
Дискуссии вокруг ИИ
В последнее время в моем окружении ведутся дискуссии об искусственном интеллекте (ИИ). Наверняка вы также не остались в стороне от этих бесконечных споров о последствиях искусственного интеллекта, порождаемых им этических проблемах, плюсах и минусах. Однако мало кто из моих нетехнических оппонентов затрагивает вопрос о том, как работает ИИ. Дело в том, что подобные концепции пугают неспециалистов. Им кажется невозможным понять, как функционируют большие языковые модели (LLM).
Но это не так. Любой человек может это понять. Ведь принцип, лежащий в основе резкого скачка в сегодняшнем развитии ИИ, довольно прост.
Я постараюсь без единого технического термина и математического уравнения объяснить, как на самом деле работают LLM.
Меню
Представьте следующее: вы приготовили ужин, но для его подачи нужен еще один гарнир. Приготовленных блюд недостаточно. Необходимо добавить к ним еще какой-то компонент.
Легче сказать, чем сделать. То, что вы выберете, должно соответствовать набору подаваемых блюд. Если преобладают соленые блюда, то и гарнир должен быть таким же. Если в меню уже есть салат, не стоит делать еще один. Если в использованных продуктах много крахмала, возможно, стоит добавить запеченные овощи.
Разве не здорово иметь приложение, которое просто подскажет, что приготовить? И не случайным образом. Вы вводите то, что уже приготовлено, а оно подсказывает оптимальный вариант гарнира. Это приложение должно работать для любого приема пищи, с любым сочетанием блюд и вкусов независимо от того, сколько человек требуется накормить — четыре или сорок.

Вот как создается такое приложение. Два простых шага.
Во-первых, надо заставить его продумывать каждое меню так, чтобы это было понятно компьютеру. Ведь у компьютеров нет вкусовых рецепторов. Они должны воспринимать понятия, о которых у них нет интуитивного представления. Правильно восприняв понятие “еда”, компьютер должен закодировать его в виде неких данных, фиксирующих все, что может повлиять на сочетаемость этой еды с другими продуктами.
Во-вторых, нужно научить приложение принимать любой набор существующих блюд и выдавать другой. Система не должна просто запоминать то, что уже было заложено в нее ранее. Она должна работать с любыми комбинациями блюд, даже с теми, о которых она ранее ничего не знала. Поэтому нужно не просто запрограммировать систему. Необходимо ее обучить.
Шаг первый: моделирование меню
Нам нужно научить компьютер воспринимать наборы блюд как данные. Не будем делать это, описывая блюда (например, сообщая о том, какие они на вкус или с чем сочетаются). Это устаревший тип машинного обучения. Слишком ограниченный, слишком склонный к ошибкам. Просто предоставим компьютеру большое количество данных о том, какие блюда сочетались между собой в прошлом.
Рассмотрим два типа блюд: скажем, салат “Цезарь” и салат “Капрезе”. Мы, люди, знаем, что эти два блюда похожи. Они оба итальянские, оба салаты, оба содержат овощи и сыры. Но машине не нужно знать ничего из вышеперечисленного, чтобы понять, насколько похожи эти два блюда.

Вполне вероятно, что, просматривая горы данных, можно увидеть салат “Цезарь” в сочетании с другими итальянскими блюдами. И также вероятно не встретить меню, в котором он сочетался бы с другим салатом. То же самое можно сказать и о салате “Капрезе”. Обычно его не подают с другими салатами, но он может сочетаться с итальянскими блюдами.
Поскольку эти два блюда часто сочетаются с одними и теми же видами других блюд, можно отнести их к категории похожих. Как правило, они встречаются в одних и тех же меню. Можно сказать, что блюдо классифицируется по окружению, в котором оно находится.
И это не так уж интуитивно понятно. Обратите внимание: нет ни одного меню, в котором салаты “Цезарь” и “Капрезе” встречались бы вместе. Эти блюда никогда не должны подаваться вместе, чтобы мы сочли их похожими. Они просто должны встречаться среди других одних и тех же блюд, чтобы стало понятно: их принято считать взаимозаменяемыми и, следовательно, похожими.
Для наглядности представим, что нам надо изобразить на этом графике всю еду:
Для начала возьмем все блюда, которые есть в наших данных, и поместим их на график в произвольном порядке:
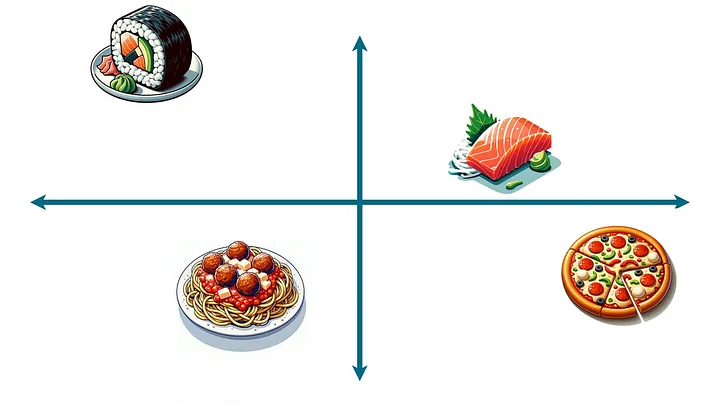
Здесь показаны только четыре блюда для примера. Но представьте все возможные блюда.
Теперь, просматривая данные и всякий раз находя два блюда, которые сочетаются с другими одинаковыми блюдами, передвинем их ближе друг к другу. Заметив разные виды суши, которые обычно сочетаются с одним и тем же мисо-супом, сдвинем эти суши друг к другу. Заметив, что пицца и спагетти сочетаются с чесночным хлебом, тоже сдвинем их поближе друг к другу:
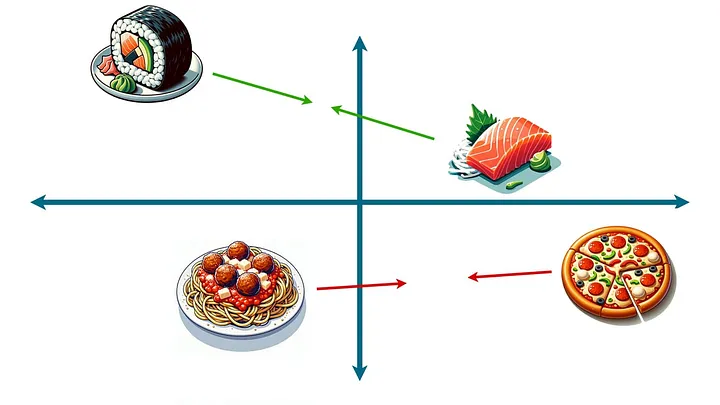
После того, как вы сделаете это неоднократно (я имею в виду, много раз), произойдет нечто волшебное. Блюда, которые являются взаимозаменяемыми, будут располагаться очень близко друг к другу. Блюда, которые в некоторой степени взаимозаменяемы (скажем, тако и буррито), окажутся немного ближе друг к другу. А блюда, которые редко взаимозаменяются (скажем, бургеры и суши), будут находиться далеко друг от друга.
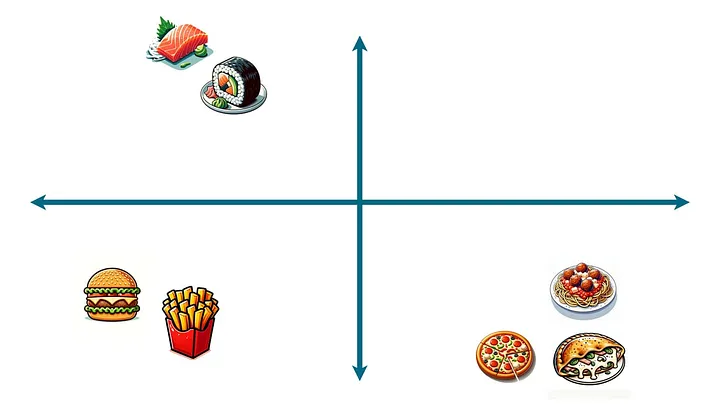
На практике двух измерений недостаточно. Всевозможные национальные блюда и оригинальные закуски должны располагаться на достаточном расстоянии друг от друга. А это значит, что реальным способом отображения такой картины было бы построение графика, состоящего из гораздо большего количества осей (сотен, может быть, тысяч). Хоть это и невозможно представить, суть остается неизменной. Блюда должны располагаться так, чтобы ближе друг к другу оказывались те, которые сочетаются с одними и теми же блюдами.
Для краткости будем называть этот большой многоосевой график “пространством еды”. Каждое возможное блюдо существует в своем пространстве, располагаясь в координатах, близких к тем блюдам, с которыми оно взаимозаменяемо, и далеких от тех, которые сильно отличаются.
Остановимся на минуту, чтобы оценить потрясающие результаты проделанной работы. Мы создали очень точную модель еды, в которой похожие блюда сгруппированы вместе, а разные — далеки друг от друга. И сделали это без учета того, каковы эти блюда на вкус или из чего они сделаны.
Более того, обучение системы на таком большом количестве данных позволяет сделать кое-что еще. Например, выполнить расчет меню.
Расчет меню? Думаете, я сошел с ума?
Уверяю вас, это не так. Вам придется поверить мне на слово, но оказывается, что расположение блюд в пространстве еды не случайно. На самом деле не только похожие блюда располагаются рядом, но и отношения между ними имеют свою логику. Блюда, содержащие хлеб, располагаются на одной плоскости. Соленые блюда также находятся на одной линии. Между блюдами со вкусом кленового сиропа существует некая математическая связь.
И это открывает невероятные возможности. Например, если взять координаты буррито и вычесть координаты тортильи, то можно оказаться в точке буррито-боул. А если взять координаты куриного супа с лапшой, вычесть координаты лапши и добавить координаты риса, то можно оказаться в точке куриного рисового супа.
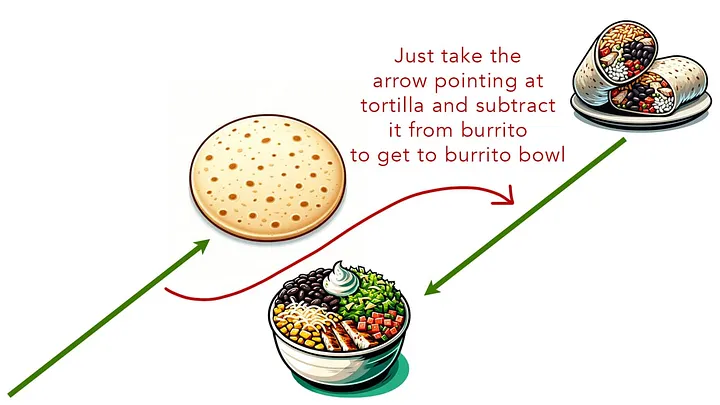
Важный вывод: расположение блюд в пространстве еды не является случайным. Существуют скрытые математические закономерности, благодаря которым каждое блюдо располагается определенным образом по отношению к другим блюдам.
Шаг второй: поиск закономерностей
Итак, мы создали пространство еды и задали каждому виду блюд определенные координаты, которые имеют значение относительно любого другого вида блюд. И что теперь?
Продолжим обучать модель. На этот раз предоставим ей целые меню — речь идет обо всех меню, которые мы когда-либо видели, — и попросим ее найти закономерности. В частности, обучим программу отвечать на вопрос: если меню содержит блюда A, B и C, то каким блюдом D с наибольшей вероятностью оно будет дополнено?
Все, что нужно сделать для этого, — спросить модель по каждому меню, на котором она обучается: как это представлено в пространстве еды? Модель должна заметить, что во многие меню входят блюда из четырех областей графика:
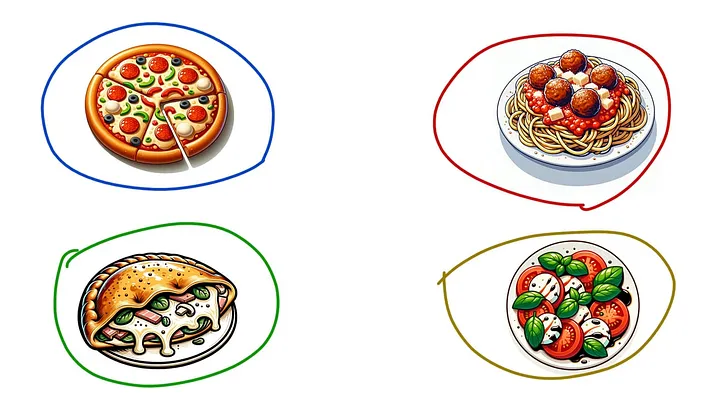
Теперь перейдем к обобщению с учетом исключительно координат в пространстве еды, игнорируя то, какие блюда вообще были использованы для обучения этой закономерности. Можно сделать вывод: если в меню уже присутствуют блюда из этих трех областей, то наиболее вероятно, что дополнительным компонентом будет блюдо из четвертой области:
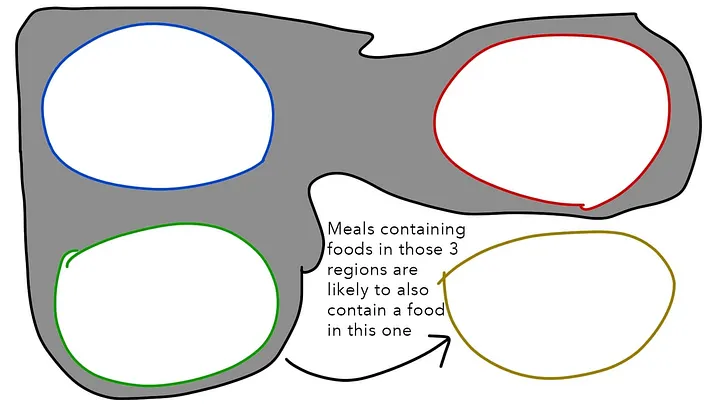
Вспомните, что “блюдо классифицируется по окружению, в котором оно находится”. А поскольку модель была обучена распознавать виды блюд и отношения между ними, а не то, что содержат конкретные блюда и каковы они на вкус, она может предположить любой сценарий с любой вкусовой комбинацией при определении оптимального блюда для добавления в меню. Поскольку еда находится в нескольких областях, модель будет искать область с блюдом, которое обычно подается с блюдами данного меню.
Таким образом, поставленная цель достигнута. Мы хотели создать приложение, которое могло бы достоверно подсказать, какие блюда следует сочетать с другими блюдами. И мы сделали именно это.
Слова вместо блюд
Какое отношение все это имеет к большим языковым моделям?
Просто замените понятие “меню” предложениями, а понятие “блюда” — словами. Такая замена, с теми же установками и подходом, приведет вас к инструментам генеративного текстового ИИ, с которыми мы все знакомы сегодня.
Шаг первый: обучение модели пониманию взаимосвязи между словами с учетом того, как часто они встречаются в схожих контекстах. “Слово классифицируется по окружению, в котором оно находится”. Предоставьте модели кучу данных, написанных людьми (когда я говорю “куча”, имею в виду весь интернет), и позвольте ей соответствующим образом скорректировать координаты слов.
Вывод больше не называется пространством еды. Он называется векторным пространством. Но принципы те же. Система не знает, что означает то или иное слово (точно так же, как она не знает, каково блюдо на вкус). Она понимает только, как это слово связано со всеми остальными словами в векторном пространстве.
Шаг второй: поиск закономерностей. Если в предложении есть слова A, B и C, какое слово появится следующим с наибольшей вероятностью? Если оно содержит X и Y, в какой области векторного пространства искать следующее слово?
То, что делают LLM, получило название “предсказание следующего слова” (аналогично “предсказанию следующего блюда” моделью еды). Допустим, вы попросили LLM произнести: “Скажи, что ты меня любишь”. Модель будет искать во всех своих шаблонах ответ на один вопрос: какое слово с наибольшей вероятностью последует за этой последовательностью слов? Или сформулируем иначе: учитывая векторно-пространственные координаты слов в этом предложении, какие шаблоны, использованные в других предложениях, помогут найти следующее слово?
Ответ, который найдет LLM, будет “Я”. Определив это, модель добавит “Я” в конец вашего исходного промпта и вернет все это себе: “Скажи, что ты меня любишь. Я”. А какое слово, скорее всего, будет следующим? Конечно же, “люблю”! Модель добавит его и вернет все целиком: “Скажи, что ты меня любишь. Я люблю”.
Понятен принцип?
Заключение
Конечно, есть еще несколько нюансов, включая замысловатую математику и сложные вычисления. Но принцип работы LLM ничем не отличается от примера с моделированием меню.
На мой взгляд, этим и объясняется притягательность феномена ИИ, который мы сейчас наблюдаем. Сама технология не так уж сложна на самом деле, если учесть, насколько преобразующей силой она является. Несколько простых математических понятий, куча обучающих данных, немного соли с перцем — и вы, по сути, создали мыслящую машину.
Читайте также:
- Навигация по ландшафту ИИ в 2024 году: тренды, прогнозы, возможности. Часть 2
- Создание Copilot для визуального распознавания в Azure
- Как запустить ИИ-генератор Stable Diffusion
Читайте нас в Telegram, VK и Дзен
Перевод статьи Nir Zicherman: How AI Works





