
Мы расскажем, как реализовали бесконечные репозитории Git на Cloudflare при помощи нового типа бессерверной базы данных — сильно оптимизированный и горизонтально масштабируемый Git-сервер на Webassembly, работающий на Cloudflare Worker. Это позволяет легко размещать бесконечное количество репозиториев. Кроме того, поскольку сервер работает на Cloudflare, он по умолчанию поддерживает IPv6. Для сравнения, GitHub пока не поддерживает IPv6.
Сейчас мы используем нашу технологию, чтобы создать платформу для написания кода. Рассматривается идея сервиса — дать возможность создавать бессерверные базы (DBaaS), позволяющие любому пользователю создавать произвольное количество репозиториев Git в облаке, а также использовать их в собственном продукте.
Зачем это нужно
Работая над приложением для создания заметок разработчиков на основе Git, мы столкнулись с необходимостью эффективного размещать репозитории. Хотелось избежать самостоятельного управления серверами и мы экспериментировали с бессерверным подходом. После исследования не получилось найти никого, кто пытался сделать нечто подобное, поэтому кроме потенциальной полезности эффективное размещение также показалось интересной задачей.
Мы большие поклонники Cloudflare и платформы Workers, а еще мы знали о Durable Objects. Последние показались идеальным базовым хранилищем для такого проекта в смысле модели применения, вероятных шаблонов доступа и общей философии.
Мы считаем Durable Objects новым, революционным типом хранения. Они предлагают транзакционное, строго согласованное и устойчивое хранилище типа ключ-значение. Они тесно интегрированы со средой выполнения Workers и подходят для всех видов координации и использования данных из приложений. Учитывая их полезность, мы вполне ожидаем, что в будущем другие облачные провайдеры предложат аналогичный тип хранилища наряду со своими бессерверными предложениями.
Начиная исследование, мы знали, что Cloudflare построила D1 (их предложение базы данных SQLite) на основе Durable Objects. В дополнение к нашим ранним экспериментам с Durable Objects это вселило в нас уверенность в том, что то, что мы намеревались реализовать, осуществимо, поэтому мы поставили перед собой цель разместить репозиторий Git внутри Durable Objects.
Git в Cloudflare Workers
Cloudflare Workers — бессерверная платформа на основе движка JavaScript V8, которая также способна выполнять бинарные файлы Wasm, поэтому при попытке запустить Git в этой среде варианты были несколько ограничены. Мы попробовали несколько разных подходов, в итоге осталось только два разумных кандидата:
- libgit2 — кроссплатформенная подключаемая библиотека Git, написанная на C;
- isomorphic-git — реализация Git на чистом JavaScript.
Мы пришли к выводу, что начать проще с isomorphic-git, но первоначальные вложения в работу libgit2 могут окупиться более существенно, поскольку libgit2 применяется гораздо шире и лучше закалена в боях. До наших попыток другие разработчики уже реализовали работу libgit2 в Node.js и в браузерах (смотрите wasm-git), это еще сильнее убедило нас в том, что в разработке мы находимся на правильном пути.
В итоге мы скомпилировали libgit2 через Emscripten и упаковали ее для Cloudflare Workers.
В качестве основного хранилища Git использует файловую систему, поэтому следующим шагом стала реализация файловой системы поверх Durable Objects. Большим препятствием, с которым мы столкнулись на этом этапе, оказалось то, как в современном JavaScript обрабатывается ввод-вывод (при помощи промисов или async/await), в сравнении с тем, как ожидается, что ввод-вывод файловой системы будет работать в Emscripten (синхронными системными вызовами). Emscripten предлагает два механизма применения асинхронных вызовов функций JavaScript в синхронных функциях C — это JSPI и Asyncify. После обширных исследований мы переписали значительную часть Emscripten для поддержки асинхронных вызовов файловой системы. В итоге поверх Durable Objects мы создали собственную файловую систему Emscripten, которую называем DOFS. Наличие файловой системы на Durable Objects очень полезно для запуска Git-сервера, но также открывает много других интересных возможностей.
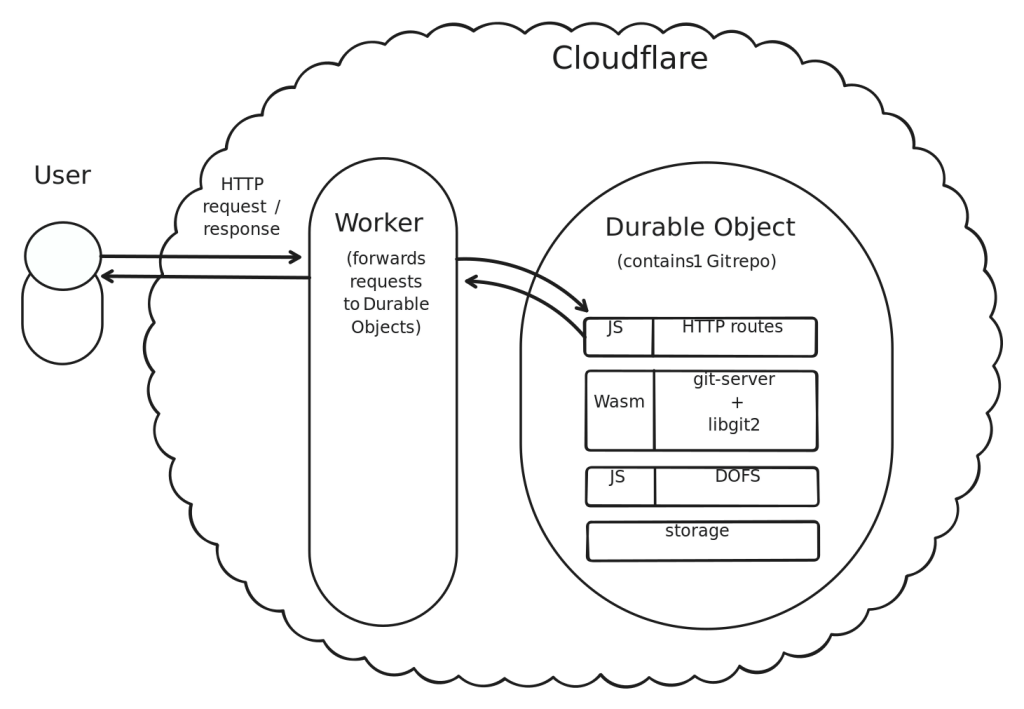
Реализация сервера
Компиляция libgit2 в Wasm и реализация файловой системы поверх Durable Objects стала хорошим началом, но, чтобы сделать полезным весь проект, нужно было проделать дополнительную работу. На этом этапе реализация Git в Cloudflare Workers могла хранить репозиторий в Durable Objects и взаимодействовать с внешним миром через кастомные операции HTTP (чтение файла, перечисление веток и т. д.), но не могла общаться по протоколу Git, поэтому нельзя было использовать CLI Git, чтобы извлечь или запушить код.
libgit2 — отличная библиотека Git, но она предоставляет только клиентскую функциональность; функциональности сервера нет. Нам не удалось найти в сети другие реализации функций сервера Git, которые можно использовать как справочный материал. Хотя Git сам реализует серверные команды получения и загрузки пакета, их портирование на libgit2 оказалось невозможным. Основная причина в том, что требуемые команды сервера зависели от множества других файлов исходников, а интерфейсы между этими файлами выглядели плохо определенными.
Забросив попытки портирования, мы в конечном счёте реализовали недостающую функциональность сервера самостоятельно: использовали основные функции libgit2, изучали всю доступную документацию и кропотливо исследовали поведение Git. Также мы создали обширный набор интеграционных тестов, чтобы обеспечить надежность и производительность нашего сервера.
Воспроизводимые сборки
Компиляция нативных библиотек типа libgit2 для конкретной целевой платформы, требует значительной подготовки, особенно если саму библиотеку нужно компилировать модифицированной версией компилятора. Мы обнаружили, что поддерживать повторяемость всего процесса ручным вызовом команд сборки для каждого компонента затруднительно. К счастью, уже есть замечательное программное обеспечение именно для этой цели, например Nix — декларативная и чисто функциональная (в смысле функционального программирования) система сборки, которая делает воспроизводимые сборки возможными.
Мы создали нашу систему сборки, используя Nix. Это позволило всего одной командой воспроизводимо собирать исправленный Emscripten, исправленную libgit2 и реализацию Git-сервера на C с нуля. Мало того, Nix также позволил тонко настроить этот процесс сборки и сделать его настраиваемым с помощью флагов, передаваемых команде сборки. Теперь мы можем создать наш сервер с нуля, ориентируясь на нативную платформу (Linux или Mac), Node.js или Cloudflare Workers.
Мы также можем легко настроить, хотим ли выпускать или разрабатывать сборку всего дерева пакетов. Кроме того, Nix позволяет создавать только поддерево пакетов, что позволяет вмешиваться в середине сборки и вносить необходимые изменения. Кривая обучения Nix сложна, но оно того стоит. Если вас интересует столь же мощный инструмент, с которым легче начать работу, flox — отличный вариант.
Мы обнаружили прекрасный, изначально непредвиденный итог построения дерева пакетов через Nix: приложив немного усилий, мы смогли скомпилировать широкий спектр интересных нативных библиотек для WebAssembly, используя модифицированный компилятор Emscripten. На данный момент мы скомпилировали zlib, libarchive и libmagic в Wasm и статически связали их с нашим сервером. В результате сервер может создавать архивы во множестве различных форматах (в настоящее время мы используем только zip и tar.gz) и легко определять MIME-типы для огромного количества хранимых файлов. Nixpkgs полон Nix-скриптов для сборки различных программных пакетов, и было достаточно просто настроить некоторые из них для сборки в Wasm.
Наконец, мы также скомпилировали QuickJS в Wasm, используя нашу систему сборки Nix. Мы используем наш сервис на основе QuickJS, чтобы запускать файлы JavaScript с полной поддержкой операторов импорта/экспорта модулей ES в Cloudflare Workers по требованию (подробнее в следующем разделе).
Возможности компоновки
Один из основных принципов проектирования нашей кодовой базы — вкладывать усилия в создание мощных возможностей компоновки и бережно хранить их в нашем репозитории. Наличие мощного набора этих возможностей открывает интересные комбинации, особенно при использовании такой платформы, как Cloudflare Workers, которая упрощает композицию.
Пример номер один. Мы разработали наш сервер с намерением обслуживать из Durable Object один репозиторий, но после этого было очень легко упаковать одни и те же конечные точки HTTP и Wasm и предоставить его из простого Worker, а не Durable Object. Таким образом, мы получили возможность запускать один и тот же код Git либо в постоянном контексте (клиенты подключаются к одному и тому же Durable Object), либо в эфемерном контексте (клиенты подключаются к любому ближайшему к ним Worker). Есть случаи, когда выполнение функций Git в эфемерном контексте полезно и когда отправка запроса к Durable Object будет неправильным выбором. Например, при валидации имени ветки или тега в веб-интерфейсе нет необходимости заново реализовывать эти специфичные для Git правила на JavaScript, если мы можем предоставить точное поведение апстрима libgit2 в эфемерном, ближайшем к пользователю веб-интерфейса Worker.
Пример номер два. Если вы посетите https://gitlip.com/@nataliemarleny/test-repo/ref/HEAD/main.js, вы увидите возможность выполнить этот файл, нажав Play справа.
Вот небольшое видео.
Для достижения конечного результата некоторые из наших возможностей компоновки работают вместе:
- API получает запрос на выполнение main.js из HEAD репозитория.
- API координирует сервисы (с помощью биндингов сервисов).
- Сервис git-server получает запрос на архив HEAD репозитория и передает снимок tar.gz HEAD обратно в API.
- API перенаправляет поток tar.gz в сервис js-run (на основе QuickJS).
- js-run распаковывает поток архива в память.
- js-run запускает запрошенный файл из памяти (обратите внимание, что main.js импортирует fizzbuzz.js!) и передает ответ обратно в API.
- API передает ответ обратно пользователю.
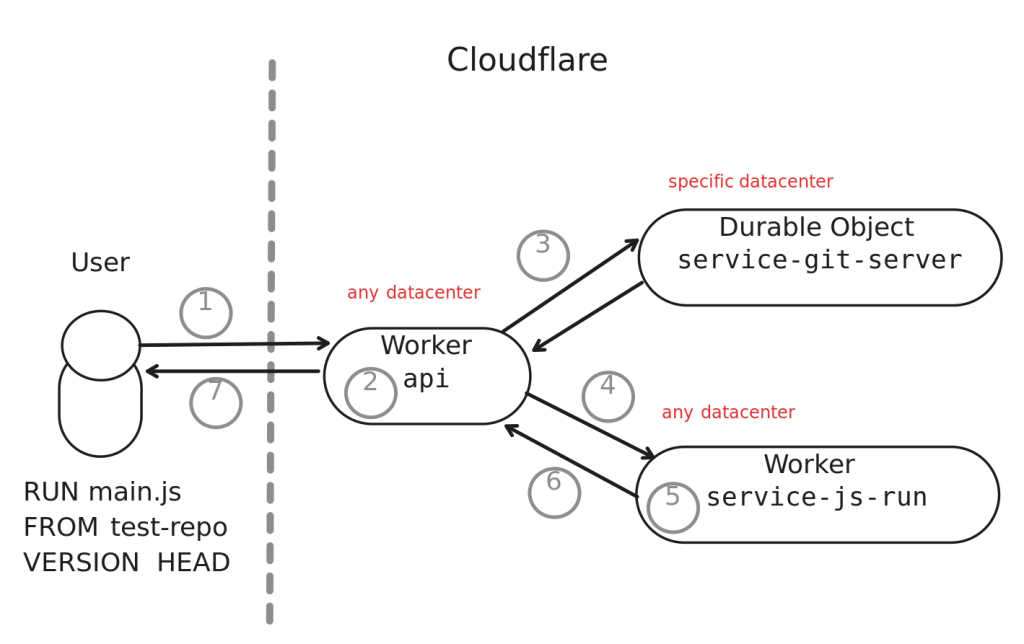
Сейчас выполнение JavaScript по требованию — всего лишь демонстрация того, чего мы можем легко достичь с помощью нашего стека, но в будущем мы планируем сделать его мощнее, добавив поддержку импорта модулей NPM и многое другое.
Оптимизации
Достижение прогнозиоуемой производительности нашего Git-сервера потребовало применить нескольких методов оптимизации. Обозначим самые важные из них.
Как и любая другая бессерверная платформа, Cloudflare Workers имеет свой набор ограничений. Для запуска сервера Git наиболее важными из них являются размер Worker (общий размер развернутого кода), объем памяти и ограничение ЦП.
В сентябре 2023 года ограничение размера Worker в платном тарифном плане увеличили с 1 МБ до 10 МБ, но Cloudflare по-прежнему рекомендует сохранять размер всего развертывания менее 1 МБ, чтобы обеспечить максимальную производительность. Наш сервер Wasm Git вместе с libgit2, всеми остальными библиотеками и связующим кодом на JavaScript занимает всего 800 КБ, мы считаем это большим достижением. Мы добились этого в первую очередь за счет оптимизации размера кода во время компиляции и сокращения количества форматов файлов, которые обнаруживает наша утилита libmagic.
Ограничение времени выполнения в 128 МБ памяти представляло проблему изначально. libgit2 активно использует отображение в память при чтении или записи объектов в пак-файлы Git. К сожалению, в приложении Wasm, скомпилированном с помощью Emscripten, отображение в память требует совершенно новой копии файла в памяти (даже если файл уже находится там). Это означало, что наш сервер копировал весь пак-файл Git в память при чтении даже самых маленьких объектов, в результате его производительность зависела от размера пакетного файла, а не от размера объекта. Мы попытались решить эту проблему, изменив Emscripten, но это оказалось слишком сложно, поэтому вместо этого мы решили изменить libgit2: удалили все эквиваленты mmap и заменили их эквивалентами для чтения/записи. Результаты были невероятными. Мы добились производительности, которая не зависит от размера пак-файла (репозитория). Обратите внимание, что отображение в памяти имеет смысл в типичных обстоятельствах, для которых была разработана libgit2.
Durable Objects однопоточны, поэтому можно подумать, что сложно будет эффективно обслуживать одновременные запросы к одному и тому же репозиторию. К счастью, паттерны доступа к репозиторию Git хорошо подходят для оптимизации посредством кэша. Для этой цели мы создали компонент под названием ConsistentCache, который оборачивает API HTTP-кэша Cloudflare (он доступен в каждом Worker и Durable Object) и добавляет необходимые гарантии согласованности. Этот компонент также дедуплицирует вызовы к программе Git Wasm, выдавая один вызов и параллельно передавая ответ всем, кто делал запрос. С этим методом значительное количество запросов к серверу выполняется прямо из кэша, а любое изменение репозитория согласованно очищает этот кэш.
Персистентное хранилище в Durable Objects имеет собственный встроенный уровень кэширования, который повышает общую производительность и дает дополнительные гарантии согласованности. К сожалению, все операции чтения, попадающие в этот встроенный кэш, оплачиваются так же, как и доступ к основному хранилищу. В частности, libgit2 и Git в целом часто приходится читать небольшие фрагменты файла постепенно, что приводит к большому количеству небольших чтений. Во время тестирования это становилось несколько затратным. Мы решили реализовать собственное хранилище кэша под названием StorageEngine и полностью отключить встроенный кэш. Так мы ничего не платим за большинство операций, которые сервер выполняет на DOFS, а несем расходы только на периодическую очистку, при которой все индексные дескрипторы и блоки файлов записываются в хранилище, а также на периодические чтения, заполняющие StorageEngine.
Наконец, мы оптимизировали реализацию голых репозиториев Git, чтобы они всегда содержали очень ограниченное (в основном постоянное) количество директорий. Это позволило предварительно загружать все директории и файлы индексов пакетов из персистентного хранилища (в зависимости от репозитория их от 20 до 60, размером до нескольких КБ каждый) при каждом создании экземпляра Durable Object. Так репозиторий эффективно разогревается для любой команды Git, которую он может получить.
(log) StorageEngine.get (1/1): [HTTP_CACHE_LRU_MAP]
(log) StorageEngine.get (4/4): [NNID, ..., PRECACHE]
(log) StorageEngine.get (48/48): [N_1, ..., B_463_0]
(log) StorageEngine.get (0/1): [N_1]
(log) StorageEngine.get (0/1): [N_2]
(log) StorageEngine.get (0/1): [N_350]
(log) StorageEngine.get (0/1): [N_3]
(log) StorageEngine.get (0/1): [N_6]
(log) StorageEngine.get (0/1): [N_349]
(log) StorageEngine.get (0/1): [B_349_0]
(log) StorageEngine.get (0/1): [N_10]
(log) StorageEngine.get (0/1): [B_350_0]
(log) StorageEngine.get (0/1): [N_7]
(log) StorageEngine.get (0/1): [N_463]
(log) StorageEngine.get (0/1): [B_463_0]
(log) StorageEngine.get (0/1): [N_5]
(log) StorageEngine.get (0/1): [N_25]
(log) StorageEngine.get (0/1): [N_24]
(log) StorageEngine.get (0/1): [N_4]
(log) StorageEngine.get (0/1): [B_25_0]
... предыдущая строка повторяется еще 263 раза
(log) StorageEngine.get (1/1): [B_24_0]
(log) StorageEngine.get (1/1): [B_24_15]
(log) StorageEngine.get (0/1): [B_25_0]
(log) StorageEngine.get (1/1): [B_24_9]
(log) StorageEngine.get (0/1): [B_24_9]
(log) StorageEngine.get (0/1): [B_25_0]
... предыдущая строка повторяется еще 8 раз
(log) StorageEngine.get (1/1): [B_24_10]
(log) StorageEngine.get (0/1): [B_24_10]
(log) StorageEngine.get (0/1): [B_24_9]
... предыдущая строка повторяется еще 10 раз
(log) StorageEngine.get (0/1): [B_24_10]
(log) StorageEngine.get (0/1): [B_25_0]
... предыдущая строка повторяется еще 8 раз
(log) StorageEngine.get (1/1): [B_24_12]
(log) StorageEngine.get (0/1): [B_24_12]
... предыдущая строка повторяется еще 30 раз
(log) StorageEngine._syncBufferFinal START
(log) StorageEngine.put (1): [HTTP_CACHE_LRU_MAP]
(log) StorageEngine._syncBufferFinal END
(log) StorageEngine._syncBufferFinal START
(log) StorageEngine._syncBatchPut (1): [HTTP_CACHE_LRU_MAP]
(log) StorageEngine._syncBufferFinal ENDПриведенные выше, а также некоторые другие оптимизации гарантируют разумную и надежную производительность наших серверов Git. Небольшие операции чтения и записи, например типичный README.md, через HTTP выполняются менее чем за 150 мс, даже без кэширования и независимо от размера репозитория.
Ограничения
На данный момент Git-сервер хорошо подходит для репозиториев размером до 100 МБ. Этого более чем достаточно для нашего случая. За пределами 100 МБ мы сталкиваемся с несколькими проблемами:
- Однопоточная упаковка и распаковка пак-файлов Git во время операций клонирования, извлечения и пуша превышает ограничение времени на запросы к Worker, если пак-файлы слишком велики.
- Потоки тела извлечения не полнодуплексные. К сожалению, это означает, что, хотя теоретически возможно клонировать и отправлять любой репозиторий на нашем сервере, мы не сможем получить из него данные. Это связано с тем, что операция извлечения в интеллектуальном протоколе Git требует полнодуплексного канала, чтобы согласовать оптимальный для отправки пак-файл. К счастью, в репозиториях, содержащих до 32 ссылок, такая коммуникация никогда не происходит.
- Cloudflare Worker на данный момент поддерживает только HTTP, поэтому мы не можем поддерживать клонирование, извлечение и пуш по SSH без существенного усложнения инфраструктуры.
Мы считаем, что вышеуказанные ограничения разрешимы в долгосрочной перспективе и что в будущем мы сможем настроить наш сервер Git, чтобы он обрабатывал репозитории произвольного размера и поддерживал SSH.
Демо
Чтобы просмотреть работу на продакшне, посетите общедоступные профили Gitlip:
Обратите внимание: текущая производительность ограничена тем фактом, что наша основная база данных не размещена на Cloudflare, и вызовы к ней доминируют над задержкой большинства запросов. За счет дальнейших оптимизаций ожидается сокращение общей задержки большинства запросов на 50–75 %.
Планы
Наличие бессерверной и бесконечно горизонтально масштабируемой серверной инфраструктуры Git открывает для продуктов, созданных на ее основе, множество возможностей. Мы считаем, что Git недостаточно применяется при хранении данных, учитывая его возможности управления версиями и тот факт, что он хранит простые файлы, которые могут быть любого формата, подходящего для приложения.
Дополнительным преимуществом создания производительного сервера Git на JavaScript и Wasm является тот факт, что наш сервер уже в основном работает прямо в браузере. Это открывает захватывающие возможности: представьте себе часть PWA — легкий клиент Git, способный поверхностно клонировать удаленный репозиторий, чтобы разрешить локальное редактирование даже в автономном режиме. Мы планируем исследовать эту возможность.
Читайте также:
- 10 продвинутых советов по Git
- Руководство по Git для новичков
- Как развернуть GitLab с помощью Docker за 5 секунд
Читайте нас в Telegram, VK и Дзен
Перевод статьи Zoran Plesivcak, Natalie Marleny: Infinite Git repos on Cloudflare Workers




