
Расскажу, как выбрать между реляционными и нереляционными базами данных для программного решения, какая роль при этом отводится структурированным и неструктурированным данным, а также другим факторам. Это сложный выбор, ведь статья посвящена управлению ПО.
Помню слова преподавателя в университете: «Я здесь не для того, чтобы научить Вас быть инженером. Инженерия — это деньги!»
Вспоминая свою инженерную карьеру, я понимаю: он был прав. Выбор технологии определяется тем, хороша ли она для работы, и в неменьшей степени — затратами. Необходимо учитывать и то, и другое.
Это же относится и к выбору между реляционными и нереляционными базами данных, который обычно превращается в обсуждение технологии БД, применяемой для того или иного программного решения.
Начнем с того, хороша ли технология для работы, и обратимся к данным. Структурированные это данные или неструктурированные? Этот вопрос неизбежен.
Затем рассмотрим нетехнические аспекты выбора.
Структурированные или неструктурированные
Многие говорят, что их данные не структурированы. В отчетах утверждается: при управлении компаниями задействуется около 80 % неструктурированных данных.
Мало кто говорит о своих данных как структурированных. Вероятно, объясняется это тем, что на каком-то уровне все данные структурированы.
Структурированные данные отличают от неструктурированных по двум вопросам:
- Известна ли информация о данных — то есть метаданные — до написания кода?
- Меняется ли во время выполнения форма получаемых данных?
Ответ на оба этих вопроса: «И да, и нет».
Например, текст на странице обычно считают неструктурированным. И это странно, ведь он очень хорошо структурирован: написан на языке ограниченным набором символов и обычно по грамматическим правилам этого языка. А значит, у страницы неструктурированного текста имеются очень структурированные метаданные.
Смысл текста может быть любым, поэтому семантика не структурирована.
То есть на одном уровне данные структурированные, на другом — неструктурированные. Для большинства данных это обычное дело.
По-настоящему не структурированные данные случайны, к ним применимы правила относительно лишь наличия данных, их размера и возможности преобразования, например, шифрованием.
Для решения с более-менее обширной функциональностью в программном обеспечении используются структурированные данные или их метаданные. Когда понимаешь это, говорить о структурированности данных становятся неактуально: они и структурированные, и неструктурированные.
Текучесть данных
Поговорим тогда о текучести данных.
При соответствии правилам строгой типизации данные считают твердыми, как кирпичи. Структура таких данных задана и неизменна.
При несоответствии правилам типизации данные считают текучими, как вода. Структура таких данных не определена и фактически случайна.
Таким образом, по текучести данные ближе то к кирпичам, то к воде — в зависимости от решаемой задачи. Этим и определяется выбор соответствующей технологии.
Постоянно хранимые данные
Итак, выбор между нереляционными и реляционными базами данных — это фактически выбор технологии БД или слоя хранения и управления данными. Разберемся, что это значит.
Большинство описаний, выдаваемых в поисковике при вводе «структурированные против неструктурированных», сводятся к способу сохранения или постоянного хранения данных в БД. Подобными формулировками решения по хранению данных разделяются на реляционные БД для хранения структурированных данных — тех самых кирпичей — и нереляционные БД для хранения неструктурированных данных — воды.
Хотя имеются и другие варианты, ограничимся этими двумя.
Посмотрим, что из этого получится.
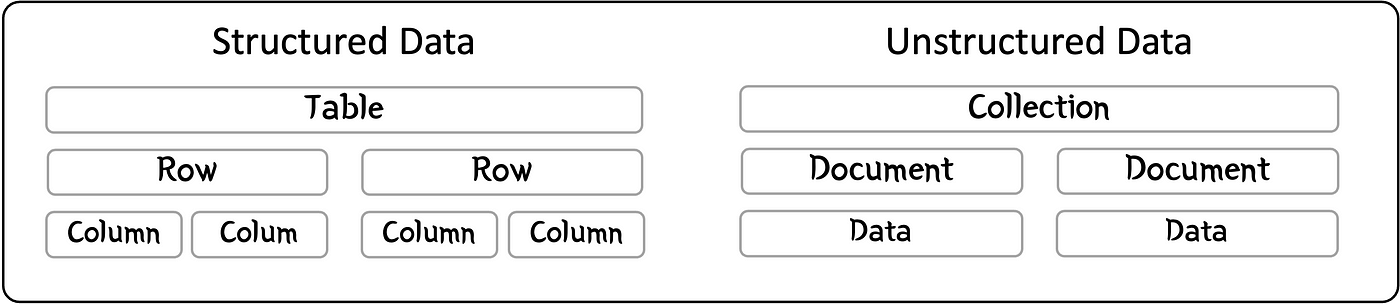
Структурированные данные в реляционных БД
У структурированных данных имеется фиксированное определение данных, или схема. Данные хранятся в таблицах БД, причем каждый новый фрагмент данных или запись сохраняется в виде строки. А каждое поле записи в строке сохраняется в виде столбца. Каждый столбец — это конкретный тип данных. Таким образом, все структурированные данные хранятся в фиксированной трехмерной сетке из таблиц, строк и столбцов.
Строгой структурой хранения объясняется то, что для создания, считывания, изменения и/или удаления данных используется язык структурированных запросов. Код теперь им обрабатывается с помощью данных и их структуры.
Реляционными БД поддерживаются и неструктурированные данные в виде большого двоичного объекта, строки или даже поля JSON. Подробнее об этом — позже.
Неструктурированные данные в нереляционных БД
У неструктурированных данных нет определенной схемы. В базе данных нет строгого определения содержания записи и ее внешнего вида. Она абсолютно независима: ей нет дела, что это за данные.
Но, если нет структуры, как получить доступ к данным? Ведь даже на неструктурированные данные нужно как-то ссылаться.
Таблицы и строки реляционной БД здесь, как правило, заменяются коллекциями и документами. Этому имеется объяснение.
В документе может быть что угодно, чем угодно могут быть и неструктурированные данные. Коллекция — это набор документов, объединенных общей темой, например коллекция документов о рыбах. В документах даже из одной коллекции содержатся данные любого типа.
Поэтому очень текучие данные намного больше соответствуют нереляционной БД.
Реляционные базы данных
Под реляционной БД подразумевается реляционная система управления базами данных — РСУБД.
Между структурированными данными имеются взаимосвязи. Возьмем две таблицы: с рыбой и аквариумами. Какая рыба в каком аквариуме, определяется взаимосвязью данных о рыбе и аквариумах.
В реляционной БД эти взаимосвязи представлены ссылками между записями данных.
Ввиду особой важности взаимосвязи управляются непосредственно в РСУБД, например, правилами ссылочной целостности, благодаря которым ссылки всегда остаются рабочими.
Именно этими взаимосвязями данные в БД управляются с помощью языка SQL, даже если находятся в разных таблицах, строках и столбцах.
Нереляционные базы данных
В по-настоящему не структурированном наборе данных определенной взаимосвязи между данными нет. Например, никак не связанные друг с другом книги в библиотеке — не что иное, как коллекция документов.
В отсутствие структуры для доступа к неструктурированным данным нужна альтернатива SQL. Хотя SQL хорошо стандартизирован, языки No-SQL-запросов больше зависят от базовой технологии хранения. Общее у них всех одно — No-SQL в названии.
No-SQL-запросы — это вроде поиска описания золотой рыбки в библиотеке.
Велик соблазн считать, что элементы данных — то есть документы — в нереляционной БД не имеют никакого отношения к другим документам, но так случается редко. Взаимосвязи нереляционными базами данных поддерживаются, но не всегда обеспечивается та же целостность, как в РСУБД. Это может быть проблемой, а может и не быть.
Многими нереляционными БД сейчас поддерживается та или иная разновидность SQL.
Оптимальная технология для работы
Итак, данные в целом не в полной мере структурированы и не в полной мере неструктурированы. Те и другие обрабатываются и реляционными, и нереляционными БД.
Как же выбрать?
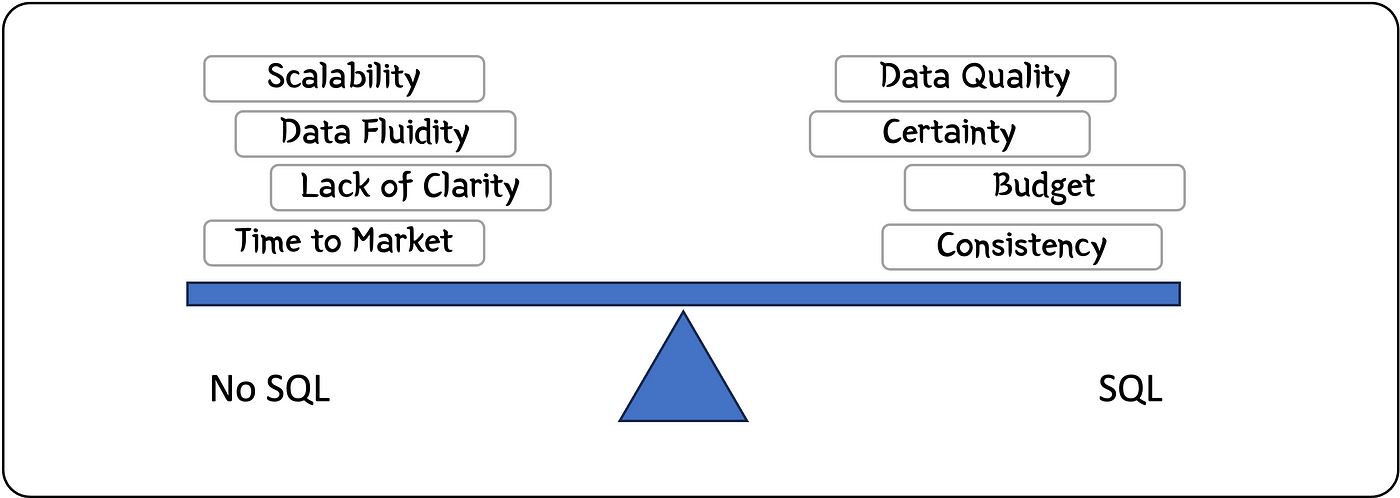
Учесть текучесть данных. Если они как кирпич, придутся кстати строгие правила реляционной БД. Если как вода — гибкость реляционных БД.
Имеется и другой сценарий. Иногда необходимо сохранить данные, структура которых еще неизвестна. Когда освоим идентификацию структуры, данные обработаются. В этом случае уровень текучести данных еще не известен, предпочтительнее нереляционная БД.
Таким образом, по текучести большинство данных располагаются между кирпичами и водой. Если ближе к кирпичам, предпочитается реляционная БД, к воде — нереляционная.
А как обрабатывается другой тип данных?
Неструктурированные данные с реляционной БД
Реляционными базами данных неструктурированные данные обычно обрабатываются в виде большого двоичного объекта. В нем, как и в файле, содержатся данные любого типа.
Сохраняются неструктурированные данные и в виде текстовых полей со строкой в формате JSON внутри. JSON — типичный формат текучих данных, но у него самого строгая структура.
В последней Postgres SQL данные в формате JSON по умолчанию управляются типом поля JSONB. К данным в поле JSON затем обращаются с помощью SQL.
То есть неструктурированные данные сохраняются в реляционной БД по-разному.
Структурированные данные с нереляционной БД
С другой стороны, для структурированных данных можно выбрать нереляционную БД, но для обработки данных нужна структура.
Здесь тоже имеются варианты.
Структура базы данных, за исключением коллекций и документов, совершенно неопределенная. Поэтому в ней сохраняется все что угодно, в том числе структурированные данные. Но прежде, чтобы обеспечить соответствие сохраняемых в БД данных желаемой структуре, применяются правила проверки.
Этим обеспечивается использование в коде структуры данных.
Если данные системой не введены, то для соответствия желаемой структуре правила проверки применяются при считывании данных. При любом сбое этой проверки данные не обработаются: сначала понадобится устранить сбой.
Нужна согласованность
При выборе технологии хранения учитывается также согласованность.
Как изменение данных одного пользователя представляется для других?
Имеется два основных варианта:
1. Если в одной транзакции случается минимум одно изменение, до ее завершения другие пользователи его не видят. В этот момент все, что изменилось во время транзакции, сохраняется вместе, другие пользователи всегда видят согласованный набор данных.
2. При тех же обстоятельствах каждое изменение сохраняется отдельно, другие пользователи сразу их видят. Пока транзакции не завершатся, данные не согласованы.
Второй вариант называется «Согласованность в конечном счете», то есть данные остаются несогласованными недолго. В случае сбоя они оставляются в несогласованном или даже недопустимом состоянии.
Первый вариант обеспечивается реляционными БД, второй — нереляционными.
Хотите отображать все данные в согласованном состоянии? Предпочтите реляционную БД.
Готовы немного потерпеть несогласованность? Получите преимущества. В отсутствие согласованности нереляционная БД масштабируется горизонтально с репликацией на нескольких узлах при необходимости. То есть нереляционная БД хороша для больших наборов данных и репликации содержимого по географическим зонам. В итоге повышается реактивность, особенно если данные больше считываются, чем записываются.
Но так ли нужна «согласованность в конечном счете»? Разве компьютерами не обеспечивается такой уровень достоверности?
На самом деле, если вы применяете микросервисную архитектуру с очередью сообщений или асинхронных событий, то уже приняли согласованность в конечном счете как допустимую модель. Для большинства решений это приемлемая стратегия.
Таким образом, при выборе технологии обнаруживается два технических фактора: согласованность и текучесть.
Как выбираю я
Однако важно не только то, хороша ли технология для работы, но и во сколько обходится.
Это затраты на разработку решения, его функционирование и поддержку, а все вместе — совокупная стоимость владения. Сюда относятся затраты за период времени, в том числе:
- издержки упущенных возможностей за время вывода на рынок;
- разработка на первоначальном этапе;
- доработки и эволюция;
- сопровождение;
- проверка качества;
- сторонние лицензирование и поддержка;
- надежность и доступность сервиса;
- масштабируемость.
В реальности выбор технологии связан не столько с техническими возможностями, сколько с совокупной стоимостью владения, которая ограничена выделяемым на решение бюджетом.
Затраты распределяют на три большие категории:
- время вывода на рынок;
- расходование ресурсов на разработку;
- оперативная поддержка и сопровождение.
Разберем их подробнее.
Время вывода на рынок
Любой проект для соответствия рынку, целевому доходу, экономии ограничивается сроками. Их срыв сказывается на компании финансово.
Поэтому необходимо решение, которым минимизируется риск нарушения сроков разработки и выпуска проекта.
То есть, исходя из времени вывода на рынок, предпочтение отдается технологии с минимальным риском реализации. Обычно это решение уже имеется или очень хорошо знакомо команде разработки и выпуска проекта.
Оно чревато ростом технических недоработок, но с ними текущие бизнес-цели достигаются раньше.
Расходование ресурсов на разработку
Часто считается, что с применением нереляционной БД разработка ускоряется, ведь в этом случае нет необходимости проектировать и реализовывать уровень хранения. Теоретически разработка и выпуск ускоряются, снижаются связанные с ними риски, но в реальности любая экономия времени незначительна.
Хотя слой данных не нуждается в настройке, его еще нужно спроектировать и написать для него код.
В нереляционных БД обычно предпочитаются неизвестные структуры данных и неизвестные бизнес-требования. Поэтому такие базы данных идеальны для сценариев, в которых решение нужно сейчас, но требования подтверждаются позже. Использование нереляционной БД чревато сокращением технических недоработок, создаваемых такими решениями.
При выборе технологии необходимо подумать о команде разработчиков. Если говорить о времени вывода на рынок, качестве решения — с точки зрения функциональных, нефункциональных требований, а также требований безопасности — и сокращении технических недоработок, предпочтительнее технология, знакомая команде разработчиков.
При наличии времени и бюджета для приобретения навыков работы с новой технологией, какой бы она ни была, время разработки не является фактором выбора. Однако времени и бюджета обычно не хватает.
Оперативная поддержка и сопровождение
Итак, технология выбрана, и на ее основе разработано решение. Помещаем его в продакшен, и тут начинаются проблемы.
Затраты на сопровождение увеличиваются: лицензирование новой технологии не относится к имеющимся соглашениям, поэтому образуются дополнительные затраты.
Команда оперативной поддержки, в том числе 1-го, 2-го и 3-го уровней, не разбирается в новой технологии: их кривая обучения такая же, как у разработчиков. Это сказывается на сроках разработки и выпуска проекта и/или качестве сервиса.
Чтобы команда устраняла неисправности различной сложности, необходимо создать новые инструменты оперативной поддержки. В процессе обучения допускаются ошибки, и это сказывается на пользователях — сроки восстановления увеличиваются.
При смене технологии все это нужно учитывать и планировать.
Подводя итоги
Рассмотрев учитываемые факторы, приходим к выводу: выбор технологии баз данных не так прост.
Вот эти факторы на высоком уровне:
- текучесть данных;
- согласованность;
- время вывода на рынок;
- расходование ресурсов на разработку;
- оперативная поддержка и сопровождение.
Разрыв и различия между реляционными и нереляционными базами данных с каждым днем сокращаются. Уникальных преимуществ, которыми отличаются эти БД и которые приходятся кстати в проектах, в целом становится все меньше.
Принимая равными прочие условия выбора технологии, переходим к изучению влияния на бизнес, которое обычно сводится к финансовым последствиям. Создать новый проект и нанять команду разработчиков — роскошь для вас? Тогда существенны факторы, исходя из которых предпочтение обычно отдается уже применяемой технологии.
При выборе технологий я и сам сталкивался с трудностями. Создавал проект, набирал команду разработчиков, наследовал встроенные технологии и команды разработчиков и рассматривал различные варианты.
Почти в каждом случае приходилось отвечать на вопрос о влиянии на бюджет и сроки. Технические недоработки разгребаются позже, они в любом случае накапливаются.
По неподтвержденным данным, программное обеспечение устаревает за 5–8 лет до его замены. Эти сроки продиктованы изменениями современной архитектуры в целом, изменениями на рынке, давлением конкурентов на поставщиков с целью совершенствования их технологий и т. д. Как пользоваться кредитной картой, которая через пять лет исчезнет?
Поэтому при выборе между реляционными и нереляционными решениями я бы руководствовался такими приоритетами:
- текучесть данных — во время разработки и во время выполнения;
- согласованность данных;
- доступный бюджет/сроки;
- имеющаяся технология и возможности команды;
- масштабируемость и производительность.
Рассмотрим это в сценариях с двумя проектами:
Проект № 1 — набор текучих данных, в отсутствие согласованности данных и при массовом масштабировании.
Проект № 2 — относительно твердый набор данных с согласованностью и без требований по массовому масштабированию.
- Учитывая новый проект, в № 1 я бы выбрал вариант с нереляционным решением.
- Учитывая новый проект, в # 2 я бы выбрал вариант с реляционным решением.
- Учитывая имеющуюся технологию и соответствующие навыки, а также достаточные для смены технологии бюджет и сроки, оставляем выбранные выше варианты: для № 1 нереляционное решение, для № 2 реляционное.
- Учитывая имеющуюся технологию и соответствующие навыки, а также отсутствие для смены технологии бюджета или сроков, я бы использовал имеющуюся технологию для решения в проектах № 1 или № 2 с соответствующей стратегией устранения любых компромиссов.
Заключение
Мы рассмотрели факторы, учитываемые при выборе между реляционными и нереляционными БД.
Решение принимается в первую очередь исходя из способности технологии «выполнять работу». Но по мере совершенствования технологий разрыв между базами данных сокращается, и значение этого фактора уменьшается.
Следующий фактор выбора — совокупная стоимость владения с точки зрения затрат на разработку, поддержку и сопровождение, а также оперативную поддержку.
Стоит отметить, что бизнес-сценарий внедрения новой технологии обосновать куда сложнее, чем применение уже имеющейся — при том что со стороны технологии нет неблагоприятных факторов.
Проект, бизнес и структура принятий решений у всех разные, но учитываемые факторы те же.
Читайте также:
- SQL или NoSQL: как правильно выбрать базу данных?
- Java и базы данных NoSQL: практическое руководство
- Выбор между SQL и NoSQL: ACID и CAP, схема и транзакции
Читайте нас в Telegram, VK и Дзен
Перевод статьи Martin Hodges: How I choose between SQL and No-SQL solution





