
Сегодня мы обсуждаем структурированную конкурентность в Java, нативное решение, представленное в качестве предварительной функции в JDK 21. Мы рассмотрим, как оно поможет в структурировании и управлении сложностью конкурентной работы, а также как оно может ускорить процесс разработки и повысить надежность, сопровождаемость, тестируемость и наблюдаемость приложений.
В этой статье приведен пример кода для реальной задачи, решенной с использованием структурированной конкурентности. Исходный код доступен в репозитории Git.
Практический подход
Научимся решать реальную проблему с использованием структурированной конкурентности. Сначала сформулируем задачу, а в следующих разделах рассмотрим новые возможности Java и способы их применения для решения нашей задачи.
Представьте, что у нас есть приложение BFF (Back-end для Front-end). Это приложение взаимодействует с различными поставщиками данных, имеющими информацию о странице, агрегирует эти данные и возвращает их клиенту (приложение FE).
В реальном случае это приложение будет иметь дополнительные обязанности, такие как применение алгоритмов для изменения/нормализации данных, регистрация информации отслеживания и многое другое. Однако они не в фокусе данной статьи. Для простоты мы сосредоточимся только на возврате агрегированных данных.
Приложение FE представляет собой страницу электронной коммерции, состоящую из следующих компонентов: Hero, Product Details, Recommendations и Reviews.
Прототип этой страницы выглядит так:

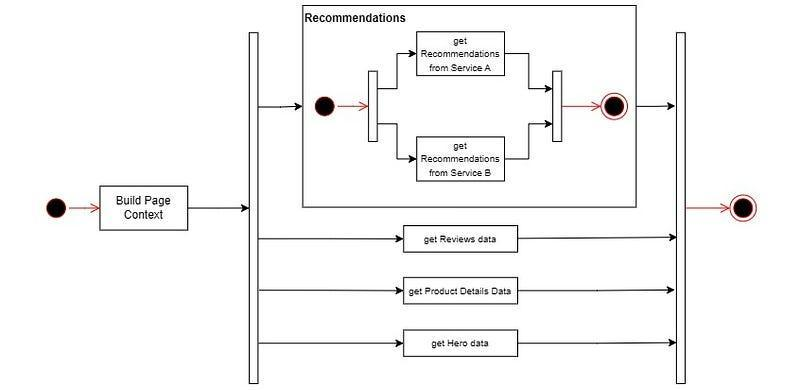
К концу этой статьи мы создадим это приложение, используя новую функциональность, представленную в JDK 21.
Виртуальные потоки
Как вы, возможно, знаете, в Java для запуска потоков выполнения кода используются другие потоки — Thread. Когда нужно выполнять асинхронные задачи, требуются дополнительные потоки. Вместо управления потоками напрямую следует использовать Executor или ExecutorService из пакета java.util.concurrent. Возможно, вы помните класс ThreadPoolTaskExecutor из Spring Framework; этот класс является примером класса Executor.
Обычно Executor создается во время запуска приложения, и он остается активным, пока система выполняется. Executor поддерживает пул потоков, который могут все задачи могут поделить между собой. Когда создается традиционный экземпляр потока, поток выделяется на уровне операционной системы, поэтому этот тип потока называется «платформенным потоком». Потоки платформы ресурсоемки, поэтому рекомендуется использовать их общий пул.
В JDK 21 представлены виртуальные потоки. По сути, это «облегченные потоки», поскольку они не распределяются на уровне операционной системы. Oracle дает простое определение виртуальных потоков:
«Подобно платформенному потоку, виртуальный поток также является экземпляром java.lang.Thread. Однако виртуальный поток не привязан к конкретному потоку ОС. Виртуальный поток по-прежнему выполняет код в платформенном потоке, однако, когда код, выполняющийся в виртуальном потоке, вызывает блокирующую операцию ввода-вывода, среда выполнения Java приостанавливает этот виртуальный поток до тех пор, пока он не будет возобновлен. Поток ОС, связанный с приостановленным виртуальным потоком, теперь может свободно выполнять операции для других виртуальные потоки».
Как и в случае с латформенными потоками, не следует взаимодействовать с виртуальными потоками напрямую. Вместо этого нужно использовать Executor. Вызвав метод Executors#newVirtualThreadPerTaskExecutor, мы получаем Executor, который для каждой переданной ему задачи создает новый виртуальный поток.
Структурированная конкурентность
Мы обсудили потоки и исполнители, полезные для одновременного выполнения задач. Однако когда мы начинаем создавать более сложные рабочие процессы — даже из самых простых — мы также начинаем видеть разрыв между нашими намерениями как разработчиков и тем, что предоставляют эти инструменты.
Представим, что у нас есть метод, который для построения объекта выполняет две асинхронные задачи:
public MyRecord getRecord(String id) throws ExecutionException, InterruptedException {
var recordMetaFuture = executorService.submit(() -> getRecordMetadata(id));
var recordHistoryFuture = executorService.submit(() -> getRecordHistory(id));
return new MyRecord(recordMetaFuture.get(), recordHistoryFuture.get());
}Этот код довольно распространен, и многие разработчики сталкивались с подобными ситуациями в своей карьере. Разберем некоторые проблемы этой реализации:
- Если метод RecordMetaFuture.get() завершится неудачно и бросит исключение, выполнение RecordHistoryFuture не остановится. Задача будет продолжать выполняться в собственном потоке, что приведет к потенциальной утечке потока, которая, в свою очередь, приведет к нерациональному использованию ресурсов и может вызвать в приложении побочные эффекты.
- Если RecordHistoryFuture завершается с ошибкой, но RecordMetaFuture все еще работает, исключение из RecordHistoryFuture будет видно только после завершения RecordMetaFuture и вызова RecordHistoryFuture.get(). Это может привести к напрасной трате времени и ресурсов.
- Если поток, вызвавший метод getRecord, прерывается, прерывание не будет передано на RecordMetaFuture и RecordHistoryFuture. Эти потоки будут продолжать выполнять свои задачи, пока они не завершатся или не упадут.
Разработчики управляют сложностью, разбивая задачи на несколько подзадач и создавая связь между задачами и подзадачами. Эти отношения естественным образом обрабатываются в однопоточной среде, но в многопоточных реализациях они держатся только в уме разработчика.
Структурированная конкурентность введена, чтобы устранить этот пробел. Ее цель — упростить модель конкурентного программирования установлением связей между задачами и подзадачами, выполняемыми в разных потоках, что позволяет нам рассматривать их как единую единицу работы.
StructuredTaskScope
В JDK 21 представлен класс StructuredTaskScope — фундаментальный строительный блок структурированной конкурентности. Этот класс представляет выполняемую задачу и позволяет нам разветвлять ее на подзадачи. Эти подзадачи выполняются в виртуальных потоках.
Для каждой подзадачи мы получаем экземпляр Subtask, который позволяет проверять состояние отдельной подзадачи, получать ее результат или — в случае возникновения исключения — Throwable. Следующий фрагмент кода демонстрирует простую область действия (scope), где задачи возвращают целые числа. Обратите внимание, что subtask2 включает вызов Thread.sleep, чтобы имитировать дорогостяющую задачу:
public static void main(String[] args) {
// создание области действия
try (var scope = new StructuredTaskScope<Integer>()) {
// разветвление на подзадачи
StructuredTaskScope.Subtask<Integer> subtask1 = scope.fork(() -> 1);
StructuredTaskScope.Subtask<Integer> subtask2 = scope.fork(() -> {
Thread.sleep(1_000);
return 2;
});
StructuredTaskScope.Subtask<Integer> subtask3 = scope.fork(() -> 3);
// объединение подзадач, ожидание завершения или неудачи
scope.join();
// печать результатов
System.out.println(printSubTask("subtask1", subtask1));
System.out.println(printSubTask("subtask2", subtask2));
System.out.println(printSubTask("subtask3", subtask3));
} catch (Exception exception) {
exception.printStackTrace();
}
}
// вывод в консоли:
// subtask1 state: SUCCESS value: 1
// subtask2 state: SUCCESS value: 2
// subtask3 state: SUCCESS value: 3Теперь посмотрим на взаимосвязь задача-подзадача на практике. Предположим, что по истечении 500 мс мы больше не заинтересованы продолжать задачу. Можно вызвать StructuredTaskScope#shutdown, который предотвращает запуск новых потоков и прерывает все незавершенные потоки.
public static void main(String[] args) {
// создание области действия
try (var scope = new StructuredTaskScope<Integer>()) {
// разветвление на подзадачи
StructuredTaskScope.Subtask<Integer> subtask1 = scope.fork(() -> 1);
StructuredTaskScope.Subtask<Integer> subtask2 = scope.fork(() -> {
System.out.println("starting subtask2");
Thread.sleep(1_000);
System.out.println("subtask2 completed");
return 2;
});
StructuredTaskScope.Subtask<Integer> subtask3 = scope.fork(() -> 3);
// ожидание 500ms
Thread.sleep(500);
// отключение области действия
scope.shutdown();
scope.join();
// печать результатов
System.out.println(printSubTask("subtask1", subtask1));
System.out.println(printSubTask("subtask2", subtask2));
System.out.println(printSubTask("subtask3", subtask3));
} catch (Exception exception) {
exception.printStackTrace();
}
}
// вывод в консоли:
// starting subtask2
// subtask1 state: SUCCESS value: 1
// subtask2 state: UNAVAILABLE value: null
// subtask3 state: SUCCESS value: 3Видно, что более медленная подзадача 2 была отменена. Состояние UNAVAILABLE указывает на то, что подзадача была разветвлена, но не завершена. Это состояние также может возникнуть, если задача завершена после закрытия области действия или если она была разветвлена после закрытия области действия задачи.
StructuredTaskScope имеет полезную специализацию под названием ShutdownOnFailure. Она упрощает обработку ошибок в конкурентном коде. В этой области действия, если задача завершается сбоем и бросает исключение, область действия закрывается, прерывая любые другие подзадачи. В следующем примере исключение выбрасывается из третьей подзадачи, что приводит к отмене других подзадач:
public static void main(String[] args) {
// создание области действия
try (var scope = new StructuredTaskScope.ShutdownOnFailure()) {
// разветвление на подзадачи
StructuredTaskScope.Subtask<Integer> subtask1 = scope.fork(() -> {
System.out.println("starting subtask1");
Thread.sleep(500);
System.out.println("subtask1 completed");
return 2;
});
StructuredTaskScope.Subtask<Integer> subtask2 = scope.fork(() -> {
System.out.println("starting subtask2");
Thread.sleep(1_000);
System.out.println("subtask2 completed");
return 2;
});
StructuredTaskScope.Subtask<Integer> subtask3 = scope.fork(() -> {
System.out.println("starting subtask3");
System.out.println("throwing exception from subtask3");
throw new RuntimeException("Runtime error in subtask3");
});
// объединение подзадач, ожидание завершения самой быстрой
scope.join();
// печать результатов
System.out.println(printSubTask("subtask1", subtask1));
System.out.println(printSubTask("subtask2", subtask2));
System.out.println(printSubTask("subtask3", subtask3));
} catch (Exception exception) {
exception.printStackTrace();
}
}
// вывод в консоли:
// starting subtask1
// starting subtask2
// starting subtask3
// throwing exception from subtask3
// subtask1 state: UNAVAILABLE value: null
// subtask2 state: UNAVAILABLE value: null
// subtask3 state: FAILED Exception: Runtime error in subtask3В следующих разделах мы рассмотрим еще одну специализацию StructuredTaskScope и обсудим, как создать нашу реализацию для обработки конкретных сценариев.
Рекомендации — выигрывает первый ответивший
Мы заявили, что компонент Recommendations поддерживается двумя разными сервисами и что мы будем отображать данные от самого быстрого из них. Этого можно легко добиться, применив другую специализацию StructuredTaskScope — класс ShutdownOnSuccess.
В коде ниже показано, как с помощью класса ShutdownOnSuccess реализовать решение для компонента Recommendations. Мы отделили две подзадачи, вызывающие разных поставщиков данных. Как только мы объединим их, данные самого быстрого клиента станут доступны через метод StructuredTaskScope#result.
@RequiredArgsConstructor
public class RecommendationsService {
private final RecommendationsClientA recommendationsClientA;
private final RecommendationsClientB recommendationsClientB;
public Recommendations getRecommendations(String productId) {
try (var scope = new StructuredTaskScope.ShutdownOnSuccess<Recommendations>()) {
System.out.println("Recommendations SCOPE started...");
scope.fork(() -> recommendationsClientA.getRecommendations(productId));
scope.fork(() -> recommendationsClientB.getRecommendations(productId));
scope.join();
return scope.result();
} catch (PageContextException | InterruptedException | ExecutionException ex) {
System.out.println("Failed to get recommendations");
ex.printStackTrace();
return null;
}
}
}В этой области действия, как только подзадача завершается, завершается и область действия, а все ожидающие подзадачи прерываются. Для случая Recommendations это подходит идеально.
Построение нашей области действия
Чтобы решить задачу, обозначенную в начале статьи, необходимо агрегировать данные со всех компонентов и передать их в приложение FE. Создадим для этой цели класс-обертку — PageContext.
public record PageContext(ReviewsData reviewsData, ProductDetails productDetails,
HeroData heroData, Recommendations recommendations) {
}Идея в том, чтобы создать пользовательскую область действия, где каждая ответвленная подзадача предоставляет часть данных, необходимых для контекста. Начнем с создания интерфейса-маркера под названием PageContextComponent** ** и реализуем его всеми объектами, составляющими PageContext. Этот подход позволит разветвлять подзадачи, не беспокоясь о типе текста.
Начинаем. Первый шаг — создать класса PageContextScope и расширить им StructuredTaskScope<PageContextComponent>. В качестве атрибутов класса включим все данные, необходимые для построения PageContext, и добавим список, чтобы отслеживать исключения, которые могут быть вызваны разветвленными подзадачами. Это поможет устранить неполадки в приложения.
public class PageContextScope extends StructuredTaskScope<PageContextComponent> {
private volatile HeroData heroData;
private volatile ReviewsData reviewsData;
private volatile ProductDetails productDetails;
private volatile Recommendations recommendations;
private final List<Throwable> exceptions = new CopyOnWriteArrayList<>();
}Далее нам нужно переопределить метод handleComplete. Он вызывается каждый раз, когда подзадача завершается успешно или со сбоем. В зависимости от состояния подзадачи мы решаем, как обрабатывать успехи и неудачи. В нашем случае, когда подзадача завершается сбоем, мы фиксируем причину, но также можем закрыть область действия и создать исключение.
public class PageContextScope extends StructuredTaskScope<PageContextComponent> {
// атрибуты класса...
@Override
protected void handleComplete(Subtask<? extends PageContextComponent> subtask) {
switch (subtask.state()) {
case Subtask.State.SUCCESS -> onSuccess(subtask);
case Subtask.State.FAILED -> exceptions.add(subtask.exception());
}
super.handleComplete(subtask);
}
}Сопоставление шаблонов для выражений switch полезно при обработке успешно завершенных подзадач. По сути, мы извлекаем результат задачи, приводим его к правильному типу и сохраняем в области действия.
public class PageContextScope extends StructuredTaskScope<PageContextComponent> {
// атрибуты класса...
private void onSuccess(Subtask<? extends PageContextComponent> subtask) {
switch (subtask.get()) {
case ProductDetails productDetailsFromSubtask -> this.productDetails = productDetailsFromSubtask;
case HeroData heroDataFromSubTask -> this.heroData = heroDataFromSubTask;
case ReviewsData reviewsDataFromSubTask -> this.reviewsData = reviewsDataFromSubTask;
case Recommendations recommendationsFromTask -> this.recommendations = recommendationsFromTask;
default -> throw new IllegalStateException(STR."Invalid output for subtask {subtask}");
}
}
}Наконец, реализуем метод получения результата области действия, который я назову getContext. Перед попыткой получить результат вызывающая сторона должна присоединиться к области, поэтому мы проверяем это, вызовом super.ensureOwnerAndJoined().
Еще одна хорошая практика — проверять область действия перед возвратом результирующего значения. В нашем случае мы создаем экземпляр PageContextException для объявления любых отсутствующих компонентов и исключений, создаваемых подзадачами.
Если все в порядке, мы должны создать и вернуть экземпляр PageContext.
public class PageContextScope extends StructuredTaskScope<PageContextComponent> {
// атрибуты класса...
public PageContext getContext() {
super.ensureOwnerAndJoined();
validateScope();
return new PageContext(reviewsData, productDetails, heroData, recommendations);
}
private void validateScope() {
List<String> missingComponents = new ArrayList<>();
Objects.requireNonNullElseGet(heroData, () -> missingComponents.add("heroData"));
Objects.requireNonNullElseGet(reviewsData, () -> missingComponents.add("reviewsData"));
Objects.requireNonNullElseGet(productDetails, () -> missingComponents.add("productDetails"));
Objects.requireNonNullElseGet(recommendations, () -> missingComponents.add("recommendations"));
if (!missingComponents.isEmpty()) {
PageContextException pageContextException = new PageContextException(STR."""
Failed to build ProductDetailsContextScope, missing components: {missingComponents}
""");
exceptions.forEach(pageContextException::addSuppressed);
throw pageContextException;
}
}
}Использовать новую область действия довольно просто. Нам просто нужно создать ее экземпляр и разветвить подзадачи.
public class PageContextService {
private final HeroClient heroClient;
private final ProductDetailsClient productDetailsClient;
private final ReviewsClient reviewsClient;
private final RecommendationsService recommendationsService;
public PageContext getPageContext(String productId) {
try (var scope = new PageContextScope()) {
System.out.println("PageContext SCOPE started...");
scope.fork(() -> heroClient.getHeroData(productId));
scope.fork(() -> productDetailsClient.getDetails(productId));
scope.fork(() -> reviewsClient.getReviews(productId));
scope.fork(() -> recommendationsService.getRecommendations(productId));
scope.join();
return scope.getContext();
} catch (PageContextException | InterruptedException ex) {
System.out.println("Failed to build context ");
ex.printStackTrace();
return null;
}
}
}Если мы вызовем PageContextService.getPageContext("1"), у нас будет контекст со следующим содержимым:
{
"reviewsData": {
"averageReviews": 5.0,
"reviews": [
{
"value": 5.0,
"comment": "Nice",
"date": "2024-08-03T23:22:29.3327393",
"authorName": "Victor"
},
{
"value": 5.0,
"comment": "Cool",
"date": "2024-08-03T23:22:29.3327393",
"authorName": "Anna"
}
]
},
"productDetails": {
"characteristics": {
"Storage": "500GB"
}
},
"heroData": {
"title": "Playstation 5",
"image": "https://www.my-image-host/1"
},
"recommendations": {
"recommendations": [
{
"title": "Playstation 5 refurbished",
"image": "https://www.my-image-host/recommendation/1",
"price": "$1.00"
}
]
}
}Заключение
На этом наша статья завершается. Мы обсудили потоки и виртуальные потоки, изучили предварительные функции JDK 21 для структурированной конкурентности и продемонстрировали их практическое применение, решив реальную задачу. Если вам интересно узнать обо всем проекте и о том, как я написал для него модульные тесты, посмотрите его в репозитории Git.
Читайте также:
- Java Spring Boot против Golang
- Quarkus — горячий тренд Java-разработки
- Методы wait(), notify() и notifyAll() в Java
Читайте нас в Telegram, VK и Дзен
Перевод статьи Victor Hugo: [JAVA 21] Structured Concurrency: Powering Data Orchestration with Virtual Threads and Scopes





