем с не меньшим количеством отдельных типов, чем в первом квартиле коммерческого корпуса.
Сводная статистика по этим корпусам
В таблице обобщены данные по размеру схем и функционалу GraphQL, который они задействуют:
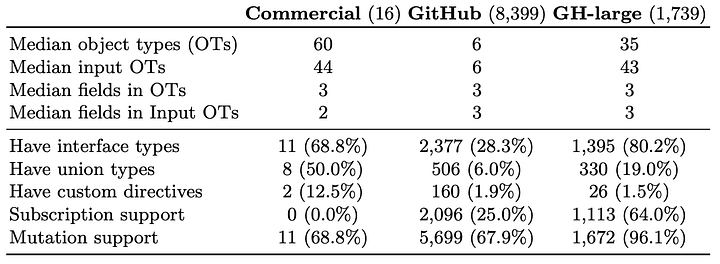
Здесь можно отметить чёткое разграничение между всеми тремя корпусами.
- Неудивительно, что коммерческие и крупные GitHub-схемы больше: они содержат больше типов объектов, доступных для запросов (первая строчка), и больше типов входных объектов с пользовательскими аргументами (вторая строчка).
- Если говорить о средних показателях (средняя по трём полям), во всех трёх корпусах объекты примерно одного размера (третья и четвёртая строчки).
- Что касается использования функционала, коммерческие схемы на первом месте по применению типов интерфейсов (5-я строчка), объединённых типов (6-я строчка) и настраиваемых указателей (7-я строчка), на втором — крупные GitHub-схемы, дальше идут схемы GitHub. В обратном порядке эти схемы расположились по мутациям (последняя строчка) и подпискам (предпоследняя строчка).
Соглашения об именовании
Соглашения об именовании или правила именования помогают разработчикам быстро понимать новые интерфейсы и самим создавать свои собственные — такие же чёткие и понятные. Если сообщество следует соглашениям, от этого все только выигрывают. Посмотрим, какие существуют правила именования GraphQL-схем:
«Официальные» рекомендации
Рекомендованные экспертами GraphQL правила именования изложены в письменных руководствах, а на практике воплощены в схемах-образцах в документации по GraphQL:
- Поля именуются в
camelCase. - Типы и перечисления именуются в стиле
Pascal. - Значения перечислимого типа пишутся полностью большими буквами.
Мы проверили эти соглашения в нашем корпусе схемы. В итоге выяснилось, что следуют им далеко не все.
А что на практике?
В следующей таблице показано, как схемы в нашем корпусе соблюдают соглашения об именовании. Кроме рекомендованных правил (верхняя часть таблицы), мы нашли несколько органичных правил именования, по которым сообщество разработчиков открытого ПО, похоже, пришло к единому мнению (нижняя часть). Например:
- Рекомендованные правила #1: лишь в 8,2% крупных GH-схем в названиях всех полей был использован верблюжийРегистр.
- Органичные правила #1: в 68,2% крупных GH-схем к названиям всех входных объектов прибавлялся постфикс
Input.
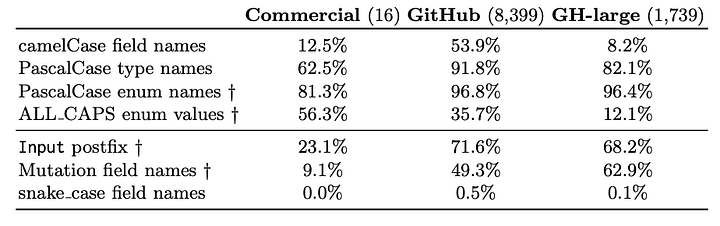
Многие схемы проявляют непоследовательность в соблюдении этих правил. К примеру, соглашения об именовании полей snake_case последовательно придерживаются менее 1% схем (здесь, очевидно, предпочтение отдаётся рекомендованному правилу верблюжьегоРегистра). Однако snake_case используют 30% всех имён полей в схемах полного корпуса и около 37% схем в некоммерческом корпусе GitHub не менее чем для одного поля.
В целом в таблице наблюдается чёткое разграничение между коммерческими и общедоступными GitHub-схемами. Похоже, что сообщество разработчиков открытого ПО движется в сторону выработки общего мнения по этим правилам, в то время как авторы коммерческих схем вряд ли будут им следовать.
Вопрос 2: типичное поведение в наихудшем случае GraphQL
Теория
Объём возвращаемых данных GraphQL может выражаться в количестве объектов, пришедших в ответ на запрос.
В первой части уже упоминалось, что в ответ на запрос GraphQL могут прийти данные экспоненциально большего объёма, чем сам запрос. Давайте разобьём схемы на три категории по объёму сложности ответа в наихудшем случае, исходя из размера потенциального запроса: линейные, полиномиальные и экспоненциальные. Так нам будет легче понять использование примеров по схеме, приведённой ниже.
- В этой схеме можно выполнить запрос на компанию с помощью её ID.
- У каждой компании есть адрес и список штатных сотрудников.
- У каждого штатного сотрудника есть имя и список закреплённых за ним стажёров, а также список коллег.
- У каждого стажёра есть имя.
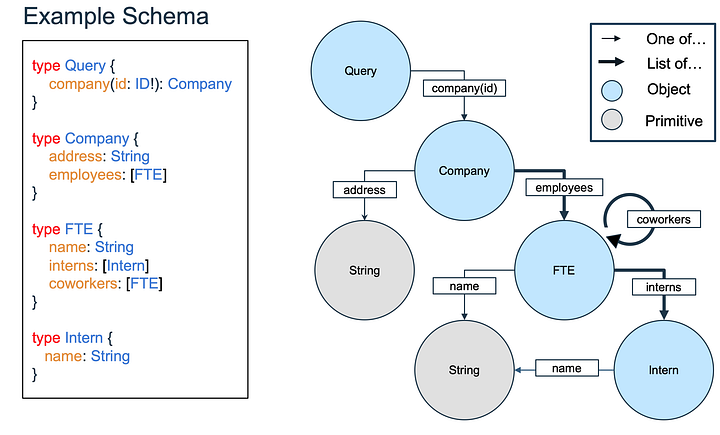
Теперь подумаем об объёме данных, возвращаемых в ответ на запрос адреса компании IBM. На следующем рисунке мы видим, что запрашивается примитивное значение от одной компании, поэтому в ответе объектов будет не больше, чем в запросе.
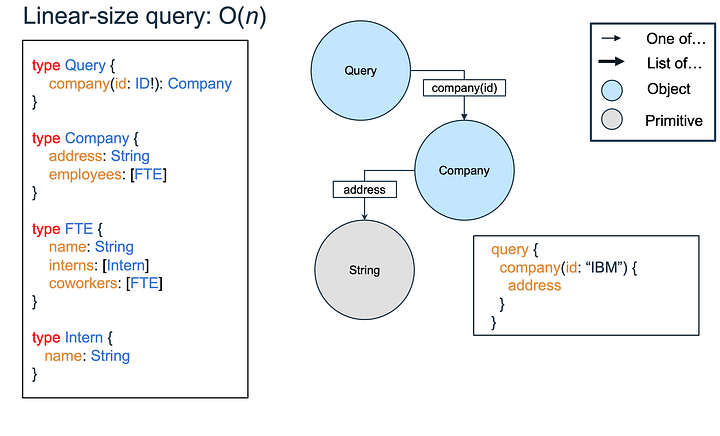
Теперь попробуем выполнить запрос на адрес компании IBM и список её сотрудников вместе со стажёрами (см. следующий рисунок). Предположим, что у каждого из D сотрудников есть D стажёров. В таком случае в ответе будет получено O(D^2) объектов. Запросив списки с вложенными списками, мы получили полиномиальное число объектов.
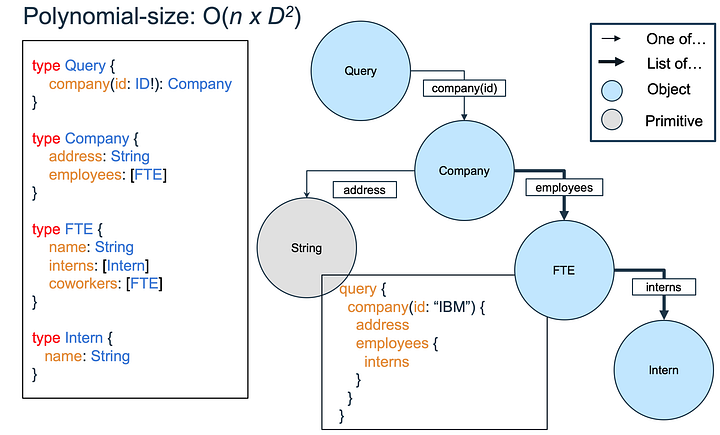
Теперь обратимся к экспоненциальному поведению. Так как все D сотрудники работают в IBM, они друг другу коллеги. В следующем запросе на список сотрудников мы получаем D объектов. Затем мы запрашиваем всех их коллег и получаем D^2 объектов. Когда мы запрашиваем уже коллег этих коллег, то получаем D^3 объектов. Таким образом, на наш запрос на n уровней коллег будет приходить ответ с D^n объектами, то есть экспоненциальное число относительно объёма запроса.
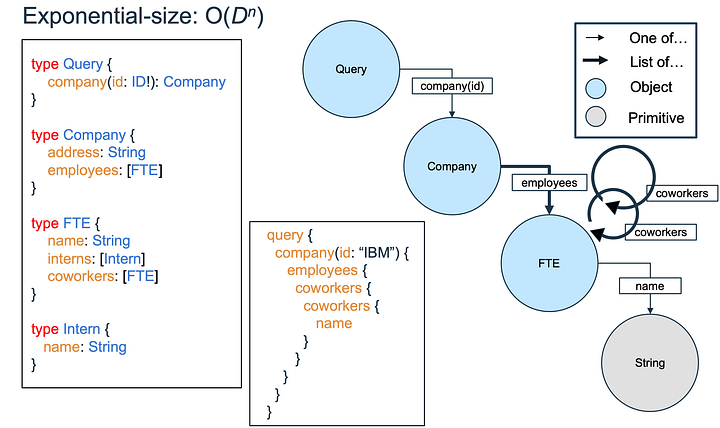
Будут ли получаемые в ответ на запрос данные полиномиально или экспоненциально большего объёма, чем сам запрос, зависит от того, есть ли в схеме вложенные списки или нет. Разница между полиномиальным и экспоненциальным поведением определяется наличием цикла в графе схемы.
- Полиномиальные: вложенные запросы для разных списков.
- Экспоненциальные: вложенные запросы для одних и тех же списков.
Основываясь на таких представлениях, мы пришли к более формализованному анализу. Наш анализ зависит от структуры схемы:
- Можно ли выполнять запросы с вложенными списками? (Полиномиальные, степень зависит от уровня вложенности).
- Есть ли среди вложенных списков такой цикл типа, который можно вложить в запрос на список того же типа? (Экспоненциальные).
Наш анализ даёт верхнюю границу объёма возвращаемых данных в наихудшем случае, при этом объём этих данных может быть переоценён из-за двух факторов:
- Сервер GraphQL может ограничивать объём возвращаемых данных.
- Данные, содержащиеся в графах GraphQL, могут оказаться скудными, так что и объём возвращаемых данных будет невелик. Так, в предыдущем примере, если бы у каждого из
Dсотрудников IBM был только один коллега, объём возвращаемых данных был быO(D), а не пугающийO(D^n)(как предполагает здесь структура схемы).
Результаты
Какие объёмы возвращаемых данных в наихудшем случае мы получаем
В следующей таблице показано, что в наихудшем случае экспоненциальный объём возвращаемых данных характерен для схем большого размера (более 80% коммерческих и крупных GitHub-схем).
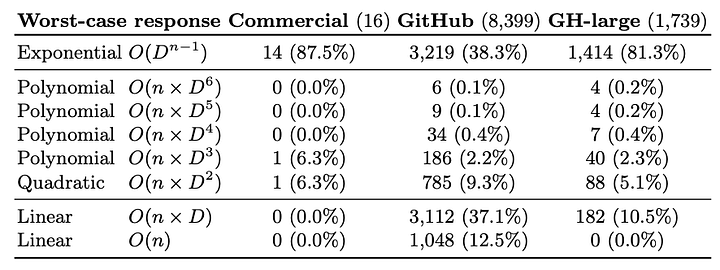
Такой результат не вызывает удивления: GraphQL описывает отношения между типами, и наличие в схеме таких отношений, ведущих к сверхлинейному поведению, кажется естественным. Однако этот результат предполагает, что поставщики GraphQL и сервисов ПО промежуточного слоя должны планировать обработку сверхлинейных запросов.
Как защититься
Документация GraphQL рекомендует разбивку на страницы как защиту от чрезмерно больших объёмов возвращаемых данных: с использованием среза или схемы соединения.
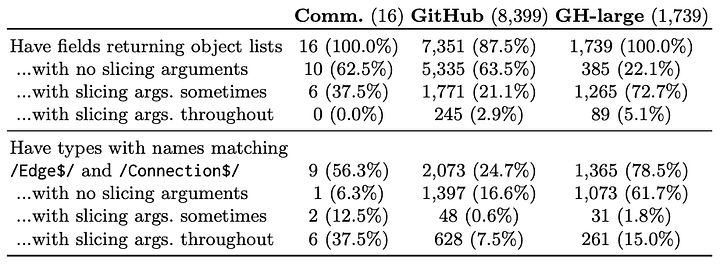
Мы проверили наши схемы на разбивку на страницы:
- Использование срезов легко увидеть, поскольку они встроены в схему.
- Для идентификации схем соединения мы использовали в названии полей эвристические алгоритмы.
Следующая таблица показывает, что мы получили:
- Ни один корпус не использует последовательно разбивку на страницы (шаблоны пагинации), поэтому угроза чрезмерного объёма возвращаемых данных в наихудшем случае возрастает.
- При использовании шаблонов пагинации коммерческие и крупные GitHub-схемы задействуют, как правило, схемы соединения, в то время как срезы не используются регулярно.
Мы призываем активнее применять пагинацию.
Выводы
GraphQL — это технология, важность которой постоянно растёт. Мы дали практическую оценку текущего состояния GraphQL, использовав корпусы с широким функционалом, новую методологию построения схем и новый анализ. Какие главные ответы мы получили на вопросы нашего исследования:
- Вопрос 1: Мы надеемся, что описанная нами ситуация с соблюдением правил именования может помочь разработчикам понять и принять стандарты сообщества для создания более чётких и понятных API.
- Вопрос 2: Мы убедились в обоснованности опасений и предостережений специалистов в отношении риска отказа в обслуживании GraphQL API. Большинство коммерческих и крупных общедоступных GraphQL API в качестве ответов на запросы могут получать данные экспоненциально большего объёма, чем сами запросы. Приходится констатировать, что во многих схемах не используются лучшие практики, поэтому большинство схем совершенно не защищены от таких запросов.
Наша работа открывает дорогу будущим исследованиям в изучении таких тем, как инструменты рефакторинга для поддержки правил именования, сдвоенный анализ схем и запросов для оценки объёма возвращаемых данных в ПО промежуточного уровня (например, ограничение скорости передачи данных), а также управляемое данными проектирование.
Дополнительная информация
- Полный текст работы здесь.
- Слайды можно найти здесь.
- Также файлы, связанные с этим проектом, опубликованы на Zenodo. Мы выложили там корпус схем с либеральными лицензиями, а также инструменты, использованные при построении нашего корпуса.
Читайте также:
- Как настроить мощный API на Nodejs, GraphQL, MongoDB, Hapi, и Swagger. Часть 1
- Пишем кастомные React-хуки для GraphQL
- Введение в GraphQL: основные принципы использования
Перевод статьи James Davis: An Empirical Study of GraphQL Schemas





